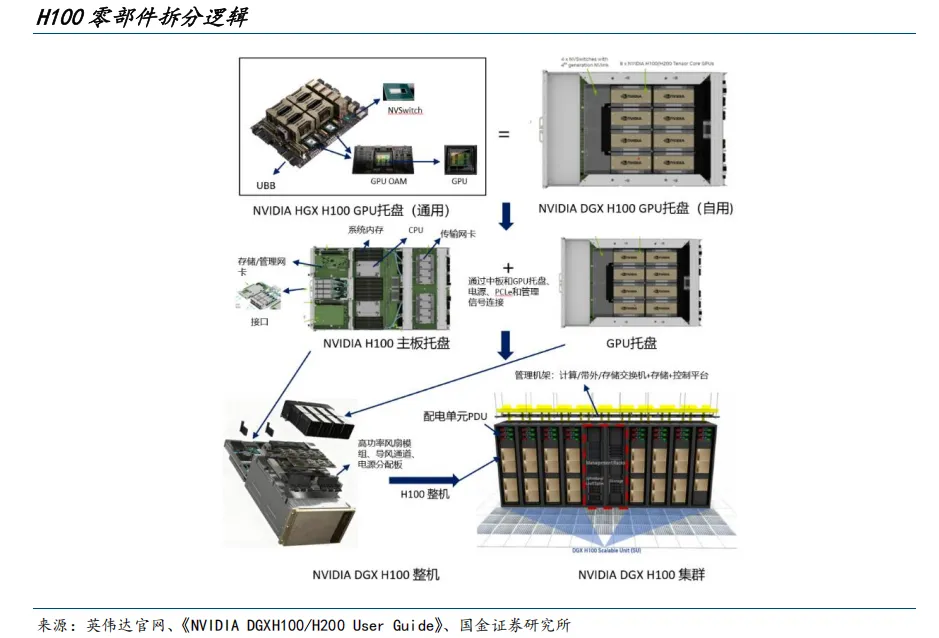
当前市场对于AI服务器乃至计算中心的讨论多集中于单一部件,本文将以更全面的视角,梳理AI计算系统的整体硬件组成。以英伟达DGX H100整机为例,AI数据中心架构普遍遵循“芯片、模块、互联、托盘、主机、机架、集群”的层层递进逻辑,目标是在标准化封装与高带宽互联的约束下,将单点算力有效汇聚为可编排的集群算力。
芯片层:算力核心
最底层的H100 GPU芯片是系统的算力核心。在H100这一代,HBM(高带宽内存)与GPU核心采用共同封装(CoWoS),通常由“GPU核心裸片+多颗HBM堆叠+封装基板”组合而成。GPU裸片与HBM直连,显著提升了模型参数与激活数据的访问带宽,缓解了访存瓶颈。
此外,GPU芯片内还集成了NVLink控制器,相当于GPU自带了高速互连接口能力。该接口从芯片封装边缘引出,连接到外部的互联载体(例如通过UBB基板走线连接至NVSwitch芯片),进而连接到其他GPU,为后续多GPU点对点互联提供了物理通道。这一层可被视为“发动机”,具备优异的能效密度,但尚未具备系统落地所需的供电、散热与标准接口能力。
加速器模块层:标准算力单元
在芯片之上,NVIDIA采用OAM(OCP加速器模块)标准将H100制作为可替换、可维护的加速器模块。OAM模块搭载一颗已封装的GPU芯片,并在模块上集成了稳压供电电路、机械与热接口以及高速电触点。这一步的本质是将裸硅芯片转化为“标准的算力砖”,既满足了数据中心高功耗场景的工程化要求,又为后续的高密度部署与快速维护提供了成本优势。至此,单卡的算力已经可用,但要实现多卡强耦合并扩展到系统级吞吐,还需要一个面向互联的结构化基座。
通用基板层:GPU计算岛
通用基板(UBB)是承载并连接多个OAM的平台,其核心增量是引入了NVSwitch芯片,形成一个全互连的GPU高速域。与传统通过PCIe或点对点NVLink链路的“局部互联”不同,NVSwitch提供了交换能力,使得多块H100可以近乎对称的带宽进行任意两两通信,显著降低了跨GPU通信的延迟,改善了大规模并行训练下的同步开销。从系统设计视角看,UBB将若干OAM聚合成了一个“GPU计算岛”。

托盘层:工程化子系统
托盘层可理解为围绕“GPU计算岛”的工程化子系统,它将UBB、若干OAM、NVSwitch、风道与散热模组、线缆与结构件、电源分配与管理信号等一体化封装,形成抽屉式可插拔单元。NVIDIA H100托盘主要有两种形态:
- HGX H100通用托盘:面向整机厂商的开放型部件,便于各家服务器平台快速集成。
- DGX H100定制托盘:更深度适配英伟达自有整机在布局、气流、线缆路径与维护工艺上的要求。
无论形态如何,托盘层完成了“从电路板到产品”的关键跨越,将高带宽互联与高功耗散热在机械空间内稳定落地,为与通用计算平台对接创造了条件。
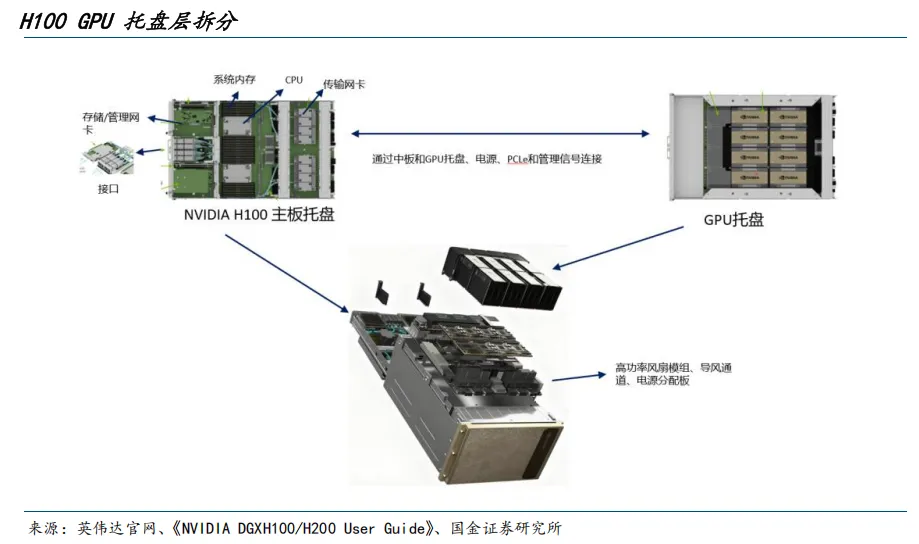
与GPU托盘配套的是主板托盘。主板托盘承载通用计算与系统入口职能,典型配置为双路高性能CPU与大容量系统内存,同时部署PCIe根复合体、网络与存储接口以及带外管理控制器(BMC)。在逻辑分工上,CPU负责任务编排、数据预处理、I/O管理与操作系统/驱动层协同,通过中板或背板与GPU托盘完成PCIe传输及管理连接,并在运行时将数据有序输送至GPU计算岛,再汇总结果。由此,计算系统的“指挥中枢”(CPU/内存)与“加速引擎”(8×H100 GPU)形成了高效协作。
整机层:系统节点
当GPU托盘与主板托盘、电源与配电单元、风扇与风道、机箱结构与面板、网络与本地存储等子系统集成进同一机箱后,便构成了DGX H100整机节点。
数据中心层:集群部署
整机节点需要与机柜配电和机房基础设施配合。多个DGX H100节点安装于标准机柜中,机柜上方配有PDU(配电单元),负责回路分配、计量与保护。此外,为了让H100整机能够高速协作,机柜内会配有专门的管理机架,包含高带宽的计算交换机、存储交换机、带外管理交换机以及管理服务器和存储设备。
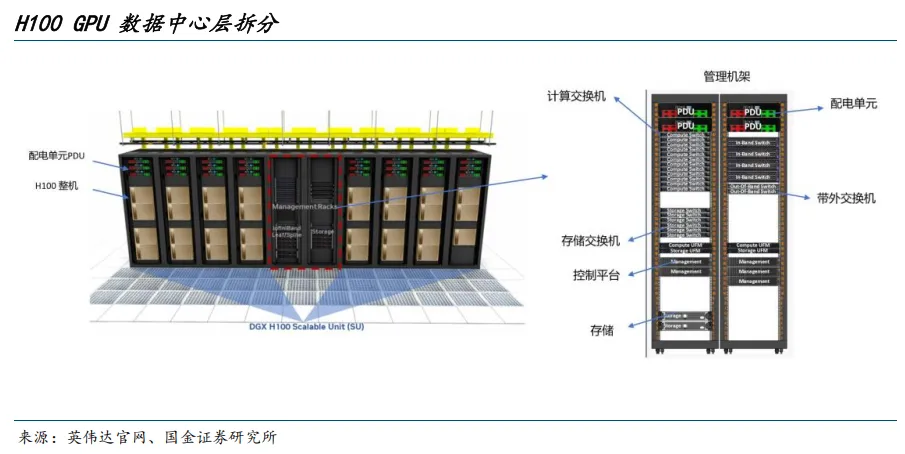
交换机的构造类似于主机。计算、带外、存储交换机都有共同的骨架:主PCB承载交换ASIC,前面板是SFP/QSFP笼体,后部是可热插拔PSU与风扇,控制板/CPU位于中部,采用前冷后热的风道设计。AI数据中心所需的高性能计算交换机需要支持更高功耗、更高速率端口、更强散热与多ASIC互联,但其基本构成仍可归纳为五件套:交换ASIC、前面板端口与光模块、控制CPU、电源与散热系统、机箱与背板。

新一代高性能AI服务器机柜更倾向于采用“超节点”架构。例如,NVL72就是典型的机柜级超节点,一柜内集成72块GPU,通过柜内的NVLink Switch实现全互联,侧重在“单柜内形成一个大规模算力域”以达到极致性能。从结构上讲,超节点架构主要改变了互联方式,域内GPU不再依赖外部交换机,但更高密度的集成也匹配了更高功率的电源模块和更高效的散热解决方案。
相比通用服务器,AI服务器在算力芯片与内存带宽上大幅增强,整机价值量分布也显著上移,其他配套部件相应升级。根据行业数据,NVIDIA DGX H100中,GPU板组(含HBM)约占整机价值的73%,存储约占4%,封装、电源、散热部件等占比较小。
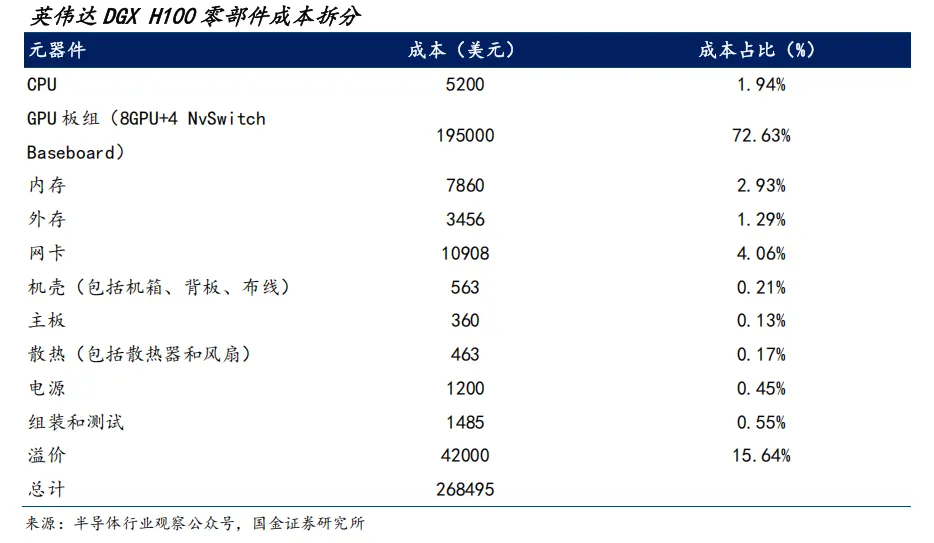
在DGX H100机柜中,涉及核心材料的零部件主要包括:GPU、NVSwitch、CPU、网卡等高性能逻辑与控制芯片;HBM、DDR等存储芯片;硅光/电光器件与光模块内的驱动与TIA芯片;电源管理芯片与各类功率半导体器件。这些器件共同决定了系统的算力、带宽与能效边界,是技术门槛与价值密度最高的环节。
 发表于 2025-12-16 03:01:44
|
查看: 329|
回复: 0
发表于 2025-12-16 03:01:44
|
查看: 329|
回复: 0
