只需几行 Python 代码——配合简单的配置字典,即可将训练好的神经网络模型一键部署到 FPGA,实现极致低延迟推理。hls4ml 会自动处理量化、并行策略和硬件映射,让你无需手动编写硬件代码。
近年来,深度学习模型在计算机视觉、自然语言处理、高能物理等领域的应用呈爆炸式增长。然而,随着模型规模不断扩大,对计算资源和功耗的要求也越来越高。
特别是在实时系统如自动驾驶、粒子对撞机触发系统中,CPU 和 GPU 往往难以满足严格的延迟约束。FPGA 凭借其可重构、低延迟、高能效的特点,成为加速深度学习推理的理想平台。但传统的 FPGA 开发流程复杂,需要硬件描述语言(如 Verilog/VHDL)和丰富的硬件知识,这大大限制了其普及。

有没有一种工具,能够像 TensorFlow 或 PyTorch 那样,让我们用高级语言定义模型,然后自动生成高效的 FPGA 硬件实现?
答案是肯定的——hls4ml 正是这样一个开源平台。
hls4ml 由 CERN、ETH Zurich、加州理工等机构的研究者联合开发,旨在将深度学习模型从主流框架(Keras、PyTorch、ONNX)自动转换为高层次综合(HLS)代码,进而部署到 FPGA 或 ASIC 上。
自 2018 年首次发布以来,hls4ml 已经发展成为一个功能强大、生态丰富的工具,广泛应用于高能物理、自动驾驶、生物医学、量子计算等领域。
本文将深入解读 hls4ml,了解其核心设计、创新点、硬件实现细节,以及如何利用它实现模型-硬件协同设计,从而为你的人工智能项目带来新的硬件加速可能。
一、为什么需要 hls4ml?
在实时系统中,延迟往往是首要考虑因素。例如,在欧洲核子研究中心(CERN)的大型强子对撞机(LHC)实验中,探测器每秒产生约 100 TB 的数据,而触发系统必须在10 微秒内决定是否保留某个碰撞事件。传统的 CPU 处理无法满足这一要求,因此 FPGA 成为必然选择。
然而,传统 FPGA 开发面临两大痛点:
- 开发门槛高:需要掌握硬件描述语言,理解时序、流水线、资源约束等概念。
- 模型适配难:深度学习框架(如 PyTorch、TensorFlow)主要针对 CPU/GPU 优化,其模型无法直接映射到 FPGA。
hls4ml 的目标就是桥接深度学习框架与 FPGA 硬件,让算法工程师无需成为硬件专家,也能享受 FPGA 的低延迟红利。
二、hls4ml 整体架构:模块化设计成就灵活性
hls4ml 的设计借鉴了现代编译器的思想,将整个流程分为前端、中间表示(IR)、优化器和后端四个层次,如图 1 所示。这种模块化设计使其能够灵活支持多种深度学习框架和硬件目标。
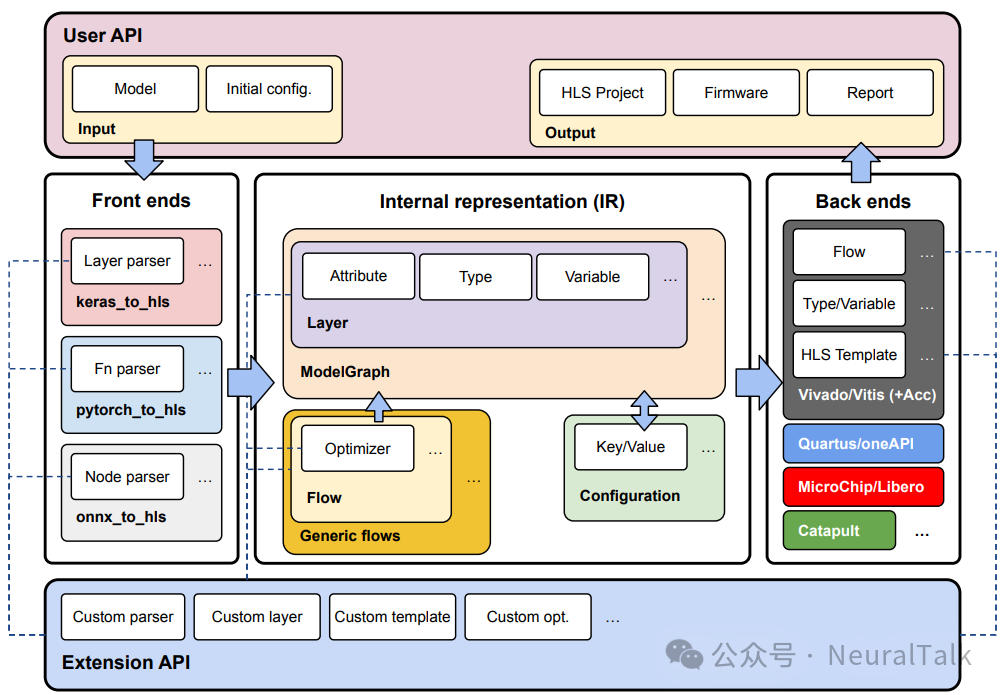
2.1 前端:支持主流深度学习框架
hls4ml 的前端负责将训练好的模型转换为内部表示。目前支持:
- Keras 2/3:包括原生 Keras 以及量化库 QKeras、HGQ。
- PyTorch:通过跟踪或脚本化模型转换为 IR。
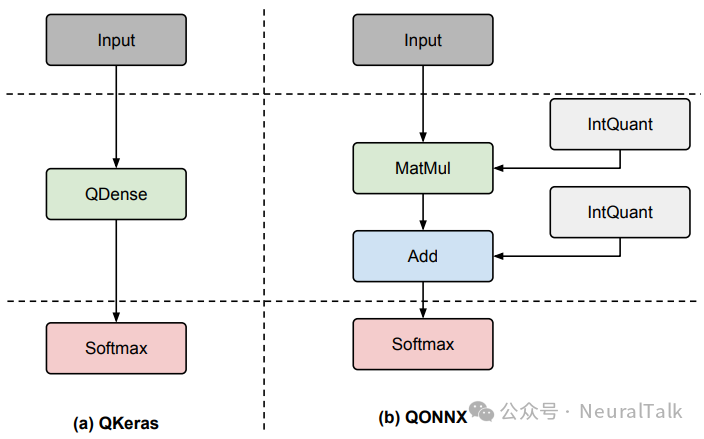
- ONNX/QONNX:开放神经网络交换格式,支持跨框架模型。
- Brevitas:PyTorch 的量化库。
对于每个框架,hls4ml 都有一组层处理器(layer handlers),负责解析特定层(如 Conv2D、Dense)的参数和权重,并将其转换为统一的 IR 节点。所有权重都被转换为 NumPy 数组,消除框架特异性。
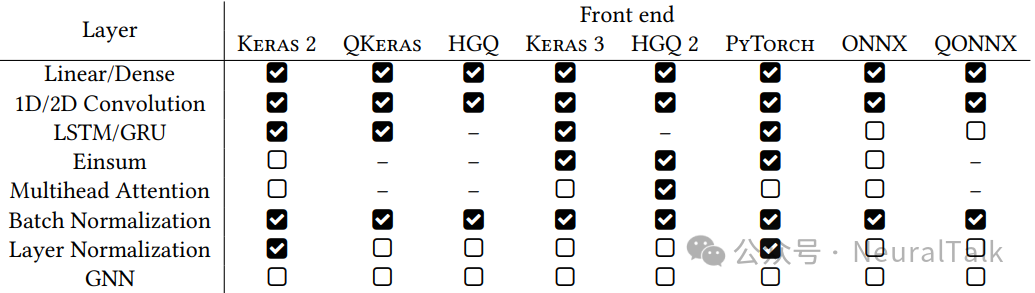
表 1 展示了各前端对不同层的支持情况。可以看出,Keras 和 ONNX 前端支持最全面,而 PyTorch 前端正在快速发展中。
2.2 中间表示(IR)与优化器
所有前端转换后的模型都统一为模型图(ModelGraph),其中包含节点(层)、边(数据流)和配置信息(如量化参数、并行度)。
IR 的设计保证了与具体框架的解耦,使得后续优化和后端生成可以复用。优化器(optimizers)是一系列对 IR 进行变换的 pass,例如:
- 精度传播:根据输入/输出精度自动推导中间累加器的位宽,防止溢出。
- 算子融合:将连续的 Conv2D+BatchNorm+ReLU 合并为一个等效节点,减少流水线级数。
- 常量折叠:在编译时计算所有可确定的常量表达式,减少硬件开销。
- 模板实例化:根据用户配置(如策略、重用因子)将节点映射到具体的 HLS 模板。
这些优化器可以按需组合成优化流(optimizer flows),不同后端可以选择不同的优化流。这种基于IR的优化框架,本身也体现了现代编译器的设计思想。
2.3 后端:多供应商 HLS 编译器支持
hls4ml 的后端负责将优化后的 IR 转换为特定 HLS 编译器的代码,并生成配套的脚本和测试平台。目前支持:
- AMD Vitis/Vivado HLS:最成熟的后端,支持所有策略(Latency、Resource、DA)和数据流类型。
- Intel oneAPI/Quartus:支持 io_parallel 和 io_stream,使用资源优化策略。
- Siemens Catapult HLS:面向 ASIC 设计,支持层次化合成,便于管理大规模设计。
每个后端都有一套HLS 模板,这些模板是手动优化的 C++代码,实现了特定层的功能(如矩阵向量乘、激活函数)。模板中插入了 HLS pragma(如 #pragma HLS unroll、#pragma HLS pipeline)来指导综合工具实现并行和流水线。
表 2 展示了各后端对不同层的支持,可见核心层都已覆盖。

三、硬件实现的核心:常数矩阵向量乘(CMVM)
神经网络的计算核心是矩阵向量乘,在 FPGA 中,权重是常数(训练后固定),因此称为常数矩阵向量乘(CMVM)。
hls4ml 对 CMVM 提供了三种实现策略,分别面向不同的优化目标。
3.1 三种实现策略
Latency 策略:追求极致低延迟
将权重直接嵌入乘法器电路,循环完全展开,允许 HLS 编译器进行激进优化(如消除零乘、常数乘法转换为移位加)。
重用因子(Reuse Factor,RF)是 HLS(高层次综合)中用于权衡硬件资源与计算延迟的关键参数。其定义为:
RF = (输入维度 × 输出维度) / (每周期乘法次数)
RF 反映了计算任务在时间维度上的“复用程度”:RF 越大,表示单位硬件单元被反复使用更多次,从而减少并行乘法器数量,节省 FPGA 资源;但代价是运算周期数增加,导致启动间隔(Initiation Interval, II)变大,整体延迟上升。
例如,对 64×128 矩阵乘法——共 8192 次乘法:
- 当 RF=1,每周期执行 8192 次乘法 → 全并行,延迟最低,资源消耗最高;
- 当 RF=16,每周期执行 512 次乘法 → 资源减少约 16 倍,但延迟增至约 16 倍;
- 当 RF=64,每周期执行 128 次乘法 → 资源进一步减少,延迟进一步增加。
因此,RF 是资源-性能折中的直接调控 knob,需根据目标平台资源约束与实时性要求合理选取。
Resource 策略:资源优先
将权重存储在 BRAM 中,通过显式状态机控制乘法的调度。
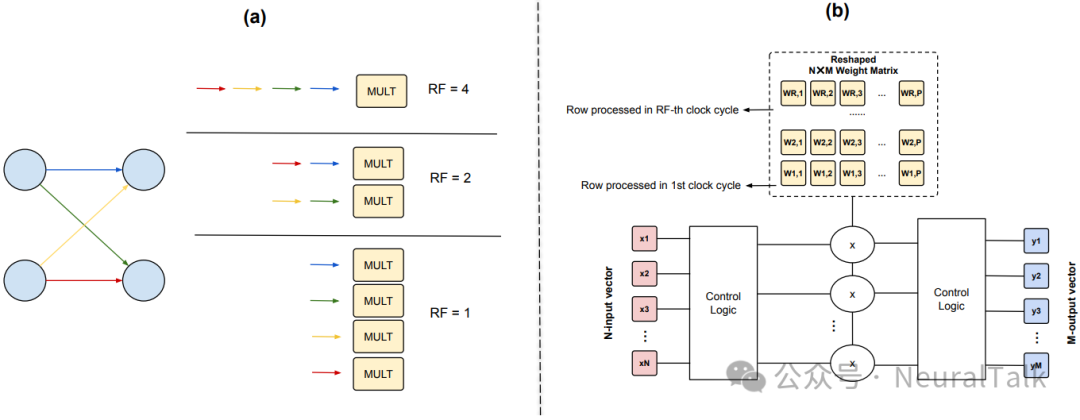
如图 3a 所示,每周期从 BRAM 中读取 RF 个权重,送入 RF 个乘法器并行计算,经过 RF 个周期完成所有乘法。这种策略适合大模型,因为循环不展开,资源可控。RF 直接决定了乘法器数量,从而平衡资源与吞吐量。
分布式算术(DA)策略:消除乘法器
利用 DA4ML 库将 CMVM 转换为仅由加法器和移位寄存器组成的网络,如图 3b 右侧。
DA(Distributed Arithmetic)策略通过查表法实现乘加运算,特别适用于权重稀疏或低比特(如1-bit、2-bit)的模型。由于无需传统乘法器,它能完全规避 DSP 资源的使用,并显著减少 LUT 消耗,提升 FPGA 资源效率。
但 DA 策略也有其局限性:
- 依赖预计算的查找表(LUT),要求内层循环(如点积计算)完全展开,导致硬件面积随向量长度线性增长;
- 同时不支持寄存器级流水(
#pragma HLS pipeline),丧失时序优化空间。
因此,DA 仅适用于中等规模矩阵如 512×512 以内,在大规模矩阵场景下易引发 LUT 资源爆炸或频率下降时序无法收敛,此时应优先考虑 Latency 或 Resource 策略。
3.2 并行度控制:重用因子(RF)与并行因子(PF)
在 hls4ml 中,并行因子(Parallelization Factor, PF) 是用于调控层内跨通道并行度的关键参数。
以卷积层为例,其经 im2col 变换后被分解为多个独立的向量-矩阵乘法(CMVM),每个对应一个输出通道。PF 即指定同一时刻并行执行的 CMVM 数量。
- 增大 PF 可显著提升吞吐率、降低单层延迟,但会线性增加 FPGA 上的逻辑资源(如 DSP 和 BRAM)占用;
- 反之,较小的 PF 节省资源,却以牺牲性能为代价。
PF 与 RF 独立配置:RF 控制单个 CMVM 内部的乘法复用,PF 控制多个 CMVM 之间的并行。这种分层并行机制使 hls4ml 能灵活适配不同硬件平台,在资源受限边缘设备与高性能加速卡间取得平衡。
3.3 激活函数的实现
对于 ReLU 等分段线性函数,hls4ml 直接使用比较器和多路选择器实现。
对于 tanh、sigmoid 等非线性函数,则采用查找表(LUT),在编译时预先计算所有可能的输出值——根据输入精度。查找表可以存储在 BRAM 或 LUTRAM 中,确保单周期访问。经验表明,2048 条目的查找表已能提供足够精度,且资源开销极小。
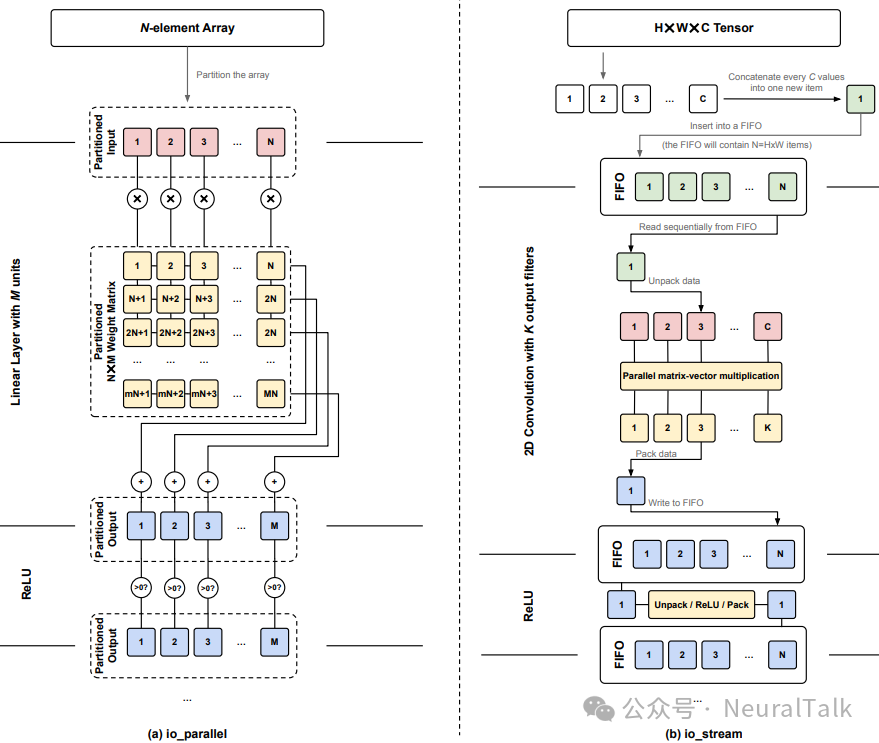
3.4 数据流类型:io_parallel vs io_stream
hls4ml 支持两种层间数据传输方式:
- io_parallel:层与层直接连线,输出立即作为下一层输入。适合小模型,延迟最低。
- io_stream:通过 FIFO 缓冲层间数据。适合大模型,当上下游吞吐率不匹配时,FIFO 可以平滑数据流。hls4ml 还提供 FIFO 深度优化器,通过 RTL 仿真确定每个 FIFO 的最大占用,从而设置最小深度,避免资源浪费。
四、量化与协同设计工具
低精度量化是 FPGA 加速的关键。hls4ml 与多个量化训练库深度集成,并提供了硬件感知的优化工具。
4.1 QKeras:Keras 的量化扩展
QKeras 是 Google 开发的开源库,提供与 Keras 兼容的量化层(如 QDense、QConv2D)。它支持固定点整数、二元(Binary,二值)、2 的幂三种量化类型,并允许逐层指定位宽。AutoQKeras 可以自动搜索最优量化配置,满足给定的模型大小和精度约束。
4.2 HGQ:高粒度量化
HGQ(High-Granularity Quantization)是一种新颖的量化训练方法,由论文作者之一 Chang Sun 等人提出。其核心思想是对每个权重和激活单独学习量化位宽,从而实现极细粒度的压缩。
在训练过程中,HGQ 引入可微分的量化器,并将资源消耗(以有效位操作数 EBOPs 为度量)作为正则项加入损失函数,通过超参数 β 控制精度与资源的权衡。
实验表明,HGQ 结合 hls4ml 的 Latency 策略,可以将 LUT 消耗降低 50%~95%,DSP 消耗降低 50%~100%,且几乎不损失精度,具体见表 3。
4.3 DA4ML:分布式算术优化
DA4ML 是一个独立的库,专门用于优化 CMVM 的加法器网络。它接收权重矩阵,通过启发式算法如公共子表达式消除,生成最优的移位加网络,从而完全消除乘法器。
对于 HGQ 训练的高稀疏模型,DA4ML 可以进一步减少约 1/3 的 LUT 消耗,且输出结果与定点实现完全一致(bit-exact)。
4.4 DSP/BRAM 感知剪枝
传统的剪枝通常以权重稀疏度为目标,但稀疏度并不直接对应 FPGA 资源节省。hls4ml 提供了一种硬件感知剪枝算法,将权重分组映射到具体的 DSP 或 BRAM 单元。
例如,一个 DSP 可能处理一组权重,如果该组所有权重被剪枝,则整个 DSP 可被移除。该算法将问题建模为背包问题,在给定资源预算下选择保留权重,最大化精度。在多个案例中,DSP 消耗减少了 2.2 倍到 12.2 倍。
4.5 符号回归与代理模型
hls4ml 还集成了符号回归(Symbolic Regression)接口,可以将黑盒函数(如物理过程的响应)表示为简洁的数学表达式(如 sin、exp 的组合),然后通过 LUT 高效实现。
此外,社区开发了rule4ml和lui-GNN等代理模型,可以快速预测 hls4ml 设计的资源消耗和延迟,避免长时间的综合等待,助力设计空间探索。这类硬件性能建模本身就是计算机基础与AI交叉的有趣实践。
五、与现有工作的对比
FPGA 上的神经网络加速器可分为两大类:覆盖层(overlay)架构和定制硬件生成器。
- 覆盖层(如 AMD Vitis AI、Intel FPGA AI Suite)实现固定的微架构,通过软件调度执行不同模型,灵活性高但效率略低。
- 定制硬件生成器(如 hls4ml、FINN、MASE)则针对每个模型生成专用数据流电路,效率极致但编译时间较长。
表 10 对比了主流定制硬件生成工具,hls4ml 在以下方面具有独特优势:
- 多框架支持:支持 Keras、PyTorch、ONNX,而 FINN 只支持 Brevitas/QONNX,MASE 只支持 PyTorch。
- 多后端支持:同时支持 AMD、Intel、Siemens EDA,且可扩展至其他 HLS 工具。
- 量化灵活性:支持任意精度(不仅仅是 INT8 或 FP16),可与 QKeras、HGQ、Brevitas 等多种量化库配合。
- 活跃的社区:作为开源实战项目的典范,持续维护,定期举办教程和研讨会。
六、性能评估:从 Jet Tagger 到 MNIST
实验提供了多个基准测试的评估结果,涵盖高能物理、计算机视觉等任务。
6.1 高能物理 Jet Tagger
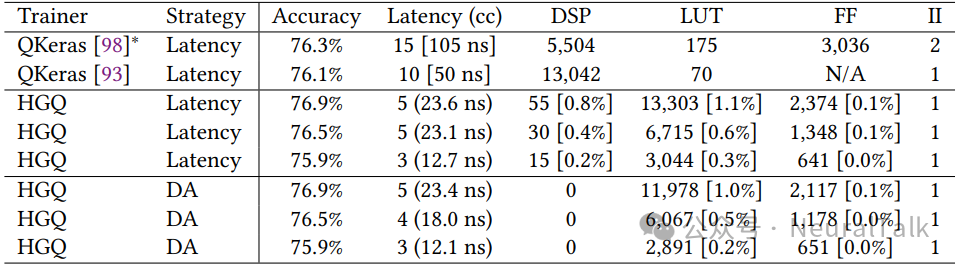
任务:将喷注(jet)分为 5 类,输入为 16 个高能特征。模型为多层感知机(MLP)。对比 QKeras 和 HGQ 训练,以及 Latency 和 DA 策略。
| 训练库 |
策略 |
精度 |
延迟(周期) |
DSP |
LUT |
FF |
| QKeras |
Latency |
76.1% |
10 |
13,042 |
70 |
N/A |
| HGQ |
Latency |
76.9% |
5 |
55 |
13,303 |
2,374 |
| HGQ |
DA |
76.9% |
5 |
0 |
11,978 |
2,117 |
上表显示,HGQ 训练+DA 策略在几乎不损失精度的情况下,将 DSP 消耗降为 0,LUT 消耗也比 QKeras+Latency 降低一个数量级。
注:DA 策略之所以能实现零 DSP,是因为它利用 HGQ 训练出的稀疏、低位宽权重,将乘法运算替换为移位加操作,这里是通过 DA4ML 生成的加法器网络实现,从而完全避免了 DSP 的使用,同时保持输出结果与定点实现比特级一致。后面其他几张表也是一样。
6.2 街景门牌号(SVHN)分类
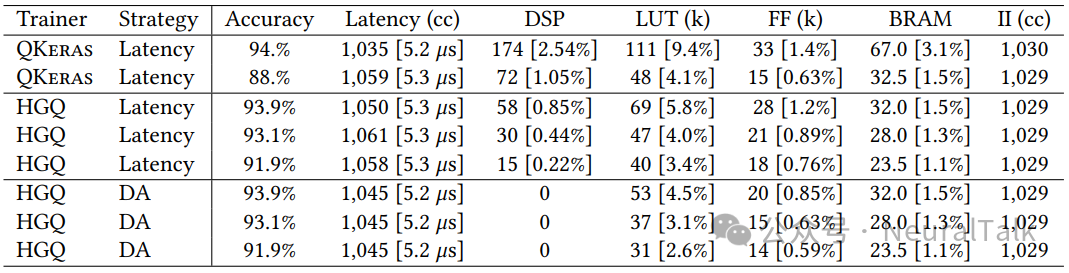
任务:CNN 分类彩色数字图像。对比 QKeras 和 HGQ。表 7 显示,HGQ+DA 同样实现了零 DSP,LUT 和 FF 大幅下降。
6.3 基于粒子的 Jet Tagger
更复杂的任务:输入为每个喷注中最多 64 个粒子的 16 维特征,模型为 MLP-Mixer。表 8 显示,只有 DA 策略能成功综合,Latency 策略因循环过度展开而失败。

6.4 MNIST 分类
单层 MLP(784→128→10)。表 9 再次验证 DA 策略的优越性,所有设计零 DSP,LUT 仅数千。

这些结果表明,hls4ml 结合 HGQ 和 DA4ML,能够协同优化硬件实现的关键维度:
- 计算效率、资源占用与精度保持。HGQ 通过混合精度量化策略,在保留关键权重高精度的同时,对冗余通道或激活值采用极低比特(如 2–4 bit)表示,天然适配稀疏模型的非均匀信息分布;
- DA4ML 则提供面向 FPGA 的自动化编译与调度优化,针对稀疏计算模式(如跳过零值乘加)定制数据流与内存层次。
二者与 hls4ml 的高层次综合流程深度集成,显著降低 LUT/BRAM 占用、提升吞吐量,并缩短时序关键路径。因此,该技术栈特别适用于边缘端部署——在资源严苛约束下,高效运行剪枝后稀疏模型或低位宽神经网络(如 BNN、Ternary Net),兼顾实时性与能效比。
七、广泛应用:从粒子物理到自动驾驶
hls4ml 自诞生以来,已在众多领域落地:
- 高能物理:CERN 的 CMS 和 ATLAS 实验使用 hls4ml 在 FPGA 上部署实时触发算法,如异常检测(CICADA)、μ 子动量分配。
- 自动驾驶:语义分割模型在 Xilinx ZCU102 上实现 5ms 延迟,资源占用<30%。
- 量子计算:用于量子比特的读出门控和误差校正。
- 生物医学:ECG 心律失常分类,功耗仅 1.655W。
- 网络安全:100Gbps 网络流量中的恶意软件检测,延迟 44ns。
- 航天:卫星上的实时地球观测数据处理。
八、挑战与未来展望
尽管 hls4ml 功能强大,但仍面临一些挑战:
- 前端/后端支持不均:某些层仅在特定前端或后端可用,用户需注意兼容性。
- HLS 工具版本波动:不同版本的 HLS 编译器可能改变行为,导致 hls4ml 模板需要调整。
- 大模型支持:对于 Transformer 等超大模型,完全展开的数据流设计可能超出 FPGA 资源,需要结合分块、分层或利用 HBM。
未来发展方向包括:
| 方向 |
描述 |
| 支持更多前端:Flax/JAX |
让框架能直接读入用 JAX/Flax 训练好的模型,无需额外转换格式,从而扩大对深度学习生态的支持范围。 |
| 集成 AMD AI Engine |
直接利用 AMD Versal 芯片中专为 AI 加速设计的 AI Engine 硬件单元,相比仅使用通用 FPGA 逻辑资源,显著提升推理速度与能效。 |
| 分布式推理:多 FPGA 大模型部署 |
结合 Coyote shell 等通信与调度层,将大模型切分并部署至多片 FPGA 构成的集群,实现并行推理,有效应对单芯片容量与算力瓶颈。 |
| 强化协同设计:和 NAS 深度集成 |
实现神经架构搜索(NAS)与 FPGA 硬件部署的端到端打通:NAS 自动探索最优网络结构,框架同步生成匹配的硬件配置方案,达成算法与硬件的联合自动优化。 |
结论
hls4ml 作为一个开源、灵活、模块化的深度学习加速平台,成功降低了 FPGA 部署的门槛,让研究人员和工程师能够快速将先进模型转化为低延迟、高能效的硬件实现。其创新的编译架构、丰富的量化工具集、以及对多供应商的支持,使其在学术界和工业界都获得了广泛认可。随着社区持续贡献,hls4ml 将在未来的实时智能系统中扮演更重要的角色。
如果你对 FPGA 加速、模型量化或硬件-软件协同设计感兴趣,欢迎在 云栈社区 的 智能 & 数据 & 云 板块与其他开发者交流探讨,共同挖掘硬件加速的无限潜力。
 发表于 2026-2-25 04:39:12
|
查看: 183|
回复: 0
发表于 2026-2-25 04:39:12
|
查看: 183|
回复: 0
