自从AI时代开启,英伟达(NVIDIA)的地位愈发如日中天。从AI三要素——算力、算法、数据来看,英伟达的影响力无疑聚焦于算力。面对AI这座金矿,人们常将英伟达比作“卖铲子的”。但在2026年CES展上,黄仁勋的演讲却透露出新的动向:当这位“卖铲子的”巨头开始手把手教大家如何挖矿时,我们该将其解读为“大佬扶我上路”的善意,还是背后藏着更深远的战略图谋呢?

黄仁勋在CES上宣布,一口气开源了视觉语言行动模型(VLA)Alpamayo、仿真工具AlpaSim以及配套数据集,可谓在AI三要素上全面出击。1月13日,英伟达中国区高管更是专门面向国内媒体进行了深度解读,大力推介这套开源“组合拳”。
扩大中国市场的业务版图
乍一看,英伟达此举颇有亲自下场研发自动驾驶的架势。但从商业逻辑来看,这可能性极低。自动驾驶的商业价值最终要落实到整车产品上,而英伟达绝无可能涉足整车制造。这不仅关乎企业基因,更因为整车制造的利润率与英伟达当前主营的AI硬件业务相差甚远。即便退一步做智能驾驶供应商,也要陷入与众多同行的激烈竞争,远不如在AI硬件领域占据绝对优势来得“舒适”。
一个更可信的逻辑是:如果用户广泛采纳了英伟达的开源工具链,势必会增强对其硬件的依赖。因此,强化英伟达AI硬件的影响力和生态护城河,很可能是这次开源行动的核心出发点。
这轮慷慨的开源举动,让人联想到当年CUDA生态建设的扩大版。在当前英伟达中国硬件业务面临不确定性、在大国竞争的夹缝中求生存的背景下,拓宽其在中国的软件与生态业务,具有现实的战略意义。更何况,中国拥有全球最活跃的自动驾驶研发群体,这里的潜在业务前景最为明确,值得英伟达重点投入。相比之下,规模庞大的特斯拉生态,英伟达反而难以切入。
为了证明这套系统的商业可行性,英伟达已与Lucid、捷豹路虎、Uber达成合作,据说今年一季度就在美国进行路测,后续还将扩展至欧洲和亚洲。虽然覆盖面听起来很广,但目前可能仍局限于小范围的测试验证。
开源模型:好教具,难直接部署
这套开源组合究竟实力如何?我们先从功能看起。Alpamayo本身是一个VLA模型,但它与其他端到端模型的关键区别在于,其推理过程并非“黑盒”。它会主动拆解复杂驾驶场景,并输出自己的思考链。这不仅对人类开发者更友好,也在很大程度上缓解了人们的担忧:在没有硬规则兜底的情况下,AI会不会“乱来”?
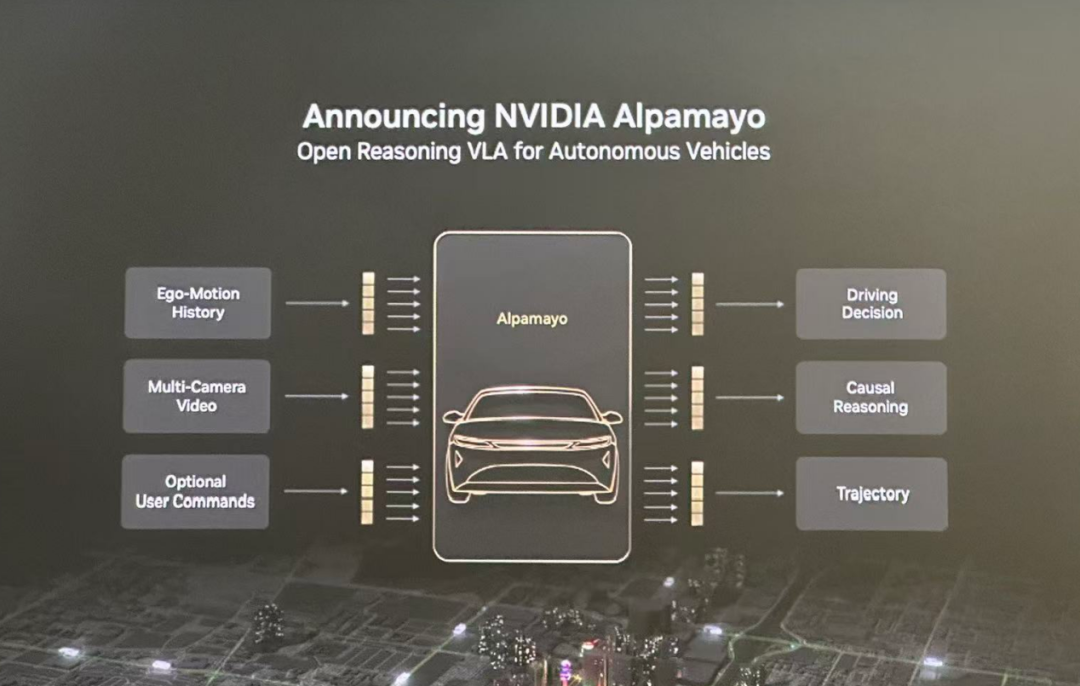
例如,面对一个复杂的红灯调头场景,Alpamayo会将其拆解为:分析规则是否准许、对准分道线、减速、识别信号灯与停止标志、避让直行车辆与过街行人,最后择机完成两次左转。这个过程与人类的决策逻辑高度相似,每一步都清晰可循,从而建立起更强的信任感。
当然,Alpamayo更像一个“教师模型”。其参数量过大,不适合直接部署在车端,必须通过知识蒸馏等技术转移到中小模型上才能实用。
业内也有分析指出,Alpamayo可能在空间分析上表现优异,但在严格的时序认知能力上或许存在短板。理由是2025年12月发布的Alpamayo-1版本,即使用了远超车载算力的RTX 6000 Pro Blackwell显卡,其端到端延迟仍约0.1秒。在极端紧急情况下,这个响应速度可能不足以确保及时决策,仍有提升空间。
相对于空间认知,时序问题向来是语言类模型的弱项。任何可用的自动驾驶模型,都必须保证其认知的物理规律与真实世界高度吻合。这也是一些公司尝试放弃VLM(视觉语言模型)路线的原因——他们试图绕过文本对齐环节,从视觉信号直接输出驾驶决策,以加速思维链。
与模型一同开放的,还有约1700小时的驾驶场景数据切片。相比特斯拉的数据集,规模上确实存在差距,但考虑到英伟达本身并非车企,能获得这些数据已属不易。
数据生成与环境模拟:英伟达的看家本领
相比模型和数据集,仿真工具AlpaSim似乎不那么引人注目。但事实上,仿真数据的来源只有一小部分来自真实场景切片,绝大部分需要依靠模型来生成。
这便引出了英伟达的“世界模型”——Cosmos。该模型主要用于训练大模型,而非强调在实时系统中提供预测。

英伟达宣称,Cosmos能够生成高度逼真的合成数据,覆盖雨、雪、雾、风、交通事故、道路施工等各类长尾场景,从而解决真实数据获取成本过高、极端场景稀有的难题。
当然,英伟达并未声称合成数据可以完全替代真实物理数据。两者之间的关系,或许有点像婴儿奶粉与母乳,只能无限接近却无法彻底取代。至于接近到什么程度,最终需要通过大模型训练的实际效果来验证,有待未来采用这套全家桶的用户给出反馈。
有了高度仿真的数据,数字孪生系统Omniverse则负责提供模拟驾驶场景的测试环境。说到这里,就进入了英伟达在AI时代之前就已深耕的领域:实时渲染、物理仿真、运动模拟、传感器模拟等。本质上,这些都是强大GPU的“本职工作”。
在自动驾驶领域,当前主流方案是将车载SoC设计为包含NPU、GPU、DPU、CPU的异构芯片。黄仁勋在本届CES上发布的Vera Rubin计算架构,则是一个庞大的机架式系统,需要精密的散热设计。这类依靠超强算力支撑的系统,才能完成英伟达所描述的复杂模型训练,这也是其业务根基所在。
开源背后的真实意图
现在情况似乎更清晰了:英伟达开源的核心,是一套大模型及其训练方法论,辅以仿真工具和数据生成器。这对于AI模型投资不足、想要快速入门的车企而言,无疑是一套极佳的工具包和“教具”。只要采购英伟达的软硬件全家桶,就能较快地搭建出一个演示级别的辅助驾驶系统。而后续的数据积累与模型迭代,对车企而言更多是成本和时间问题。这套组合拳相信能吸引一批潜在的B端客户。
然而,对于自动驾驶领域的头部玩家而言,情况则不同。他们已经建立起自有的大模型和硬件系统,形成了数据闭环,不太可能转而利用英伟达的开源系统进行核心训练。这些供应商和车企,并非英伟达此套系统的目标客户。换言之,已在自动驾驶领域实现商业化落地的中国车企,很难成为英伟达全家桶的买家,这其中还叠加了潜在的政策风险。
跨国车企或许更有兴趣尝试(目前的合作名单也印证了这一点),但训练系统部署在哪里是个棘手问题。如果放在中国,进口英伟达的大规模算力硬件存在不确定性;如果放在海外,中国的数据出境又受到严格限制。到头来,其在中国市场的应用,可能仍需依赖本地采购的自动驾驶解决方案。
相比之下,英伟达那些更具独立性的产品,如低功耗车规级AI芯片Orin、Thor系列,在中国市场的护城河依然清晰,几乎不受此番开源生态策略的影响。这便是产品与生态的区别:构建和更换生态的成本远高于单一产品,而一旦成功占领生态位,带来的收益也将更为持久和丰厚。
可以看出,为了打出这套软硬件组合拳,英伟达早已提前数年进行布局和研发投入。如果仅仅将其行为视为强化在自动驾驶领域的硬件竞争力,视野或许有些狭窄。在更广阔的AI领域,英伟达不断推高GPU和超算系统的性能门槛,旨在巩固其“基础算力供应者”的霸主地位,彻底拉开与竞争对手的差距。自动驾驶,不过是AI众多应用场景中的一个分支。

软件生态的繁荣,能为硬件销售提供持续不断的驱动力。这套开源系统,将鼓励更多圈外的玩家投身于自动驾驶研发。新玩家的涌入,必然对云算力和模型训练算力产生海量需求。英伟达的终极目的,恐怕是意图构建一个庞大的“算力帝国”。按照其宏大构想,“美股七姐妹”中的其他六位,未来都将在英伟达的“算力根系”上生长。服务于如此宏伟的蓝图,开源软件这点“甜头”,英伟达自然毫不吝啬。
对这类前沿技术的战略剖析与开源动态,欢迎在云栈社区继续深入交流与探讨。
 发表于 2026-2-1 16:46:16
|
查看: 198|
回复: 0
发表于 2026-2-1 16:46:16
|
查看: 198|
回复: 0
