本文是 ThunderKittens(TK)2.0 版本的发布与技术解析。TK 是一款轻量的嵌入式 CUDA 领域特定语言(DSL),专为编写高性能 GPU 内核而设计。
自两年前首次发布以来,团队将大部分精力投入到新功能的开发中,例如通用代码模板、定制化设备端调度器、英伟达 Blackwell 架构支持、FP8 精度支持、多 GPU 支持以及超级内核(Megakernels)。

本次版本更新的一大特点是“做减法”与“做加法”并重:团队重构了内部代码,剔除了冗余指令,简化了构建系统,并且在这个过程中发现了现代英伟达 GPU 上诸多出乎意料的硬件行为,这些发现本身也构成了一份珍贵的“避坑指南”。
ThunderKittens 2.0 的主要更新包括:
| 更新点 |
说明 |
| 新增功能 |
支持 MXFP8/NVFP4 低精度格式、CLC 调度、张量内存可控性;新增多款实用工具及 PDL 功能。 |
| 内部重构 |
对核心代码进行大规模重构,过程中识别出大量细微性能低效问题,并逐项优化。 |
| 示例简化 |
全面简化所有示例内核的构建结构,显著降低使用门槛,便于快速适配与二次开发。 |
| 行业贡献 |
多家企业基于 TK 衍生出内部分支,部分优化成果已开源回馈,形成协作生态。 |
这些改进使得我们能够用更少的代码、基于全新的优化策略编写出更快的 GPU 内核。作为例证,团队推出了全新的 BF16/MXFP8/NVFP4 精度通用矩阵乘法(GEMM)内核,在英伟达 B200 显卡上,其性能持平甚至超越了英伟达官方的 cuBLAS 库。
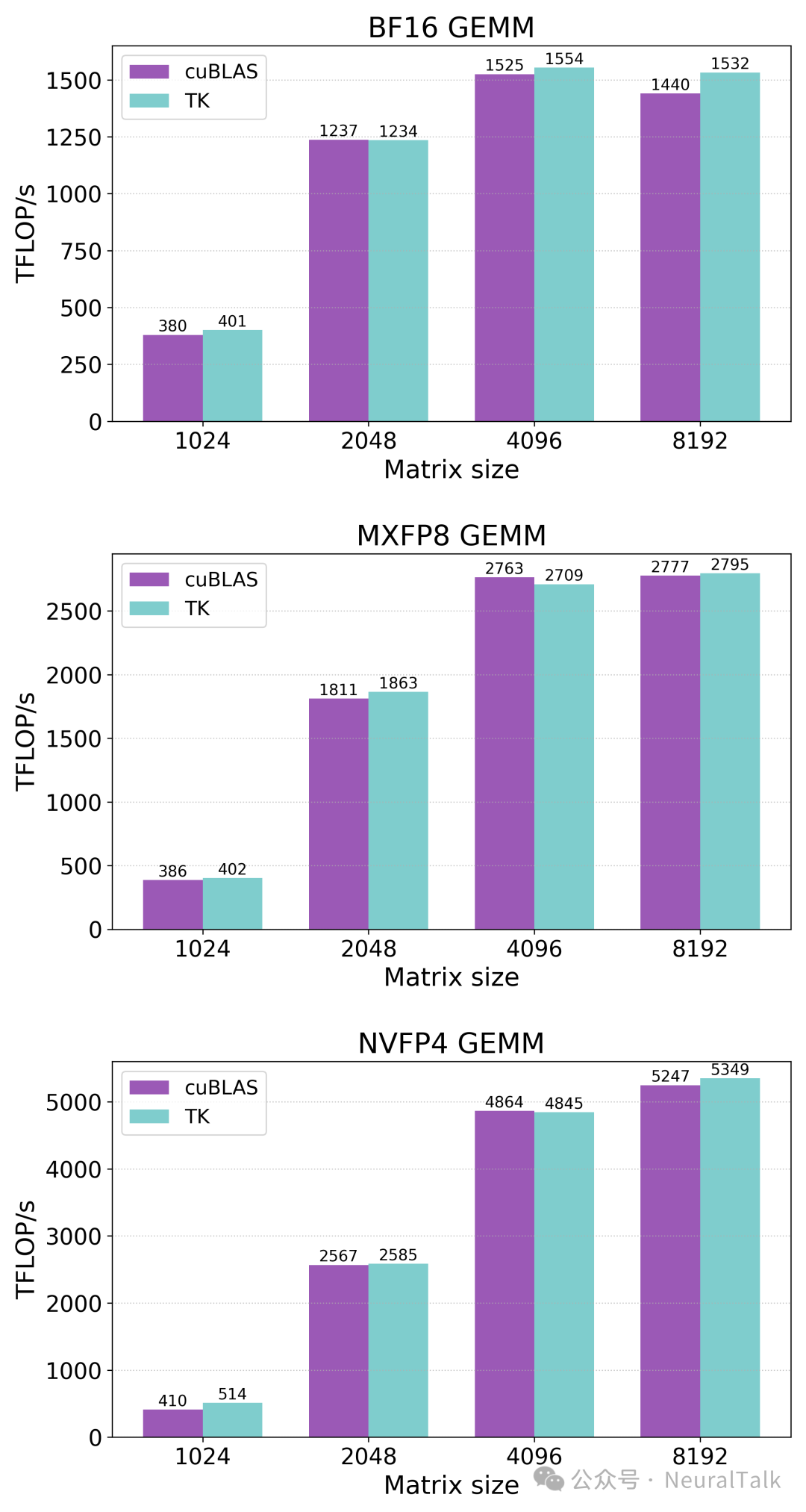
图 1 | 全新内核性能测试。所有内核均采用按位完全相同的随机输入,测试包含 500 次预热迭代、100 次性能分析迭代,并开启了 L2 缓存淘汰机制。
团队还对所有现有示例内核进行了更新以适配新版 API,并正在基于 TK 积极开发更多业界领先的内核,例如 Flash Attention 4、分组式通用矩阵乘法等。
下文将精选在优化 ThunderKittens 2.0 过程中发现的关键技术细节,这些都是榨干 GPU 最后一点性能的核心所在:
- 内存一致性:优化内存同步是实现峰值性能的关键,不当的栅栏指令会导致显著的性能损失。
- 张量核心与内存流水线:部分张量核心指令支持隐式流水线执行,但相关文档不完善,最优策略需探索。
- 向 PTX 汇编器传递优化提示:逻辑相同的代码,写法不同可能生成差异巨大的汇编指令。
- 线程占用率:分布式共享内存和张量核心指令会暗中限制线程占用率,传统优化思维可能失效。
- 合理开展 GPU 内核基准测试:需兼顾 L2 缓存使用与功耗等因素,测试方法本身就会影响结果。

关键问题探讨
问题一:关于 NVIDIA 在 tcgen05.copy 文档的错误
团队是如何发现 tcgen05.copy 在 PTX 文档中是一个笔误(应为 tcgen05.cp),并借此优化了 NVFP4 GEMM 性能的?
- 为何未能更早发现? 根本原因在于缺乏示例。PTX 文档仅在一处提到了这个流水线特性,且使用了错误的指令名(
copy而非cp),而文档其他部分从未出现过 tcgen05.copy 指令,也没有任何示例展示 tcgen05.cp 与 tcgen05.mma 是如何形成流水线的。这种孤证且错误的信息,使得团队难以确认这是一个真实特性而非笔误。
- 反映了 NVIDIA 文档的系统性缺陷吗? 这无疑揭示了文档在准确性和完整性上的问题。一个关键的优化特性被错误命名且缺乏示例,极大地增加了开发者的学习和试错成本。
- 开发者应如何应对? 当文档与性能期望不符时,要敢于怀疑并通过实验反向验证硬件行为。正是团队决定在代码中尝试将
cp 和 mma 放在同一线程,才最终验证并利用了这一特性。
问题二:关于张量内存与 Occupancy 硬限制
发现 tcgen05 指令会硬性限制每 SM 的 Occupancy 为 1,即使只使用了部分张量内存。这意味着什么?
- 张量内存是否是独占资源? 是的,实验表明,一旦内核访问了张量内存,其每 SM 的最大驻留线程块数就被硬限制为 1。这与 PTX 文档暗示的“可共享”概念相悖,更像是一个必须由单个线程块完全占有的资源。
- 这是否误导了开发者? 这清晰地指出了文档暗示与现实硬件行为之间的差距。开发者若遵循传统的高 Occupancy 优化思路,在涉及张量内存时可能会走入性能死胡同。
- ThunderKittens 的未来策略? 当 Occupancy 被限制为 1 时,性能优化策略必须从“横向扩展”转向“纵向挖潜”。这正是超级内核(Megakernel) 的核心思想:让单个线程块处理更多工作,从而压满整个 SM 的算力和带宽。这也是 TK 未来的重点探索方向之一。
一、内存一致性
CUDA/PTX 提供了多种内存一致性原语。缺少同步会导致竞态条件,而冗余的同步则会造成性能损失。事实上,优化获取/释放同步模式的使用,是团队超级内核实现性能超越的最后几步关键优化之一:几条冗余的内存栅栏指令就导致了超过 10% 的性能损失。
本节将展示如何合理设计内存栅栏的使用。以下是一段来自 ThunderKittens 中 Blackwell 架构下块缩放矩阵乘法流程的代码:
... // 准备指令与矩阵描述符
asm volatile("tcgen05.fence::after_thread_sync;\n");
asm volatile("fence.proxy.async.shared::cta;\n" ::: "memory");
... // 执行五代张量核心矩阵乘法
这段代码的作用是确保在执行 tcgen05.mma(张量核心矩阵乘法)指令前,所有输入数据(位于共享内存和张量内存)都已就绪且可被读取。但性能分析显示,这两条栅栏指令导致了约 20-30 TFLOP/s 的计算吞吐量损失。那么,它们真的必要吗?
1.1 理解 PTX 内存一致性模型
要回答这个问题,需要理解 PTX 的内存一致性模型。其核心是因果序:若一个线程的写操作与另一个线程的读操作满足因果序,则读操作一定能感知到写操作的结果。
因果序可通过“同一线程内有序”或跨线程的“释放-获取”操作链来建立。PTX 还有内存代理的概念,大多数操作用通用代理,而异步操作(如 tcgen05.mma, TMA加载)使用异步代理。因果序通常仅在同一代理内有效,跨代理需插入代理栅栏指令 (fence.proxy)。
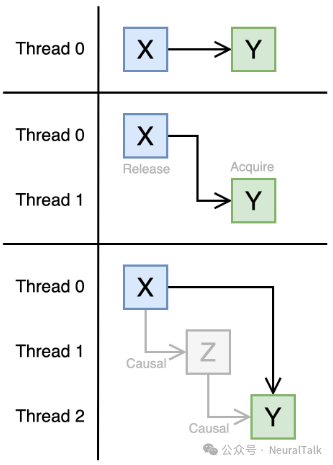
图 2 | PTX 中满足因果序的内存操作示例。
1.2 张量核心能否感知到输入数据?
张量核心执行时需感知两类数据:1) 通过 TMA 加载至共享内存的矩阵分块;2) 通过 tcgen05.cp 加载至张量内存的缩放因子。
通过结合 PTX 文档中多个分散的章节进行严谨推导:
- 对于 TMA 加载的数据:TMA 加载 (
cp.async.bulk.tensor) 是弱内存操作,使用异步代理。紧随其后的 mbarrier.complete_tx 是释放操作,并隐式插入了通用-异步代理栅栏。张量核心前的 mbarrier.try_wait 是获取操作,与 TMA 加载建立因果序。tcgen05.mma 由发起 try_wait 的同一线程执行,并通过异步代理读取共享内存。因此,在该特定场景下,TMA 写操作与张量核心读操作已通过传递性满足因果序,无需额外栅栏。
- 对于
tcgen05.cp 加载的数据:根据文档,tcgen05.mma 与 tcgen05.cp 指令支持隐式流水线执行,且支持流水线的指令无需额外的内存排序机制。因此,若 cp 与 mma 由同一线程发起,二者会自动满足有序性。而块缩放 GEMM 的标准范式正是如此。
结论:上述分析的两条内存栅栏指令均为冗余。在 GEMM 和注意力机制内核中剔除这类冗余指令后,性能提升了约 20 TFLOP/s。
二、张量核心与内存流水线
2.1 tcgen05.cp与tcgen05.mma的流水线化执行
在 MXFP8/NVFP4 精度的内核中,将缩放因子加载至张量内存是主要的性能瓶颈之一。以 NVFP4 精度、128x128x64 的线程块形状为例,一个完整的 MMA 阶段(连续4次矩阵乘)需要为 A、B 操作数执行多达 12 次 tcgen05.cp 调用。
最初的内核设计需要专门的线程束来执行这 12 次复制并显式等待完成,导致内核吞吐量比领先水平低约 10%。经过数周调试,团队在 PTX 文档 9.7.16.6.2 节发现了关于 tcgen05 流水线指令 的关键说明。

图 3 | PTX 文档中关于 tcgen05 流水线指令的说明。
文档中提到 tcgen05.copy 与 tcgen05.mma 支持隐式流水线。团队反复查阅后意识到,tcgen05.copy 实为 tcgen05.cp 的笔误——文档中再未出现过 copy 指令。基于此发现,内核被重新设计:将复制操作与矩阵乘法操作合并至同一线程执行,移除了屏障等待。
优化后的伪代码逻辑:
if (warp_id == 0) {
通过TMA加载A、B矩阵分块
} else if (warp_id == 1) {
通过TMA加载A、B矩阵缩放因子
} else if (warp_id == 3) {
等待矩阵和缩放因子加载至共享内存
通过tcgen05.cp加载缩放因子至张量内存 // 与下一条指令流水线化
执行4次矩阵乘法运算
}
这一优化最终恢复了约 500 TFLOP/s 的性能损失,NVFP4 GEMM 性能提升约 10%。
2.2 张量内存的流水线化设计
常见的张量内存流水线设计是双缓冲:将每个 SM 上 128x512 的张量内存分为两个 128x256 的区域,一个用于张量核心累加,另一个用于收尾线程读取上一次的结果。
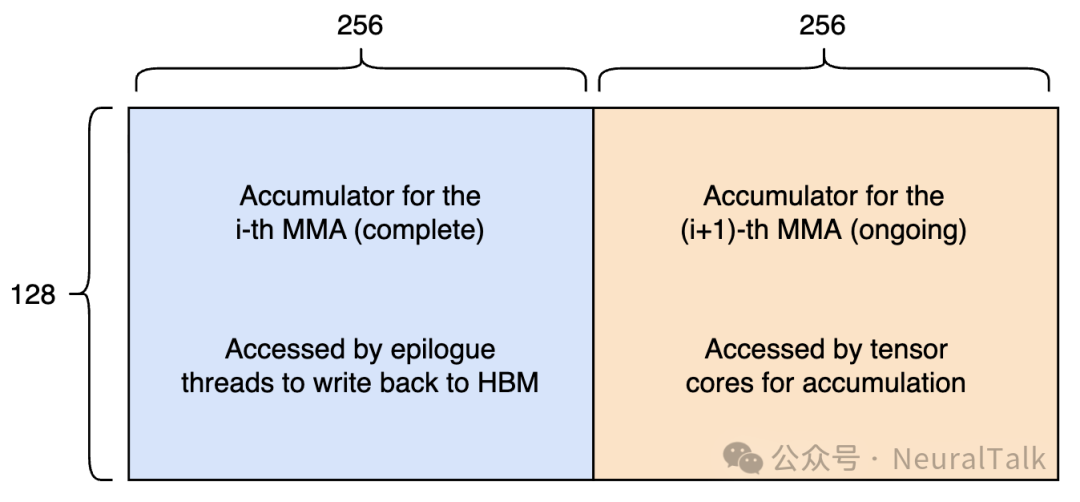
图 4 | 张量内存双缓冲设计。
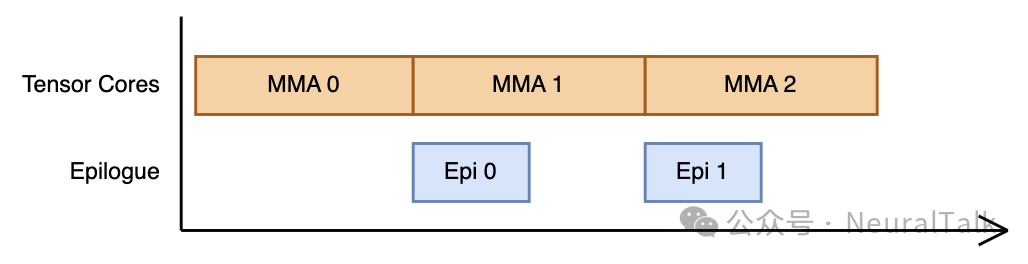
图 5 | 双缓冲设计的流水线执行流程。
该设计理论上无流水线气泡,在小尺寸 GEMM 中表现最优。但对于大尺寸 GEMM,团队发现双累加模式性能更佳。
双累加模式会同时运行两条矩阵乘法流水线(A×B0 和 A×B1),共享同一个 A 矩阵分块。此时整个 128x512 的张量内存都用于累加,虽然会在乘法之间因收尾线程读回数据而产生轻微气泡,但共享 A 矩阵大幅减少了内存访问量,优势明显。
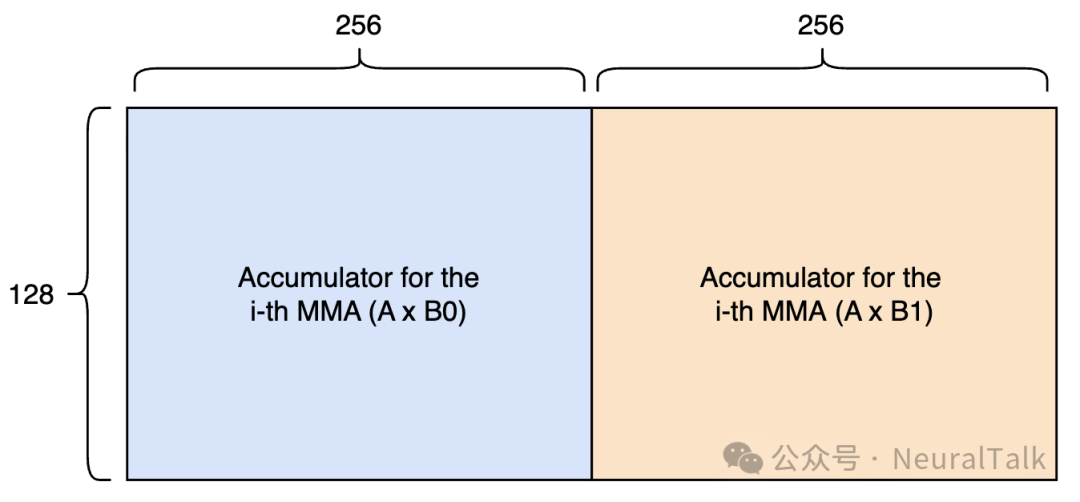
图 6 | 双累加模式的张量内存布局。
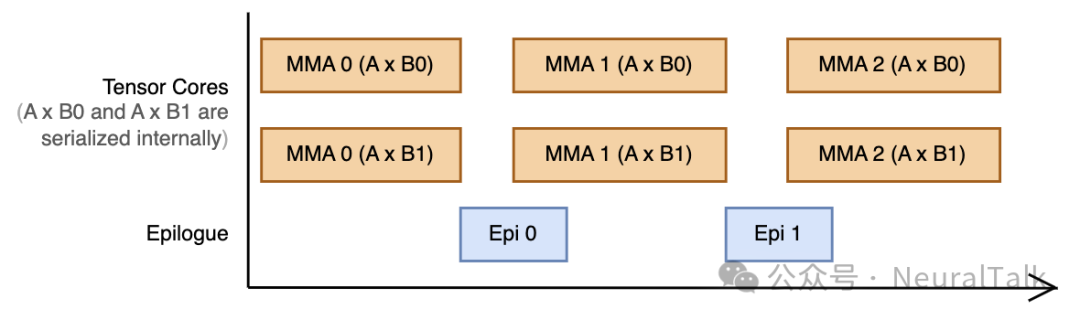
图 7 | 双累加模式的流水线执行流程(硬件内部对A×B0和A×B1串行化处理)。
该模式使 BF16 GEMM 性能提升了约 100 TFLOP/s。
三、SM90+架构下单线程指令的 PTX 汇编器行为
现代 GPU 内核常采用线程束专用化设计,某些角色(如发起 TMA 加载)仅需线程束内的单个线程。ThunderKittens 最初的设计代码如下:
if (warpgroup::groupid() == 0) {
if (warpgroup::warpid() == 0 && warp::laneid() == 0) {
tma::expect_bytes(arrived, sizeof(smem));
tma::load_async(smem, A, {0, 0}, arrived);
}
}
查看生成的 SASS 代码后发现问题:虽然源码逻辑保证只有一个线程执行,但 PTX 汇编器因无法验证这一点,保守地插入了一个串行化循环,让线程束内的线程逐个尝试执行 UTMALDG(TMA加载)指令。
解决方法:使用汇编器能识别的单线程选择指令——elect.sync。在 ThunderKittens 中,通过 warp::elect_leader() 函数实现:
if (warpgroup::groupid() == 0) {
if (warpgroup::warpid() == 0 && warp::elect_leader()) {
tma::expect_bytes(arrived, sizeof(smem));
tma::load_async(smem, A, {0, 0}, arrived);
}
}
修改后,SASS 代码中的循环被成功移除。将这一范式应用到内核中所有单线程指令后,小尺寸 GEMM 的计算吞吐量提升了约 10%。
四、线程占用率
4.1 并非所有流多处理器(SM)都支持所有 cluster 尺寸
大于 2 的线程块集群(Threadblock Clusters)可启用分布式共享内存以提升性能,但存在隐患:部分集群尺寸会导致调度器无法充分利用所有 SM。
以 B200 GPU(148个SM)上的持久化内核为例:
- 集群尺寸为2时,运行良好,共74个集群。
- 集群尺寸为4时,预期运行37个集群,但实际同一时间仅有 132 个SM处于活跃状态,剩余线程块需要等待。
测试不同集群尺寸的活跃 SM 数量如下:
| 集群尺寸 |
活跃流多处理器数量 |
| 2(网格尺寸 148) |
148 |
| 4(网格尺寸 148) |
132 |
| 8(网格尺寸 144) |
120 |
| 16(网格尺寸 144) |
112 |
这表明在持久化网格内核中盲目使用大于 2 的集群尺寸可能导致性能下降。推测原因是分布式共享内存需要SM间的硬件连线,而部分SM可能不具备此连线。
解决方案是放弃 __cluster_dims__ 属性,转而使用 cudaLaunchKernelEx API 启动内核,它可以指定首选集群尺寸和最小集群尺寸,调度器会智能分组以利用所有SM。
4.2 TCGEN05 指令会硬性限制每个流多处理器的线程占用率
一个更令人意外的发现是:内核一旦访问张量内存,每 SM 的最大线程占用率(Occupancy)会被硬性限制为 1。即使只分配了四分之一张量内存容量也是如此。
通过一个简单的测试内核即可验证:一个仅执行张量内存分配指令的空内核,其 cudaOccupancyMaxActiveBlocksPerMultiprocessor 返回值始终为 1。
这一结果与PTX指令语义所暗示的“可共享”相悖。对于涉及张量核心的内核,试图通过提升 Occupancy 来优化性能的传统思路是行不通的。这也进一步凸显了超级内核等“纵向挖潜”策略的重要性。
五、合理开展 GPU 内核基准测试
在数周的基准测试中,团队曾发现 CUTLASS 的 GEMM 内核始终比自己的快 100-150 TFLOP/s。最终发现,CUTLASS 性能分析器会默认将输入值四舍五入为整数,这减少了GPU晶体管的位翻转,降低了功耗和时钟节流概率,从而影响了结果。
这促使团队深入研究,意识到基准测试的每个细节都至关重要:使用几个CUDA事件、如何清理L2缓存、随机数分布等,可能导致高达 10% 的结果偏差。
基于大量实验,团队制定了一套GPU内核基准测试规范:
- 输入数据:使用按位完全相同的随机输入(通常为均匀分布)。
- L2缓存处理:若输入总尺寸小于3倍L2缓存大小,则使用多组输入,让每组自然淘汰前一组缓存,模拟冷缓存。避免显式刷新缓存(耗时剧增)。
- 预热:性能分析前执行500次预热迭代,让GPU达到稳定功耗状态。
- 性能迭代:执行100次性能分析迭代,内核连续启动,迭代间不同步。
- 计时:使用2个CUDA事件记录性能迭代的开始与结束时间。
- 测试间隔:不同内核测试间,让GPU短暂闲置散热。
以下伪代码展示了核心流程:
int l2_cache_size;
cudaDeviceGetAttribute(&l2_cache_size, cudaDevAttrL2CacheSize, 0);
int num_input_groups = (input_size >= l2_cache_size * 3) ? 1 : int(l2_cache_size * 3 / input_size) + 1;
// 准备num_input_groups组完全相同的输入
cudaDeviceSynchronize();
for (int i = 0; i < 500; i++) {
input_group_index = i % num_input_groups;
launch_kernel(inputs[input_group_index]);
}
cudaEventRecord(start_event);
for (int i = 0; i < 100; i++) {
input_group_index = i % num_input_groups;
launch_kernel(inputs[input_group_index]);
}
cudaEventRecord(end_event);
cudaEventSynchronize(end_event);
float milliseconds;
cudaEventElapsedTime(&milliseconds, start_event, end_event);
// 计算并保存吞吐量
sleep_ms(500);
六、未来规划
ThunderKittens 2.0 已完成对 Blackwell 架构的全面优化,并开始工业界应用。然而,仍有极致的优化方向,最关键的是应对现代 GPU 的多芯粒设计带来的非统一内存访问(NUMA)效应。
以英伟达 B200 为例,其两个芯粒间的互连带宽(约10TB/s)远低于单个芯粒内 L2 缓存的带宽。即使 L2 缓存命中,吞吐量也可能受限于芯粒互连。通过内核设计或模型架构优化来缓解 NUMA 效应,将带来显著的性能提升。
团队对超级内核的研究仍在继续。超级内核已被验证在多种负载下性能优于主流推理引擎。当前的核心挑战在于降低其使用门槛。团队认为,这并非需要全新的DSL或编译器,而是需要对机器学习基础设施进行根本性改造。PyTorch 作为优秀的前端,但其已有十余年历史的底层后端架构,可能并非榨干现代 GPU 性能的最优解。
技术的演进永不止步,我们期待在云栈社区与广大开发者一起,继续探索 GPU 计算的性能极限。
 发表于 2026-2-22 04:44:25
|
查看: 296|
回复: 0
发表于 2026-2-22 04:44:25
|
查看: 296|
回复: 0
