本文面向有一定嵌入式开发经验的工程师,聊聊自定义通信协议中最容易被忽视的基础问题——帧边界与转义机制。
一、从一个真实的现场问题说起
前段时间有人在群里问:MCU 和上位机通过串口通信,数据发过去大概率正常,但隔一段时间就会出现一帧“错位”,后续所有解析全部乱掉,重启才能恢复。
这个问题很典型。根本原因不在波特率,不在中断,而在于协议里根本没有明确的帧边界——程序不知道一包数据从哪里开始、到哪里结束,一旦中间丢了一个字节,整个接收状态机就垮了。
帧头、帧尾、转义,是自定义串口协议里最基础的三件事,但也是最多人“差不多得了”的三件事。
二、字节流没有天然边界
UART 本质上是一条连续的字节流通道,它只管把字节一个一个搬过去,不区分包与包之间的边界。
发送方视角:
[0xAA][0x01][0x10][0x03][0xBB][0xAA][0x02][0x20][0x01][0xBB]
↑_______第一包_______↑ ↑________第二包________↑
接收方视角(没有帧结构时):
0xAA 0x01 0x10 0x03 0xBB 0xAA 0x02 0x20 0x01 0xBB ...
???哪里是分界线???
如果通信双方没有约定好“一包数据长什么样”,接收方面对这串字节就是瞎子摸象。帧结构要解决的核心问题只有一个:让接收方能可靠地从字节流中找到每一包数据的起点和终点。
三、帧头:数据包的“门牌号”
帧头(Frame Header / SOF, Start of Frame)是接收方扫描字节流时最先寻找的标志。
常见的设计方式有两种:
方案 A:固定魔数

用 0xAA 0x55 这样的固定组合做帧头,接收状态机不断扫描,匹配到这两个字节就认为一帧开始了。
选两个字节而不是一个,是为了降低误同步概率——有效载荷中随机出现 0xAA 0x55 连续序列的概率远小于单独出现 0xAA。
方案 B:帧头 + 长度字段(推荐)

在帧头之后紧跟长度字段,是工程中最稳定的做法之一。接收方逻辑变得非常清晰:找到帧头 → 读长度 → 按长度收数据 → 校验。
四、帧尾:可选,但有它更安全
帧尾(EOF, End of Frame)不是必须的,尤其当协议有长度字段时,理论上帧尾可以省略。但在实际工程里,帧尾依然有价值:
- 双重校验:帧尾作为第二道防线,配合 CRC 一起判断这帧是否完整
- 硬件调试方便:用逻辑分析仪抓波形时,能直观看到每帧的终止位置
- 异常恢复:当状态机检测到帧尾位置不对时,可以主动丢弃并重同步
一个典型的完整帧结构长这样:
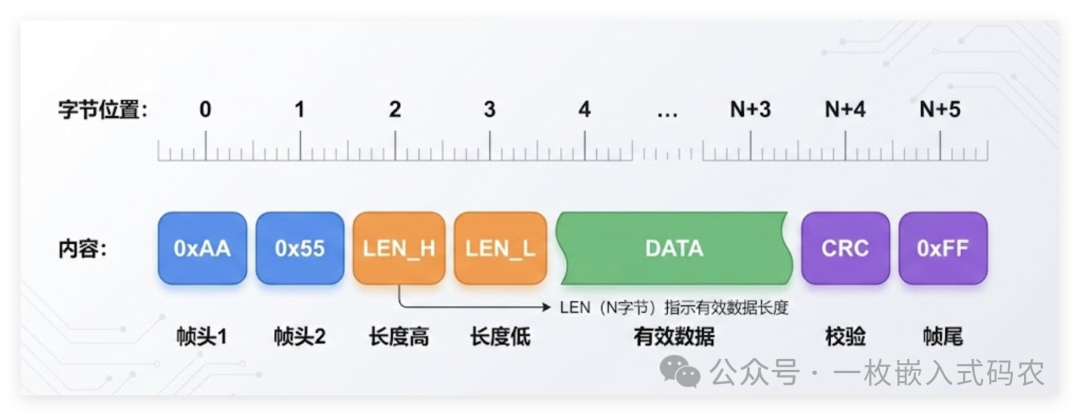
帧尾选 0xFF 或其他特殊值,同样建议避开在 DATA 中高频出现的数值——这引出了最后一个问题:如果 DATA 里真的出现了和帧头/帧尾相同的字节,怎么办?
五、转义:协议的“元字符”机制
这是整个帧设计里最容易被新人跳过的一步,也是最容易埋坑的地方。
问题场景:
假设帧头是 0xAA 0x55,有效载荷里偶然出现了这两个连续字节,接收状态机就会把它当成一个新帧的开始,导致解析完全错乱。

解决方案:字节填充(Byte Stuffing)
引入一个转义字节(Escape Byte),例如 0x7D,规则如下:
- 发送前:DATA 中凡是出现
0xAA、0x55、0xFF、0x7D 的地方,在其前面插入 0x7D,并将原字节异或一个固定值(常用 0x20)
- 接收后:遇到
0x7D,跳过它,将下一个字节再异或 0x20 还原

完整的收发流程变成:
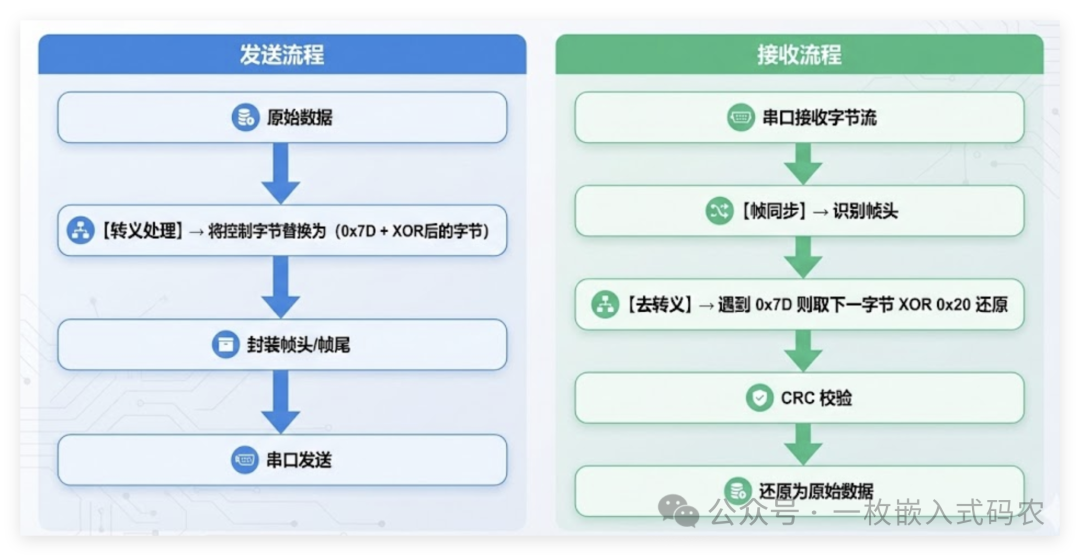
注意: 转义处理只针对 DATA 区域,帧头和帧尾本身不做转义,因为它们是协议控制字段,接收方需要直接识别它们。
六、一个完整的协议规范示例
把以上内容整合成一个可直接落地的协议设计定义:
协议名称:CustomSerial v1.0
帧格式(发送时 DATA 已经过转义处理):
+------+------+-------+-------+------------------+-------+-------+------+
| 0xAA | 0x55 | LEN_H | LEN_L | DATA(已转义) | CRC_H | CRC_L | 0xFF |
+------+------+-------+-------+------------------+-------+-------+------+
1字节 1字节 1字节 1字节 0~512字节 1字节 1字节 1字节
字段说明:
帧头 : 0xAA 0x55(固定,不参与转义)
LEN : DATA 转义后的字节数(大端,16位)
DATA : 有效载荷,发送前需做转义处理
CRC : 对【原始DATA(未转义)】计算 CRC16-MODBUS
帧尾 : 0xFF(固定,不参与转义)
转义字节:0x7D
需转义的字节集合:{0xAA, 0x55, 0xFF, 0x7D}
转义方式:在原字节前插入 0x7D,原字节 XOR 0x20 后发送
接收状态机:
IDLE → 等待 0xAA
SOF1 → 等待 0x55(否则回到 IDLE)
SOF2 → 读取 LEN_H、LEN_L(共2字节)
LEN → 按 LEN 长度读取 DATA(实时去转义)
DATA → 读取 CRC_H、CRC_L(2字节)
CRC → 等待 0xFF 帧尾
DONE → 验证 CRC,通过则投递数据,失败则丢弃
这个设计的关键点在于:LEN 记录的是转义后的长度,这样接收方在 DATA 阶段只需按固定字节数读取,不需要实时计算去转义后的长度,逻辑更简单,出错也少。
七、写在最后
帧头、帧尾、转义,三件事组合解决的是同一个问题:在一条没有语义的字节管道上,让通信双方都能可靠地找到数据的边界。
没有长度字段时,依赖帧尾定界;有长度字段时,帧尾做双重保险;有特殊字节冲突风险时,转义处理。这几个机制不是非此即彼,而是根据实际场景灵活组合。
最后一点经验:协议文档要在写代码之前定好,而不是写完代码后补。 两端各自理解的“帧格式”差一个字节,联调的时候会让你怀疑人生。希望这篇关于MCU通信基础的文章能帮你避开一些坑,更多深入的技术讨论,欢迎来云栈社区交流。
 发表于 2026-2-24 09:25:38
|
查看: 381|
回复: 0
发表于 2026-2-24 09:25:38
|
查看: 381|
回复: 0
