前面我们学习了MySQL分库分表的理论基础,以及ShardingSphere的原理和核心概念,大家对这套技术栈应该有了大体上的掌握。这次,我们就从实际编码出发,动手实现一个基于Spring Boot + ShardingSphere的分库分表项目。
文章会分为三个主要部分:从搭建基础项目架构开始,到详细配置分库分表规则,最后探讨分库分表实践中需要关注的关键点。希望通过这个循序渐进的过程,能让你对整个实践流程有一个详尽的了解。
搭建项目架构
Apache ShardingSphere-JDBC 支持通过 Java 编码和 YAML 属性文件两种方式进行配置,你可以根据项目场景选择合适的方式。
引入Maven依赖
你可以选择单独引入 shardingsphere-jdbc-core 依赖。
<!-- https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc-core -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.4.0</version>
</dependency>
或者,为了更方便地集成到 Spring Boot 项目中,可以通过 Spring Boot Starter 引入相关依赖。
<!-- https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc-core-spring-boot-starter -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.1</version>
</dependency>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>
注意:如果这里报错 The following method did not exist: org.apache.shardingsphere.infra.util.yaml.constructor.ShardingSphereYamlConstructor$1.setCodePointLimit(I)V,可以降低shardingsphere版本号或调整高版本snakeyaml版本。
创建YAML配置文件
ShardingSphere的YAML配置文件遵循一个基础结构:
# JDBC 逻辑库名称。在集群模式中,使用该参数来联通 ShardingSphere-JDBC 与 ShardingSphere-Proxy。
# 默认值:logic_db
databaseName(?):
mode:
dataSources:
rules:
- !FOO_XXX
...
- !BAR_XXX
...
props:
key_1: value_1
key_2: value_2
Spring Boot配置使用ShardingSphere JDBC驱动
在 application.properties 或 application.yml 中配置数据源,使用 ShardingSphere 驱动。
# 配置 DataSource Driver
spring.datasource.driver-class-name=org.apache.shardingsphere.driver.ShardingSphereDriver
# 指定 YAML 配置文件
spring.datasource.url=jdbc:shardingsphere:classpath:xxx.yaml
数据库准备
为了演示分库分表,我们需要创建两个数据库 db_test_01 和 db_test_02。并在每个数据库中创建相同的表结构,包括:user_info(用户表),production(商品表),order(订单表),以及用于分表的 order_item_00 和 order_item_01(订单项表)。
SQL 脚本如下。
# 分别创建两个数据库
CREATE DATABASE `db_test_01` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
CREATE DATABASE `db_test_02` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
# 在两个数据库中都创建以下表
# 创建单表:用户表
create table `user_info` (
`user_id` bigint not null comment '用戶id',
`user_name` varchar(255) comment '用戶姓名',
`user_sex` varchar(255) comment '用戶性別',
`user_age` int(8) not null comment '用戶年齡',
primary key (`user_id`) using btree
) engine = InnoDB character set = utf8mb4 collate = utf8mb4_general_ci row_format = compact;
# 创建单表:商品表
create table `production` (
`production_id` bigint not null comment '商品id',
`production_name` varchar(255) comment '商品名称',
`production_price` int(8) not null comment '商品价格',
primary key (`production_id`) using btree
) engine = InnoDB character set = utf8mb4 collate = utf8mb4_general_ci row_format = compact;
# 创建单表:订单表
create table `order` (
`order_id` bigint not null comment '订单号',
`order_price` int(8) not null comment '订单总金额',
`user_id` bigint not null comment '用戶id',
primary key (`order_id`) using btree
) engine = InnoDB character set = utf8mb4 collate = utf8mb4_general_ci row_format = compact;
# 创建分表:订单项表1
create table `order_item_00` (
`order_info_id` bigint not null comment '订单详情号',
`order_id` bigint not null comment '订单号',
`production_name` varchar(255) comment '商品名称',
`production_price` int(8) not null comment '商品价格',
primary key (`order_info_id`) using btree,
index `key_order_id`(`order_id`) using btree
) engine = InnoDB character set = utf8mb4 collate = utf8mb4_general_ci row_format = compact;
# 创建分表:订单项表2
create table `order_item_01` (
`order_info_id` bigint not null comment '订单详情号',
`order_id` bigint not null comment '订单号',
`production_name` varchar(255) comment '商品名称',
`production_price` int(8) not null comment '商品价格',
primary key (`order_info_id`) using btree,
index `key_order_id`(`order_id`) using btree
) engine = InnoDB character set = utf8mb4 collate = utf8mb4_general_ci row_format = compact;
创建数据库用户
为了方便连接,我们创建一个具有权限的数据库用户。
create user 'sharding'@'%' identified by 'sharding123!@#';
grant all privileges on db_test_01.* to 'sharding'@'%' with grant option;
grant all privileges on db_test_02.* to 'sharding'@'%' with grant option;
flush privileges;
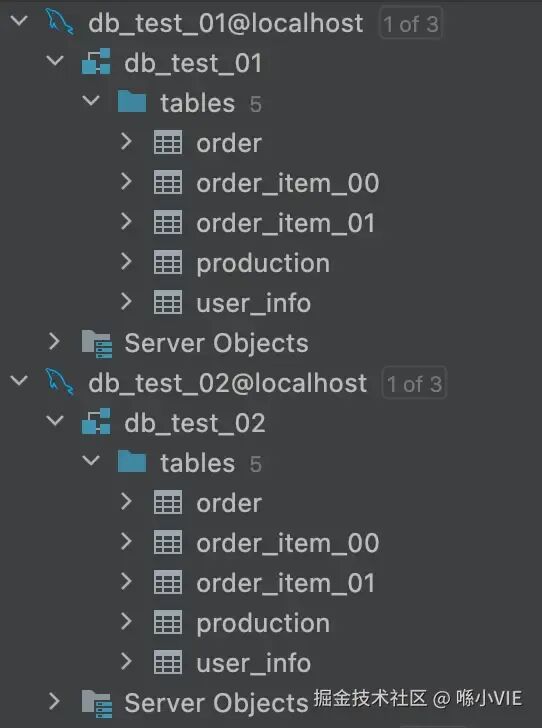
数据库一览
执行完上述脚本后,用于分库分表实践的数据库结构如下所示:
生成代码
使用 MyBatis-Plus 的代码生成器,快速生成 Service、Mapper、Entity 等基础代码。生成的目录结构大致如下:
service
├── UserInfoService.java
├── OrderService.java
├── OrderItemService.java
└── ProductionService.java
impl
├── UserInfoServiceImpl.java
├── OrderServiceImpl.java
├── OrderItemServiceImpl.java
└── ProductionServiceImpl.java
dao
├── UserInfoMapper.java
├── OrderMapper.java
├── OrderItemMapper.java
└── ProductionMapper.java
mapper
├── UserInfoMapper.xml
├── OrderMapper.xml
├── OrderItemMapper.xml
└── ProductionMapper.xml
entity
├── UserInfo.java
├── Order.java
├── OrderItem.java
└── Production.java
分库分表配置
配置多数据源
如果你是通过 Spring Boot Starter 引入的依赖,可以在 application.yml 中配置多个真实数据源。
spring:
shardingsphere:
mode:
# 不配置则默认单机模式
type: Standalone # 运行模式类型。可选配置:Standalone、Cluster
repository:
# 持久化仓库配置
type: JDBC
datasource:
# 配置多个数据源
names: ds0,ds1
# 配置第一个数据源
ds0:
url: jdbc:mysql://localhost:3306/db_test_01?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=true&tinyInt1isBit=false&allowMultiQueries=true
username: sharding
password: sharding123!@#
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
# 配置第二个数据源
ds1:
url: jdbc:mysql://localhost:3306/db_test_02?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=true&tinyInt1isBit=false&allowMultiQueries=true
username: sharding
password: sharding123!@#
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
多数据源可用性测试
在配置分片规则前,先简单测试一下数据源连接是否正常。我们先配置一个最简单的分片规则,只指定一个真实表。
spring:
shardingsphere:
rules: # 规则配置
sharding: # 数据分片规则
tables: # 配置所有分片表
order_item: # 逻辑表
actual-data-nodes: ds0.order_item_00 # 声明商品表所在的真实数据节点(这里先显式声明一个节点测试)
props:
sql-show: true # 日志显示具体的SQL
编写一个简单的测试接口,插入一条数据。
@RestController
@RequestMapping("/admin-service")
public class AdminTestController {
@Resource
private OrderItemService orderItemService;
@PostMapping("/test")
public void test() {
OrderItem orderItem = new OrderItem();
orderItem.setOrderInfoId(1L);
orderItem.setOrderId(1L);
orderItem.setProductionName("商品1");
orderItem.setProductionPrice(9);
orderItemService.save(orderItem);
}
}
调用接口后,查看控制台打印的 SQL 日志。可以看到 ShardingSphere 将我们编写的“逻辑SQL”正确地路由到了“实际SQL”并执行。
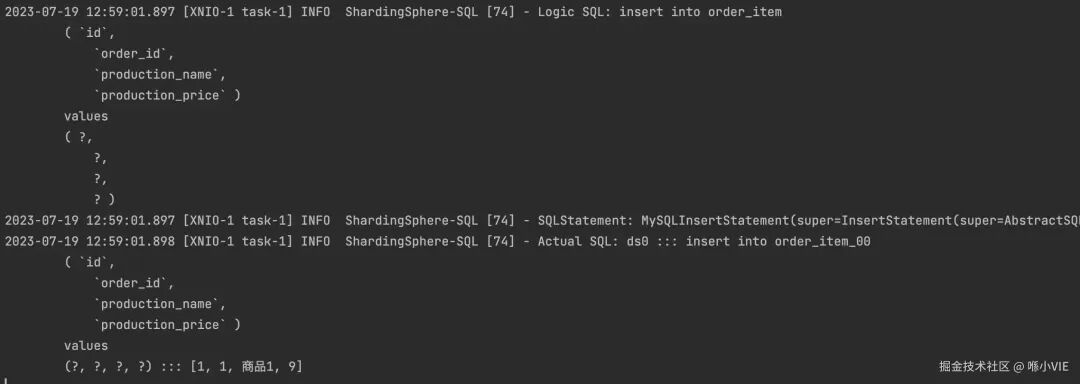
登录 db_test_01.order_item_00 表查看数据,验证分库分表的基础功能已成功应用。
mysql> select * from db_test_01.order_item_00;
+----+----------+-----------------+------------------+--------+
| id | order_id | production_name | production_price | is_del |
+----+----------+-----------------+------------------+--------+
| 1 | 1 | 商品1 | 9 | 0 |
+----+----------+-----------------+------------------+--------+
1 row in set (0.00 sec)
配置分库规则
现在,我们来配置真正的分库规则。我们打算根据 id 字段的奇偶性,将数据分别存入 ds0 和 ds1 两个数据源。
spring:
shardingsphere:
rules: # 规则配置
sharding: # 数据分片规则
tables: # 配置所有分片表
order_item: # 逻辑表
actual-data-nodes: ds$->{0..1}.order_item_00 # 声明表所在的真实数据节点(这里先显式声明一个节点测试)
database-strategy: # 分库策略
standard:
sharding-column: id # 分片列名称
sharding-algorithm-name: db-inline-mod # 分片算法名称
# 分片算法配置
sharding-algorithms:
db-inline-mod: # 分片算法名称
type: INLINE # 分片算法类型
props: # 分片算法属性配置
algorithm-expression: ds$->{id % 2}
props:
sql-show: true
更新测试代码,循环插入10条商品数据,id 从10到19。
@RestController
@RequestMapping("/admin-service")
public class AdminTestController {
@Resource
private OrderItemService orderItemService;
@PostMapping("/test")
public void test() {
for (long i = 10; i < 20; i++) {
OrderItem orderItem = new OrderItem();
orderItem.setId(i);
orderItem.setOrderId(1L);
orderItem.setProductionName("商品" + i);
orderItem.setProductionPrice(9);
orderItemService.save(orderItem);
}
}
}
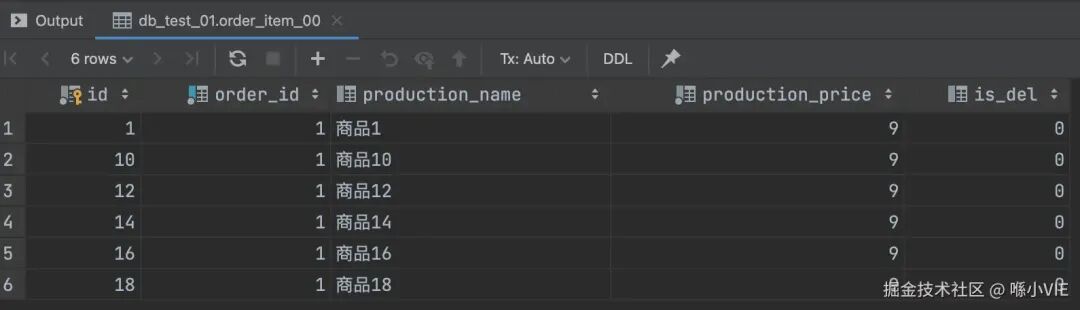
执行后,查看 db_test_01.order_item_00(ds0)的数据,id 为偶数(10,12,14,16,18)的记录被插入至此。
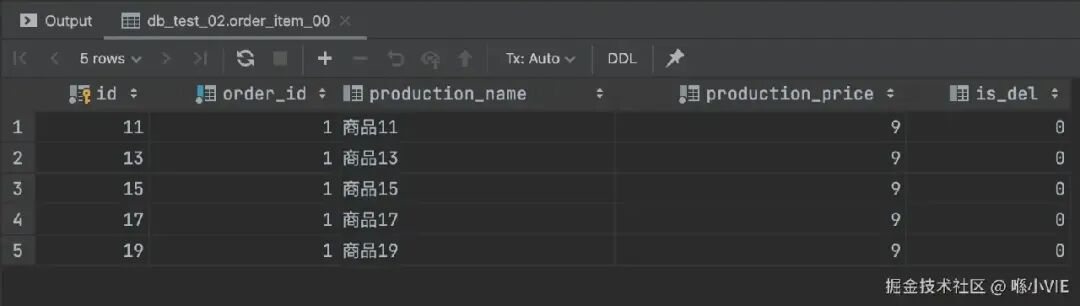
查看 db_test_02.order_item_00(ds1)的数据,id 为奇数(11,13,15,17,19)的记录被插入至此。分库策略生效!
小提示:对于取模这种常用分片算法,ShardingSphere 提供了内置的 MOD 类型,配置更简洁:
sharding-algorithms:
db-inline-mod:
type: MOD
props:
sharding-count: 2
配置分表规则
现在我们在分库的基础上,增加分表规则。目标是将数据进一步分散到 order_item_00 和 order_item_01 两张表中。我们选择 production_name 作为分表的分片键,并使用 HASH_MOD 算法(先计算HASH值再取模)。
spring:
shardingsphere:
rules:
sharding:
tables:
order_item:
actual-data-nodes: ds$->{0..1}.order_item_0$->{0..1} # 真实节点:两个库,每个库两张表
database-strategy:
standard:
sharding-column: id
sharding-algorithm-name: db-inline
table-strategy: # 分表策略
standard:
sharding-column: production_name
sharding-algorithm-name: tb-key-hash
sharding-algorithms:
db-inline:
type: INLINE
props:
algorithm-expression: ds$->{id % 2}
tb-key-hash:
type: HASH_MOD
props:
sharding-count: 2
更新测试代码,循环插入20条数据,production_name 分别为“商品1abc”到“商品20abc”。
@RestController
@RequestMapping("/admin-service")
public class AdminTestController {
@Resource
private OrderItemService orderItemService;
@PostMapping("/test")
public void test() {
for (long i = 1; i <= 20; i++) {
OrderItem orderItem = new OrderItem();
orderItem.setId(i);
orderItem.setOrderId(1L);
orderItem.setProductionName("商品" + i + "abc");
orderItem.setProductionPrice(9);
orderItemService.save(orderItem);
}
}
}
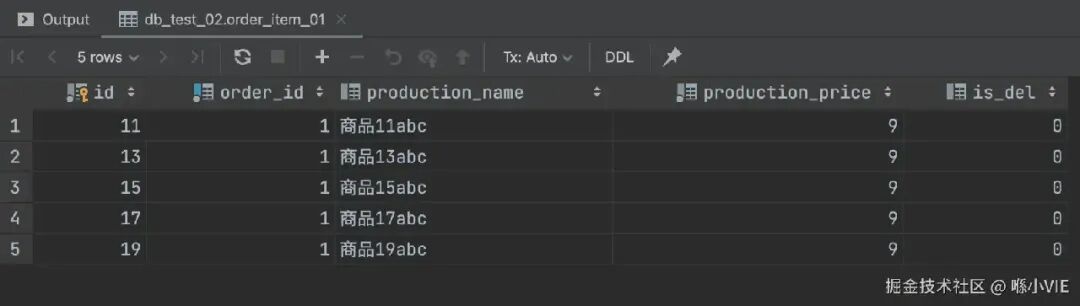
执行后,数据被均匀地分到了四个物理表中:
db_test_01.order_item_00: id为偶数,且根据production_name哈希分配到_00表。
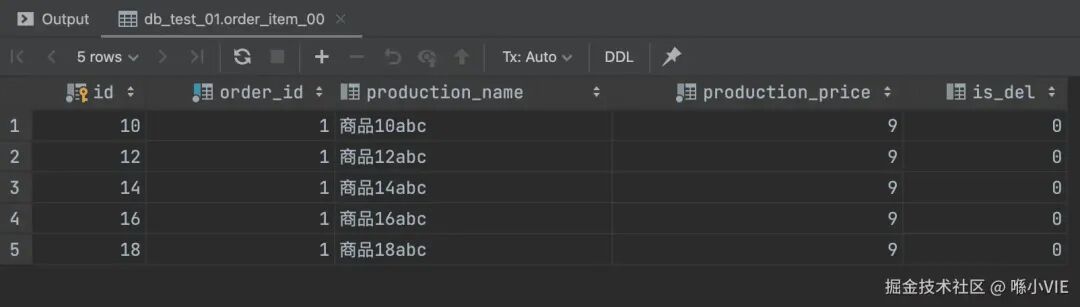
db_test_01.order_item_01: id为偶数,且根据production_name哈希分配到_01表。
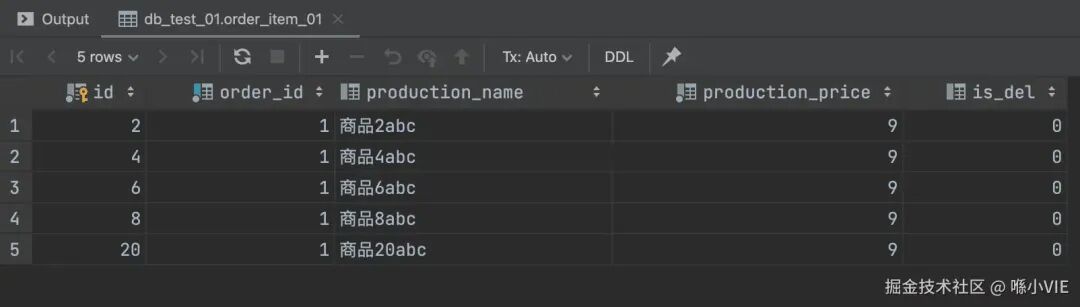
db_test_02.order_item_00: id为奇数,且根据production_name哈希分配到_00表。

db_test_02.order_item_01: id为奇数,且根据production_name哈希分配到_01表。
至此,一个同时进行分库和分表的配置就完成了。
分库分表中的关键点
分表策略的分片键选择
在前面的例子中,我们对 order_item 表的分表策略使用了 production_name 作为分片键。这带来一个问题:当我们以 order_item.id 作为条件进行查询时,会发生什么?
@PostMapping("/test")
public void test() {
orderItemService.findById(1L); // 根据id查询
}
查看SQL日志你会发现,实际的查询语句使用了 UNION ALL,同时查询了 order_item_00 和 order_item_01 两张表。
2023-07-19 20:03:40.031 [XNIO-1 task-1] INFO ShardingSphere-SQL [74] - Logic SQL: select `id`, `order_id`, `production_name`, `production_price`, `is_del` from order_item where `id` = ? and is_del = 0
2023-07-19 20:03:40.032 [XNIO-1 task-1] INFO ShardingSphere-SQL [74] - SQLStatement: MySQLSelectStatement
2023-07-19 20:03:40.032 [XNIO-1 task-1] INFO ShardingSphere-SQL [74] - Actual SQL: ds1 ::: select `id`, `order_id`, `production_name`, `production_price`, `is_del` from order_item_00 where `id` = ? and is_del = 0 UNION ALL select `id`, `order_id`, `production_name`, `production_price`, `is_del` from order_item_01 where `id` = ? and is_del = 0 ::: [1, 1]
这是因为查询条件 id 并非分片键 production_name,ShardingSphere 无法根据 id=1 这个条件计算出数据具体位于哪一张分表,因此只能向所有分表发起查询,这会导致全表路由,性能低下。因此,在选择分片键时,需要优先考虑最常用的查询条件,这对于 分布式系统 的查询性能至关重要。
分布式序列算法
前面的例子中,我们手动设置了主键 id 的值。在实际业务中,我们通常希望主键是自动生成的。但在分库分表环境下,数据库自增ID会导致全局ID冲突。常见的解决方案是使用分布式ID生成算法,如Snowflake(雪花算法)。
在 ShardingSphere 中配置雪花算法生成主键:
spring:
shardingsphere:
rules:
sharding:
tables:
order_item:
actual-data-nodes: ds$->{0..1}.order_item_0$->{0..1}
key-generate-strategy: # 分布式序列策略
column: id # 自增列名称
keyGeneratorName: global-id # 分布式序列算法名称
# ... 其他分库分表策略
# 分布式序列算法配置
key-generators:
global-id:
type: SNOWFLAKE # 分布式序列算法类型
props:
worker-id: 1 # 工作机器唯一标识
更新测试代码,不再手动设置 id。
@PostMapping("/test")
public void test() {
for (long i = 1; i <= 20; i++) {
OrderItem orderItem = new OrderItem();
// orderItem.setId(i); // 不再手动设置ID
orderItem.setOrderId(1L);
orderItem.setProductionName("商品" + i + "abc");
orderItem.setProductionPrice(9);
orderItemService.save(orderItem);
}
}
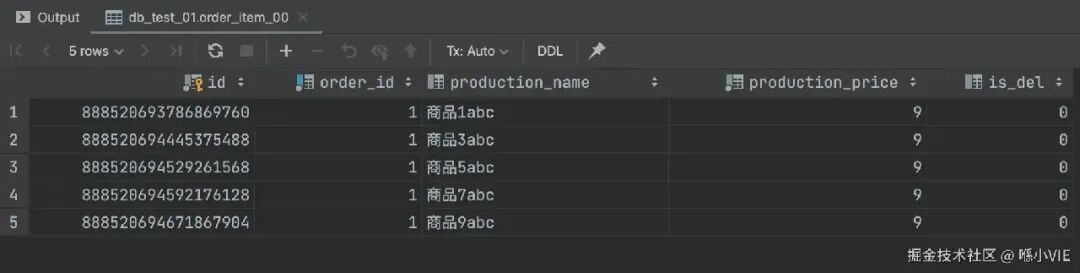
执行后,查看数据,id 字段变成了Snowflake算法生成的全局唯一长整型数字。
绑定表配置
在我们的表设计中,order 表与 order_item 表存在主外键关系(逻辑上)。在分库后,我们必须确保关联的数据(例如同一个订单及其所有订单项)被存储在同一个数据库中,以避免跨库关联查询。ShardingSphere 通过“绑定表”机制来解决这个问题。
绑定表要求参与绑定的多张表,其分库和分表策略必须完全一致(使用相同的分片算法和分片键)。
配置示例:
spring:
shardingsphere:
rules:
sharding:
tables:
order: # 订单表逻辑表
actual-data-nodes: ds$->{0..1}.order
database-strategy:
standard:
sharding-column: id # 按订单ID分库
sharding-algorithm-name: db-mod
order_item: # 订单项表逻辑表
actual-data-nodes: ds$->{0..1}.order_item
database-strategy:
standard:
sharding-column: order_id # 按所属订单ID分库,确保与父表在同一库
sharding-algorithm-name: db-mod
binding-tables: # 声明绑定表关系
- order,order_item
sharding-algorithms:
db-mod:
type: MOD
props:
sharding-count: 2
这样配置后,当进行 order 和 order_item 的关联查询时,ShardingSphere 只会从对应的单个库中进行查询,而不会产生笛卡尔积关联,极大提升了关联查询的效率。
总结
至此,我们就完成了 Spring Boot 整合 ShardingSphere 实现 MySQL 分库分表的完整实践。商品订单场景的分库分表是一个非常典型的案例,涵盖了从环境搭建、配置编写到核心概念落地的全过程。
当然,实际业务中可能会遇到更复杂的分片需求,例如按时间范围分片。但万变不离其宗,只要理解了分片算法的原理和配置方法,结合 ShardingSphere 丰富的内置算法和扩展能力,这些需求都能得到很好的解决。
希望这篇实战指南能帮助你更深入地理解分库分表技术,并顺利应用到自己的项目中。如果在实践中遇到问题,欢迎到云栈社区与其他开发者交流探讨。
 发表于 2026-2-25 04:09:38
|
查看: 177|
回复: 0
发表于 2026-2-25 04:09:38
|
查看: 177|
回复: 0
