
当通用计算芯片的军备竞赛愈演愈烈时,一种“反常识”的硬件路径正悄然浮现。它不再追求极致的通用性,转而拥抱极致的专用化。这就是Taalas公司带来的颠覆性思路:将大语言模型直接“固化”在芯片的物理结构中,而非作为软件在通用硬件上运行。
这种被称为“硬连线(Hard-Wired)”或“硬核模型”的方案,拿到了Meta开源的Llama 3.1 8B模型,并为其定制了一款专用硅片(HC1)。在这块芯片上,模型的权重本身就是电路物理结构的一部分,无需在运行时加载。结果令人震惊:在Llama 8B模型上跑出了17000 tokens/秒的推理速度。
这一速度不仅是传统GPU的上百倍,更是以速度著称的Cerebras晶圆级芯片的10倍以上。它快到让响应几乎成为“零延迟”事件。
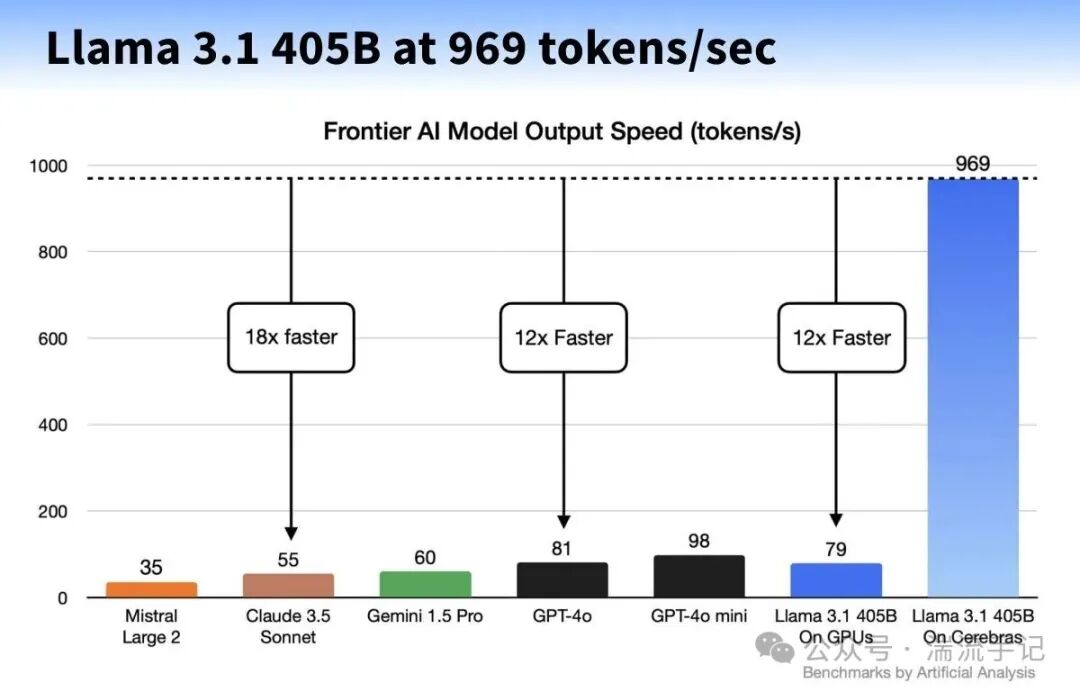
图表显示了Llama 3.1 405B在Cerebras系统上达到969 tokens/s的惊人速度,但请注意,这仅是Taalas为8B模型实现速度的约1/17。这不仅是一场速度竞赛,更是对传统算力架构的一次根本性质疑。
拆掉“内存墙”:冯·诺依曼架构的阿喀琉斯之踵
为什么传统架构难以企及这样的速度?核心瓶颈并非计算能力本身,而是数据的“搬运”效率。
在经典的冯·诺依曼架构中,计算单元(如GPU核心)和存储单元(如显存)是物理分离的。每次计算都需要将数据从存储单元搬到计算单元,结果再搬回去。这个“数据往返跑”的过程产生了巨大的延迟和能耗,也就是著名的“内存墙(Memory Wall)”。
Taalas的方案本质上是存算一体(Compute-in-Memory)。它将逻辑门和存储器紧密集成在同一片硅基底上,消除了数据搬运的需求。模型权重被物理地“焊接”在芯片内部,计算直接在数据存放的位置发生。这好比让厨师(计算单元)直接在装满食材(数据)的厨房(存储单元)里工作,而非在遥远的餐厅和冷库间疲于奔命。
极致的成本账本:从“喝依云”到“呼吸空气”
技术突破最终要转化为商业价值。那么,这种专用硬件的成本优势有多大?
根据已披露的测试数据,在Taalas的硬核架构下,Llama 3.1 8B模型的推理成本被压缩至约0.75美分/百万token。相比之下,在同等条件下使用传统高端通用GPU,这一成本通常在20到49美分之间。
这意味着成本降低了数十倍。对于大规模部署AI服务的企业而言,这种成本差异将彻底改变商业模型的可行性。它使得AI推理从一项“昂贵服务”转变为近乎“基础设施”级别的低成本操作。
这种成本优势源于极致的“晶体管效率”。当你使用一块强大的通用GPU运行一个相对较小的8B模型时,芯片上大量的浮点运算单元、张量核心和复杂的控制逻辑实际上处于闲置状态。你为“可能用到的通用能力”支付了高昂溢价。而专用芯片的每一个晶体管都为了执行特定模型的计算而设计,几乎没有浪费。
当然,追求极致密度与速度并非没有代价。在初代HC1芯片上,为优化性能采用了一些非标准的低精度格式,可能导致输出质量相比标准GPU有轻微下降。不过,Taalas已宣布预计在2026年底部署的第二代硅片(HC2)中将采用标准的4-bit浮点格式(FP4),以在保持高性能的同时,确保模型输出质量。
专用化的未来:从“云端API”到“实体硅片”的想象
一个自然的疑问是:模型迭代如此迅速,将特定模型物理固化在芯片上,是否会导致硬件迅速过时,成为“电子垃圾”?
这引出了一个关于未来AI部署形态的有趣思考。或许,在众多嵌入式、边缘和特定场景中,我们并不总是需要最新、最全能的大语言模型。例如,智能家居中的语音助手、工业流水线上的质检系统、车载基础交互模块,它们需要一个稳定、高效、低功耗且成本极低的“大脑”,而非一个时刻追逐热点的“全能学者”。
沿着Taalas的逻辑推演,未来的AI服务可能不再仅仅是一串云端API调用代码,而是一片片实体的、即插即用的“智能硅片”。科技巨头或云服务商可能会直接销售这些“焊死”了经优化、验证的特定模型的专用硬件。用户将其插入设备,即可获得终身免网络、瞬间响应、超低功耗的专属AI能力。这是一种“一次性智能”或“固化智能”的范式,它反主流,却可能是AI真正下沉并融入物理世界基础设施的必然路径之一。
结语:在“大力出奇迹”之外
过去几年,我们见证了通过堆叠成千上万张GPU来训练庞然大物的“暴力美学”。然而,Taalas的路径提醒我们,在追求通用化的“加法”之外,还存在通过极致专用化做“减法”的智慧。它用一块小小的专用芯片,实现了对传统计算单元架构的效率“降维打击”。
这不仅仅是技术的革新,更是一种思维模式的转变。当整个行业都在试图建造更大的船以征服海洋时,有人选择直接冻结海面,滑行而过。这种追求极致效率的“固执的诗意”,或许正是推动下一次算力革命的关键火花。
技术的讨论永无止境,关于效率、通用性与成本的权衡,也欢迎在云栈社区的人工智能板块继续深入交流。从芯片底层的计算机基础原理,到顶层的应用部署,每一次思维碰撞都可能催生新的洞见。
参考资料:
- Taalas Promises 10X Faster AI With Hard-Wired Llama Chip - VKTR
- Taalas Launches Hardcore Chip With ‘Insane’ AI Inference Performance - Forbes
- Taalas Is Running AI at 17000 Tokens Per Second - YouTube
 发表于 2026-2-25 04:25:22
|
查看: 188|
回复: 0
发表于 2026-2-25 04:25:22
|
查看: 188|
回复: 0
