在搜索系统中,C++引擎长期扮演着底层核心基础设施的角色:性能敏感、逻辑复杂、变更频繁,同时承载着大规模线上流量的稳定运行。随着业务持续发展和技术架构不断演进,我们逐步意识到:在高频迭代背景下,回归能力也需要同步升级。
过去一年,我们围绕搜索 C++ 引擎展开了一次系统性的回归能力工程化建设。本文将介绍这次能力升级的背景思考、核心设计思路以及落地实践,希望能为面临类似挑战的团队提供参考。
高频迭代背景下:回归能力需要同步升级
搜索 C++ 引擎的升级主要来自三类需求:业务功能需求、重要技术项目(有 QA 深度参与)、大量技术优化与结构性改造需求。
在实际迭代节奏中,技术优化与结构性改造类需求占比较高,引擎整体呈现出多人并行开发、持续迭代推进的状态。随着规模扩大,我们发现:现有回归环境更适用于单次项目式验证。多需求并行时,资源调度与复用能力仍有提升空间,回归准出标准尚未完全工程化。这意味着,在稳定性要求不断提升的背景下,我们有必要构建更加标准化、流程化的回归体系,让质量保障能力与迭代节奏匹配。
现有测试方式的演进空间
当前搜索引擎主要依赖两类测试手段:DIFF 测试和压测,这些手段在长期实践中发挥了重要作用,但随着业务复杂度提升,我们也逐步看到进一步优化的空间:
- 流量获取依赖下载日志、手工上传,自动化程度仍可提升。
- DIFF 过程中存在自然噪音。需要更精细化处理(AA DIFF、排序不稳定)。
- 报告与分析信息分散在不同工具中,定位效率有优化空间。
- 多套工具并行使用,缺乏统一平台化沉淀。
整体来看,测试能力更多体现为“工具能力集合”,而在流程标准化、资产沉淀与统一治理方面仍有提升空间。
我们要解决什么问题
这次建设的目标,并不是简单“再做一个工具”,而是希望系统性解决以下问题:
- 让 DIFF 和压测成为搜索 C++ 引擎的标配回归能力。
- 让回归结果具备可分析、可归因能力。
- 让回归成为发布的硬性准出标准。
- 保证工具本身的稳定性,不成为新风险。
- 整体提升引擎的回归效率和交付质量。
- 通过流程和流水线,降低对“人”的依赖。
一句话总结:把回归这件事,从“靠自觉”,变成“靠系统”。
整体方案概览
围绕上述目标,我们将建设拆分为五个关键方向:
- 流量录制:一次录制,多处复用。
- 环境建设:稳定、可复用的 DIFF/压测环境。
- DIFF 工具体系:从“能跑”到“好分析”。
- 一键压测能力:降低执行门槛。
- 工具与索引平台集成:让回归真正被用起来。
下面将会按模块展开说明。
流量录制:回归的基础设施
为什么先做流量录制
DIFF 和压测的核心前提只有一个:真实、稳定、可复用的流量。因此我们优先建设了搜索 C++ 引擎的流量录制链路,作为后续所有测试能力的基础。
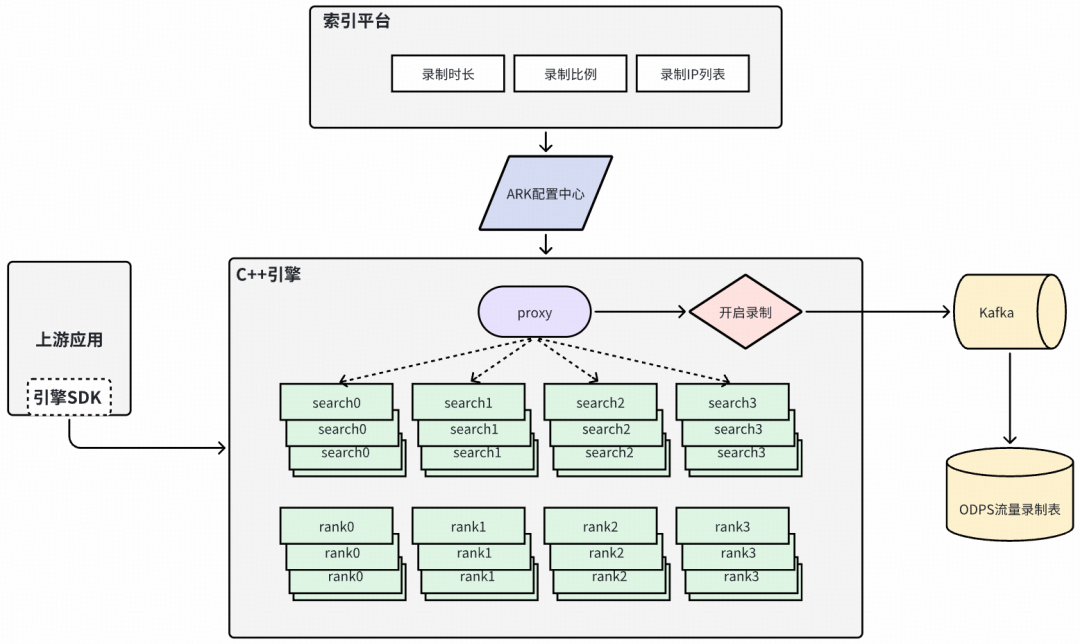
流量如何触发
- 在索引平台集群详情页直接发起流量录制。
- 索引平台更新 ARK 配置中心中的录制配置。
- 搜索 C++ 引擎实时监听配置变化。
录制配置设计
所有配置统一收敛在 dsearch3#test.properties,支持:
- 全局开关。
- 指定 app / group。
- 截止时间。
- 指定 IP。
- 采样率(0~100)。
这使得录制行为可控、可回收、可精细化管理。
流量生成与存储
- 引擎侧根据配置生成 Kafka 消息。
- 多业务场景复用同一 ARK 集。
- 多场景流量复用同一个 Kafka Topic。
最终流量落入 ODPS,按天分区,字段包含:
- 请求体。
- 流量场景。
- 实验信息。
- 环境信息(生产 / 预发)。
这为后续 DIFF、压测、问题复现提供了统一数据源。
流量存储字段说明:
request_type:流量标签(原C++引擎请求类型)
app_name:C++引擎appName
group_name:C++引擎groupName
request_body:录制的C++引擎请求体
env:录制的流量环境:预发/生产
graph_name:图名称
experiments:实验列表(搜索新增)
pt:ODPS分区,按天分
DIFF 测试:从无到“可归因”
DIFF 执行流程:
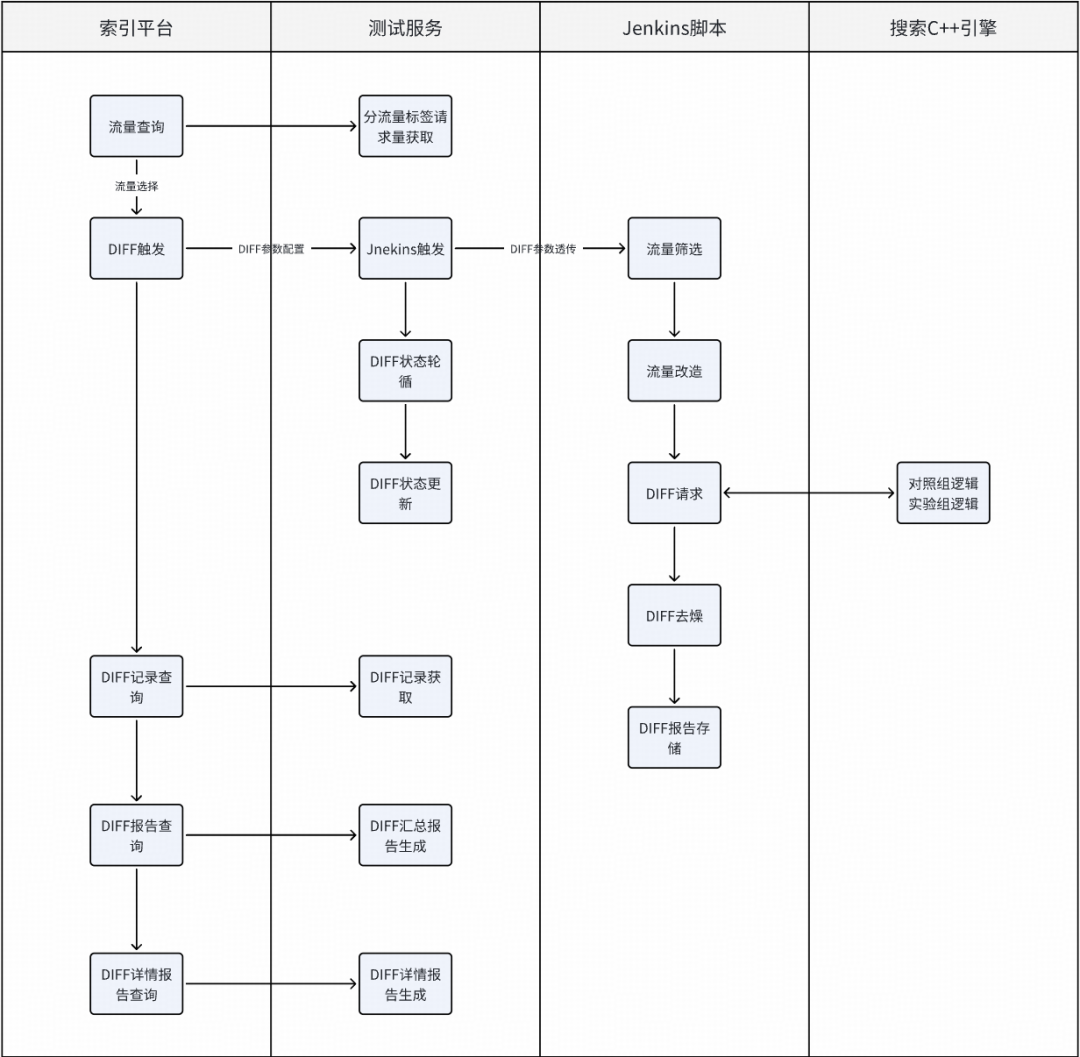
DIFF 的入口统一在索引平台:查询流量 →选择流量→配置参数→触发 DIFF→查看报告。底层由测试服务 + 脚本完成:流量筛选与改造、请求转发、去噪、报告生成与存储。
DIFF 对比方式:
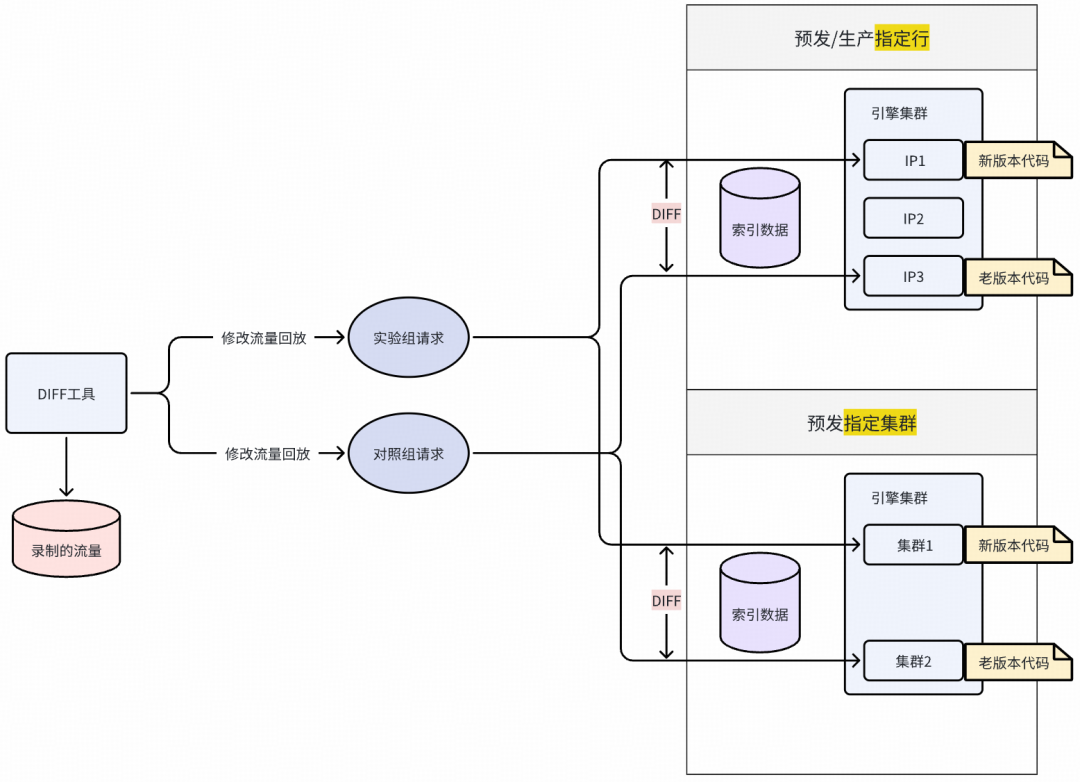
对照组部署 master 分支,实验组部署预发布分支。指定行或者指定集群方式请求对照组和实验组环境。打开新功能开关进行响应比对,生成预期有DIFF报告。
DIFF 环境设计
支持两种模式:
- 指定集群:对照组 / 实验组两套完整集群。
- 指定行:精确绑定 search / rank IP。
通过该设计,保证对比的唯一变量只有代码和配置。
流量筛选与回放改造
支持多维度筛选:
- 搜索场景(交易 / 社区 / 聚合等)。
- 流量标签(综合 / 销量 / 新品等)。
- 实验命中情况。
同时解决了生产流量无法直接在预发回放的问题(表名、图参数、模型等适配)。
DIFF 策略设计
我们不只关注“有没有 DIFF ”,而是关注这个 DIFF 是否符合预期,因此 DIFF 被拆为两类:
响应 DIFF
指标 DIFF
- 相似度分布(忽略/不忽略排序)。
- 漏斗算子一致率。
- 字段增删改统计。
- 定制化指标。
DIFF 去噪
DIFF 不可用,往往不是因为“真问题”,而是噪音太多。我们重点处理了:AA DIFF(排序不稳定、非确定性逻辑)、可忽略字段、数值微小波动、内部超时导致的异常结果,目标只有一个:让开发看到的DIFF,尽可能都是真问题。
DIFF 报告设计
报告展示
DIFF 汇总报告:
- 应用、集群、请求接口、流量标签、路由信息、对比数量、DIFF 数量、完全一致率、query_tag 平均召回数、score 平均分等。
- 相似度分布统计报告(不忽略排序/忽略排序)。
- 漏斗算子一致率统计报告。
- 字段增删改统计。
DIFF 详情报告:
- traceId、一致率、增删改字段、请求体等。
- 漏斗算子 DIFF 明细。
- 响应 DIFF 明细。
报告通知
通知到群 @个人,添加报告链接。
压测:一键完成性能回归
压测执行流程:
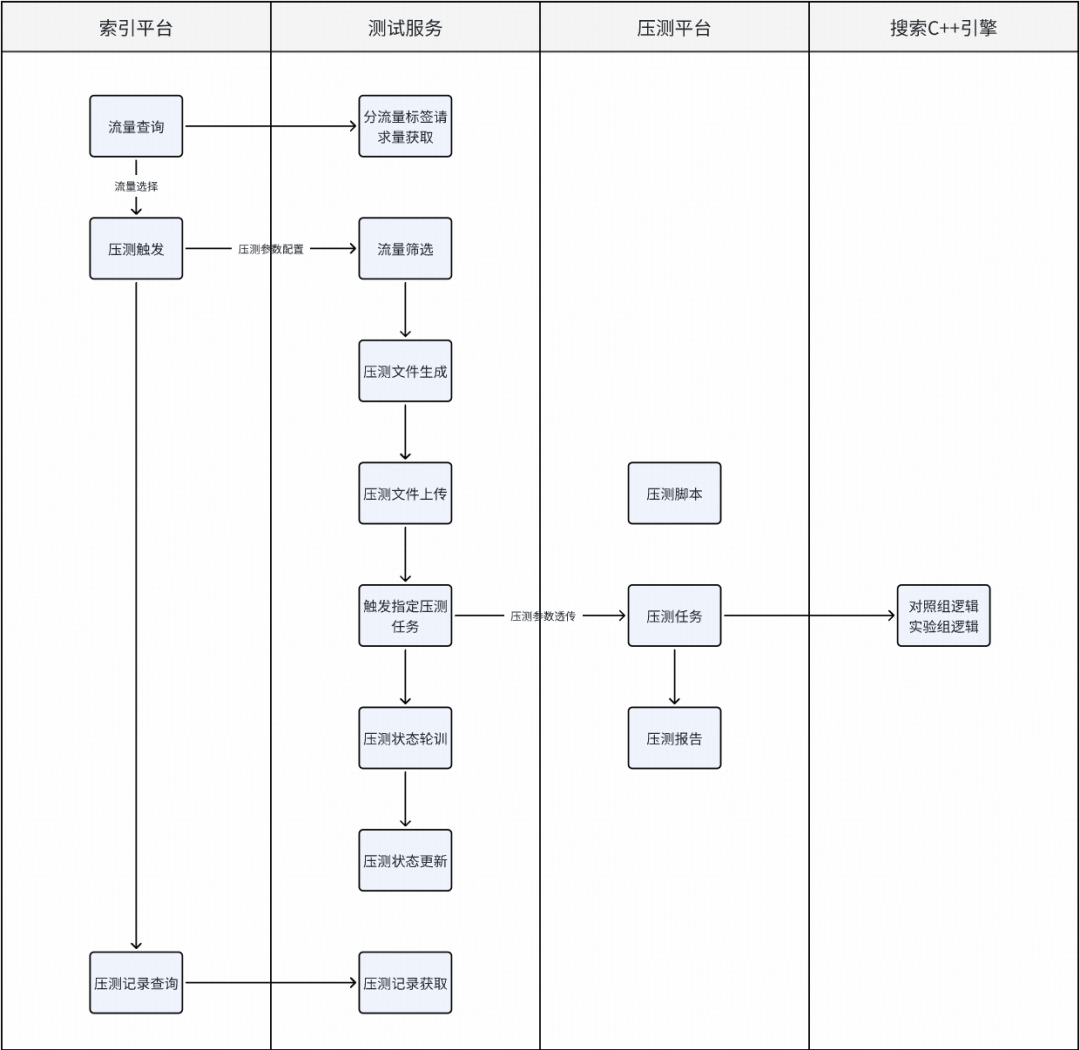
- 索引平台作为压力测试发起入口,查询流量->选择流量->填写压测参数->压测触发->压测记录查看。
- 测试服务提供索引平台操作的接口能力,查询流量->流量筛选->压测文件生成->压测任务触发->压测状态更新。
- 压测平台提供实际压测能力,启动压测任务->生成压测报告。
整个过程无需人工干预。
执行方式:
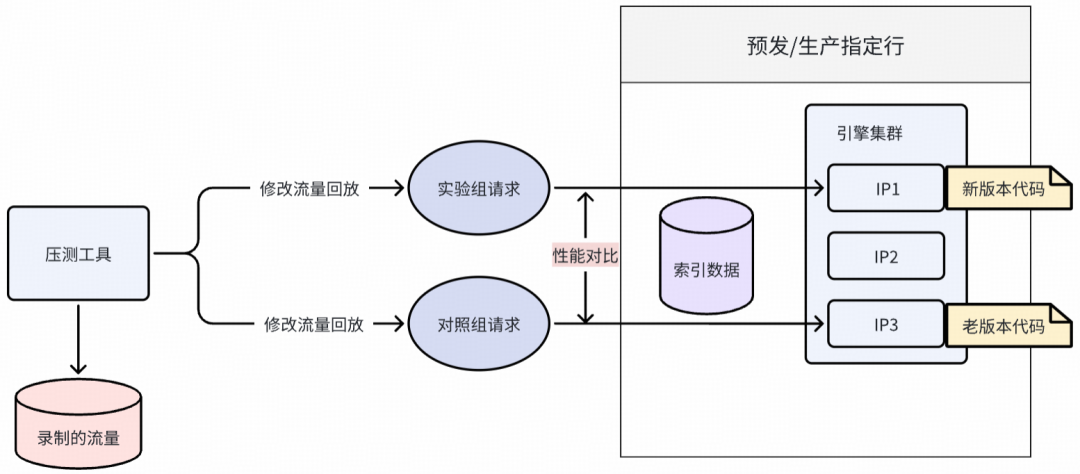
- 对照组:master 分支。
- 实验组:预发布分支。
- 开启新功能开关。
- 阶梯式加压,对比性能曲线。
压测环境设计
同 DIFF 环境建设。
压测报告设计
报告展示
压测平台报告。
报告通知
通知到群 @个人,添加报告链接。
发布流水线与准出机制
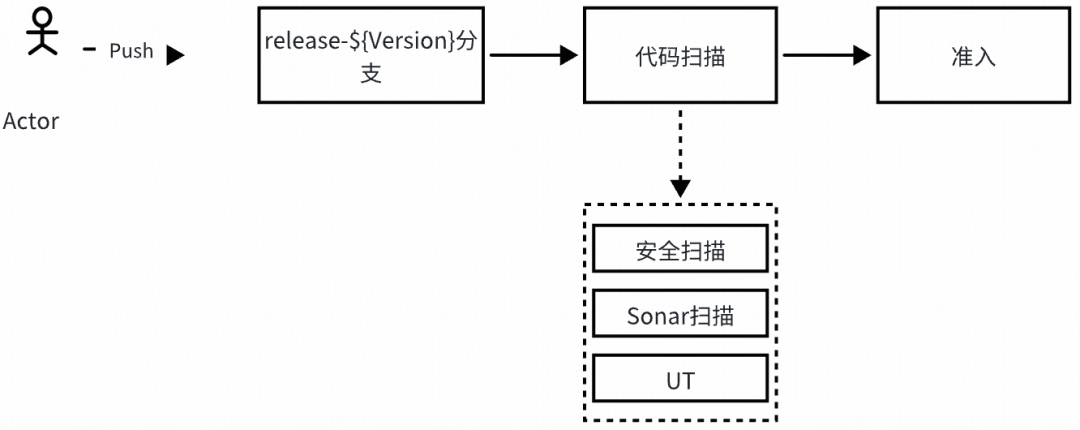
回归能力建设的最终目标,是进入发布流程。当前已完成:UT / MR 流水线初步建设,后续规划中将:
- 把 DIFF 和压测作为发布硬性卡点。
- 回归不通过,禁止上线。
- 回归过程自动扩缩容,避免长期占用资源。
- 自动生成准出报告。
后续规划
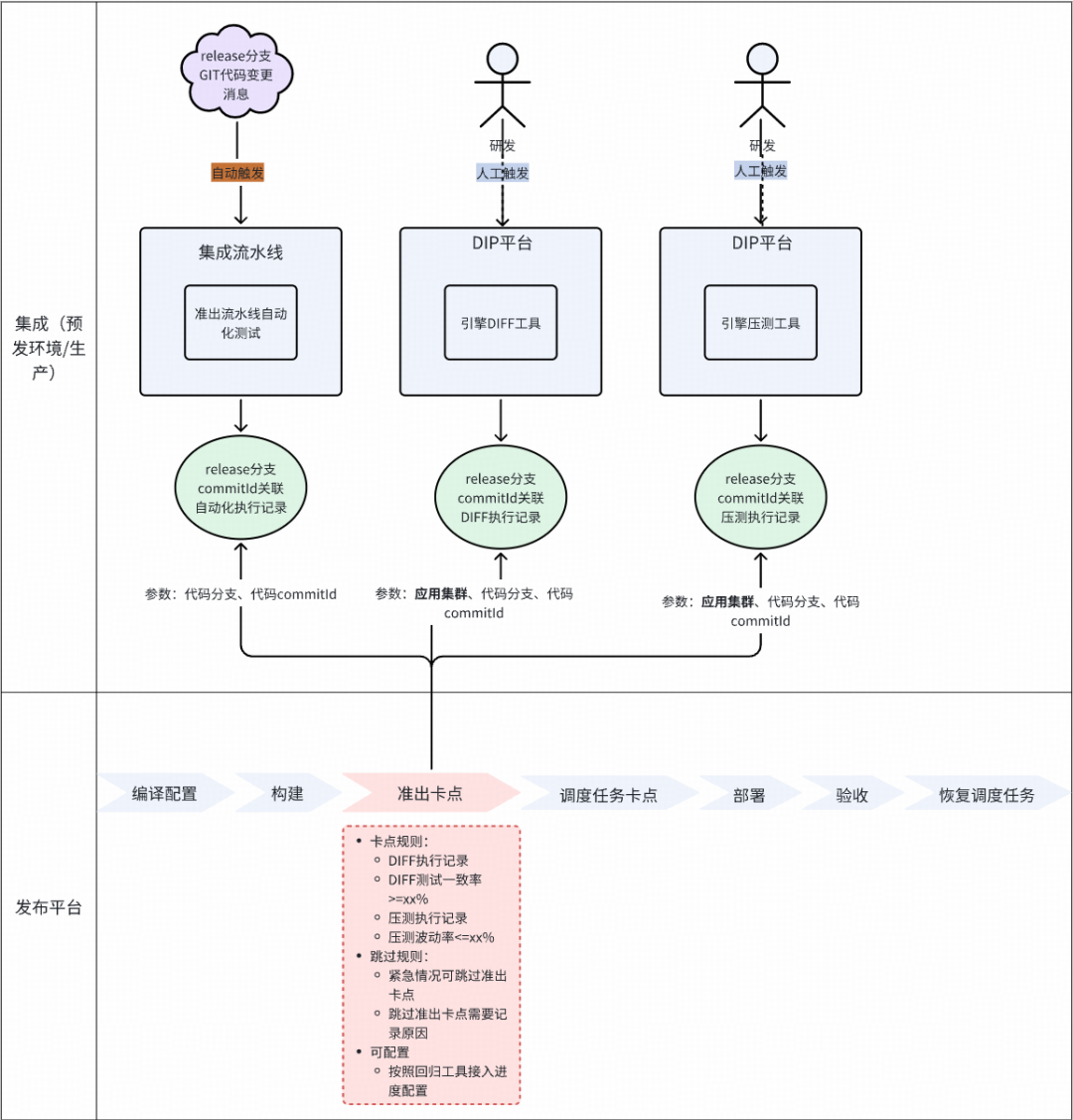
准出流水线全自动化。

- 横向覆盖更多搜索场景(流控、商业化、国际搜索等)。
- 形成统一的上线 SOP 规范。
总结
搜索 C++ 引擎回归能力建设,并不是一次“工具升级”,而是一场工程化治理:把经验变成流程、把自觉变成约束、把风险前移到上线之前,最终目标只有一个:让搜索引擎的每一次升级,都更可控、更可信。这个过程也印证了,将成熟的测试实践系统化、平台化,是保障复杂软件测试 质量与效率的必由之路。
 发表于 2026-3-10 03:14:26
|
查看: 168|
回复: 0
发表于 2026-3-10 03:14:26
|
查看: 168|
回复: 0
