在嵌入式与AI结合的趋势下,越来越多的开发者开始关注TinyML。一个最常见的问题就是:“我手头的这颗MCU,到底能不能跑得动TinyML?”
今天,我们就来系统地解答这个问题,核心围绕两点展开:第一,哪些MCU已经被验证适合运行TinyML;第二,如何一步步评估你自己的MCU是否满足项目需求。
一、TinyML 的本质是什么?
首先需要明确,TinyML 既不是某一颗“专用AI芯片”,也不是某一个固定的框架。它更接近于一类工程范式:将机器学习模型的推理(必要时包含轻量级特征提取)部署到资源受限的微控制器(MCU)上,让设备在端侧独立完成识别、分类、检测等任务。
以 Google 的 LiteRT for Microcontrollers(原 TensorFlow Lite Micro)为例,它的设计目标就是面向“只有几KB内存”的微控制器。其核心运行时在 Arm Cortex-M3 上可以被压缩到约16KB的量级,并且不依赖操作系统、标准C/C++库或动态内存分配。
这引出了一个关键结论:TinyML 能否成功运行,首要条件是‘推理运行时 + 业务模型 + 输入数据预处理’这个完整闭环,能否被MCU有限的Flash、RAM、算力以及功耗预算所容纳。
二、哪些 MCU 已被官方“认证”可运行 TinyML?
我们可以从几个主流生态的官方资料中找到明确答案。
1. Google LiteRT for Microcontrollers (TFLM)
Google在其文档中明确列出了“支持的平台”与“支持的开发板”。

从上图可以总结出:
- 平台要求:需支持C++17的32位平台。已在Arm Cortex-M系列上经过广泛测试,并移植到了ESP32等其他架构。它可以作为Arduino库使用,也能生成Mbed等工程。
- 支持的开发板:包括Arduino Nano 33 BLE Sense、SparkFun Edge、STM32F746 Discovery、Adafruit EdgeBadge、ESP32-DevKitC等。
这些开发板背后的MCU架构涵盖了Cortex-M4/M7、Cortex-M0+(如ATSAMD51)、ESP32(Xtensa)等。
2. Arm CMSIS-NN
CMSIS-NN 是Arm专门为Cortex-M系列处理器优化的神经网络算子库。其目标非常明确:在Cortex-M处理器上最大化性能、最小化内存占用。
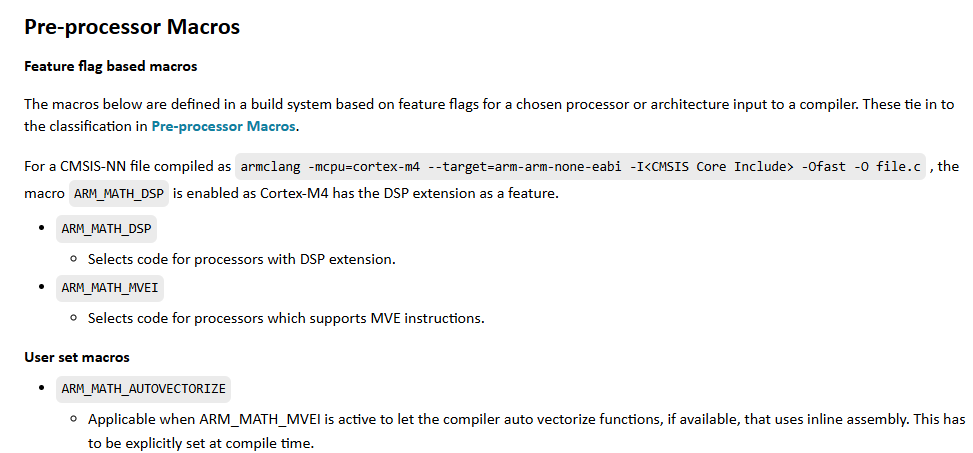
它根据处理器的指令集能力,将Cortex-M分为了三类优化路径:
- 无SIMD(如 Cortex-M0)
- 带DSP扩展(如 Cortex-M4)
- 带MVE/Helium向量扩展(如 Cortex-M55)
这给了我们一个清晰的选型指引:同样运行TinyML,拥有DSP或向量处理能力(如Cortex-M4, M33, M7, M55)的MCU,通常在性能、时延和能效比上更具优势。
3. STM32Cube.AI
ST的STM32Cube.AI工具链宣称,可以将训练好的神经网络优化并部署到任意STM32微控制器上。它会提供详细的分析报告,包括参数量、计算复杂度(MACC)以及具体的RAM/Flash需求。
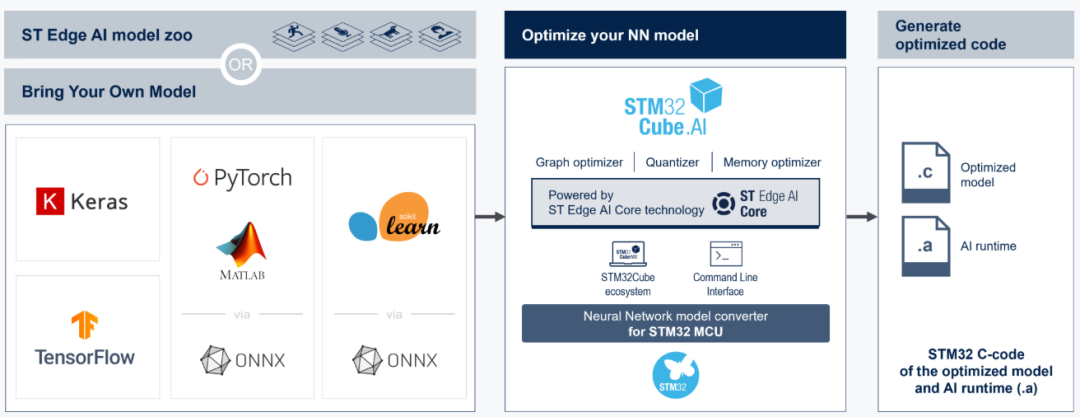
其用户手册中列举了广泛的系列支持,如STM32F3/F4/F7/H7/L4/L5/G4/G0等,这些都可以作为验证平台。
小结
- Google 给出了通用运行时的最低平台要求和已验证的硬件列表。
- Arm 提供了针对不同级别Cortex-M内核的优化路径与性能分层。
- ST 在其STM32生态内提供了可视化的部署工具和量化的评估手段。
三、工程视角:TinyML 适合哪些 MCU?
综合官方信息,我们可以从工程落地的角度,将“能运行TinyML”分为三个层次:
第一层:能跑起来(验证/入门型)
- 典型任务:正弦回归、简单二分类、基础异常检测。
- MCU特征:32位,支持C/C++(推荐C++17),具备基本串口用于调试。即便是Cortex-M3,核心运行时也能控制在约16KB。
- 注意:“能跑通TinyML示例”不等于“能跑你的业务模型”。很多项目失败是因为特征提取的中间缓存和模型激活张量耗尽了RAM,而非模型本身。
第二层:跑得合理(量产常用型)
- 典型任务:传感器时序分类(振动、姿态)、关键词唤醒、低分辨率图像分类。
- 推荐架构:Cortex-M4/M7/M33。理由在于,CMSIS-NN等库在这些带DSP/FPU的核上能发挥强大的优化效果,实现更可控的时延和能耗。
- 场景:这是最常见的区间,适合需要在同一颗MCU上兼顾实时外设任务和AI推理的量产项目。
第三层:跑得更大/更快(进阶型)
- 典型任务:更高分辨率视觉处理、复杂时序模型、端侧多任务。
- 方案:采用Cortex-M55/M85(带Helium) 或配备微型NPU(如Ethos-U)的MCU。也可能需要为MCU扩展外部RAM/Flash来存储权重和缓存。
- 关键:此时瓶颈往往是内存带宽、数据搬运效率和吞吐量,而不仅仅是模型能否放下。
四、如何评估“我的MCU能不能运行TinyML”?
评估对象不是孤立的“MCU”,而是 “特定业务模型 + 数据预处理流程 + 目标MCU + 所选运行时” 这个组合能否形成闭环。以下是系统性的评估步骤。
Step 0:明确问题定义——确定6个关键量
在开始技术评估前,必须先厘清业务需求,这直接决定了资源消耗的底线。
- 传感器与数据:IMU、麦克风、图像?决定系统形态和训练数据。
- 采样率与位宽:如16kHz/16bit音频。决定原始数据吞吐量和缓冲区大小。
- 窗口长度与步长:如1秒数据窗,每100ms滑动一次。决定单次推理的数据量和系统实时性要求。
- 预处理方法:FFT、MFCC、归一化?决定端侧额外计算量和缓存需求,影响对DSP/FPU的依赖。
- 模型类型与输入:1D CNN、小型MobileNet等。直接决定权重大小(占Flash)和中间激活峰值(占RAM)。
- 输出策略:触发事件、连续概率?决定后处理复杂度与系统功耗策略(如仅事件上报)。
Step 1:利用工具进行快速初筛
使用官方工具快速获取模型在目标平台上的预估资源消耗,排除明显不行的方案。
- Edge Impulse:在Studio中可直接对模型进行性能画像,预估内存、Flash和时延。
- STM32Cube.AI:导入模型后,会给出详细的RAM/Flash占用、计算量分析,并支持在开发板上实际验证。
这一步常会暴露一个典型问题:模型本身不大,但预处理所需缓存巨大。
Step 2:Flash 占用评估
Flash占用不止是.tflite模型文件,还包括:
- 模型权重(常量数据)
- 推理运行时及算子实现(TFLM/CMSIS-NN)
- 预处理代码库(如FFT、DSP库)
- 外设驱动、RTOS、应用代码等
工程方法:先编译一个基础示例(如Hello World)得到基线大小,再逐步加入模型和预处理代码,通过map文件分析增量来源。
Step 3:RAM 占用评估——最常见的失败点
MCU的RAM主要被以下几部分瓜分:
- Tensor Arena(激活张量 + 临时缓冲区)
- 模型输入/输出缓冲区
- 预处理缓冲区(如音频环形缓冲、FFT输入输出数组)
- 系统栈、协议栈缓冲区、DMA缓冲区
关键:TinyML运行时(如LiteRT Micro)通常禁用动态内存,需要预先分配好所有内存。评估时:
- 先在目标板上跑通一次推理,记录打印出的Arena使用量。
- 逐步加入实际的预处理和系统任务,观察RAM峰值。
使用STM32Cube.AI可以直接看到它建议的每层内存分配策略。
Step 4:算力与时延评估——决定“是否实时”
核心判断:在要求的推理节拍内(如每100ms),“预处理时间 + 推理时间” 必须小于节拍周期,并留有充足余量(如30%以上)。
- 评估方法:分别测量预处理和模型推理(
Invoke)的耗时。
- 加速路径:在Cortex-M上,确保启用CMSIS-NN优化路径(对M4/M55等效果显著)。若使用带NPU的MCU,需同步评估数据搬运开销。

Step 5:功耗评估(针对电池供电设备)
对于电池设备,决定性因素往往是平均功耗,而非单次推理功耗。需要评估“推理频率 + 预处理占空比 + 无线通信策略”的整体影响。
- 工程方法:
- 测量系统在低功耗待机模式下的基线电流。
- 测量在特定推理频率下(如每秒10次)系统的平均工作电流。
若不达标,需折中考虑:降低频率、简化模型或预处理、选用更具能效比的硬件。
Step 6:算子支持与工程集成——决定“能否落地”
最后两项必须尽早确认的硬约束:
- 算子子集:TFLM/LiteRT Micro仅支持TensorFlow算子的一个有限子集。务必确认你的模型所需算子均被支持。
- 工具链集成:评估所选运行时能否顺利集成到现有的编译环境、RTOS、驱动框架中,并具备可持续的更新、调试和日志记录能力。
通过以上六个步骤的系统性评估,你就能对“我的MCU能否运行TinyML”得出一个扎实、可靠的结论,从而避免项目后期陷入资源不足的困境。希望这份评估手册能为你正在进行的TinyML项目提供清晰的路径。如果在实践中遇到具体问题,欢迎到技术社区交流探讨。
 发表于 2026-2-1 16:49:45
|
查看: 158|
回复: 0
发表于 2026-2-1 16:49:45
|
查看: 158|
回复: 0
