2026年3月17日,日本乐天(Rakuten)高调发布了号称“日本最大规模”的AI模型——Rakuten AI 3.0。该模型宣称参数规模约7000亿,日语性能超越GPT-4o,并且获得了日本政府GENIAC项目的资金补贴。
然而,模型发布不到12小时,其“真面目”便被全球开发者识破。
有开发者在 HuggingFace 平台查看该模型的配置文件时发现,核心的 config.json 文件里清晰地写着:architectures: [“DeepseekV3ForCausalLM”]。
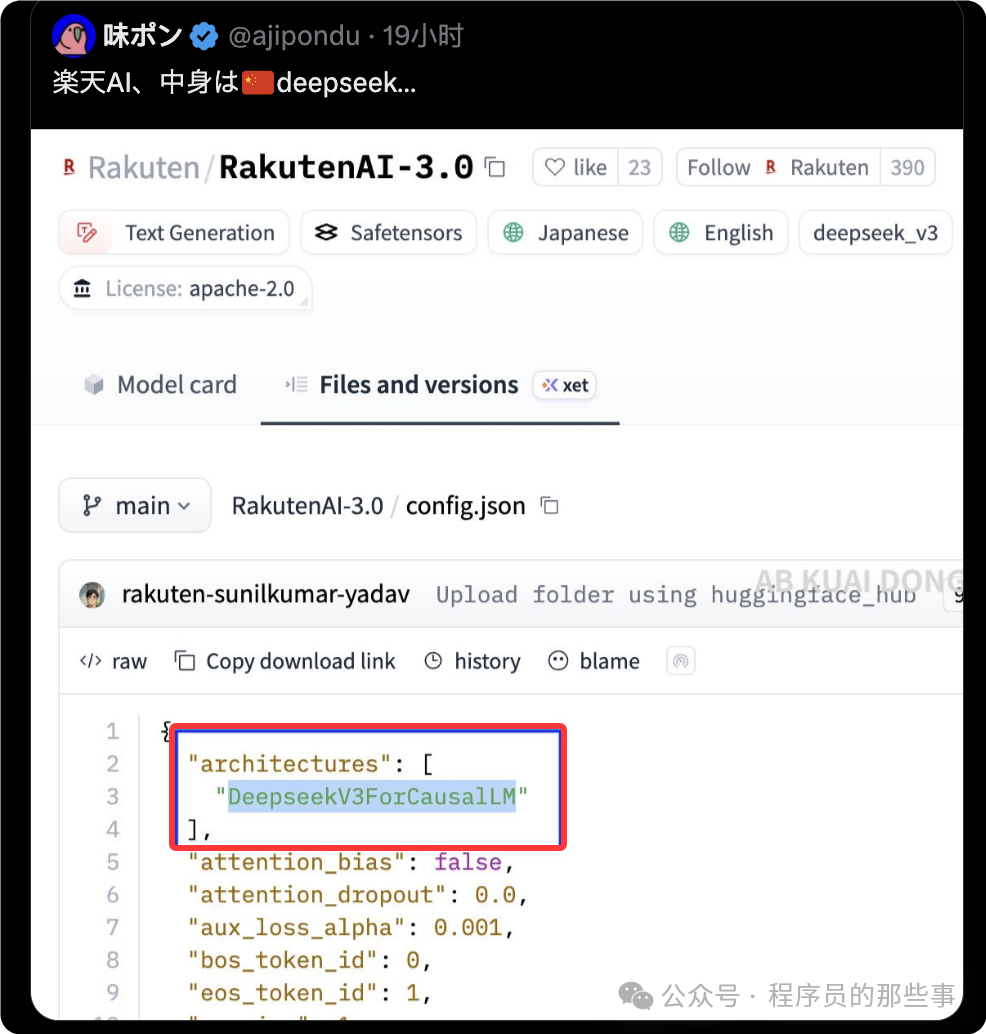
进一步分析表明,其核心参数、层数、维度均与中国团队开发的 DeepSeek V3 模型完全一致。乐天所做的工作,似乎仅是基于少量日文数据进行了微调。
颇为讽刺的是,乐天最初将模型上传至开源社区时,直接删除了 DeepSeek 模型所遵循的原生开源许可证。在被开发者发现并指出后,才匆忙补充了一个 NOTICE 文件。在其官方新闻稿及发布会中,乐天仅模糊地提及“使用了社区开源成果”,全程刻意避免提及“DeepSeek”之名,试图将模型包装为“日本自研”成果,此举被广泛认为涉嫌虚假宣传。
这一事件迅速引发了日本网友的广泛批评,许多人指责其利用纳税人的补贴进行“换皮套壳”,不仅违背了开源协议精神,更是一种“欺骗国民感情”的行为。
DeepSeek V3 模型采用宽松的 MIT 开源协议(该协议几乎无限制性条款,主要要求是在分发时保留原始的版权声明和许可声明),其他厂商合规使用本无问题,但刻意隐瞒来源则构成了信用层面的抄袭。
(参考:HuggingFace 、36kr,本文经由 AI 优化) |  发表于 2026-3-19 05:52:42
|
查看: 202|
回复: 0
发表于 2026-3-19 05:52:42
|
查看: 202|
回复: 0
