
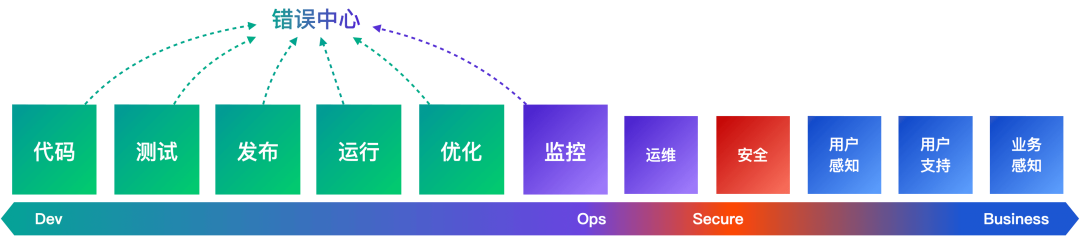
有效追踪错误,是保障应用稳定性的基石。如今的开发团队构建和维护的应用,其复杂性往往横跨前端、后端乃至移动端——每一层都可能产生影响性能与用户体验的异常。当错误信息分散在日志、应用性能监测(APM)和用户访问监测(RUM)等多个独立工具中时,定位与解决问题就变成了一场艰难的拼图游戏:你需要手动关联 Trace ID、在不同窗口间切换、费力地拼凑上下文。这种碎片化的调试流程不仅拖慢排障速度,更可能导致关键缺陷被遗漏,进而增加系统的不可用时间。
一个典型的日常场景:当 999+ 封报错邮件涌向你的收件箱
你的邮箱被 NullPointerException、Connection Timeout、TypeError 等各类报错邮件塞满。同一个 Bug 触发了上千次告警,然而当你尝试排查时,却陷入困境:APM 里的错误堆栈不完整,日志里的错误缺少关键 Trace ID,RUM 里捕捉到的前端异常又无法和后端问题关联。你不得不在几个浏览器标签页间反复切换,耗费大量时间,却依然搞不清楚:这到底是同一个问题的重复告警,还是多个独立故障?它影响了多少用户?严重程度是否值得深夜唤醒整个团队?
为了应对上述挑战,观测云错误中心为团队提供了一个贯穿前后端的单一真实数据源。它能自动汇聚来自 APM、RUM 和日志等不同数据源中的错误,通过智能指纹算法将它们聚类为错误根因,并关联完整的链路、日志和用户会话上下文。这使开发者能够快速识别关键问题、加速根因定位、并有效防止已修复问题的复发,从而将“修复错误”从混乱无序的“救火”转变为标准化、高效率的流程。
本文将深入解析观测云错误中心如何通过统一视图,帮助团队高效处理应用与服务中的问题:
- 快速识别并优先处理最关键的错误
- 凭借全栈可见性加速故障排查
- 主动检测并防止问题复发
01|快速识别并优先处理错误根因
需求背景
你可以将应用中的错误想象成汽车仪表盘上的“发动机故障灯”。它告诉你系统有问题,但具体是什么问题、严重程度如何,单凭这一个灯很难判断。在观测云中,一个“Error”就是这样一个具体的异常实例,例如后端抛出的 NullPointerException、前端 JavaScript 报出的 TypeError,或是日志中记录的数据库 Connection Timeout。
关键在于,错误通常是持续且重复的。同一个底层 Bug 可能每分钟触发上百次 Error 告警,但真正需要工程师去修复的根因或许只有一个。随着现代应用架构日益复杂,团队需要从海量、嘈杂的告警噪音中,迅速分辨出哪些是次要的警告,哪些是真正影响业务的高优先级问题。当错误分散在不同监控工具中时,判断一个问题是新出现的、历史问题的复发还是正在恶化,变得异常困难。
观测云解法
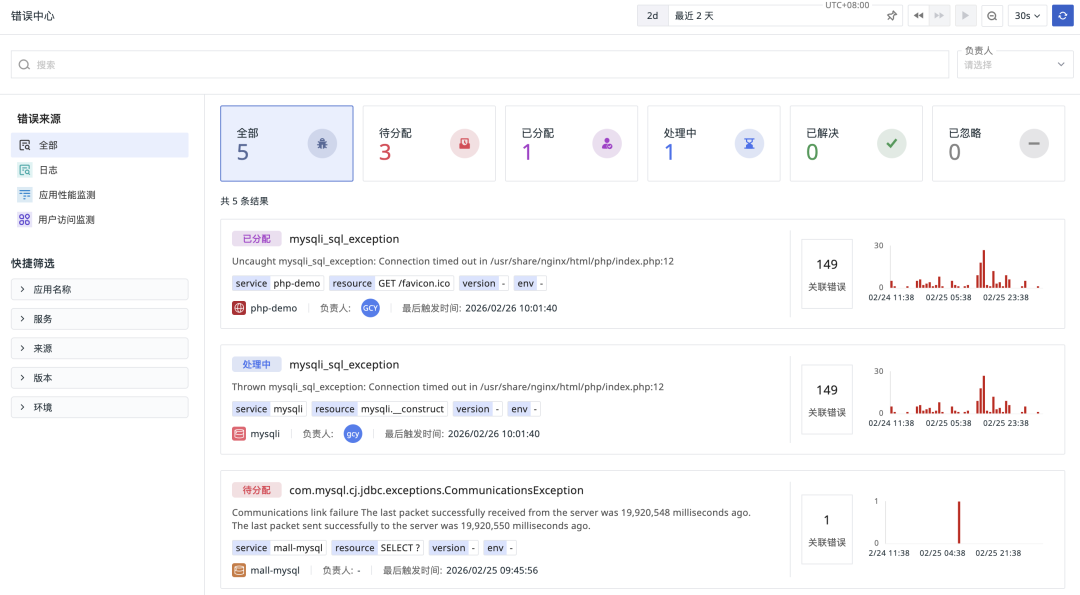
观测云错误中心在无需你配置任何告警规则的前提下,自动采集全量的 Error 数据,并通过智能指纹算法将其聚类为清晰的错误根因:
- 智能降噪与分组:系统在计算错误指纹前,会先优化堆栈信息,保留关键业务调用路径,并自动过滤掉变量内容(如 UUID、时间戳等)。基于错误类型、信息和堆栈特征生成的指纹,能将同一根源产生的海量 Error 自动归并为同一个 Issue。例如,因数据库连接池耗尽而产生的 10000 次 Error,在错误中心只会显示为“1个 Issue,累计触发 10000 次”,而非铺天盖地的 10000 条独立告警。这极大减轻了告警疲劳,让你能一目了然地识别出新问题、复发问题或与特定部署相关的问题。
- 实时趋势与影响面分析:通过错误分布趋势图表,你可以直观看到问题是部署后 API 失败率的意外激增,是与网络状况相关的移动端崩溃,还是由过期认证令牌引发的前端错误。识别这些跨越不同技术栈的错误模式,是开展高效修复工作的第一步。
02|通过全面的上下文加速故障排查
需求背景
当复杂分布式应用出现问题时,精确定位根因往往耗时费力,尤其是在技术栈各部分数据相互割裂的情况下。一个前端页面崩溃,根源可能在后端 API 超时;一次页面加载缓慢,也许关联着数据库的查询性能瓶颈;一次移动端闪退,没准是由服务器端的某个配置错误所触发。如果缺乏一个集中、全面的上下文视图,开发者就只能被迫拼凑来自不同监控工具的碎片化信息,这不仅拖慢解决速度,也增加了误判的风险。
观测云解法
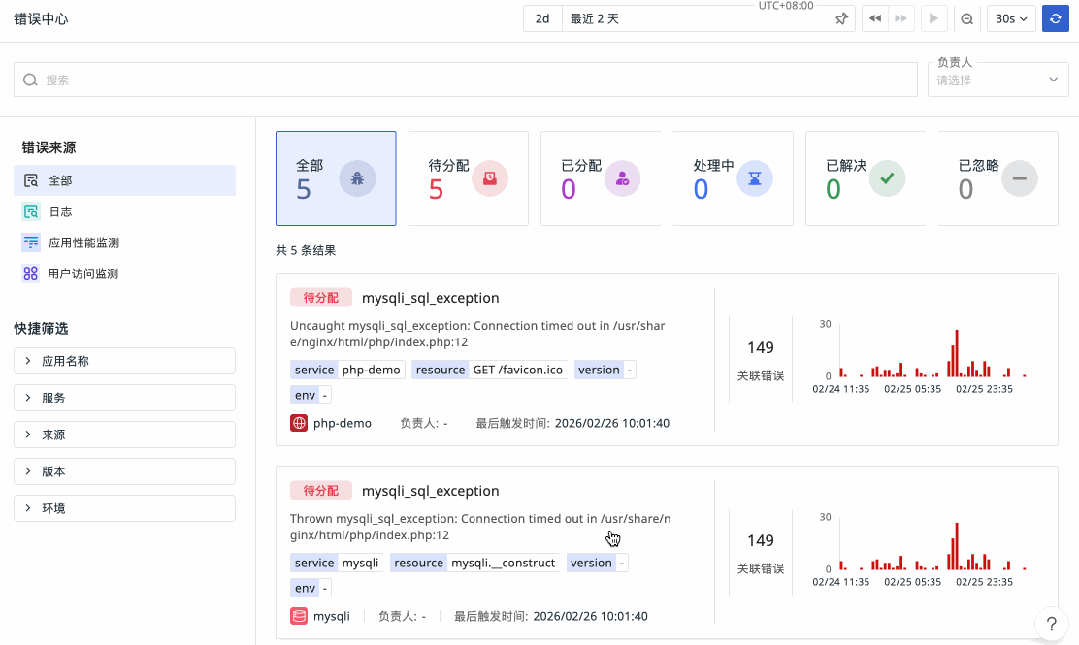
观测云错误中心通过连接整个技术栈的可观测性数据,消除了排障过程中的盲区,在一个界面内为开发者提供所需的所有上下文:
- 跨数据源统一汇聚:自动采集 APM(后端异常)、RUM(前端/浏览器错误)、日志(系统与应用日志)中的错误,打破数据孤岛。当问题被识别后,你可以从前端用户界面一路追踪到后端微服务、数据库调用乃至网络请求。
- 完整堆栈跟踪与源码映射:提供完整的错误堆栈信息。对于前端 JavaScript 错误,集成的 SourceMap 可自动将混淆后的代码映射回源码的准确行与列,并支持直接链接到代码仓库,让修复工作直达病灶。
- 用户会话关联与复现:对于来自 RUM 的前端错误,可以直接下钻查看触发错误的真实用户会话详情。关联的会话重放功能让你能够观察错误发生前后用户的具体操作路径(例如点击了哪个按钮、浏览了哪些页面),极大帮助于复现难以捉摸的偶现问题。
- 关联链路追踪:点击任何一个错误,无需手动复制粘贴 Trace ID,完整的分布式调用链路(火焰图、Span 瀑布图)便会自动关联并呈现出来。
- 日志与指标联动:错误与对应的日志详情、基础设施指标均在统一平台中关联。这能帮助你快速判断问题是否由特定的代码部署、基础设施变更或第三方服务依赖失败所引发。
这种深度的上下文关联让根因分析变得前所未有的高效。开发者可以从一个错误点,自然地跳转到相关的日志、调用链路和性能指标,彻底告别在不同工具标签页间反复横跳的繁琐操作。
03|主动检测并防止问题复发
需求背景
修复一个问题,并不等于它能一劳永逸。如果没有对回归的有效追踪,团队很可能在不知情的情况下,将早已修复过的 Bug 或问题重新引入系统。手动监控这些问题是否复发效率低下,团队需要一种主动的机制,在回归导致服务中断和损害用户体验之前,就及时发现并处理它们。
观测云解法
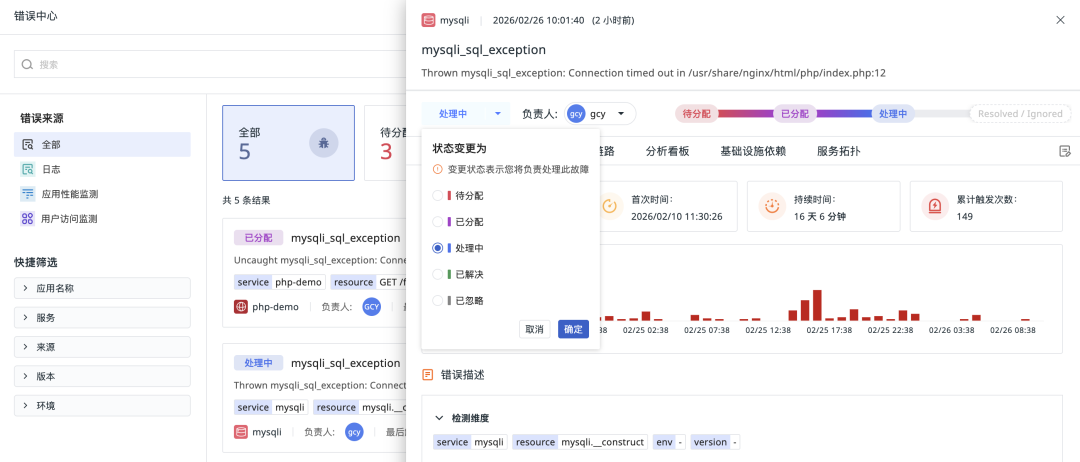
观测云错误中心通过完善的状态流转与生命周期管理机制,确保每一个 Issue 都有始有终,形成管理闭环:
- 生命周期状态管理:每个错误根因都拥有明确的状态流转路径:待分配 → 已分配 → 处理中 → 已解决。团队可以据此优先处理那些未分配但影响广泛的高频 Issue,避免在已处理的问题上重复投入精力。
- 自动回归检测:对于已标记为“已解决”的 Issue,如果系统再次检测到相同指纹的错误出现,该 Issue 的状态会自动回退到“待分配”,并进行高亮提示,告知团队“问题疑似复发”。所有历史排查上下文都得以保留,有效防止“以为修好了但实际上没有”的情况被忽视。
- 智能忽略与降噪:对于一些已确认无需修复或暂时无法处理的已知问题(例如某些第三方 SDK 的非致命性警告),可将其标记为“已忽略”。后续产生的相同错误将不再产生干扰,让团队能够集中精力处理那些真正关键的业务代码错误。
场景示例
假设你的监控告警显示“支付服务不可用”,同时观测云错误中心有一个状态为“待分配”的 Issue,显示“数据库连接超时”,且已累计触发 5000 次:
- 认领与优先级判断:运维或开发负责人查看该 Issue 的趋势图,发现其在最近一次应用发布后错误量激增,且影响了大量支付用户,于是判断为高优先级,点击“分配给我”,状态变为“已分配”。
- 全栈关联排查:进入 Issue 详情页,“关联链路”自动展示了最近一次错误的完整调用链,发现是某个新增的联表查询因缺少索引导致慢 SQL;“关联日志”则显示同一时间段数据库连接池被占满的告警;“用户会话”信息也证实了部分用户在支付页面点击提交后长时间无响应。
- 定位根因:通过 SourceMap 映射,直接定位到源码第 142 行存在问题的查询逻辑,并确认该 Issue 开始爆发的时间点与最近一次代码部署完全吻合。
- 修复与验证:提交修复代码(如为查询添加索引)并部署后,将该 Issue 标记为“已解决”。系统将持续监控,若相同指纹的错误不再出现,则保持关闭状态。
- 回归预警:三天后,相同指纹的错误再次出现。错误中心自动将该 Issue 状态回退到“待分配”,并通知原处理人:“疑似回归,请确认”。开发者快速对比新旧错误实例,发现是另一个服务模块也引用了同一段有问题的代码,于是立即进行批量修复,避免了影响范围扩大。
总结
观测云错误中心 vs. 传统方式
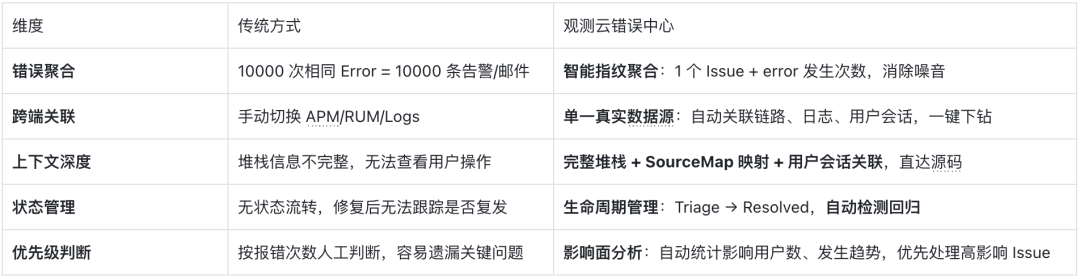
统一错误视图,直指错误根因
观测云错误中心提供了覆盖前端、后端、浏览器及移动端的统一错误管理视图。借助强大的全栈可观测能力,团队能够精准识别并优先处理最关键的错误,利用完整的上下文信息大幅加速故障排查,并在回归对最终用户产生实质性影响之前,就主动检测并加以防止。这让开发者得以从繁琐、重复的问题拼图游戏中解放出来,将更多精力投入到真正的创新与业务开发中。
 发表于 2026-2-27 04:25:46
|
查看: 154|
回复: 0
发表于 2026-2-27 04:25:46
|
查看: 154|
回复: 0
