
想象一下,在CES 2026的舞台上,黄仁勋正式宣布其新一代AI超级计算平台Vera Rubin已进入全面投产阶段。这并非遥不可及的未来,而是基于现有技术路线的合理推演。
根据构想,Rubin GPU将搭载第三代Transformer引擎,其NVFP4推理/训练算力将达到惊人的50/35 PFLOPS,是前代Blackwell平台的5倍和3.5倍。更引人注目的是其存储架构的革新:HBM4带宽高达22TB/s,晶体管数量跃升至3360亿个,这些都直指一个核心问题——如何突破AI计算中的“内存墙”瓶颈。
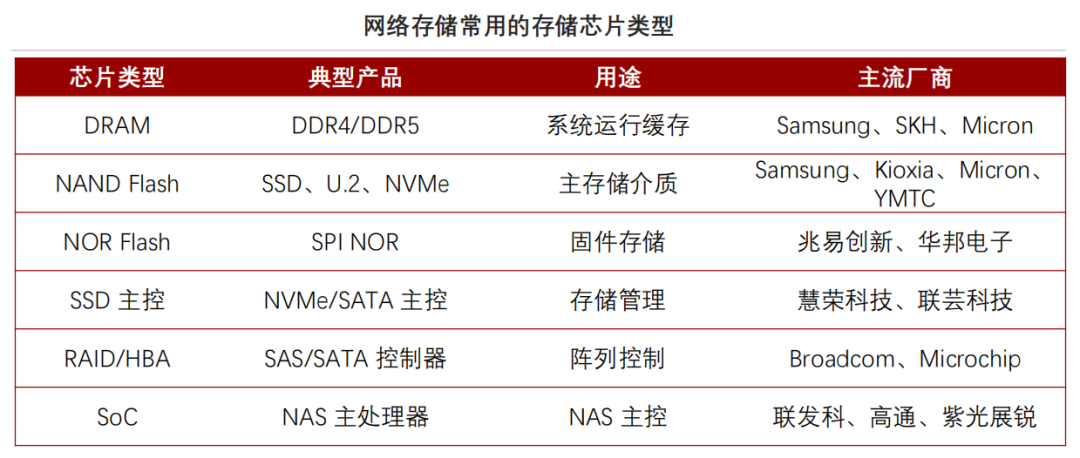
Vera Rubin 全面投产,重构存储架构改善“内存墙”困境
Vera Rubin平台的核心变革在于重构了HBM、DRAM、NAND组成的三层存储金字塔。在智能体(Agentic AI)时代,AI需要记住漫长的对话历史和复杂的上下文,这会产生巨大的KV Cache(键值缓存)。传统的解决方案是将这些数据全部塞进昂贵的HBM显存中,但HBM容量有限且成本高昂。
为此,英伟达设计了全新的存储架构,推出了由BlueField-4驱动的第三层推理上下文内存存储平台。这一设计旨在让系统每秒处理的token数量提升高达5倍,从根本上优化数据在各级存储间的流动效率。这场围绕计算与存储的协同设计,正在重新定义高性能AI基础设施的形态。
HBM4:与GPU深度绑定的“计算核心”
Rubin GPU集成了新一代高带宽内存HBM4。与HBM3e相比,HBM4的接口宽度增加了一倍。通过全新的内存控制器、与内存生态系统的深度协同设计以及更紧密的计算-内存集成,Rubin GPU的内存带宽几乎达到了Blackwell的三倍。
具体而言,每颗Rubin GPU的HBM4容量为288GB,带宽为22TB/s。它已不再仅仅是GPU附近的“高速缓存”,其性能直接成为了整个系统吞吐能力的硬性约束。从市场角度看,HBM4的单价较HBM3e有显著提升,有望明显带动内存原厂的毛利率。
LPDDR5X:负责存放“温热”的KV缓存数据
在Vera Rubin平台中,CPU部分(Vera CPU)升级采用了LPDDR5X内存。Vera将可扩展一致性结构(SCF)与高达1.5TB的LPDDR5X内存子系统相结合,能在低功耗下提供高达1.2TB/s的带宽。相比之下,上一代Grace平台的配置为480GB LPDDR5X和512GB/s带宽。
在实际应用中,系统可将LPDDR5X和HBM4视为一个统一的一致性内存池,这极大地减少了不必要的数据移动开销,并高效支持了KV缓存卸载和多模型并行执行等关键技术。这一设计体现了现代计算机体系结构中对内存层级优化的深刻思考。
NAND与DPU:BlueField-4驱动的推理上下文存储平台
Vera Rubin在机架内部署了BlueField-4处理器,专门用于管理海量的KV Cache。BlueField-4集成了64核的Grace CPU和高带宽LPDDR5X内存,并配备了ConnectX-9网络接口,可提供高达800 Gb/s的超低延迟以太网或InfiniBand连接。
容量是这一层的最大亮点。在每个GPU原有1TB HBM内存的基础上,BlueField-4 DPU内存存储平台额外为每个GPU增加了16TB的存储容量。对于一个NVL72规格的机架而言,这意味着总共增加了1152TB的可用内存。这类专为加速和卸载存储任务而设计的DPU,正成为智算中心不可或缺的一部分。
综上所述,英伟达Vera Rubin平台通过精细化的存储层级设计,用HBM4担当极致性能核心,用大容量LPDDR5X承载温热数据,再用DPU管理的扩展存储解决海量上下文需求,系统地回应了AI对高带宽、大容量、低延迟的复合诉求。这不仅是单一产品的升级,更代表了AI算力基础设施向存储感知型架构演进的重要趋势。对这类前沿技术动态的持续追踪与解读,正是像云栈社区这样的开发者社区所关注的核心。 |  发表于 2026-1-18 06:27:28
|
查看: 249|
回复: 1
发表于 2026-1-18 06:27:28
|
查看: 249|
回复: 1

