NVIDIA Rubin Ultra 作为下一代 AI 数据中心 GPU 旗舰产品,在互联带宽方面实现了跨越式升级,这标志着 AI 基础设施正式进入 PB 级全互联时代。
1. Kyber 架构机柜详解:Rubin Ultra 互联带宽推演
根据 NVIDIA 在 GTC 2025 大会公布的技术规格,Rubin Ultra 机柜总带宽较上一代 GB200 增长 12 倍,达到 1.5 PB/s(1555.2 TB/s)。这一突破性的带宽能力由 144 颗 GPU 共同提供,每颗 GPU 封装集成 4 个 dies,总计 576 个计算 die,对应单颗芯片双向互联带宽达到 10.8 TB/s。如此高密度的算力与带宽配置,对 Scale-up 网络架构提出了前所未有的工程挑战,很可能会采用双层网络拓扑以在极致性能、成本控制与物理可实现性之间取得平衡。
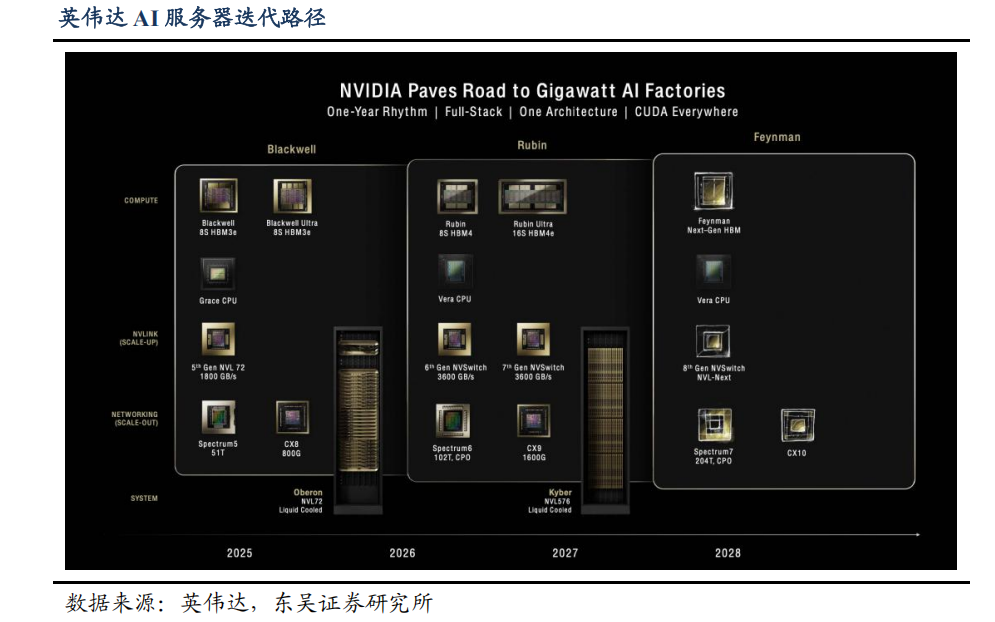
从交换侧来看,Rubin Ultra 将配备第七代 NVSwitch 芯片。根据官方 PPT 披露的技术细节,单颗第七代 NVSwitch 芯片的交换容量达到 3600 GB/s(3.6 TB/s)。考虑到 Rubin Ultra 机柜采用 4 个 Canister 堆叠构成的物理形态,这种模块化设计不仅优化了机柜的空间布局与散热管理,也为分层网络架构提供了天然的物理边界。
假设第七代 NVSwitch 的 SerDes 仍沿用成熟的 224G 技术路径,radix 端口数维持 72 配置,整个 Scale-up 网络就必须进行双层组网架构设计:第一层负责 Canister 内部的高速电交换,第二层负责跨 Canister 的光互连。这种分层设计不仅符合信号完整性的工程约束,也通过电光混合方案在带宽密度与传输距离之间取得了最优平衡。
2. Kyber 架构机柜详解:Canister 内部正交背板交换网络
第一层网络负责 Canister 内部计算托盘与交换托盘之间的高速互联,是实现机柜级全互联的基础单元。按照历次 GTC 大会展示的技术方案及产业链验证,这一层的信号传输介质采用正交背板 PCB。
正交背板架构通过将计算板与交换板垂直插接,最大限度地缩短了高速信号走线长度,有效降低了传输损耗和信号延迟,为高带宽、低延迟的片间通信提供了理想的电气环境。
考虑到 224G SerDes 的高频信号完整性要求,正交背板所使用的 CCL 材料需达到 M9 级别。M9 级超低损耗材料具有优异的介电常数(Dk)稳定性和极低的介电损耗(Df),能够有效降低高频信号在 PCB 走线中的插入损耗,确保 224G PAM4 信号在正交背板上的传输质量,从而支撑 Canister 内部全带宽无阻塞交换。

从带宽层面进行定量分析,单颗 Rubin Ultra 芯片具备 10.8 TB/s 的双向互联带宽,单个 Canister 包含 36 颗 Rubin Ultra 芯片(相关分析可参考行业技术报告)。考虑到交换芯片的容量规划通常以单向带宽为基准,整个 Canister 的总单向带宽需求达到 194.4 TB/s。
基于第七代 NVSwitch 单颗 3.6 TB/s 的交换容量,第一层网络需配置 54 颗第七代 NVSwitch 芯片方可满足该 Canister 内部的无阻塞交换需求。这 54 颗交换芯片通过正交背板与 36 颗计算芯片实现高密度的端口映射,构建出 Canister 内部的全互联拓扑。这种高密度的交换芯片配置不仅提供了充足的交换容量,还通过缩短信号路径降低了通信延迟,为 Canister 内部 36 颗 GPU 之间的高速通信提供了坚实的电气基础,确保训练过程中梯度同步等关键操作能够以最高效率完成。
整个机柜共包含 4 个 Canister,因此第一层网络总共需要 4 块正交背板,216 颗第七代 NVSwitch 完成内部互联。
3. Kyber 架构机柜详解:Canister 间 NPO 交换网络
第二层网络用于实现 4 个 Canister 之间的跨节点互联,这是构建完整 144 GPU 机柜级全互联的关键环节,也是实现 1.5 PB/s 机柜总带宽的必经之路。由于 4 个 Canister 在物理上呈堆叠或并排布局,跨 Canister 的信号传输距离超出了正交背板铜互连的有效范围,因此需采用光互连技术。根据行业研究,Canister 之间的网络带宽采用 3:1 的收敛比设计,这一工程权衡在极致性能与成本控制之间取得了合理平衡,既保证了机柜内任意 GPU 间的可达性,又通过适度的带宽收敛控制了光引擎的数量和系统总成本。
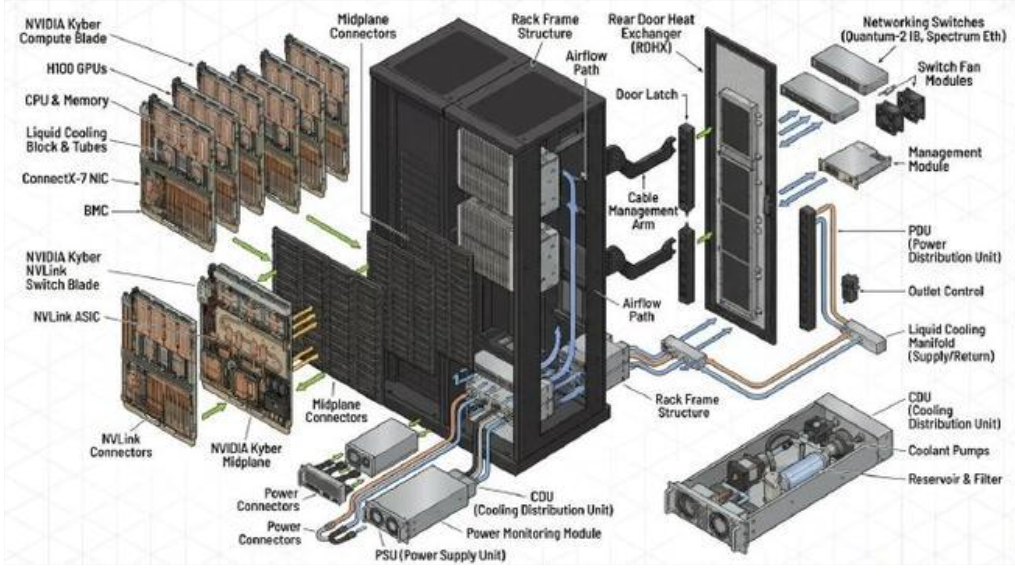
要支撑整个机柜双向 1.5 PB/s(1555.2 TB/s)的带宽互联需求,第二层网络所需的 NVSwitch 芯片数量可通过严谨的数学计算得出:首先将双向总带宽 1555.2 TB/s 除以 2 转换为单向带宽 777.6 TB/s,再除以 3 考虑 3:1 的收敛比得到 259.2 TB/s,最后除以单颗芯片 3.6 TB/s 的交换容量,即 1555.2 / 2 / 3 / 3.6 = 72 颗第七代 NVSwitch 芯片。第二层网络中这 72 颗 NVSwitch 的总交换带宽达到 259.2 TB/s,换算为比特率即 2073.6 Tbps。这些交换芯片充当着 Canister 间通信的汇聚与转发节点,将来自第一层网络的电信号转换为适合长距离传输的格式。
根据技术披露,第二层网络中 Canister 之间的互联介质采用 3.2 Tbps 速率的光引擎(NPO,Near-Package Optics)。基于上述总带宽需求 2073.6 Tbps,需配置 648 颗 3.2 T 光引擎以完成第二层网络的互联。
这种近封装光学方案将光模块紧密集成在交换芯片附近,极大地缩短了电信号走线,降低了功耗和信号完整性风险。光互连方案通过将电信号转换为光信号,突破了铜缆在传输距离和带宽密度上的物理限制,使得 4 个 Canister 能够在机柜范围内实现高速、低延迟的协同计算,构建出真正意义上的机柜级统一加速计算资源池。这一配置对应 GPU 与光引擎的比例为 144:648,即 1:4.5。
该配置方案不仅满足了 1.5 PB/s 机柜带宽的技术指标,也为未来超大规模 AI 模型训练与推理工作负载提供了可扩展、高可靠、高能效的互联基础设施,代表了当前 AI 数据中心 Scale-up 网络架构 的巅峰工程水平。对于想深入了解此类高性能计算架构细节的开发者,欢迎在 云栈社区 参与更多技术讨论。
 发表于 2026-2-27 04:28:18
|
查看: 440|
回复: 0
发表于 2026-2-27 04:28:18
|
查看: 440|
回复: 0
