今天我们来深入探讨操作系统中的一个核心组件——文件系统。
我们知道,在日常使用电脑时,文件是以一层套一层的树形结构呈现在我们面前的。
但是,计算机底层的数据在磁盘上真的是这样“嵌套”存放的吗?其实不然。在物理磁盘上,数据是以块为单位平级存放的。
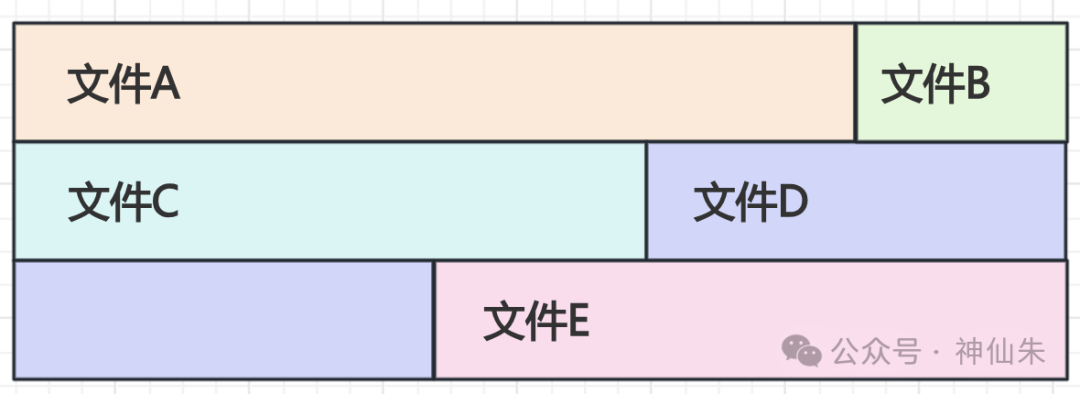
那么,一个核心问题就出现了:物理上是平级存储的数据,为什么逻辑上能呈现出树状结构呢?
答案就在于文件系统的一个关键设计:树形目录结构。虽然物理存储是平级的,但可以在逻辑上构建出树形的目录层次。这主要是为了提升用户体验,方便人类对文件进行管理和存取。
试想一下,如果所有文件都平铺在一个目录下,你会面临命名冲突、查找效率低下、文件混杂难以管理等诸多问题。树状结构符合我们的思维习惯,就像公司的部门划分或图书的分类一样自然。
那么,文件系统是如何实现这一“魔法”的呢?关键点在于:把目录本身也设计成一种特殊的文件。
要理解这一点,我们必须先引入一个核心概念:inode。
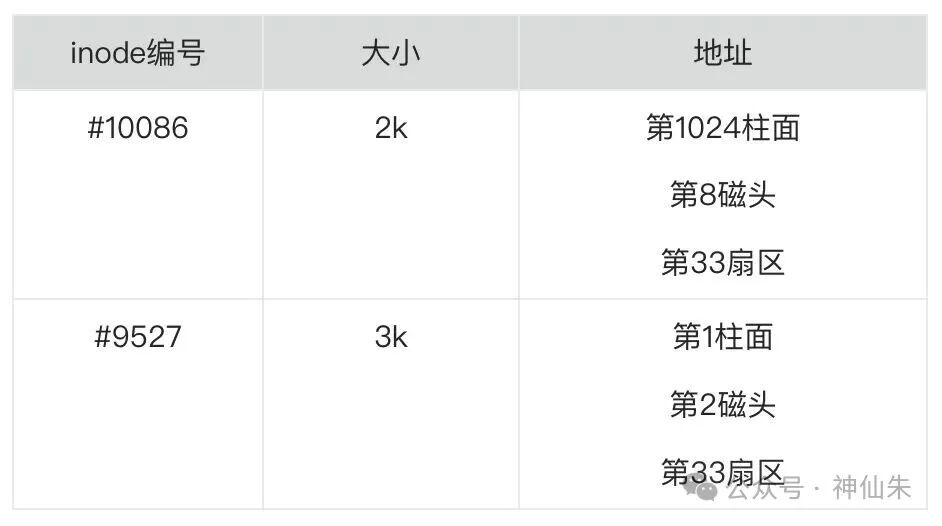
在文件系统中,每个文件(包括目录文件)都有一个唯一的ID,称为 inode 编号。记录文件元数据(如大小、时间戳、权限等)和最重要的数据块地址的结构,称为 inode 结构体。查找一个文件数据的路径可以简化为:inode编号 → inode结构体 → 数据地址 → 数据。
所有这些 inode 结构体都集中存放在磁盘的一个固定区域,称为 inode 区。你可以把它想象成一个数组,inode 编号就是数组的索引。通过编号,系统可以快速定位到对应的 inode 结构体。
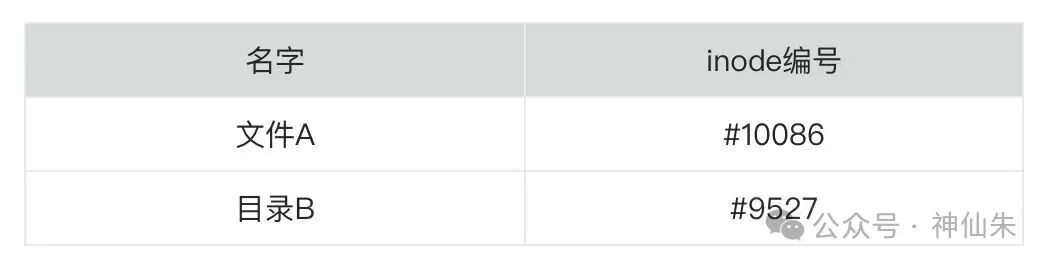
现在,回到“目录也是文件”这个点上。目录文件是干什么的?它的“数据内容”就是一张映射表,记录了属于该目录的所有目录项(即子文件或子目录)。每个目录项主要包含两项信息:
- 名称 (例如:
1111.txt)
- 对应的 inode 编号 (例如:9527)
所以,目录文件的核心功能就是建立 文件名 → inode号 的映射关系。
在 Linux 系统中,你可以使用 ls -i 命令查看当前目录下所有条目(文件和子目录)的 inode 编号:
[HOHO] .pictures % ls -i
2263533 4e926ff5c04c27d9b595dfa9e0036ae8.jpg
511811 Photos Library.photoslibrary
3815177 表情包
26776718 搞笑图片
32497737 猫猫
4884815 绒绒很刁蛮
5006030 跳跳的打工生涯
2247388 头像
正是通过这种“目录文件记录子项inode”的方式,原本平级存储的独立文件被逻辑地串联和组织成了树状结构。在磁盘上,目录文件和数据文件可能是交错存放的。
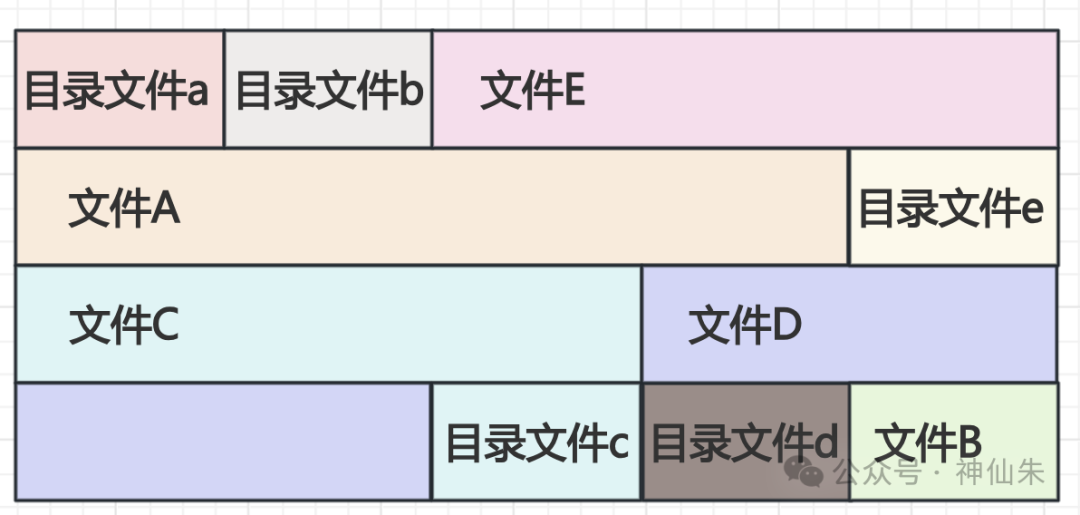
看到这里,你可能有点晕了:inode编号、inode结构体、目录文件、映射表…… 别急,我们通过一个例子来捋清整个访问链路。
假设我们要访问文件 /home/picture/a.png。假设系统中相关的 inode 结构体如下表所示:
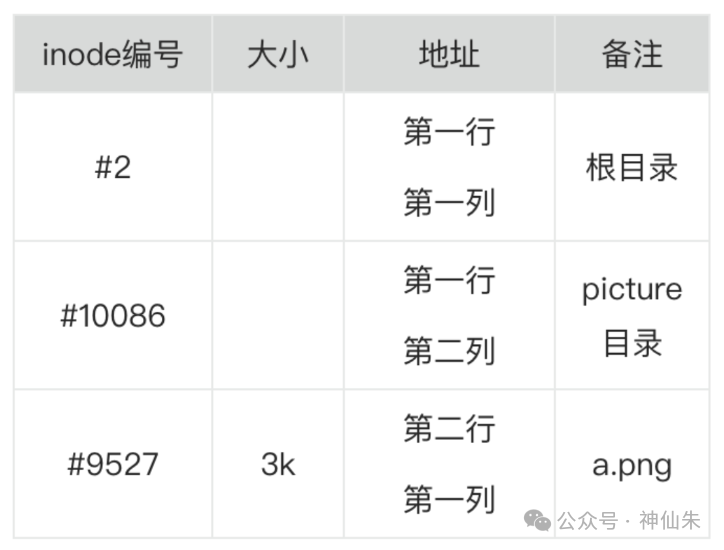
查找步骤如下:
- 从根目录开始,其固定 inode 编号为
2。通过 #2 找到根目录的 inode 结构体。
- 从该结构体中获取数据地址,读取到根目录文件的内容。
- 在根目录文件中,查找名为
home 的目录项,获得其 inode 编号 #10086。
- 通过
#10086 找到 home 目录的 inode 结构体,进而获取其数据地址,读取 home 目录文件。
- 在
home 目录文件中,查找名为 picture 的目录项,获得其 inode 编号 #9527(图中示例,实际可能不同)。
- 通过
#9527 找到 picture 目录的 inode 结构体,进而获取其数据地址,读取 picture 目录文件。
- 在
picture 目录文件中,查找名为 a.png 的文件项,获得其 inode 编号(例如 #12345)。
- 通过该编号找到
a.png 的 inode 结构体,最终从其数据地址读取到文件 a.png 的实际数据。
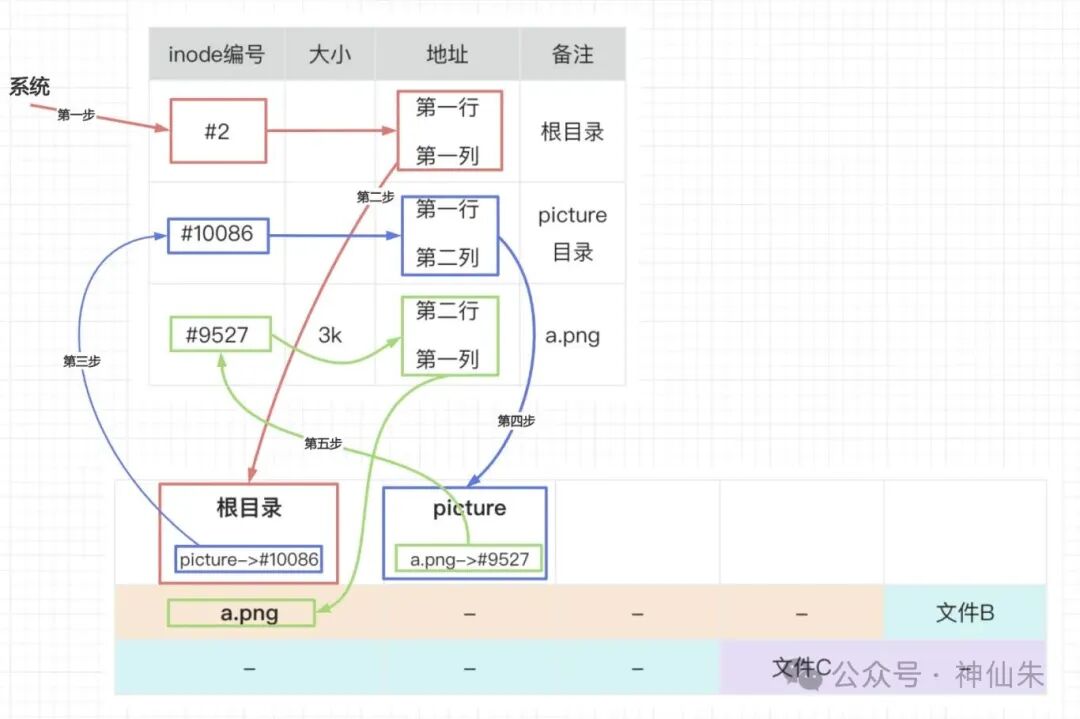
这个过程确实有点绕,但它清晰地揭示了逻辑树形结构与物理平级存储之间的桥梁是如何搭建的。这正是操作系统文件管理的精巧之处。
理解了文件如何被组织,我们再来看看单个文件的数据在磁盘上是如何存储的。
我们最初假设文件是连续占据一大块区域存储的,这种方式称为顺序存储(或称连续分配)。它的优点是寻址简单、访问速度快,因为只需要起始块号和长度即可定位。但缺点也很致命:容易产生外部碎片,且文件大小难以动态增长。

为了解决这些问题,文件系统还采用了其他两种存储结构:链式存储和索引文件结构。
链式存储将文件数据分散存放在不同的磁盘块中,每个数据块内包含一个指向下一个数据块的指针。它的优点是可以利用磁盘的任何空闲块,支持文件动态增长;缺点则是访问效率低,必须顺序遍历。

而索引结构,则巧妙结合了前两者的优点。它同样将文件分成多个数据块,但把这些数据块的指针集中管理,这个指针数组就存放在文件的 inode 结构体 中。在经典的 Unix 文件系统(如 Ext2/3/4)设计中,这个指针数组分为四类:
- 直接指针:直接指向数据块。
- 一级间接指针:指向一个充满指针的“间接块”,间接块中的指针再指向实际数据块。
- 二级间接指针:指向一个“间接块”,该块中的指针再指向更多的“间接块”,最终指向数据块。
- 三级间接指针:再多一层间接。
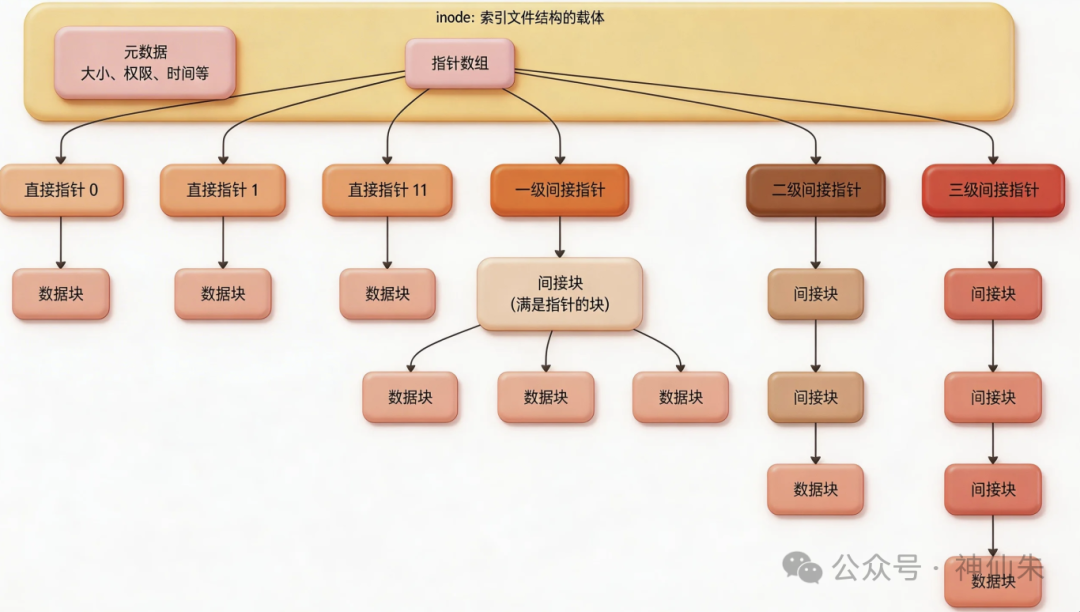
一个非常经典且实用的设计细节是:直接指针通常有 12 个。这意味着对于大多数小文件(数据块数 ≤ 12),系统可以通过一次访问 inode 就直接定位到所有数据,效率极高。这正是基于一个历史观察:大多数文件都小于 12 个数据块(当时一个块常为 512B 或 1KB,现代多为 4KB)。
你可能会问,为什么不全用直接指针?答案在于 inode 结构体的大小是固定的(典型为 256 字节),除去存储元数据(权限、时间、大小等)的空间,留给指针数组的空间有限。每个指针占 4 字节,空间不足以存储海量文件的全部直接指针。

因此,索引结构采用了一种渐进式的设计方案:
- 小文件:使用直接指针,一次访问即可。
- 中等文件:启用一级间接指针,需要两次访问(读inode,读间接块)。
- 大文件/超大文件:启用二、三级间接指针,需要三次或四次访问。
这种设计在存储效率、访问速度和功能扩展性之间取得了优雅的平衡,是计算机基础领域中一个经典的设计思想。
总结
今天,我们探讨了文件系统的两个核心层面:
- 树形目录结构:这是面向用户的设计。它通过在物理上平级存储的文件之间建立“目录文件-
inode 映射”的逻辑链路,将无序的存储空间组织成用户易于理解和操作的树状层次。这解决了文件命名、分类和高效查找的问题。
- 文件存储结构:这是面向底层存储的设计。它定义了单个文件的数据块在物理磁盘上如何分布和索引,主要关心存储效率和读写性能。经典的索引结构(如 inode 中的多级指针)完美平衡了小文件的访问速度和大文件的存储能力。
文件系统作为操作系统管理持久化数据的基石,其设计充满了权衡与智慧。理解这些机制,不仅能帮助我们更深入地理解计算机如何工作,也能在日常开发和系统优化中带来启发。希望这篇解析能帮你理清思路。如果你对网络/系统或其他底层原理感兴趣,欢迎在云栈社区继续交流探讨。
 发表于 2026-2-25 08:17:27
|
查看: 184|
回复: 0
发表于 2026-2-25 08:17:27
|
查看: 184|
回复: 0
