在追求高质量视频生成的路上,效率与交互性常常是相互制约的瓶颈。扩散模型能够产出惊艳的画面,但其双向注意力机制却带来了沉重的计算负担,推理速度难以满足实时需求。另一边,基于因果注意力的自回归模型虽然能利用KV缓存进行快速推理,但受限于内存,模型往往只在短视频片段上训练,导致其生成长序列内容时质量会显著下降,出现内容漂移的问题。
更重要的是,除了一次性的静态提示生成,交互能力对于动态内容创作至关重要。它允许用户实时引导叙事走向,但这无疑极大地增加了系统复杂度,尤其在提示切换时,如何保证视觉的一致性与语义的连贯性是一大挑战。
为了攻克这些难题,由NVIDIA、麻省理工学院等顶尖机构组成的研究团队,提出了一个全新的框架——LongLive。这是一个专注于实时交互式长视频生成的解决方案,其论文已被顶级学术会议ICLR 2026收录。LongLive不仅在质量上表现出色,更在效率上实现了巨大突破:训练端,它仅用32个GPU天就将一个13亿参数的模型微调至可生成分钟级视频;推理端,在单张H100 GPU上能达到20.7 FPS的实时帧率,支持生成最长240秒的视频。

方法

图1:LongLive 工作流程。用户连续输入提示,模型实时生成对应视频,并展现出显著优于基线模型SkyReels-V2的性能。
如图1所示,LongLive的核心在于接收用户连续输入的提示,并实时生成相应的长视频,实现用户引导的叙事创作。其技术支柱主要包括以下三点:
1. KV 重缓存
在基于DiT的架构中,交叉注意力层会反复将提示信息注入模型,并通过自注意力层进行前向传播。这导致KV缓存中会持续写入旧的提示信号,当用户切换提示时,缓存中残留的旧语义会干扰新内容的生成,造成提示遵循不一致的问题。
为此,研究团队提出了 KV 重缓存机制。其核心思想是:在提示切换的边界,利用已经生成的视频帧与新的提示重新计算KV缓存。这样做既能“擦除”旧提示的残留,又能保留已有的运动和视觉线索,从而保证时间上的连续性。
具体操作是,切换后的第一帧会将视频前缀编码为视觉上下文,并与新提示配对来重建KV缓存。后续步骤则基于这个刷新后的缓存正常生成。为了保证训练与推理的一致性,这个重缓存过程被直接集成到了训练循环中。
2. 流式长视频微调
LongLive基于因果帧级自回归视频生成器构建。这类模型通常只在5秒左右的短视频片段上训练,推理时通过反复将自身生成结果输入一个固定长度的上下文窗口来“滚动”生成长视频。但这种“短训练-长测试”的模式,正是导致长视频内容漂移和质量下降的元凶。
为了解决这个根本性的训练-推理失配问题,团队提出了“长训练-长测试”的策略,即在训练阶段就让模型基于自身不完美的预测进行长序列生成,并全程接受监督。但这在实践中面临两大挑战:一是教师模型本身是基于短片段训练的,难以端到端地监督长序列;二是直接展开长序列进行反向传播极易导致内存溢出(OOM)和计算效率低下。
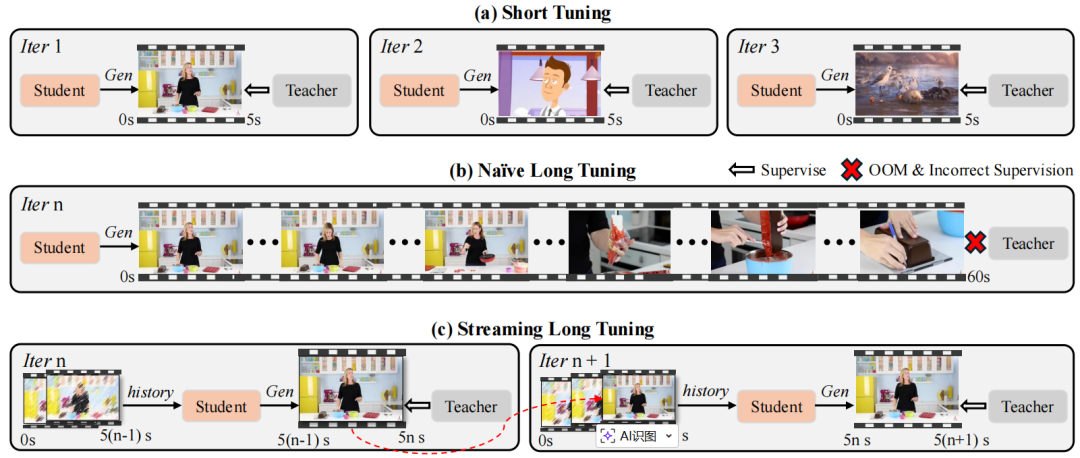
图2:流式长视频微调流程。(a) 短微调:仅监督5秒片段,长视频生成质量下降。(b) 朴素长微调:直接扩展至长序列,引发OOM及错误监督。(c) 流式长微调:通过复用历史KV缓存逐步生成长序列,实现高效、正确的长视频训练。
针对挑战,研究团队设计了流式长视频微调流程,如图2(c)所示。这个流程模拟了推理时的行为:
- 在第一轮迭代中,生成器从零开始采样一个短片段(如5秒),并对其进行知识蒸馏。
- 在后续迭代中,生成器基于上一轮迭代保存的历史KV缓存,扩展生成下一个短视频片段。
- 教师模型仅对新生成的这个片段施加监督。
- 重复这个“滚动扩展-局部监督”的过程,直至达到预设的最大生成长度,然后重置。
这种方式既在局部保持了可靠的监督信号,又将内存和计算开销控制在可管理范围内,巧妙地实现了高质量的长视频训练。如果你对这类模型微调和训练的最佳实践感兴趣,可以深入探索云栈社区的技术文档专区,那里有更多系统的解读。
3. 高效长推理
为了让长视频生成真正“实时”起来,LongLive在推理效率上做了两项关键优化:
- 短窗口注意力:基于视频内容在时间上具有局部连续性的观察(邻近帧对预测下一帧贡献最大),LongLive在推理和流式微调中均采用局部窗口注意力。将注意力限制在固定大小的窗口内,计算复杂度和每层所需的KV缓存大小都只由窗口大小决定,而不再随视频总长度增长,从而大幅降低了开销。
- 帧汇聚点:仅靠短窗口注意力无法防止模型在生成长视频时崩溃。团队发现,通过上述的流式长微调解决了长程生成的根本问题后,再引入“注意力汇聚点”便能显著提升长时间范围内的一致性。具体做法是将视频的首帧块固定为全局汇聚点
token,这些token永久保留在KV缓存中,并与每一注意力层的键和值进行拼接,使得模型即使在局部窗口注意力下也能“看到”这个全局锚点。
通过将短窗口注意力和帧汇聚点整合到流式微调流程中,LongLive实现了训练与推理的高度对齐,在提升效率的同时保障了生成质量。
评估
1. 短视频生成
研究团队采用VBench官方提示集评估了LongLive生成5秒短视频的能力,并与同规模的开源模型对比。所有分数均经过VBench统一数值系统归一化。
表1:与相关基线模型在短视频生成上的对比
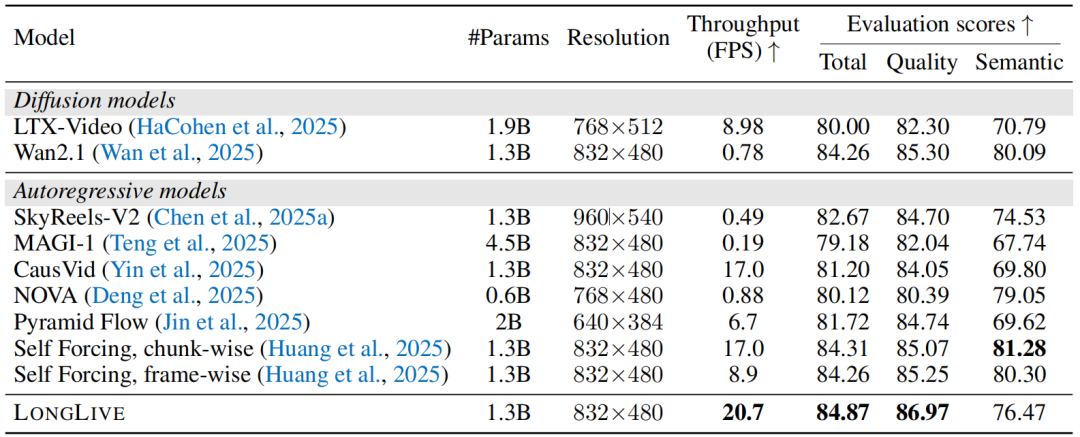
如表1所示,在5秒短视频生成上,LongLive在总分上媲美最强的基线模型,展现出优异的质量与稳定性。更重要的是,得益于短窗口注意力设计,LongLive的推理速度达到了所有方法中最快的20.7 FPS,实现了实时推理。这证明LongLive在追求长视频能力的同时,丝毫没有牺牲其短视频生成的基础性能。
2. 长视频生成
研究团队采用VBench-Long官方提示集评估LongLive的单提示长视频生成能力(生成30秒视频)。如表2所示,LongLive在取得先进性能的同时,依然保持着最快的推理速度。
表2:在VBench-Long上的单提示30秒长视频评估
3. 交互式长视频生成
由于标准评测协议不适用,团队构建了包含160个交互式60秒视频的自定义验证集(每个视频由6个连续10秒提示构成)。他们使用VBench-Long的维度评估长时质量,并使用CLIP分数按片段评估语义遵循度。
定性结果如图3所示,LongLive在提示遵循、平滑过渡和长程一致性方面都表现突出。相比之下,Self-Forcing在长时生成中质量下降,SkyReels-V2则一致性较弱。

图3:交互式长视频生成的定性比较。LongLive在长达60秒的生成中保持了高度的语义遵循与视觉一致性。
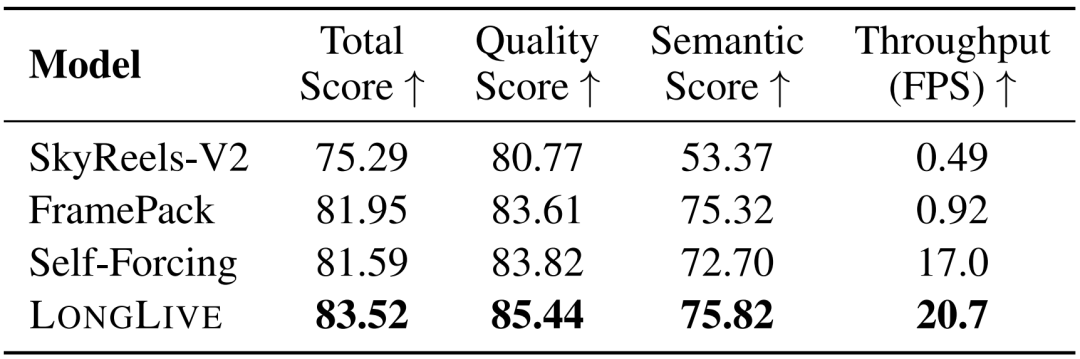
定量结果如表3所示。在速度方面,即便引入了KV重缓存机制,LongLive的推理速度仍比SkyReels-V2快41倍以上,并且略快于Self-Forcing。用户研究(图1右侧)进一步证实了LongLive在交互式长视频生成中的有效性。
表3:交互式长视频评估(质量分数基于完整60秒序列,CLIP分数基于10秒片段)

总结来说,英伟达LongLive框架通过KV重缓存、流式长视频微调和高效长推理优化三大核心技术,成功解决了实时交互式长视频生成中的质量、一致性与效率难题。它将前沿的Transformer架构与创新的训练推理策略相结合,为动态内容创作打开了新的可能性。其模型和代码已在HuggingFace和GitHub开源,推动了整个视频生成领域的发展。
 发表于 2026-3-10 03:17:25
|
查看: 234|
回复: 0
发表于 2026-3-10 03:17:25
|
查看: 234|
回复: 0
