

Tesla架构被认为是第一代真正开始用于大规模并行运算的GPU架构。其硬件设计与细节奠定了现代并行计算架构的基本形态。尽管当前主流的Hopper架构(2022年发布,H100)在算力上已远超Tesla,但其核心的运作模式与计算单元的设计理念仍一脉相承。因此,深入理解Tesla架构,是掌握GPU硬件原理的重要基础。本文将通过分析Tesla架构的第一代(G80)与第二代(GT200),帮助读者建立起对早期GPU硬件的基本认知。
PART 01 发展历史简介
NVIDIA GPU从1999年的第一代GeForce 256图形显卡,发展到2022年的Hopper数据运算卡,产品线主要衍变为三个方向:GeForce(图形/游戏卡)、Quadro(专业渲染卡)以及Tesla(数据计算卡)。其中,Tesla系列的初代架构——Tesla架构,成为了后续诸多显卡发展的基石。在Tesla架构之前,显卡产品主要以图形处理(GeForce)为主,此后才衍生出强大的专用并行计算卡。Tesla架构本身也经历了两代发展:G80系列和GT200系列。
1.1 Tesla系列并行计算卡的发展
随着架构演进,Tesla系列计算卡的算力呈现出成倍增长的趋势。下图展示了从第二代Tesla到Volta架构的演进过程:
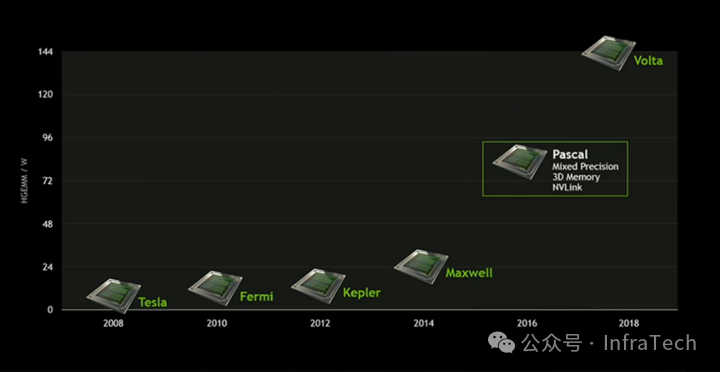
从整体架构发展时间线来看(注:数字代表大致代际,非精确算力):
1:Tesla(2008年)-> 2:Fermi (2010年)-> 3:Kepler(2012年)-> 4:?-> 5:Maxwell(2014年)-> 6:Pascal(2016年)-> 7:Volta(2018年)-> 7.5:Turing(2018年)-> 8:Ampere(2020年)-> 9:Hopper(2022年)。
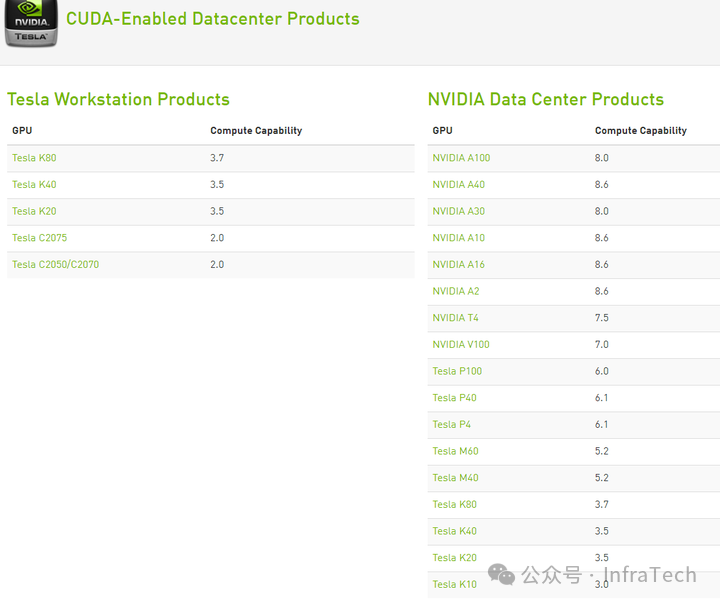
下图展示了数据中心产品的具体算力对比:
1.2 Tesla架构之前的图形显卡发展
Tesla架构之前的显卡基本定位为图形显卡,经历了从GeForce 1到GeForce 7的数代发展:
- GeForce(代号NV10,1999年):NVIDIA首个以“GeForce”命名的显示核心。
- GeForce 2(代号NV15,2000年):像素填充率达到每秒16亿。

- GeForce 3(代号NV20,2001年):全球首款支持DirectX 8的显示芯片。
- GeForce 4(代号NV25,2002年):基于GeForce 3架构改进。

- GeForce 5(代号NV3x,2002-2004年):官方称为GeForce FX系列。
- GeForce 6(代号NV40,2004年):支持DirectX 9.0c,Shader Model 3.0。
- GeForce 7(2005年):3D引擎升级为CineFX 4.0,支持DirectX 9.0c。
- GeForce 8(代号G80,2006年):Tesla架构正是在G80核心(如GeForce 8800 GTX)上首次实现。
Tesla架构讲解将围绕G80的GeForce 8800和GT200的GeForce GTX 280展开分析。

PART 02 Tesla硬件结构主体
Tesla架构于2006年首次应用于G80系列显卡,其关键创新是推出了NVIDIA第一代“统一着色与计算架构”。经过改进后,第二代统一架构应用于GeForce 200系列。该系列后来衍生出图形架构和计算架构两个版本,并行计算卡最终发展为数据中心产品系列,而图形处理则独立为GeForce和Quadro产品线。
2.1 主体架构
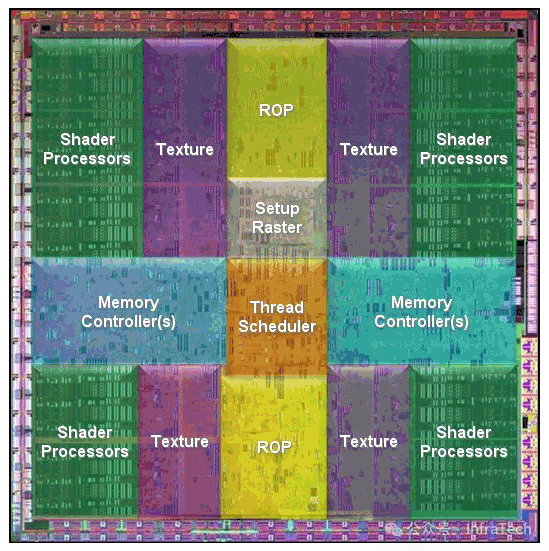
G80架构图(Tesla一代)
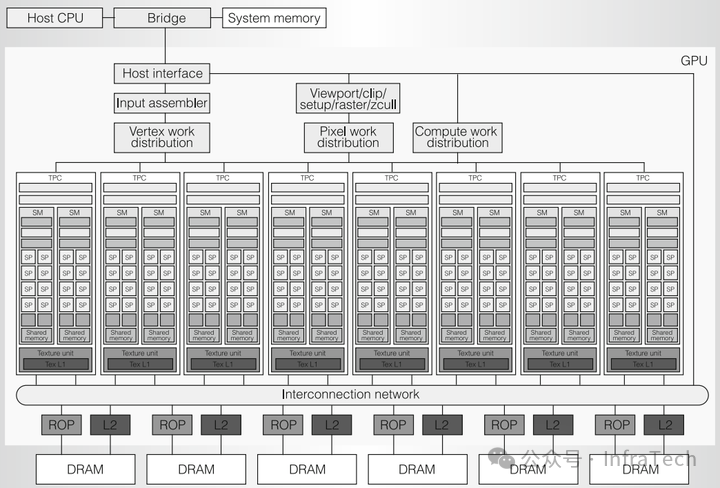
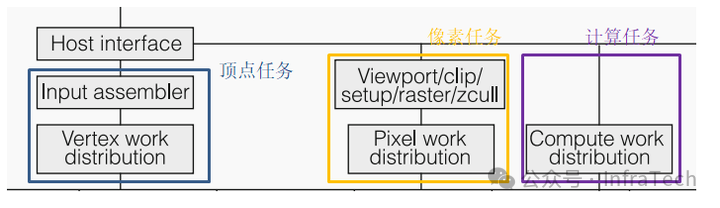
第一代Tesla是一种集图像与计算于一体的GPU架构。如图所示,主机(CPU)和系统内存通过总线(如PCIe)与GPU交互。架构大致分为三个区域:
- 调度与分发区域:包括顶点任务分发、像素任务分发和计算任务分发通道,负责任务的准备与派发。
- 计算区域:由多个阵列式的纹理/处理器簇(TPC)组成,负责具体运算。
- 存储与处理区域:包括光栅操作器(ROP)、二级缓存(L2 Cache)和全局内存(DRAM)。
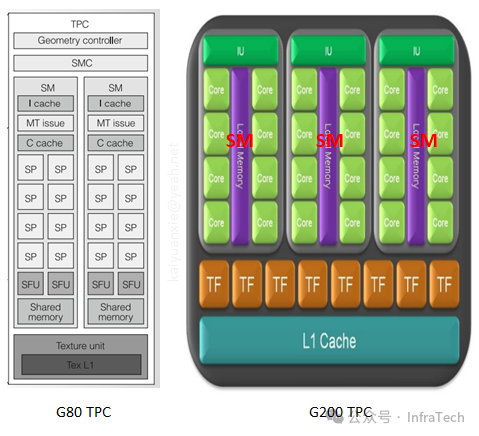
GT200架构图(Tesla二代图形版本)
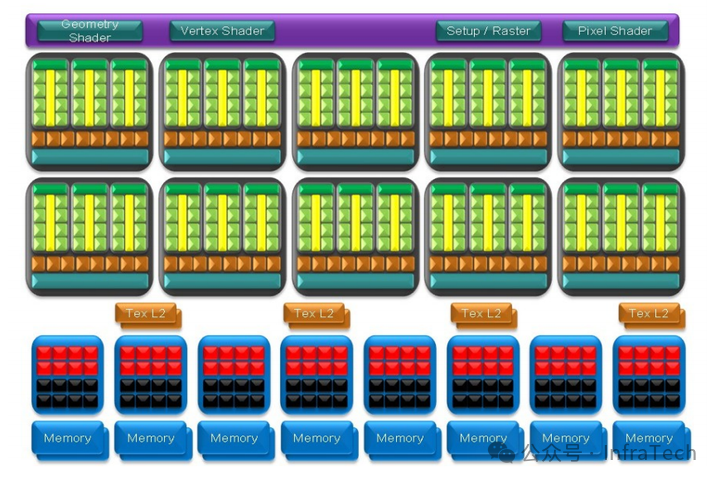
与G80架构类似,主要区别在于每个TPC包含的流多处理器(SM)数量增加至3个,且调度模块功能有所调整。
GT200架构图(Tesla二代并行计算版本)
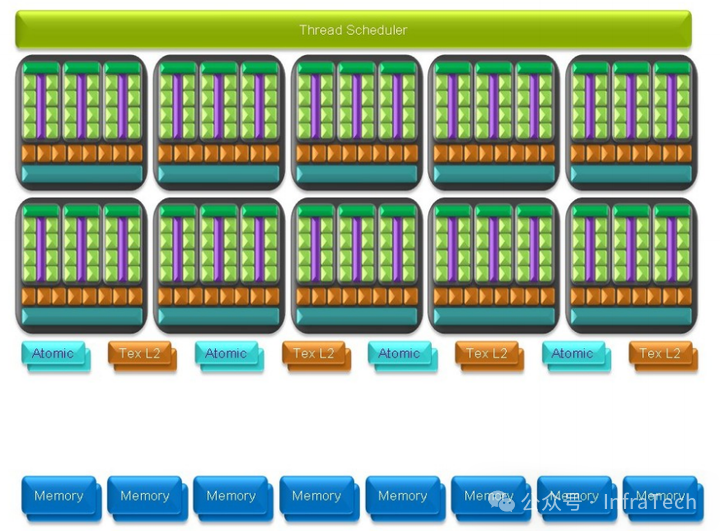
并行计算版本架构更加简洁,调度单元简化为一个任务编排器,并去除了ROP单元,增加了原子操作单元,以优化并行数据管理。
2.2 硬件参数
产品参数比较
Tesla一代和二代在整体性能上均有显著提升。以下是GeForce 8800 GTX与GeForce GTX 280的参数对比:
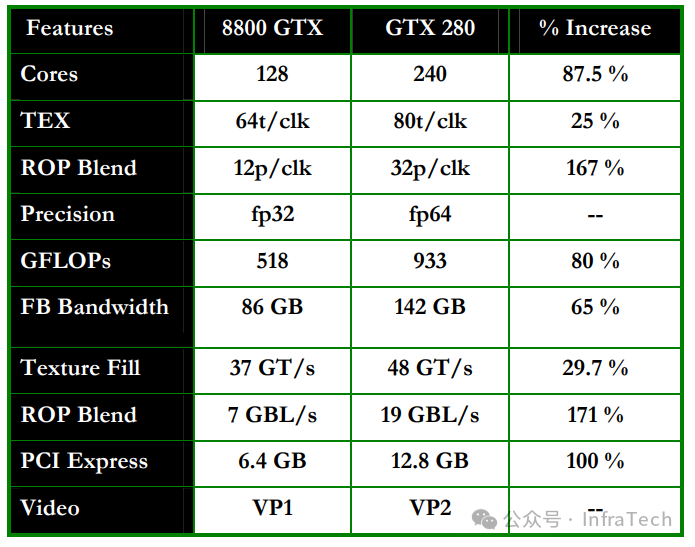
G80系列的理论算力(GFLOPS)最高可达约416,而GT200系列则提升至约1000,实现翻倍增长。
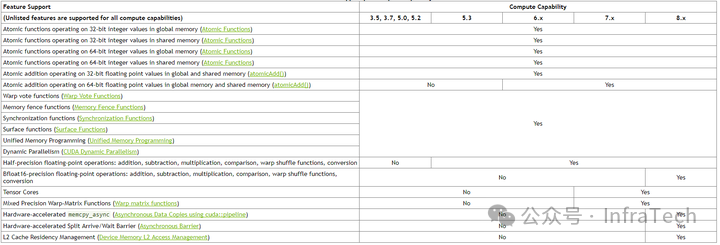
运算特性支持
G80的计算能力(Compute Capability)主要为1.0和1.1,引入的关键特性包括原子操作,确保了线程级写入安全。
- 算力1.1增加了对全局内存的32位整型/浮点数
atomicExch操作。
- 算力1.2进一步增加了全局内存的64位整型原子操作、共享内存的32位整型/浮点数
atomicExch操作,以及Warp Vote Functions。
GT200系列的部分型号(GT200a/b)支持计算能力1.3,引入了双精度浮点运算支持,并在SM中增加了专用的双精度浮点乘加单元(FMAD)。
注:由于年代久远,当前NVIDIA官方文档主要显示3.5及之后的计算能力特性。
2.3 芯片基板
G80基板(GeForce 8800 Ultra)

- 晶体管数量:6.81亿
- 工艺:90nm
- 流处理器(SP)核心:128个(16个SM)
- 核心频率:1.5 GHz
- 显存:支持768MB GDDR3,峰值带宽104 GB/s
GT200基板
得益于65nm工艺,GT200在芯片面积未大幅增加的情况下,集成了更多晶体管:
- 晶体管数量:14亿
- 工艺:65nm
- 流处理器(SP)核心:240个(30个SM)
PART 03 模块功能介绍
3.1 调度分配单元
调度单元负责在数据进入TPC运算阵列前进行处理,其设计会根据显卡定位(图形或计算)进行调整。
G80的调度分配单元:包含独立的顶点、像素和计算任务分发通道,分别处理对应的图形渲染管线阶段或通用计算任务。
GT200计算架构的调度单元:简化为一个全局块调度器,采用轮询机制将计算线程块分配给合适的SM执行。

注意:调度单元、SM运算单元以及显存控制器可能运行在彼此独立的时钟频率下。
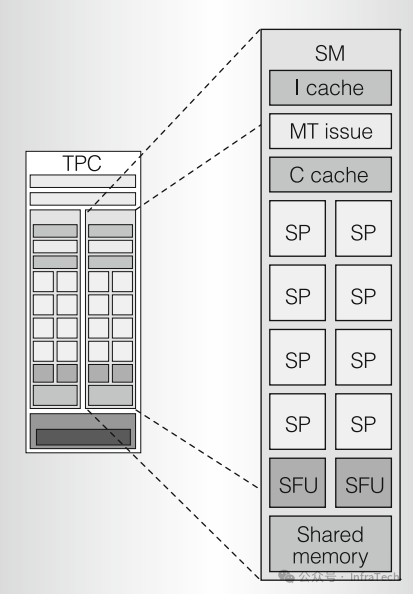
3.2 TPC单元
TPC是构成流处理器阵列的基本运算功能块。一个TPC通常包含多个SM、纹理缓存(Texture Cache)以及一个SM控制器(SMC),SM之间共享L1缓存。
3.3 SM单元
SM是指令执行的最小单元,负责调度线程在硬件上执行。
G80的SM单元:包含指令缓存、常量缓存、指令发射单元、8个流处理器(SP)、2个特殊函数单元(SFU)以及共享内存。
GT200的SM单元:在G80基础上,增加了一个64位双精度浮点乘加单元。
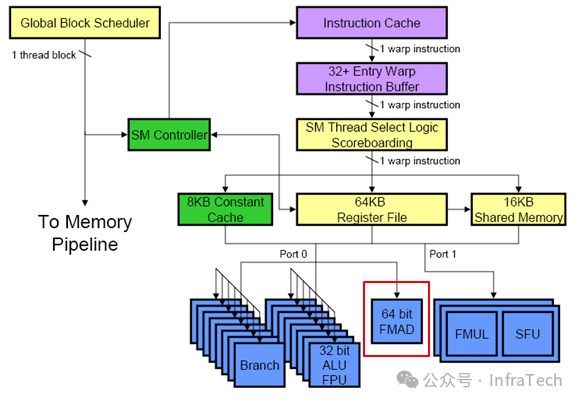
单元功能说明:
- 流处理器:执行32位整型/单精度浮点乘加运算(MAD),需4个时钟周期。
- SFU:执行复杂数学函数(如sin, cos, sqrt),需16个时钟周期。
- 双指令发射:为了提升效率,Tesla架构的SM支持双指令发射机制。例如,一个warp指令可以同时发射给SP单元执行MAD操作,下一个指令则发射给SFU执行MUL操作,从而实现SP和SFU的并行工作。
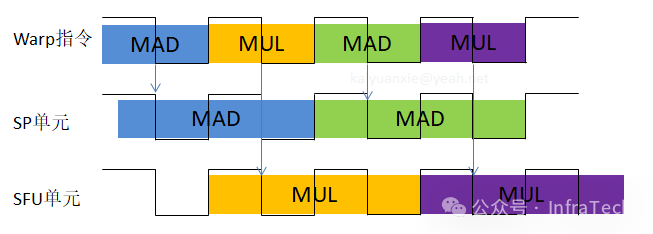
3.4 SM的工作机理
SM采用SIMT执行模型。线程被组织成Warp(大小为32个线程)进行管理。一个SM管理着一个由多个Warp组成的池(如G80的每个SM有24个Warps)。Warp之间由SM调度器按顺序调度执行,而非简单的FIFO队列。
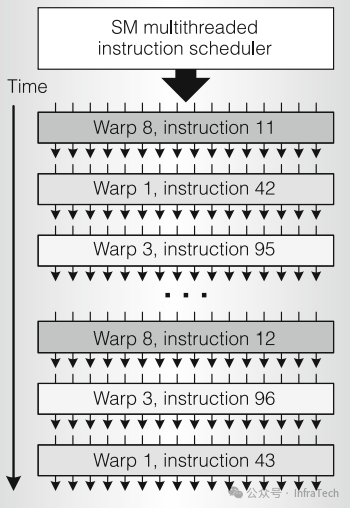
3.5 纹理单元与数据读写
纹理单元:专为图形处理中的纹理采样与过滤设计。它能够根据纹理坐标高效读取并处理数据(如进行双线性插值),相比普通的线性内存访问,能显著减少带宽浪费,但操作灵活性较低。
数据加载与存储路径:数据读写指令由SM发出。地址计算后,请求通过芯片内交叉总线发送到内存控制器。值得注意的是,内存控制器每次只能服务半个Warp(16个线程)的内存操作请求。
纹理与普通数据加载的路径对比如下(GT200):
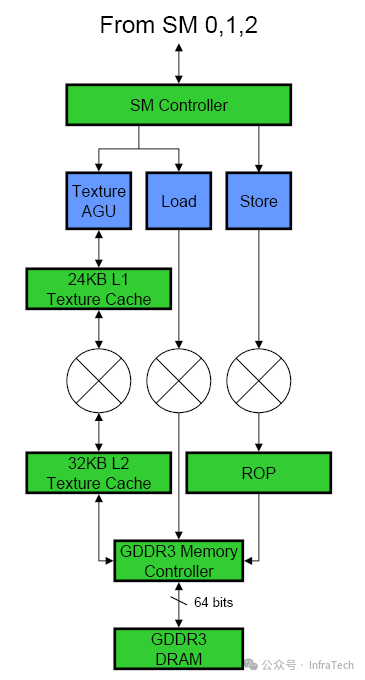
- 纹理路径:全局内存 -> 内存控制器 -> 纹理缓存 -> 纹理地址生成/过滤单元 -> SM。
- 加载/存储路径:与纹理路径部分共享,因此纹理操作和普通内存加载操作是互斥的。
ROP单元:光栅操作处理器,位于存储路径末端,直接处理像素的颜色混合、深度测试等固定功能操作。
PART 04 Warp Vote Functions
在Tesla二代(计算能力1.2)引入的Warp Vote操作,能高效实现Warp内线程间的信息聚合与同步,是并行计算编程中的重要优化手段。主要函数包括:
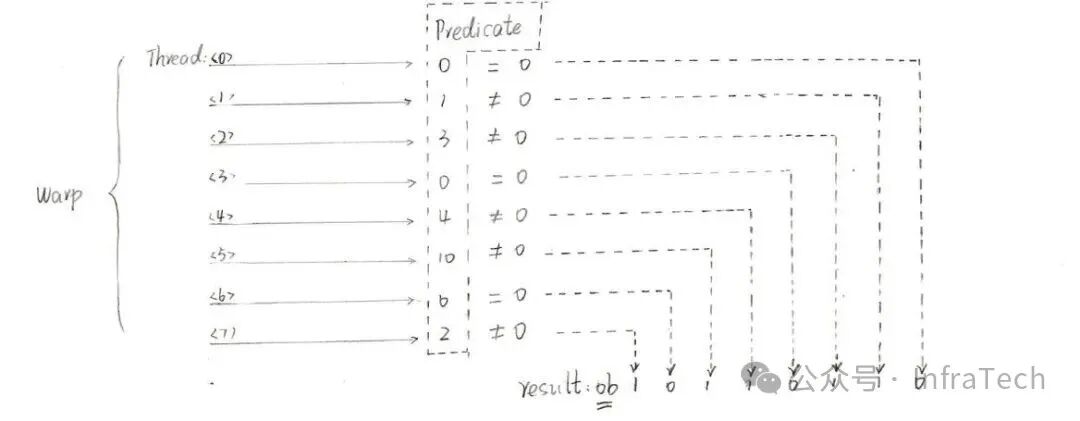
int __any(int predicate): 若Warp内任意线程的predicate非零,则返回1。int __all(int predicate): 若Warp内所有线程的predicate非零,则返回1。unsigned __ballot(int predicate): 返回值是一个掩码,其第N位对应Warp内第N个线程的predicate是否非零。
以__ballot为例,假设一个包含8个线程的Warp,其predicate值如下图所示,则返回结果为二进制0b10110110。
在CUDA 9.0之后,这些函数更新为_sync版本,增加了mask参数以指定参与操作的线程,提供了更精确的线程并发控制能力。
参考
 发表于 2025-12-14 14:33:41
|
查看: 243|
回复: 0
发表于 2025-12-14 14:33:41
|
查看: 243|
回复: 0
