在上一篇文章中,我们介绍了Agent评估的通用方法,而本文将深入几种特定类型Agent的具体评估策略,包括编码Agent、研究搜索Agent、对话聊天Agent以及计算机操作Agent。
分析参考来源:
一、评估编码 Agent 的方法
编码 Agent 的核心工作是像人类开发者一样编写、测试和调试代码,并在代码库中进行检索浏览。这类Agent通常执行明确指定的任务,因此 确定性评分器非常适合编码 Agent。
1. 评估要点一:代码能否运行、测试是否通过
评估的基石是验证代码的功能正确性。这里介绍两个相关的编程基准:
- SWE-bench Verified
- Terminal-Bench
关于这两者的区别:
- Terminal-Bench 侧重于端到端的完整流程测试,例如部署一个Web应用或从零搭建一个MySQL数据库,而非仅仅修复某个编译错误。
- SWE-bench Verified 则更像一种“单元测试”。其常规使用方法是:向Agent提供一个真实的问题(如GitHub issue),Agent编写修复代码,最后运行测试套件来验证修复代码是否通过所有测试。
2. 评估要点二:Agent 的工作过程是否合理高效
当拥有测试用例集来验证结果后,评估编码Agent的工作过程也极为有用。我们不能仅满足于“通过测试”,还应关注其完成任务的过程是否合理、高效乃至优雅。
此时,可以引入两种额外的评估方法:
- 基于启发式规则的代码质量评估:使用代码规则而非单纯测试结果来检查质量。
- 代码复杂度
- 代码重复率
- 命名规范性
- 安全漏洞
- 性能问题
- 代码可读性
- 基于模型的行为评估:利用大语言模型来评估Agent执行任务过程中的中间行为。
例如,对于任务“查询数据库中的用户信息”:
- AgentA 的做法:直接查询所有用户信息,然后在内存中进行过滤。
- AgentB 的做法:使用
WHERE语句进行条件查询,仅返回所需数据。
虽然两者都能完成任务,但AgentB的做法显然更优、更符合最佳实践。
结论: 对编码Agent的评估应涵盖两个主要方向:执行结果(代码功能)和执行过程(代码质量与行为)。
以下是一个完整的评估案例配置,实际使用时可根据需要动态调整,不必求全。
task:
id: “fix-auth-bypass_1” # 任务ID:修复认证绕过漏洞_1
desc: “修复当密码字段为空时的认证绕过漏洞...”
graders: # 评分器
- type: deterministic_tests # 确定性测试
required:
- test_empty_pw_rejected.js # 拒绝空密码的测试
- test_null_pw_rejected.js # 拒绝null密码的测试
- type: llm_rubric # LLM评分标准
rubric: prompts/code_quality.md # 代码质量评分提示词文件
- type: static_analysis # 静态代码分析
commands:
- eslint # 代码风格检查
- tsc # TypeScript类型检查
- type: state_check # 状态检查
expect:
security_logs:
event_type: “auth_blocked” # 期望安全日志中有认证阻止事件
- type: tool_calls # 工具调用检查
required:
- tool: read_file
params:
path: “src/auth/*” # 读取认证代码
- tool: edit_file # 编辑文件
- tool: run_tests # 运行测试
tracked_metrics: # 追踪指标
- type: transcript # 对话记录指标
metrics:
- n_turns # 对话轮数
- n_toolcalls # 工具调用次数
- n_total_tokens # 总token消耗
- type: latency # 延迟指标
metrics:
- time_to_first_token # 首token时间
- output_tokens_per_sec # 输出速度(tokens/秒)
- time_to_last_token # 总完成时间
二、评估对话 Agent 的方法
对话代理(如客服、销售或辅导机器人)在与用户的多轮互动中保持状态、使用工具并采取行动。虽然编程和研究代理也可能涉及多次交互,但对话代理呈现出一个独特的挑战:互动本身的质量也是评估的一部分。
因此,对话代理的有效评估通常依赖于可验证的最终状态结果和能够捕捉任务完成度与互动质量的评分标准。与其他评估不同,这通常需要另一个LLM来模拟用户进行测试。
评估要点:
- 可验证的最终状态:即Agent是否完成了核心任务,例如成功退款、修改地址或生成报价单。
- 交互质量评估:这是对话Agent独有的评估维度。
例如,在“客服退款”场景中:
- Agent A:对话生硬,仅完成流程。
用户:“我要退款”
Agent:“订单号?”
用户:“12345”
Agent:“已退款”
- Agent B:在完成任务的同时,提供了良好的交互体验。
用户:“我要退款”
Agent:“很抱歉给您带来不便。请问是哪个订单呢?”
用户:“12345”
Agent:“我查到了您的订单,符合退款条件。我现在为您处理,预计3-5个工作日到账。还有其他需要帮助的吗?”
结论: 对话Agent的评估标准应是 最终状态验证 + 交互质量评估 的组合。
一个有效的对话Agent可以从多维度衡量:
- 用户诉求是否解决(状态检查)
- 是否在规定的对话轮数内完成(如10轮)
- 语气是否恰当(由LLM评估)
𝜏-Bench 及其后续版本 τ2-Bench 是模拟零售支持、航空预订等多轮交互的测试基准,它们使用一个LLM扮演用户角色。在开发类似场景的客服对话Agent时,可以参考这两个基准进行评估。
以下是一个评估“对话Agent处理沮丧用户退款”的案例配置:
graders:
# 1. LLM评分标准
- type: llm_rubric
rubric: prompts/support_quality.md # 客服质量评分提示词文件
assertions: # 列出来的评分的重点角度
- “Agent对客户的沮丧表现出同理心”
- “解决方案被清晰地解释”
- “Agent的回复基于fetch_policy工具的结果”
# 2. 状态检查
- type: state_check
expect: # 期望的最终状态
tickets:
status: resolved # 工单状态:已解决
refunds:
status: processed # 退款状态:已处理
# 3. 工具调用检查
- type: tool_calls
required: # 必须调用的工具
- tool: verify_identity # 验证身份
- tool: process_refund # 处理退款
params:
amount: “<=100” # 金额必须 ≤ 100
- tool: send_confirmation # 发送确认
# 4. 对话记录约束
- type: transcript
max_turns: 10 # 最大对话轮数:10轮
tracked_metrics: # 追踪指标
# 1. 对话记录指标
- type: transcript
metrics:
- n_turns # 对话轮数
- n_toolcalls # 工具调用次数
- n_total_tokens # 总token消耗
# 2. 延迟指标
- type: latency
metrics:
- time_to_first_token # 首token时间
- output_tokens_per_sec # 输出速度(tokens/秒)
- time_to_last_token # 总完成时间
三、评估研究 Agent 的方法
研究Agent的核心任务是收集、综合和分析信息,并生成答案或报告等输出。其评估无法像编码Agent的单元测试那样具有确定性,研究Agent的输出质量评估只能是相对任务目标进行判断,主要关注:
- 是否进行了全面的搜索和研究。
- 是否引用了良好且正确的来源。
此外,不同领域(如市场研究 vs 技术调研)的评估标准也各不相同。研究Agent评估的独特挑战在于:专家对“综合是否全面”可能有分歧,真实信息会动态变化,而开放式输出为错误留下了更多空间。
知名的测试基准 BrowseComp 就旨在评估AI代理在开放网络中寻找“难以发现却易于验证”信息的能力(答案通常是单个词或短语)。例如:“在悉尼歌剧院附近的植物园里有一座铜雕塑,雕塑中的男人手里拿着什么物体?” 解答此题需要精准的多步骤网络搜索与信息定位。
因此,构建研究Agent评估体系的通用方式是组合多种评分器:
- 基础性检查:每个关键声明是否有来源支持?
- 覆盖性检查:来源中的关键信息是否都被涵盖和利用了?
- 来源质量检查:引用的资料是否权威可靠?(不能仅因搜索排名第一就使用)
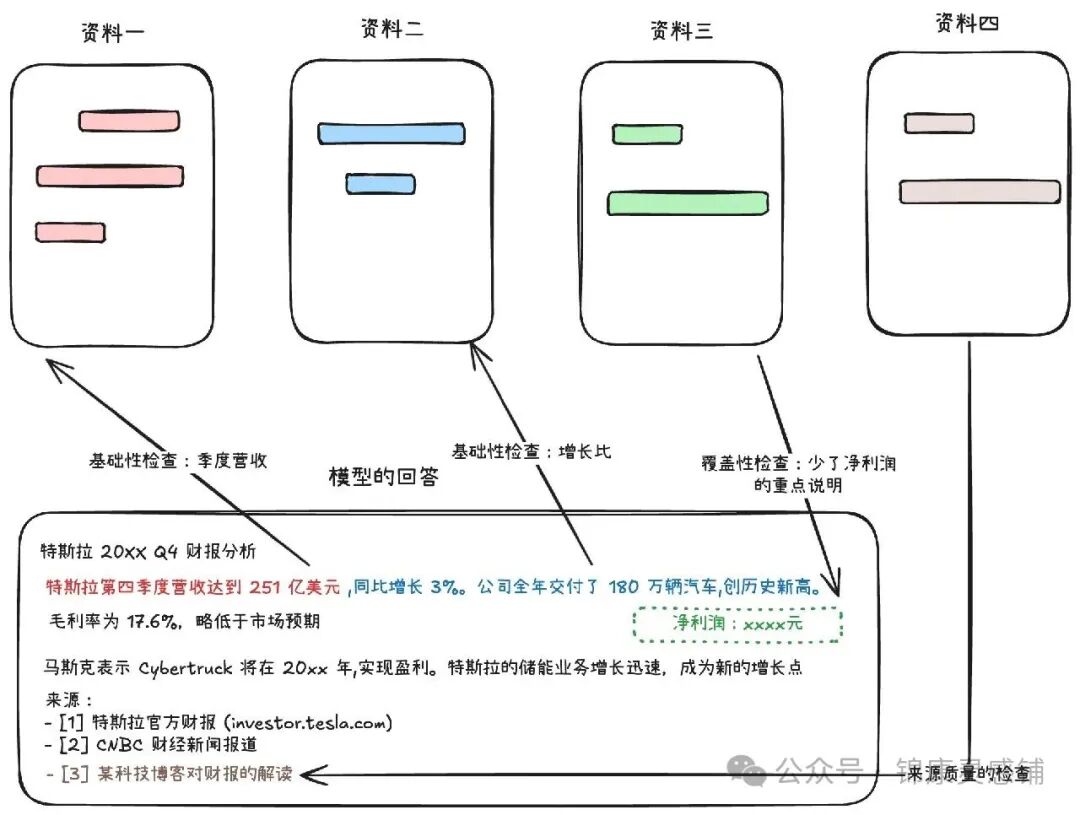
上图展示了研究Agent评估中,基础性检查、覆盖性检查与来源质量检查如何应用于具体的财务分析案例。
四、评估计算机使用 Agent 的方法
计算机使用Agent通过模拟人类操作(屏幕截图、鼠标点击、键盘输入)与软件GUI交互,而非通过API。因此,评估这类Agent时,不仅要看界面是否出现,更要验证软件背后的逻辑是否正确执行。
例如:
- WebArena:测试基于浏览器的任务。它使用URL和页面状态检查来验证导航是否正确,并对修改数据的任务进行后端状态验证(例如,确认订单确实已下单,而非仅仅显示了下单页面)。
- OSWorld:将评估扩展到完整的操作系统控制。任务完成后,通过检查文件系统状态、应用程序配置、数据库内容等来验证结果。
一个关键的设计思路在于平衡token效率与延迟:
- 基于DOM的交互:执行速度快,但提取复杂页面时消耗大量token。
- 基于屏幕截图的交互:速度较慢,但对于视觉复杂的页面(如电商网站)token效率更高。
例如,让Agent总结维基百科文章时,从DOM提取文本更高效;而在亚马逊上寻找笔记本电脑保护套时,截图可能更高效(因为提取整个DOM会消耗巨量token)。在开发浏览器Agent时,应评估其是否为不同场景选择了正确的交互模式。
五、总结:理解评估指标 Pass@k 与 Pass^k
无论哪种类型的Agent,其行为在每次运行中都可能存在波动,这使得解读评估结果变得复杂。我们常需要测量Agent在多次尝试中成功的模式,两个指标有助于捕捉这种差异:
1. Pass@k
衡量Agent在k次尝试中至少获得一次成功的概率。随着k增加,pass@k分数会上升——更多的尝试意味着至少成功一次的几率更高。
- 例如:Pass@1为50%,意味着模型首次尝试就成功完成了半数任务。
- 适用场景:对于工具类应用,只要有一个解决方案成功就很重要。
2. Pass^k
衡量Agent所有k次尝试全部成功的概率。随着k增加,pass^k分数会下降,因为保持多次一致性是更苛刻的标准。
- 例如:如果单次成功率75%,那么3次全部成功的概率是 (0.75)³ ≈ 42%。
- 适用场景:对于面向用户、要求稳定可靠的服务,一致性是关键。
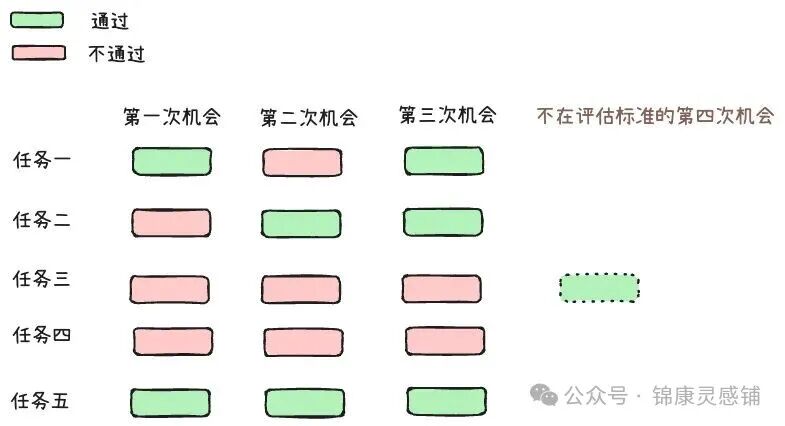
上图通过五个任务在三次尝试中的通过情况,直观展示了Pass@3的计算方式(至少成功一次的任务比例)。
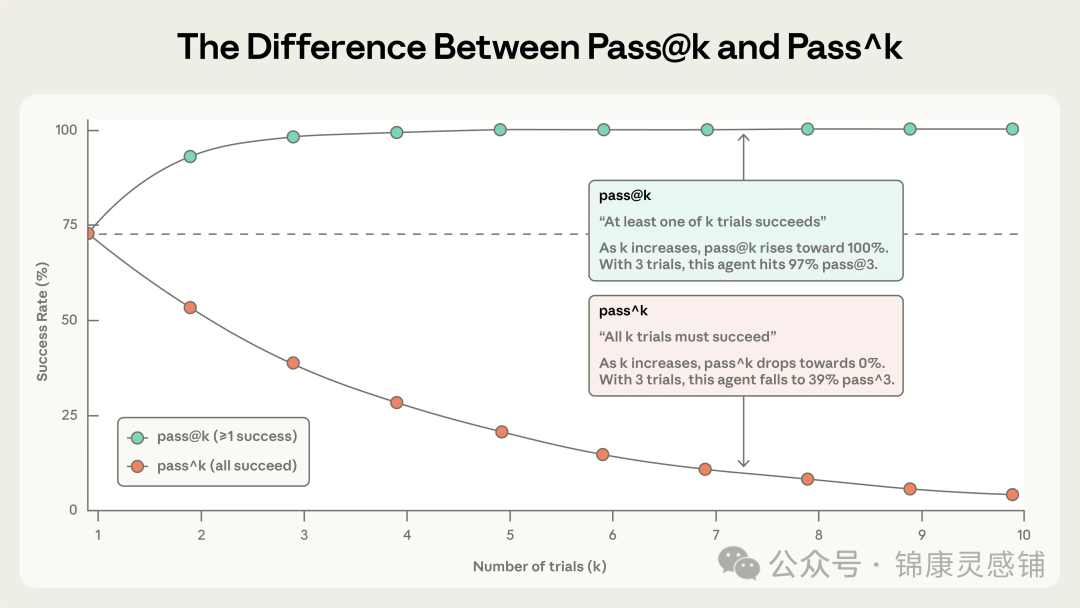
此折线图清晰显示,随着试验次数k增加,Pass@k趋向于100%,而Pass^k趋向于0%,两者逐渐分化。
结论:这两个指标从不同角度刻画了Agent的特性:Pass@k 反映其潜力与能力边界,而 Pass^k 则衡量其可靠性与稳定性。选择哪种指标取决于具体的产品需求。如果你想系统性地学习如何构建和评估AI系统,可以参考我们整理的技术文档与开源实战案例,在云栈社区与更多开发者交流人工智能领域的最新实践。
附:项目链接
本文节选自我正在整理的「上下文工程实践」项目,该项目已完整发布在GitHub上。
👉 https://github.com/WakeUp-Jin/Practical-Guide-to-Context-Engineering
 发表于 2026-2-26 02:38:11
|
查看: 311|
回复: 0
发表于 2026-2-26 02:38:11
|
查看: 311|
回复: 0
