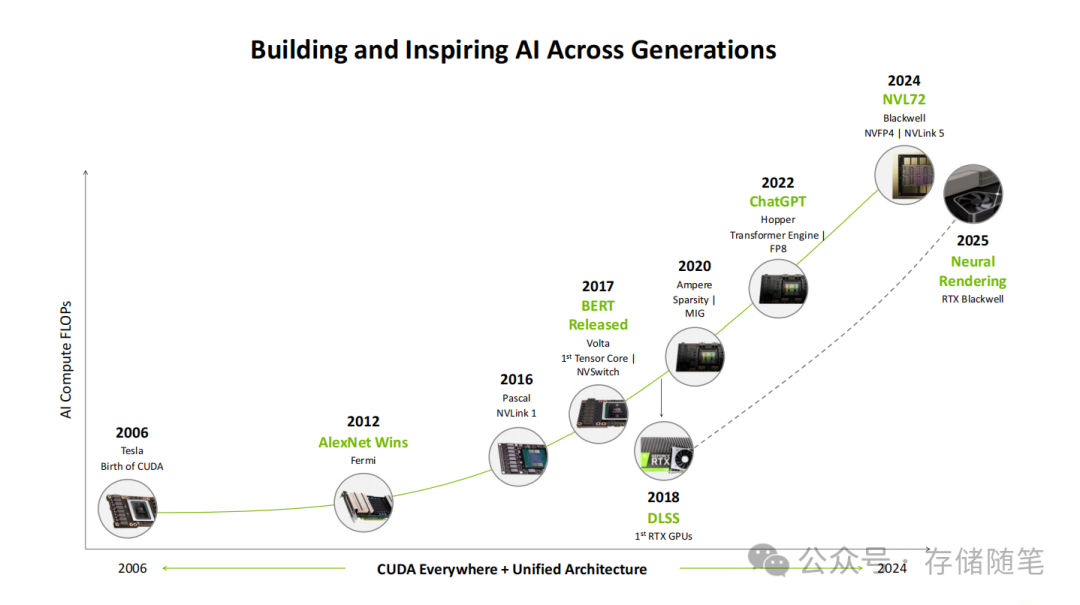
当AI与图形渲染的融合迈入深水区,NVIDIA以基于Blackwell架构的RTX 5090给出了答案。这款旗舰GPU远不止是常规的硬件迭代,它是为“神经渲染时代”量身打造的全场景计算平台。它横跨数据中心与桌面终端,将传统图形管线与AI生成技术深度耦合,试图重新定义视觉计算的性能与能效边界。

一、Blackwell架构:从数据中心到桌面的统一计算底座
NVIDIA的核心战略始终清晰:用统一架构覆盖全场景计算需求。Blackwell架构完美延续了这一思路,其设计从GB300 NVL72这样的机架级解决方案,一路下探至RTX 5090桌面GPU,实现了从15 PetaFLOPS密集型计算到终端级AI渲染的无缝衔接。
1. 架构全局设计:密度与带宽的双重突破
Blackwell架构的核心优势在于“极致并行”与“高效互联”的结合。以GB300 NVL72机架为例,72块Blackwell Ultra GPU被整合进一个统一计算域,配备高达288GB的HBM3e高速内存,内存带宽达到惊人的8 TB/s——这一数据远超前代Hopper架构,足以支撑大规模神经渲染所需的海量数据吞吐。
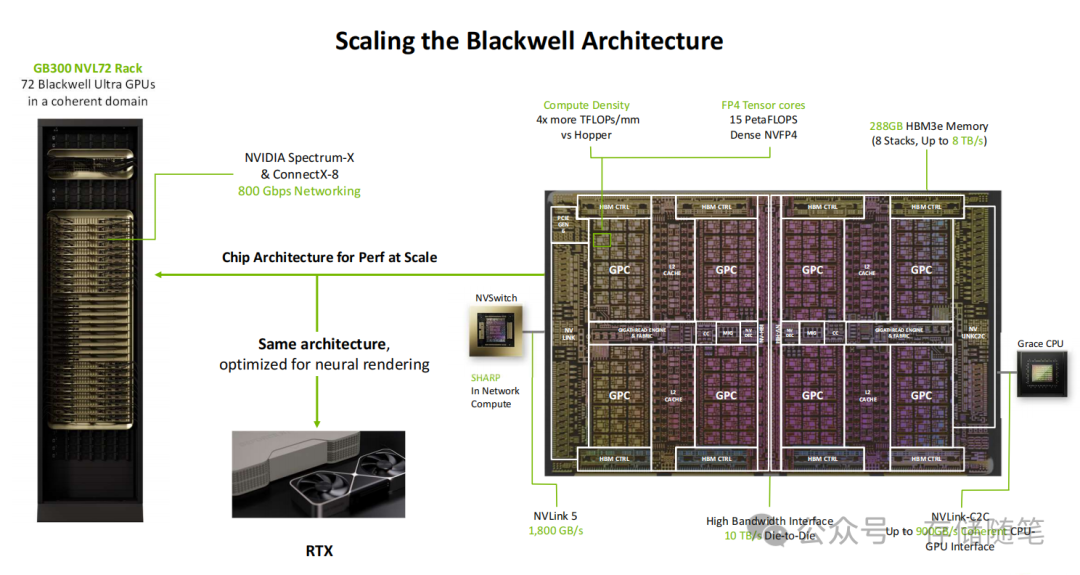
在芯片互联层面,NVLink 5技术实现了1800 GB/s的GPU间传输速度。配合Spectrum-X网络与ConnectX-8网卡提供的800 Gbps外部带宽,构建了“芯片-机架-数据中心”三级高速互联体系。而与Grace CPU的NVLink-C2C接口则达成了900 GB/s的一致性传输,让CPU与GPU能够实现近乎无延迟的协同,有望彻底解决传统异构计算中的带宽瓶颈问题。
2. 核心计算单元:为神经负载重构硬件
Blackwell架构的每一个核心组件都围绕“神经渲染”这一核心场景进行了深度优化。

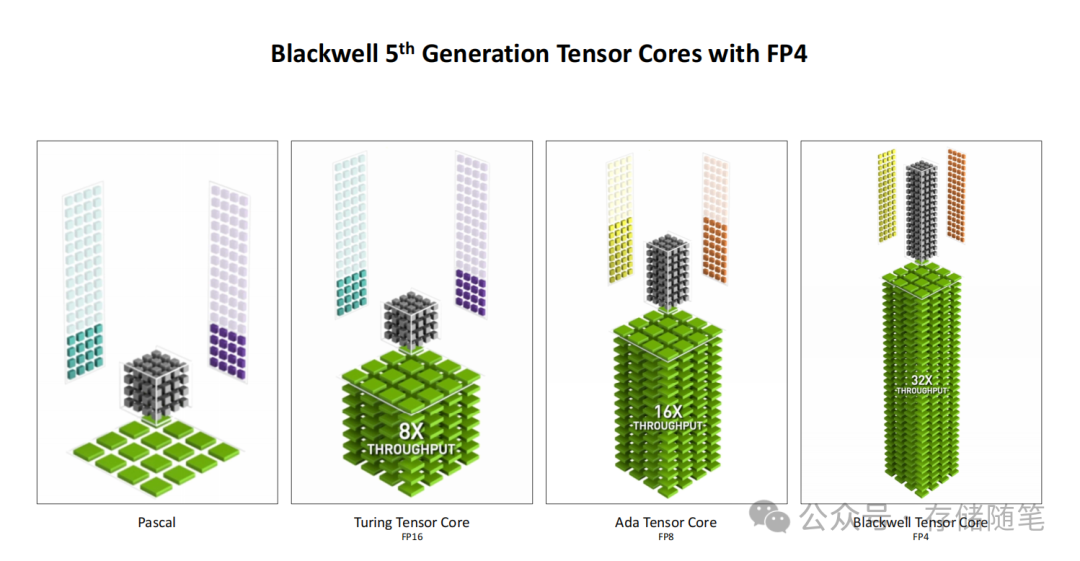
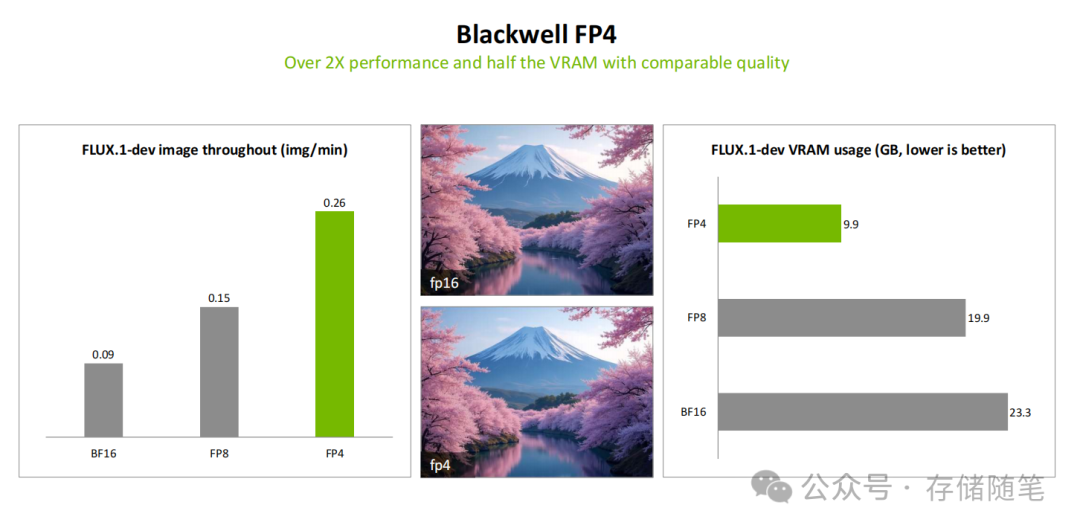
- 第五代Tensor Core:首次引入FP4精度计算,实现了4000 AI TOPS的算力输出。相比Ada架构的FP8精度,FP4在保持视觉质量相当的前提下,将吞吐量提升2倍以上,同时显存占用减少50%。在FLUX.1-dev模型的测试中,FP4精度下的图像生成速度达到FP8的1.7倍,VRAM占用从19.9GB大幅降至9.9GB。
- 第四代RT Core:提供360 RT TFLOPS的算力,专门针对“超大几何量”场景设计,能够高效处理包含亿级多边形的光线追踪计算,为神经渲染提供精准的物理光照基础。
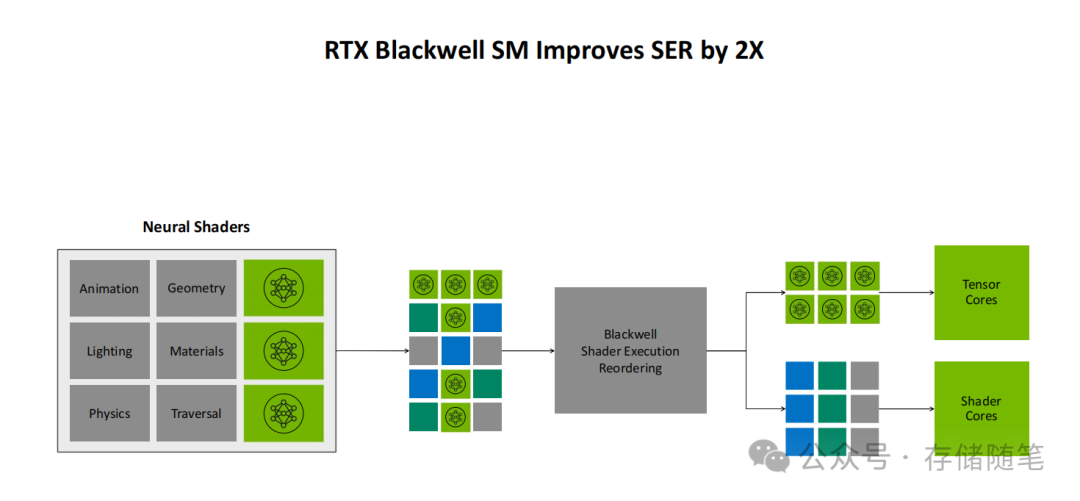
- Blackwell SM单元:125 TFLOPS的算力密度较前代有显著提升。其创新的着色器执行重排(Shader Execution Reordering, SER)技术将SER效率提升了2倍,让神经着色器能够更高效地调度和处理动画、几何、材质等多维度的渲染任务。
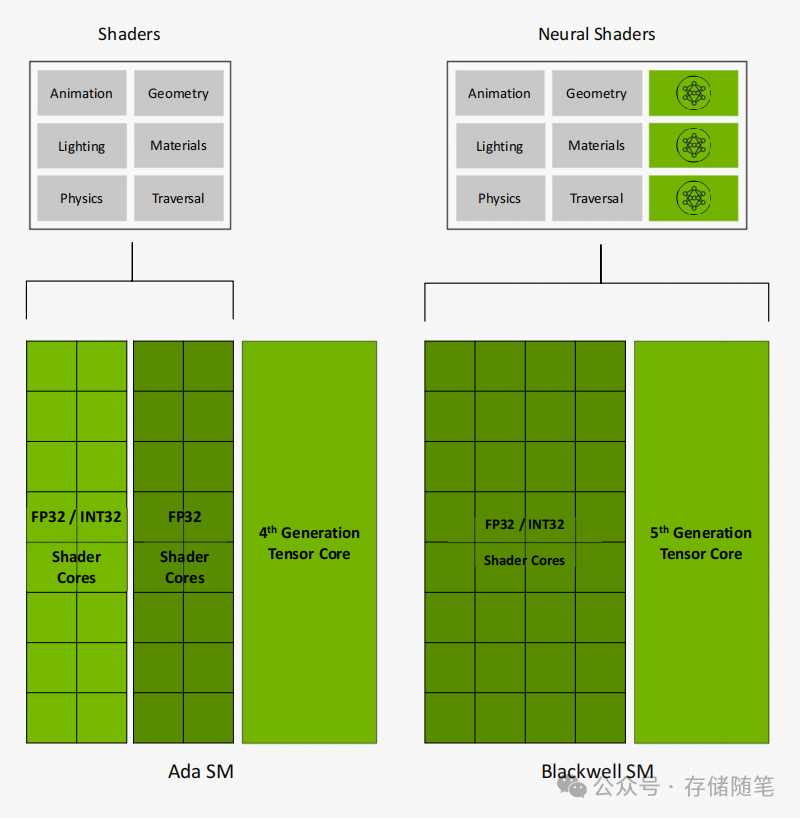
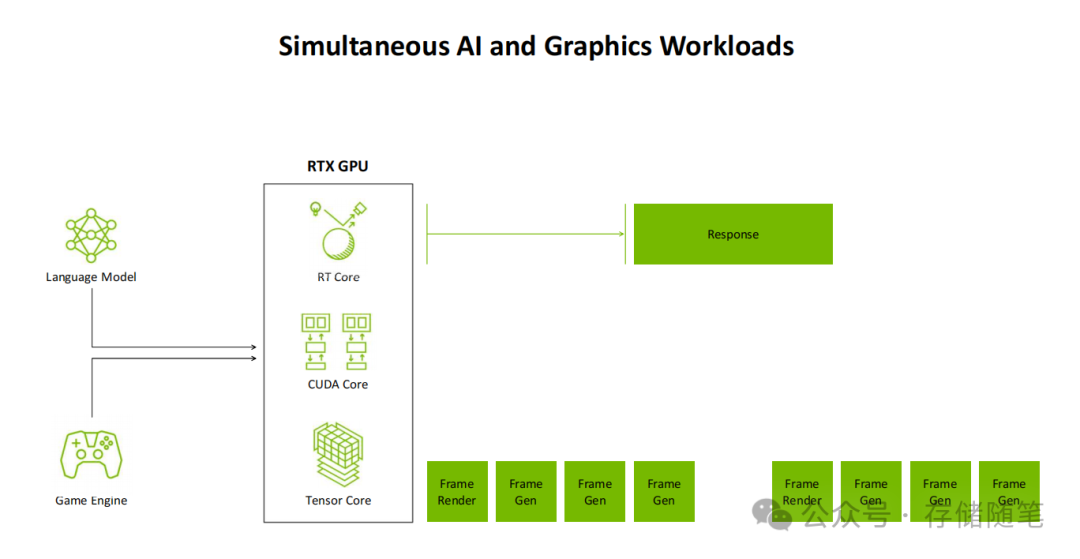
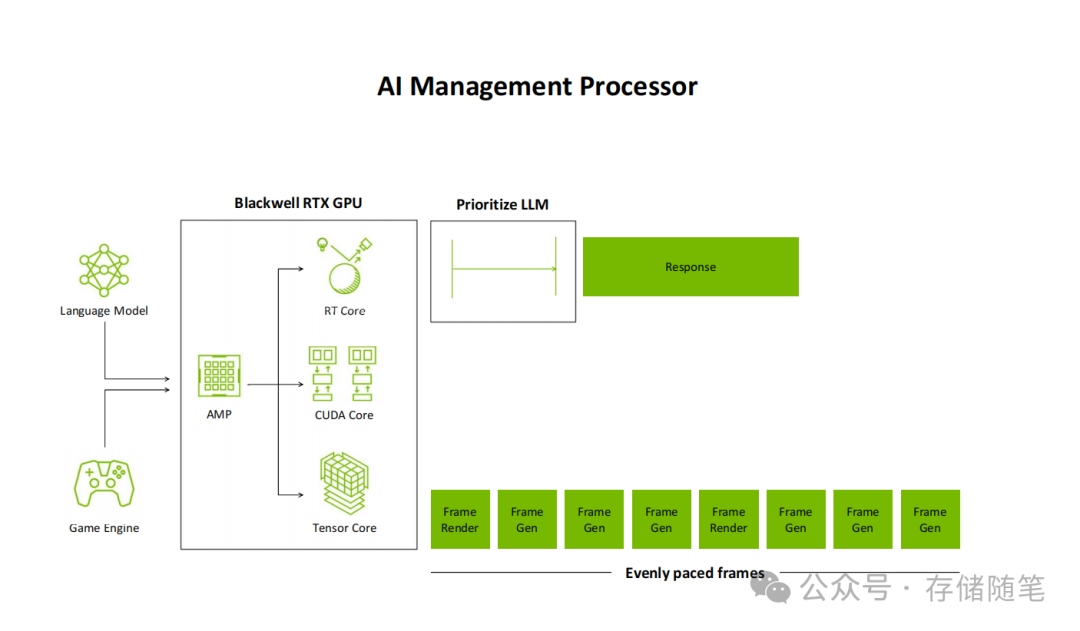
- AI管理处理器(AMP):这是Blackwell架构的点睛之笔。它实现了AI模型与图形渲染任务的并行调度与资源管理——在游戏引擎渲染画面的同时,语言模型、智能代理等AI工作负载可以同步运行,且互不干扰,旨在解决传统GPU“单任务独占”导致的资源利用率问题。
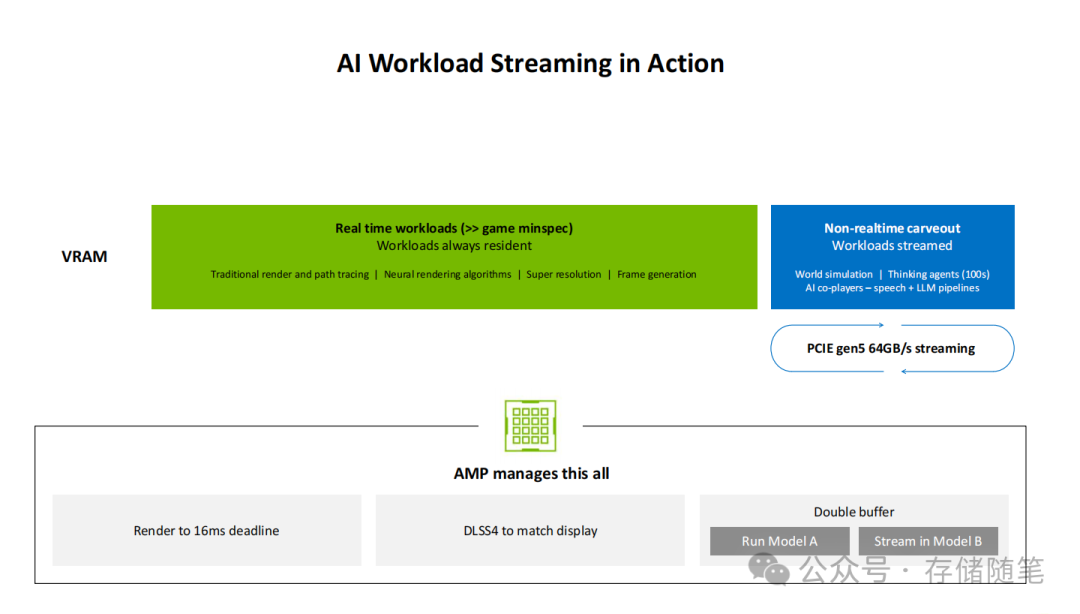
二、关键技术革新:重新定义图形计算的三大支柱
RTX 5090的技术突破是一个完整的体系,围绕“性能、能效、灵活性”三大支柱构建,每一项创新都直指当前行业痛点。
1. 显存革命:GDDR7成为新一代图形内存标准
显存技术的迭代往往是图形性能跃升的关键。RTX 5090搭载的GDDR7内存带来了双重突破:
- 性能翻倍:采用PAM3调制技术,数据传输速率达到30 Gbps,是GDDR6的2倍,旨在彻底解决4K/8K神经渲染时的显存带宽瓶颈。
- 能效优化:相比GDDR6x的PAM4技术,GDDR7在更高频率下实现了更低的工作电压,能量效率提升2倍,每比特传输的能耗显著降低。
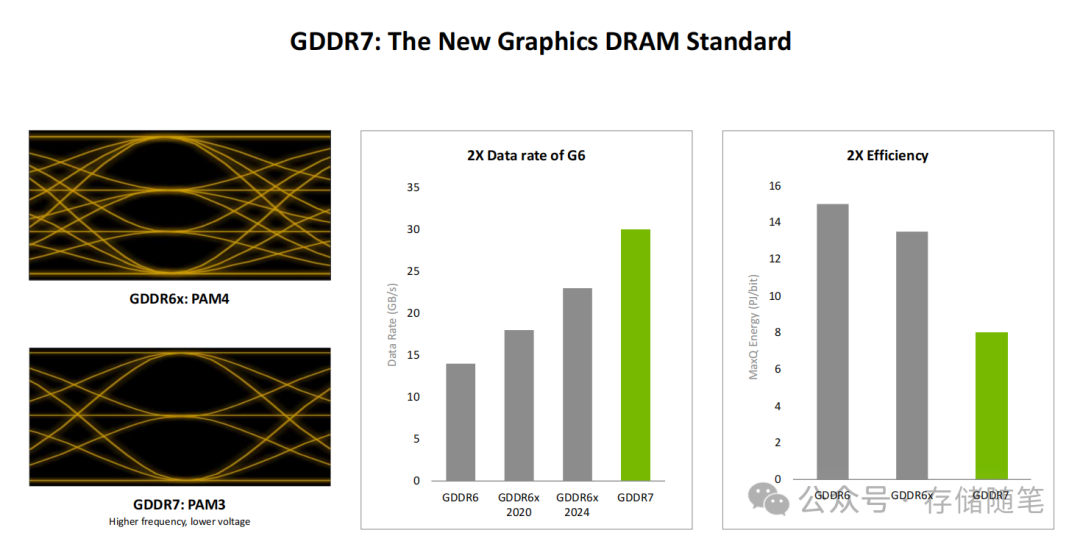
这一革新让RTX 5090能够更从容地应对“100%像素AI生成”的极端神经渲染场景——当所有像素都需要通过AI模型实时推理生成时,GDDR7的高带宽与低延迟成为流畅体验的核心保障。
2. 能效突破:Blackwell MAXQ技术重塑移动与桌面体验
能效比的提升是Blackwell架构的核心目标之一。MAXQ技术的升级让RTX 5090在性能飙升的同时,实现了2倍的功耗效率提升。这一技术并非简单的降频,而是通过三大创新实现:
- 10倍更快的核心轨门控(core rail gating),可动态关闭闲置的计算单元;
- 100倍更快的DRAM自刷新状态切换,显存闲置时可立即进入低功耗状态;
- 智能的电压调节算法,根据实时工作负载动态调整供电策略。
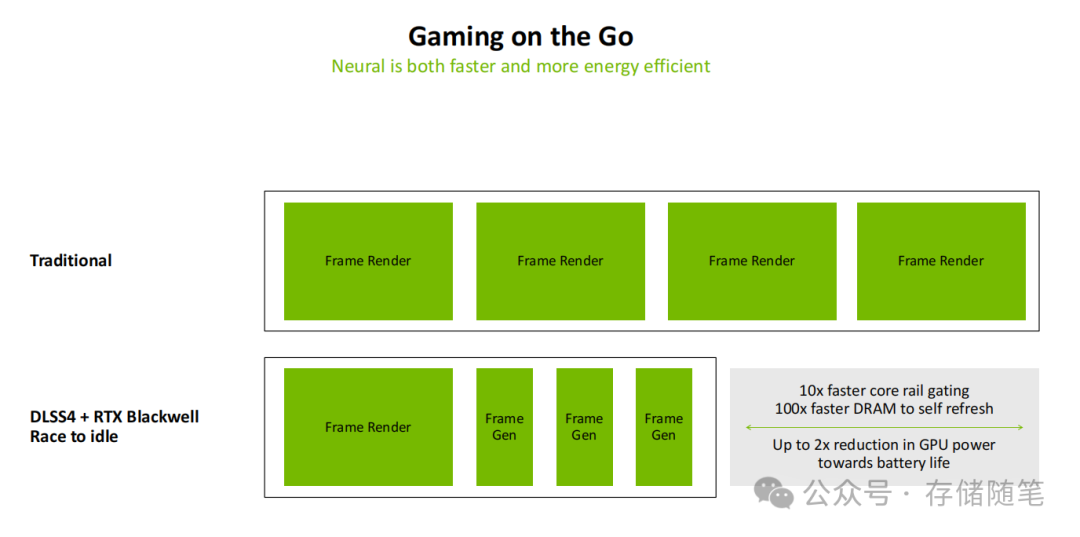
在移动场景中,这一优化带来了革命性的体验潜力:搭载RTX Blackwell架构的笔记本电脑,在运行3A游戏时可实现“渲染-生成-快速休眠”的循环,GPU功耗降低最高可达50%,续航能力有望显著提升,目标是实现移动设备上高性能与长续航的兼得。
3. 多任务灵活性:通用MIG解锁GPU虚拟化潜能
针对专业工作站等场景,基于Blackwell架构的RTX PRO 6000引入了通用多实例GPU(Universal MIG)技术。该技术能够将一块完整的物理GPU硬件划分为最多4个独立的实例,每个实例配备24GB显存、专属的SM单元、L2缓存与带宽资源。
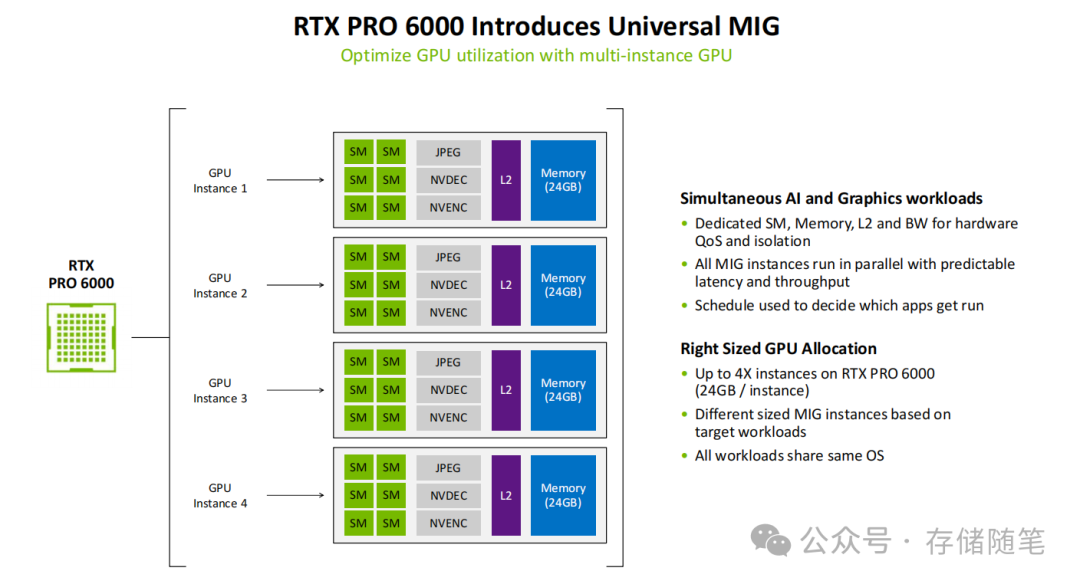
这种硬件级别的隔离带来了三大优势:
- 多任务并行运行时互不干扰,每个实例都能获得可预测的延迟与吞吐量性能;
- 不同尺寸的MIG实例可以灵活适配不同的工作负载(如AI推理、视频编码、3D渲染);
- 所有实例共享同一操作系统,降低了部署与管理的复杂度。
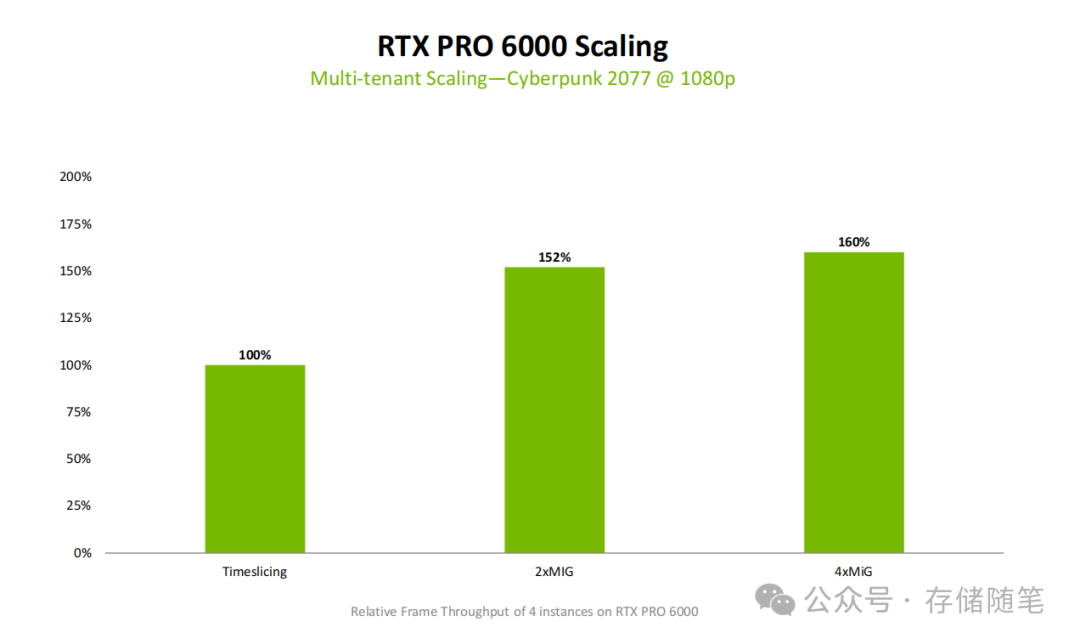
在《赛博朋克2077》1080p分辨率的测试中,启用4个MIG实例所获得的总帧率吞吐量,可以达到传统时间分片技术的1.6倍,GPU利用率实现了质的飞跃。
三、神经渲染:从技术概念到落地体验的质变
RTX 5090的终极使命,是将“神经渲染”从前沿的实验室技术转化为全民可感知的产品体验。这种深度融合AI与传统图形的渲染方式,正从多个维度重构视觉计算:
1. 性能与画质的双重飞跃
神经渲染通过AI模型替代或优化部分传统渲染管线,实现了“10倍性能提升”量级的突破——在相同画质下,渲染速度获得数量级提升;在相同硬件条件下,视觉保真度达到新的高度。更重要的是,这种提升覆盖全场景:从3A游戏的4K/120fps流畅运行,到创作者的实时3D建模与预览,再到数据中心的大规模虚拟场景生成,都能受益于神经渲染带来的效率革命。

2. 自适应与个性化的交互体验
传统游戏的玩法与内容是相对固定的,但神经渲染让“游戏随玩家共同成长”成为可能。RTX 5090支持同时运行数千个“思考智能体”(Thinking Agents),这些具备自主决策能力的AI角色能够根据玩家的行为习惯实时调整游戏进程,创造出独特的“涌现式体验”——每一次游戏过程都可能触发全新的剧情分支与互动方式,旨在打破传统线性叙事的局限。
3. 全场景覆盖的灵活性
神经渲染的高效性让其能够适配从桌面到移动的全设备形态:
- 桌面端:RTX 5090可驱动8K/120Hz显示器(通过DisplayPort 2.1 UHBR20接口),结合DLSS 4技术,实现“渲染+生成”的双重超分辨率,在保证高画质的同时大幅降低原生渲染的硬件负载;

- 移动端:借助MAXQ技术的能效优化,高性能轻薄本也能流畅运行支持神经渲染的游戏,通过“快速渲染-多帧生成-迅速进入低功耗”的循环,在16ms的帧时间内完成画面输出,兼顾性能与续航;
- 专业创作端:创作者通过NVIDIA Omniverse等工具链,可利用神经渲染技术将设计周期缩短数倍,实现从概念设计到最终渲染的全流程实时迭代与协作。
四、生态布局:构建神经渲染的完整生态系统
硬件的强大潜力需要软件生态的充分支撑。NVIDIA围绕Blackwell架构构建了从底层SDK到上层应用的全栈生态:
- 核心工具链:CUDA与TensorRT提供底层算力优化,确保AI模型与图形任务的高效执行;NIM for RTX则为开发者提供标准化的AI推理微服务接口,旨在降低神经渲染应用的开发门槛。
- 创作与协作平台:Omniverse平台整合了Dynamo SDK等工具,让设计师能够直接调用RTX 5090的神经渲染能力,实现实时3D协作与快速迭代。
- 终端应用生态:游戏开发商可通过NVIDIA提供的神经着色器工具,开发支持“高比例AI生成像素”的新玩法;专业软件则可利用MIG等技术实现多任务并行处理,显著提升工作流效率。
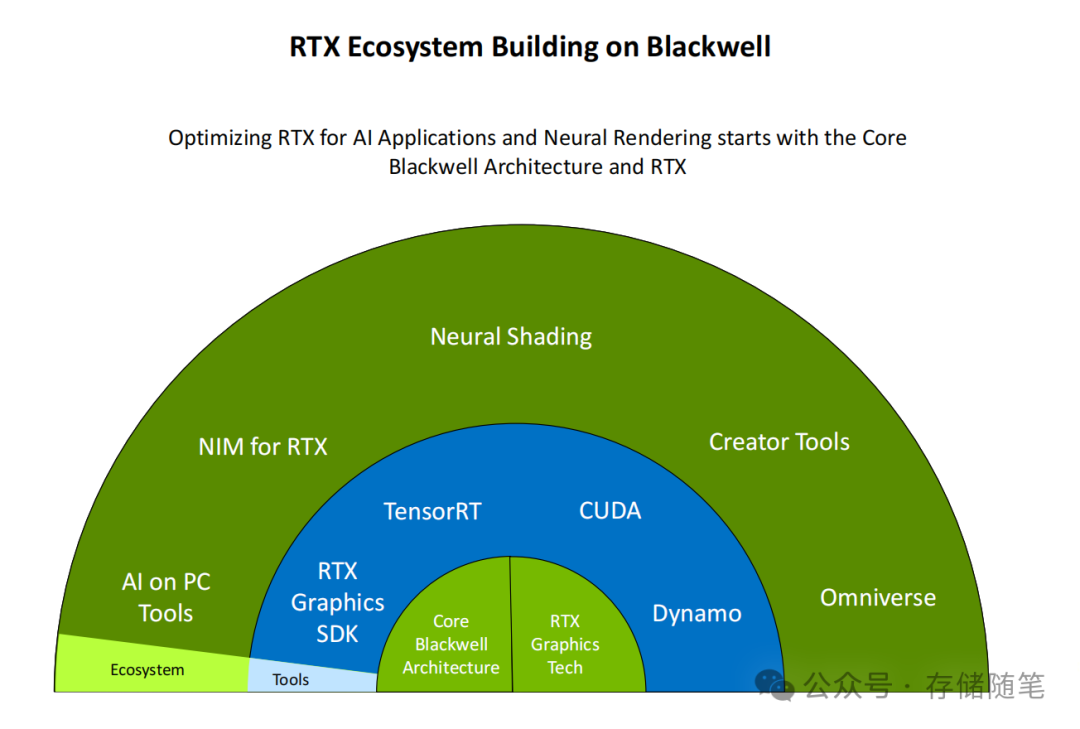
这种“硬件-软件-应用”的深度协同,让RTX 5090不仅仅是一款顶级GPU,更致力于成为神经渲染时代的“生态核心”——使开发者能够快速落地创新应用,让终端用户能够即刻享受到技术进步带来的体验升级。
五、总结:Blackwell架构的行业意义与未来展望
RTX 5090的推出,标志着视觉计算正式迈入“神经渲染时代”。Blackwell架构的核心贡献绝非单纯的参数提升,而在于它建立了一种“AI与图形深度融合”的全新计算范式:它不再将AI仅仅视为图形渲染的辅助工具,而是将二者在硬件架构层面进行深度融合,旨在创造出传统架构难以企及的性能、能效与灵活性组合。
从行业层面看,Blackwell架构实现了“从数据中心到桌面终端”的统一计算底座,让大规模神经渲染任务能够无缝下沉到终端设备,这将极大地加速AI视觉技术的普及——未来不仅是高端游戏本,甚至主流轻薄本、一体机等设备都有潜力提供令人惊艳的神经渲染体验。
从用户视角看,RTX 5090预示着一次“体验革命”:游戏可能不再是预设剧情的重复播放,而是更具千人千面特性的互动叙事;内容创作不再轻易受限于硬件性能,而是能够更实时地将想象力转化为视觉作品;移动计算也不再总是性能与续航的艰难妥协,而是有望实现二者更优的平衡。
正如NVIDIA在技术展望中所强调的:“Blackwell为神经渲染奠定了基础”。这款架构不仅试图定义下一代GPU的技术标准,更致力于开启一个“视觉计算无边界”的新时代。当AI与图形的融合进入深水区,我们有理由期待,RTX 5090所代表的Blackwell架构只是一个重要的起点,更多颠覆性的应用与沉浸式体验,或许正在路上。
参考文献:NVIDIA - Hot Chips 2025 -《RTX 5090: Designed for the Age of Neural Rendering》
 发表于 2026-1-28 10:53:18
|
查看: 345|
回复: 0
发表于 2026-1-28 10:53:18
|
查看: 345|
回复: 0
