本文对英伟达数据中心GPU产品进行全面的技术概述与横向比较,涵盖从Ampere到Blackwell的多代架构,包括CPU+GPU超级芯片、传统加速卡及先进的互连技术。内容涉及主流产品如A100、H100/H200、L40S,以及专用变体,并重点解析了多实例GPU(MIG)、NVLink/NVSwitch互连架构与NVL72等关键创新。
1、NVIDIA 数据中心 GPU 架构演进
NVIDIA GPU经历了多次架构迭代,包括Volta、Ampere、Hopper、Blackwell和Ada Lovelace,每一代都针对日益复杂的数据中心工作负载进行了优化。以下是主要架构的里程碑:
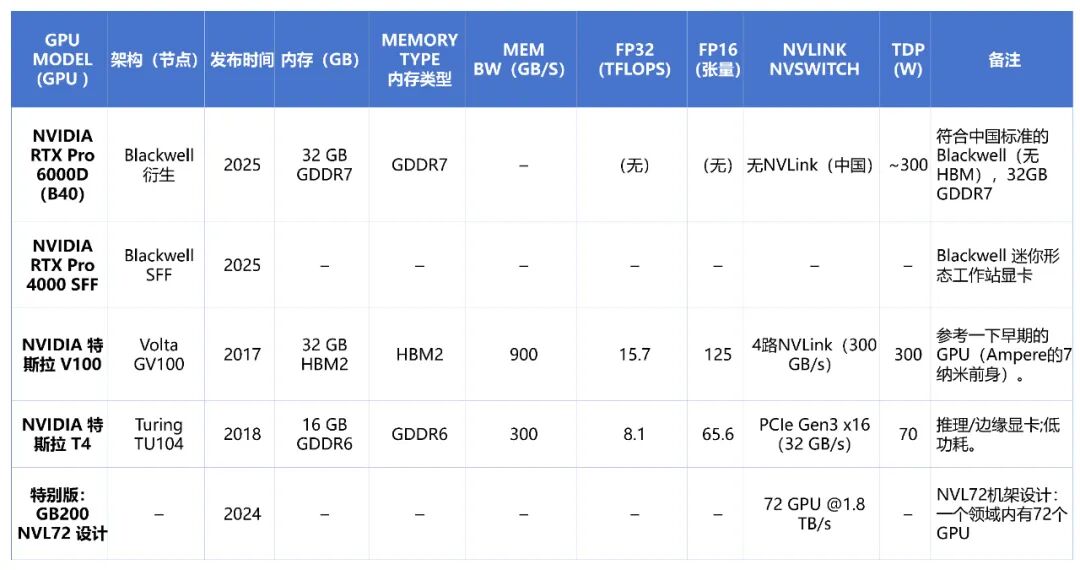
- Volta(2018年):推出了V100,配备第一代Tensor Core用于混合精度计算和NVLink 2.0互连。其单精度(FP32)性能约为15 TFLOPS。
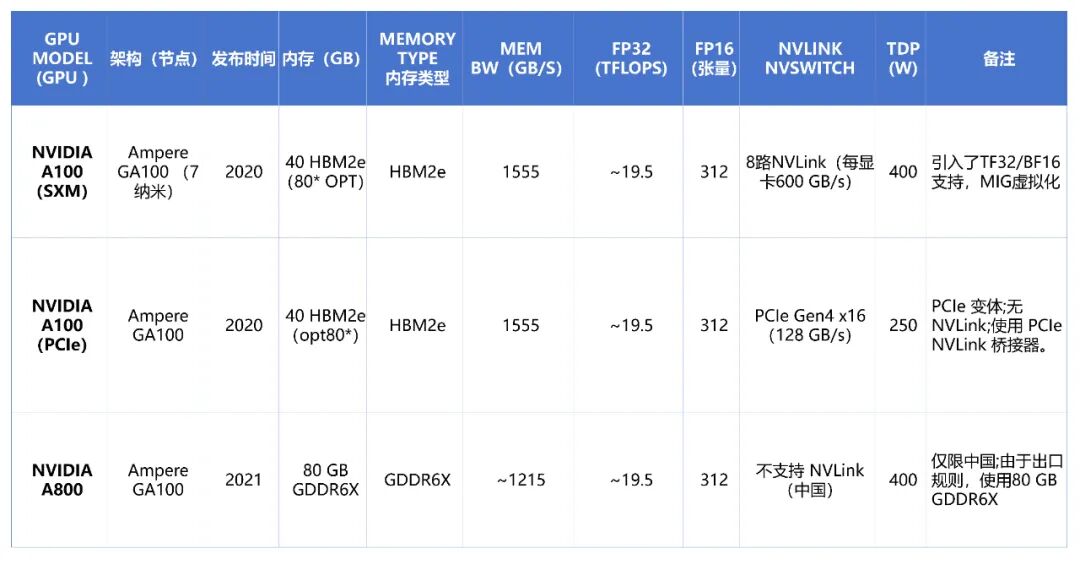
- Ampere(2020年):作为英伟达第八代架构,推出了A100 GPU。它基于Ampere GA100芯片,采用7nm工艺,集成约540亿晶体管。关键特性包括支持TF32、BFLOAT16数据格式的第三代Tensor Core,以及多实例GPU(MIG)虚拟化技术。A100 SXM模块的FP16矩阵运算性能达到约312 TFLOPS,并通过NVLink 3.0实现了每卡600 GB/s的高速互连。其变体包括面向中国市场的A800以及面向图形与虚拟化工作负载的A40、A10等。
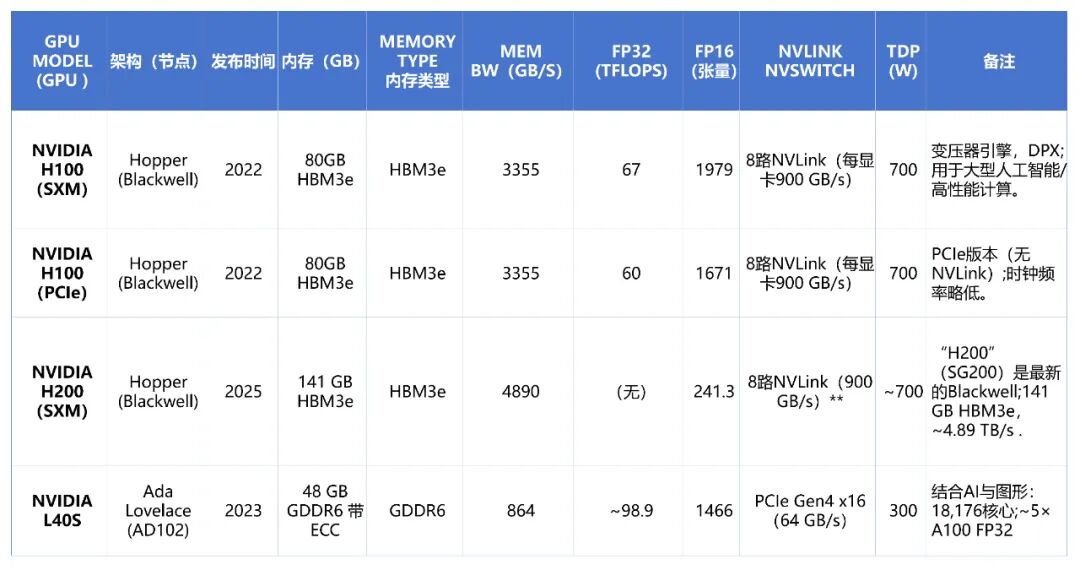
- Hopper(2022年):第九代Hopper架构首见于H100 Tensor Core GPU。它采用4nm工艺,晶体管数量达到800亿,并配备80 GB HBM3e内存。Hopper引入了Transformer引擎,专门优化FP8/FP16混合精度计算以加速大语言模型训练。H100 SXM的FP16性能高达1,979 TFLOPS,并将NVLink带宽提升至每GPU 900 GB/s。后续推出的H200则配备了141 GB HBM3e内存,带宽约4.89 TB/s。
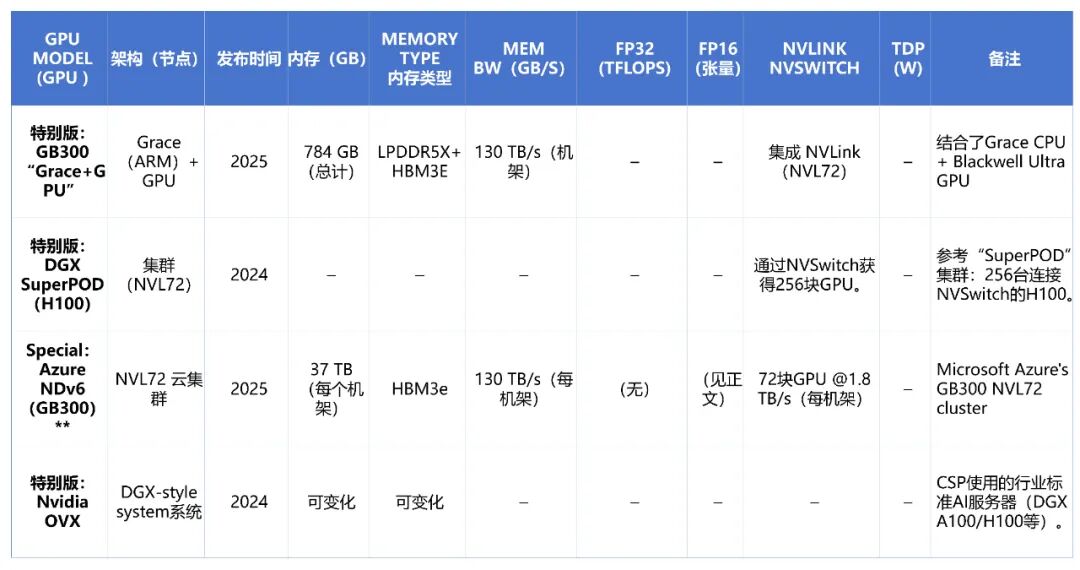
- Grace超级芯片:2022年至2025年间,NVIDIA将其GPU与基于ARM架构的Grace CPU集成,形成超级芯片。例如GH200(Grace + Hopper)和GB300(Grace + Blackwell),它们在单一封装内整合了多达96核的ARM CPU与高性能GPU,通过一致的内存架构,主要针对大规模AI模型和高性能计算(HPC)工作负载进行优化。
- Ada Lovelace(2023年):该架构面向数据中心,推出了L40S GPU。它采用与消费级RTX 4090同源的AD102核心,但配置为数据中心用途,拥有18,176个CUDA核心和48GB GDDR6显存。NVIDIA称其FP32性能达到A100的约5倍,适用于AI推理、3D渲染和虚拟工作站等场景。
2、NVIDIA 数据中心 GPU 规格详情
下表对比了当前主流NVIDIA数据中心GPU的关键规格,涵盖Ampere、Hopper、Ada Lovelace架构及Blackwell变体。

3、NVIDIA 数据中心GPU的详细特性
内存与计算
英伟达数据中心GPU以高带宽、大容量的板载内存著称。例如,A100 80GB版本提供1.555 TB/s的HBM2e内存带宽,而H100(80GB HBM3e)将此数值提升至约3.355 TB/s。最新的H200则拥有141GB HBM3e,带宽高达约4.89 TB/s。相比之下,专注于图形与推理的L40S采用48GB GDDR6显存,带宽为864 GB/s,在成本与功耗上更具优势,但绝对带宽低于HBM方案。
计算性能方面,A100 SXM的FP32性能约为19.5 TFLOPS。H100 SXM则实现了67 TFLOPS的FP32性能,FP16性能达到1,979 TFLOPS,提升显著。L40S凭借其大量的CUDA核心(18,176个),在部分推理与图形工作负载中展现出强劲性能。
多GPU互连:NVLink、NVSwitch和NVL72
对于大规模AI训练集群,GPU间的高速互连至关重要。NVIDIA提供了超越PCIe的NVLink技术。在Hopper架构中,每块H100 GPU通过NVLink 4.0可实现高达900 GB/s的双向带宽。
NVSwitch芯片用于构建更大规模的互联网络,例如在DGX或SuperPOD系统中,可将多个GPU(如16个或更多)连接成一个全网状结构,使所有GPU能像在一个总线上一样高效通信,这对紧密耦合的分布式训练任务必不可少。
最新的NVL72架构将互连规模推向新高度。在Blackwell GPU的设计中,一个NVLink域可包含多达72个GPU,每GPU链路速度达到1.8 TB/s。这种规模的飞跃能显著加速巨型模型的训练与推理。例如,一个1.8万亿参数的混合专家模型(MoE)在NVL72系统上的训练速度可比8-GPU系统快约4倍。
多实例GPU(MIG)与虚拟化
为提高GPU在云环境中的资源利用率,从Ampere架构开始,A100/H100等GPU支持硬件级的多实例GPU(MIG)功能。它允许将一块物理GPU划分为最多7个独立的、具备隔离内存和计算资源的实例,从而让多个用户或任务安全地共享单块GPU。
内存架构与效率
采用HBM(高带宽内存)是旗舰数据中心GPU的标志。通过NVLink,多GPU系统中的HBM内存可以被聚合,形成一个统一的大内存池。例如,一个8卡H100 SXM节点可提供总计640GB的快速统一内存。
随着GPU性能与密度的不断提升,散热与供电成为关键挑战。例如,NVL72参考设计需要应对每个机架高达120kW的热负载,这推动了直接液冷等先进散热技术在数据中心的大规模应用。高效的云原生基础设施与运维体系对于管理此类高密度计算集群变得日益重要。 |  发表于 2025-12-16 17:30:27
|
查看: 348|
回复: 0
发表于 2025-12-16 17:30:27
|
查看: 348|
回复: 0
