昨天凌晨,OpenAI 官方宣布了一项新特性:Responses API 正式支持 WebSocket 模式。

这个模式是专门用来解决超复杂的 Agent 调用问题的。在以前的多轮对话场景,或者需要让大模型频繁调用一系列工具(Tool call)时,HTTP 模式有个明显的痛点:每次请求都得把完整的历史记录全部带上。
一旦涉及长线任务,比如自动化编程、多步推理的复杂 Agent 编排,模型与工具间来回交互可能多达二三十次。
举个例子,当你给 AI 下达指令“帮我写个爬虫,并用 Vue 写个前端可视化图表”,它可能需要经历以下步骤:
- 调用搜索工具,查询目标网站结构
- 调用代码编写工具,撰写抓取脚本
- 调用本地终端运行代码
- 运行发现报错,将报错信息返回给大模型
- 大模型分析报错,修改代码后再次运行
- 循环往复,直到程序跑通
- 最后开始编写前端部分的代码
即使是这样稍复杂的任务,大模型与本地工具间的交互次数也很可能超过10次。
如果沿用传统的 HTTP 模式,这数十次交互中,每一次请求都必须将前面所有的对话记录、已编写的代码、报错信息完整打包,再次发送给 OpenAI。随着上下文越来越长,请求数据包会不断膨胀,延迟也随之攀升。
而这次推出的 WebSocket 模式,正是为了解决这个“又长又重”的痛点。其核心思路是:保持长连接,只传输增量数据。
根据官方发布的数据,在涉及20个以上工具调用的重度工作流中,端到端执行速度提升了约 40%。

对于开发复杂AI应用的同学来说,这无疑是一个巨大的性能优化。
优化差异对比
为了让优化效果更直观,我们可以通过一个简单的对比图来理解网络开销的变化。
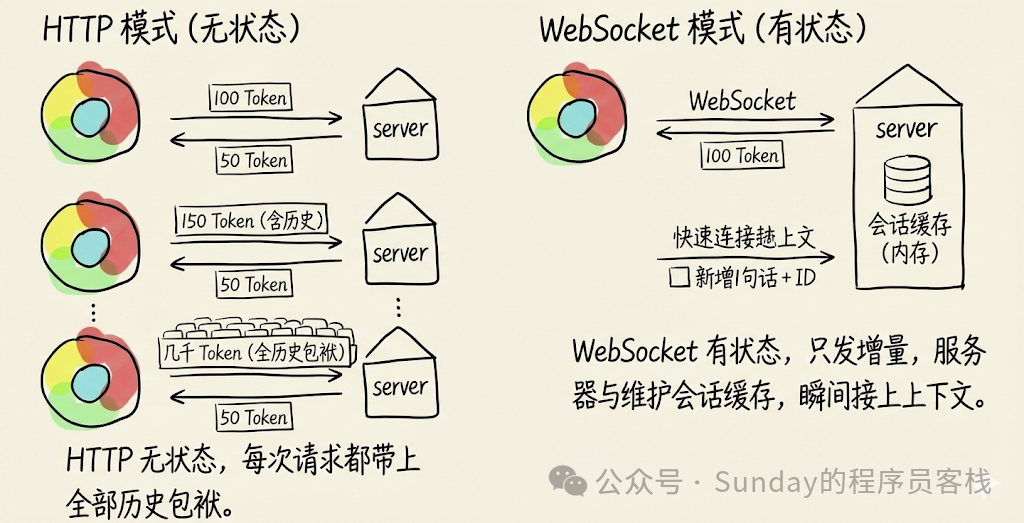
在 HTTP 模式下(左侧)
- 第1次请求:发送 100 个 Token,返回 50 个 Token。
- 第2次请求:需要带上第一次的对话历史,因此发送 150 个 Token(增量50+历史100),返回 50 个 Token。
- 第10次请求:你需要把前面所有交互产生的几千个 Token 全部发送过去。
本质上,HTTP 是无状态的。这意味着即使你只新增了一句“这行代码报错了”,也必须背负着此前累积的数千字“历史包袱”,重新传输一遍。
在 WebSocket 模式下(右侧)
服务器在内存中维护了你的会话缓存。
- 第1次交互:发送 100 个 Token。
- 第2次交互:你只需发送新增的这一句话,外加一个标识上次会话的 ID。服务器能瞬间从内存中检索并接续之前的上下文。
这种方式不仅节省了网络传输的时间,更重要的是极大地降低了服务端每次请求时的“冷启动”解析延迟。
到底怎么用?
官方文档已经给出了示例代码。接入成本其实很低,核心就是建立 WebSocket 长连接,然后发送特定格式的JSON数据。
用 Node.js 来实现非常简单,下面我们来看具体步骤。
第一步:建立连接并发送初始请求
以前是发送 HTTP POST 请求,现在需要改为使用 WebSocket 连接 wss://api.openai.com/v1/responses。连接建立后,无需传递 stream 之类的零散参数,直接发送一个 response.create 事件即可:
const WebSocket = require('ws');
// 1. 建立长连接
const ws = new WebSocket('wss://api.openai.com/v1/responses', {
headers: {
"Authorization": `Bearer ${process.env.OPENAI_API_KEY}`
}
});
ws.on('open', function open() {
// 2. 发送第一次请求
ws.send(JSON.stringify({
type: "response.create",
model: "gpt-5.2",
input: [
{
type: "message",
role: "user",
content: [{"type": "input_text", "text": "帮我写个爬虫,并用 Vue 写个前端可视化图表"}]
}
],
tools: [/* 你的本地工具列表 */]
}));
});
第二步:增量更新
这一步是这套新 API 价值最大化的地方。当你的本地工具执行完毕(例如,终端运行报错),你需要把结果返回给大模型。
这时千万不要像以前那样,把完整的聊天记录和几百行代码全部打包带上。你只需要传递 previous_response_id 和新增的报错信息:
// 后续的几十次交互,只需传增量
ws.send(JSON.stringify({
type: "response.create",
model: "gpt-5.2",
previous_response_id: "resp_123456", // 填入上一次大模型返回的 response ID
input: [
{
type: "function_call_output",
call_id: "call_abc789",
output: "Error: module 'axios' not found" // 这里只传最新的执行结果
}
]
}));
只要这个 WebSocket 连接保持不断开,OpenAI 的服务器就会在内存中直接关联 resp_123456 的上下文,并基于此继续处理。
几个实操的避坑细节
仔细翻阅官方文档后,有几个实现细节需要特别注意:
1. 如何并行处理?
单条 WebSocket 连接是串行处理的,即同一时间只能处理一轮对话。如果你需要并行运行多个不同的 Agent 任务,官方的方案非常直接:建立多个并行的 WebSocket 连接即可。
2. 连接断了怎么办?
官方限制了单条连接的最长存活时间为 60 分钟。对于绝大多数任务而言,这个时间都完全足够。
如果因超时或网络问题导致连接中断,你需要重新建立一个 WebSocket 连接,并将上次交互的 previous_response_id 传递过去,状态即可无缝恢复。
3. 隐藏的性能提升小技巧(预热)
文档中还隐藏了一个很有用的参数:generate: false。
如果你能提前预知接下来的 Agent 流程会用到哪些工具,可以先发送一个包含此参数的请求进行“预热”。这个请求不会立即消耗 Token 来生成内容,但会提前在服务端准备好请求状态。当真正的指令到达时,启动速度会更快。
总结
如果你的应用场景仅限于简单的“一问一答”式对话,那么普通的 HTTP 接口仍然完全够用,无需切换。但如果你正在开发重度依赖 Tool call 的复杂 Agent 应用,强烈建议尽快迁移到 WebSocket 模式。高达 40% 的延迟优化,足以让你的产品体验提升一个档次。
这项优化对于那些涉及长链路工具调用的场景意义重大。代码层面的具体接入方式,建议大家直接查阅 OpenAI 官方文档,并动手运行 Demo 体验效果。
如果你想了解更多关于AI应用开发的前沿技术和实战经验,欢迎来到 云栈社区 与众多开发者一起交流探讨。
 发表于 2026-2-25 08:15:26
|
查看: 239|
回复: 0
发表于 2026-2-25 08:15:26
|
查看: 239|
回复: 0
