随着深度学习模型的规模和复杂性不断提升,矩阵乘加运算已成为AI训练与推理中最主要、最昂贵的计算负载。传统GPU架构面向通用计算设计,在性能、能效和可扩展性之间越来越难以实现理想平衡。在此背景下,NVIDIA提出并持续演进Tensor Core,通过硬件级专门加速混合精度矩阵计算,重塑了GPU在AI计算中的性能边界。
本文将围绕其基本概念、工作原理以及在NVIDIA GPU微架构中的演进路径,系统解析Tensor Core如何成为现代AI算力体系的关键基础。
Tensor Core的引入
Tensor Core是嵌入在NVIDIA GPU流式多处理器(SM)中的专用硬件计算单元。在NVIDIA GPU架构中,核心计算资源主要由三类单元构成:CUDA Core、Tensor Core与RT Core。其中,Tensor Core专为深度学习和 AI 负载设计,负责高吞吐的矩阵乘积累加运算,是现代GPU AI性能的核心来源。

与通用的CUDA Core或传统ALU不同,Tensor Core不执行通用标量或矢量运算,而是专注于神经网络中最关键、最耗时的计算路径——矩阵乘法与卷积运算。尽管GPU本身已是高度并行的加速器,但Tensor Core在内部可视为“加速器中的加速器”,以更高的并行度与能效处理特定类型的计算任务。
NVIDIA于2017年在Volta微架构中首次引入Tensor Core,核心目标是将混合精度计算带入GPU硬件层。第一代Tensor Core通过融合乘加机制实现FP16输入、FP32累加的矩阵乘加运算,在保持良好数值稳定性的同时大幅提升计算吞吐。这一设计使Tensor Core成为深度学习训练与推理中不可或缺的基础计算单元。

随着GPU微架构持续演进,Tensor Core的能力也在不断扩展。从最初支持FP16/FP32混合精度计算,逐步引入对更低精度数值格式的支持,演进至BF16、TF32、INT8、INT4乃至FP8,在保持模型有效性的同时进一步压缩计算时间与功耗。
Tensor Core工作原理
Tensor Core的设计直指深度学习计算的本质特征:高度密集的矩阵乘法,以及可放宽数值精度的灵活性。在现代神经网络(如 Transformer)中,绝大部分算力消耗在矩阵乘加运算上,而这些运算并非始终需要以全FP32精度进行。这正是Tensor Core发挥作用之处。
从计算模型看,Tensor Core专用于执行形式为D = A × B + C 的运算。
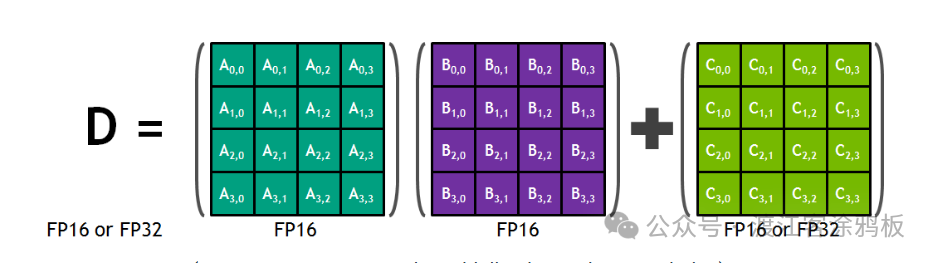
(图示:Tensor Core 4×4×4 矩阵乘积累加)
这种矩阵乘加(GEMM)运算是深度学习训练与推理中的核心算子。Tensor Core在硬件层直接实现GEMM操作,避免了由通用CUDA Core逐条执行乘加指令带来的效率瓶颈。
在微架构层面,每个Tensor Core包含一个固定尺寸的矩阵计算阵列。以第一代Tensor Core为例,基本计算单元为一个 4×4×4 矩阵乘加单元:
- 输入矩阵 A 和 B 为 4×4 FP16矩阵
- 累加矩阵 C 可为 FP16 或 FP32
- 输出矩阵 D 也可为 FP16 或 FP32
在一个时钟周期内,一个Tensor Core可完成一次4×4×4 GEMM运算,相当于64次乘法与64次加法构成的融合乘加运算。这些运算通过FMA机制在硬件中一次性完成,避免中间结果反复写回寄存器或缓存,从而显著提升吞吐与能效。
混合精度是Tensor Core高效运行的关键机制:矩阵乘法阶段使用FP16以降低计算复杂度与存储带宽需求,累加阶段则使用FP32以保证数值稳定性与结果精度。这种“低精度计算、高精度累加”的策略,确保在显著提升性能的同时,对模型收敛与推理精度的影响保持在极低水平。
在GPU执行模型中,Tensor Core调用由CUDA编程模型中的warp级调度处理。以Volta架构为例,一个SM包含8个Tensor Core,这意味着每个时钟周期内,一个SM理论上可完成8 × 64 = 512次浮点融合乘加运算。这是GPU在AI负载下实现数量级性能提升的关键原因之一。
总体而言,通过固定尺寸矩阵阵列、融合乘加运算与混合精度计算的结合,Tensor Core对深度学习中最常见、计算代价最高的路径实现了极致的硬件级优化,使其成为现代 GPU AI 计算性能爆发式增长的关键基础。
Tensor Core在NVIDIA GPU中的演进
随着NVIDIA GPU微架构的不断迭代,Tensor Core亦随之逐代演进,始终围绕两大核心目标:提升矩阵乘加运算的吞吐量,以及扩展所支持的数值精度范围。
通过硬件层对计算路径与数值格式的优化,Tensor Core使GPU在AI训练与推理场景中实现代际性能跃升。
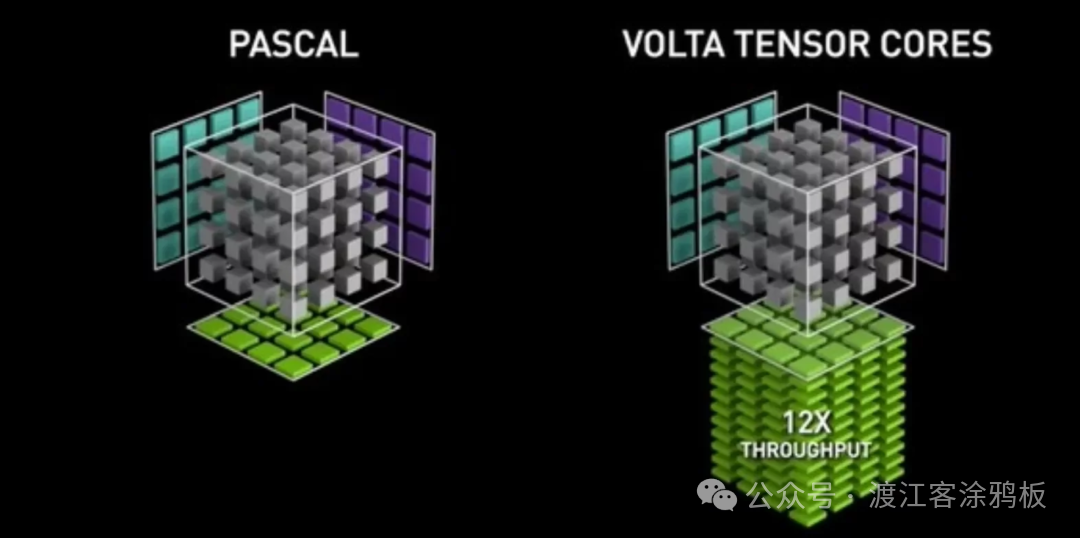
第一代:Volta架构
Tensor Core随Volta微架构首次亮相,首次将混合精度计算引入GPU核心计算单元。第一代Tensor Core以FP16为主要输入精度,并以FP32进行累加,显著提升矩阵乘加运算的吞吐。 以数据中心级V100为代表,Volta GPU在深度学习负载下实现最高12倍的AI理论吞吐提升。640个Tensor Core相比前代Pascal架构,带来约5倍的实际AI计算性能,标志着GPU正式进入“以 AI 为中心”的计算时代。
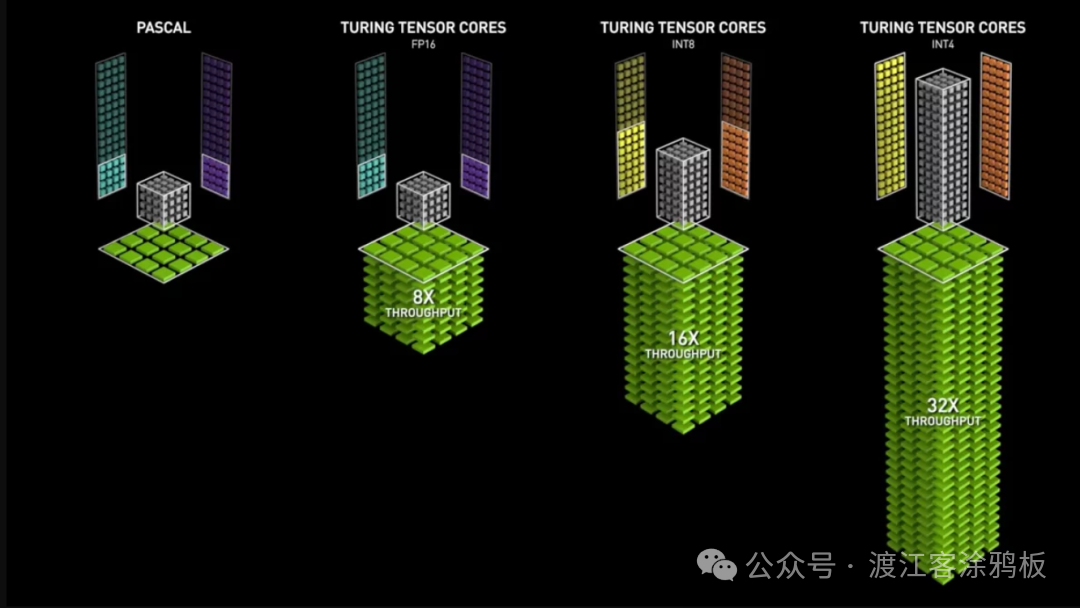
第二代:Turing架构
在Turing架构中,NVIDIA推出第二代Tensor Core,重要演进在于数值格式的扩展。除FP16外,Turing Tensor Core进一步支持INT8、INT4乃至INT1精度,使其在推理场景中具备更强的灵活性与能效表现。
得益于低精度计算能力的引入,Turing GPU在部分AI推理负载下可实现相比Pascal架构最高32倍的性能提升。Turing架构GPU还引入RT Core,增强3D环境中光影、音效等图形可视化效果。Turing架构亦首次搭载 RT Core,但Tensor Core仍是提升AI加速能力的核心。
第三代:Ampere架构
Ampere架构将Tensor Core推进至第三代,显著扩展计算精度覆盖范围,新增支持TF32、BF16及FP64(Tensor Core路径),让用户几乎无需修改代码即可在AI训练与推理中获得显著的性能提升。
以A100为代表的Ampere数据中心GPU,进一步通过结构化稀疏性(Structured Sparsity)放大Tensor Core的有效吞吐,在适用模型条件下实现指数级性能增长。
与此同时,Ampere架构结合第三代NVLink等系统级优化,大幅提升多GPU大规模训练效率。对于预算有限的用户,A4000、A5000、A6000 等工作站级GPU也继承了第三代Tensor Core的核心能力,使得自动混合精度训练在更广泛的应用中得以实现。
第四代:Hopper架构
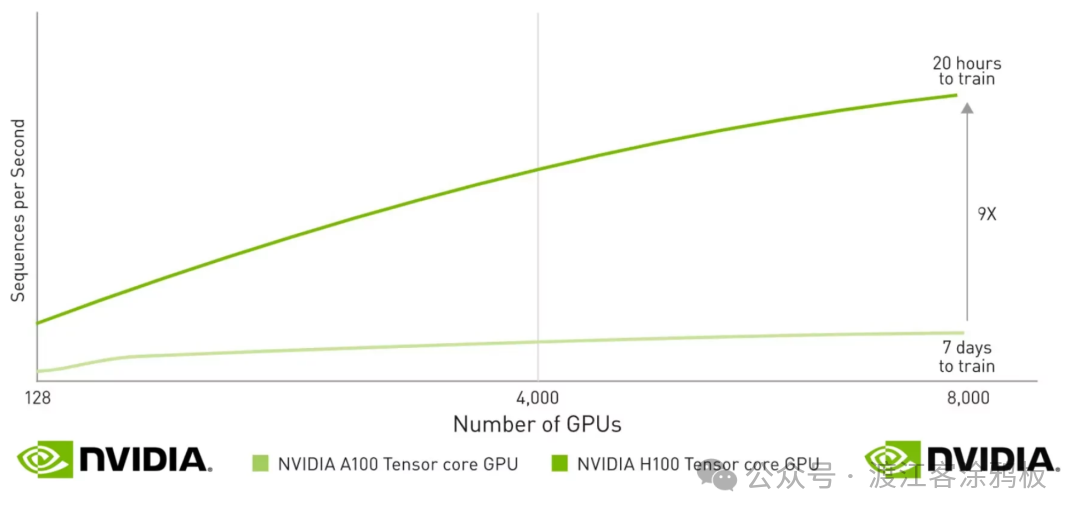
Hopper微架构标志着第四代Tensor Core的到来,最具代表性的演进在于原生支持FP8精度格式。FP8在保持模型收敛性与精度可控的前提下,进一步降低计算与存储开销,使Tensor Core在大模型训练与推理中的效率实现质变。例如,NVIDIA称H100在特定大语言模型场景中可实现相比前代最高30倍的性能提升。
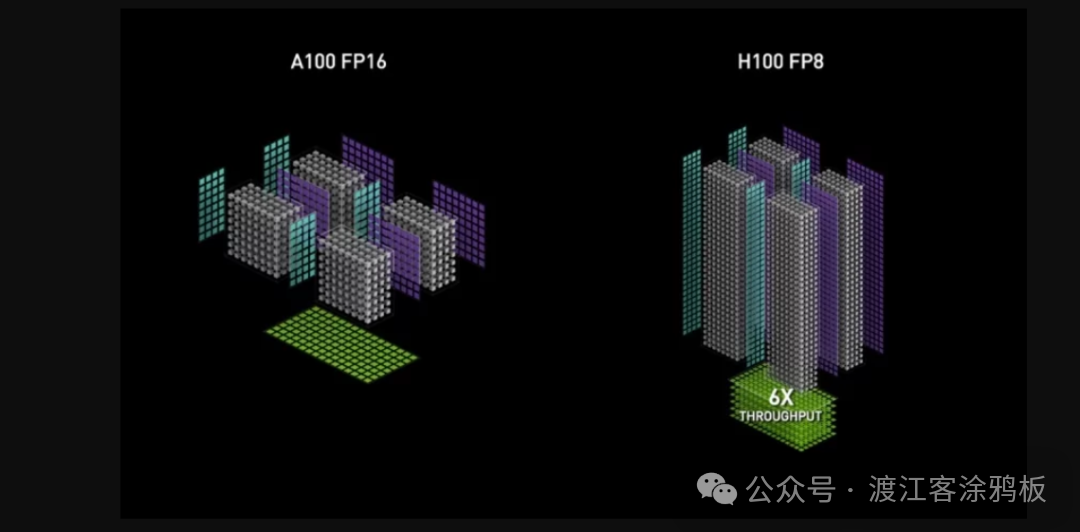
第四代Tensor Core还对Transformer架构进行了更多针对性优化,进一步巩固GPU在大规模 AI 训练与推理中的主导地位。
总体而言,Tensor Core在 NVIDIA GPU微架构中的演进路径清晰而连贯:从FP16混合精度起步,逐步扩展至多精度、多场景支持,并持续向更低精度、更高吞吐、更强系统级协同能力方向演进,成为推动计算性能飞跃的核心引擎。
总结
从Volta架构首次引入混合精度计算,到Hopper架构对FP8及Transformer负载的深度优化,Tensor Core的演进清晰体现了NVIDIA对AI计算本质的持续洞察。通过固定尺寸矩阵阵列、融合乘加机制与不断扩展的精度支持,Tensor Core在每一代GPU中显著提升矩阵计算的吞吐与能效,推动GPU从通用并行处理器向高度AI驱动的计算平台演进。可以预见,随着模型规模持续扩大、精度策略不断演化,Tensor Core仍将是NVIDIA GPU架构中驱动AI性能跃升的核心引擎。
对GPU硬件加速、深度学习底层原理及更多前沿技术感兴趣的开发者,欢迎访问云栈社区进行深度交流与资源共享。
 发表于 2026-1-16 06:38:05
|
查看: 287|
回复: 0
发表于 2026-1-16 06:38:05
|
查看: 287|
回复: 0
