今天在技术社区看到一个关于“NPU算子悖论”的讨论:如果一个工程师能在指令集难用、文档匮乏的国产NPU上写出媲美NVIDIA显卡的性能,他理应比同等水平的CUDA工程师强。但现实中,前者的薪资往往不如互联网大厂。
这个悖论背后,其实指向了一个行业痛点:GPU/NPU算子调优,长久以来被视为一门无法量产、极其耗神的“手艺活”。
工程师们常常陷入枯燥的循环:对着Nsight Compute报告中几十项晦涩的硬件计数器反复揣摩,手动推演瓶颈,小心翼翼地调整tile shape或访存模式,然后跑一轮基准测试,再看一轮报告,周而复始。更令人沮丧的是,好不容易在一个算子上积累的经验,几乎无法系统性地迁移到下一个——每一次优化都像是推倒重来。
这就解释了为什么国产NPU“大神”的价值可能被低估:因为他们的生产力被手工作坊式的调试工具封印了。
那么,如果存在这样一个系统呢?它能自动完成 “编译-验证-测速-剖析-提出假设-生成新版本-再验证” 的完整闭环,更重要的是——它还能记住哪些策略有效,哪些是死胡同。
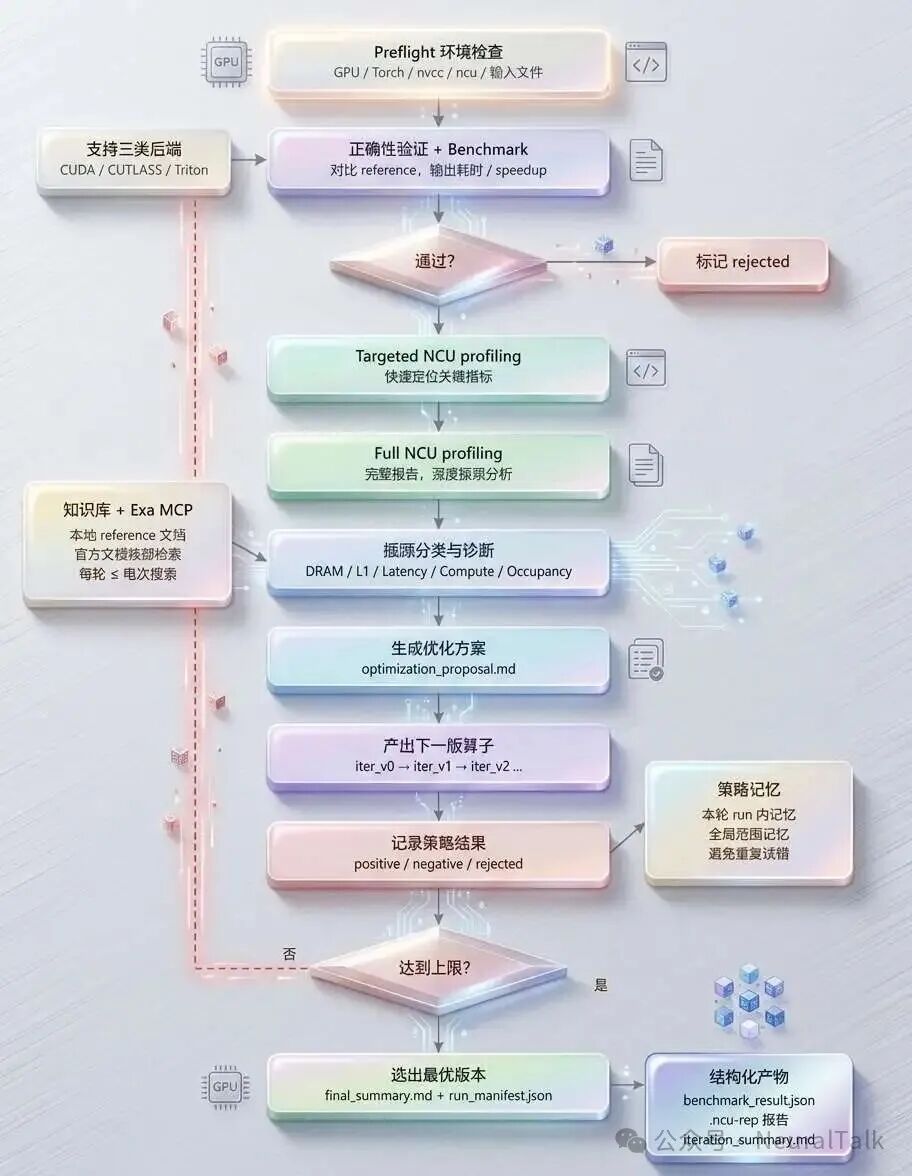
GPU算子自动化优化与验证的全流程框架
这正是开源项目 cuda-optimized-skill 的目标。它并非又一个GPU内核模板库,而是一个面向 AI编码智能体(如Claude Code)的“优化技能包”,旨在将算子调优从人类专家的经验驱动,升级为数据驱动、可复现、有记忆的工程系统。
项目简介:
- A CUDA kernel optimization toolkit for validation, benchmarking, Nsight Compute profiling, bottleneck analysis, and iterative tuning. It helps improve custom GPU operators with reproducible workflows and evidence-based performance comparison.
- GitHub: https://github.com/KernelFlow-ops/cuda-optimized-skill
接下来,让我们快速上手体验,并深入其设计哲学。
一、三分钟上手:从零开始跑通优化闭环
技术解析重要,但“先跑起来”才是程序员的第一直觉。本章用最精简的步骤,带你快速体验。
1.1 环境准备
你需要一台装有NVIDIA GPU的机器,并确保以下工具就绪:
# 基础依赖:Python 3.8+、PyTorch(CUDA版本)、nvcc、ncu
python -c "import torch; print(torch.cuda.is_available())" # 应输出 True
nvcc --version # CUDA/CUTLASS后端需要
ncu --version # 所有后端的性能剖析需要
然后克隆项目:
git clone https://github.com/KernelFlow-ops/cuda-optimized-skill.git
cd cuda-optimized-skill
1.2 最快体验:一条命令跑Benchmark
如果你已有一个CUDA内核文件(如my_kernel.cu,其中暴露了extern "C" void solve(...)接口),一行命令即可完成编译、运行和性能测量:
# 简单例子:只做benchmark,无reference对比
python skills/optimized-skill/kernel-benchmark/scripts/benchmark.py my_kernel.cu \
--M=4096 --N=4096
脚本会自动检测GPU架构、用nvcc编译、分配CUDA张量并运行。如果还有Python参考实现,加上--ref即可验证正确性:
# 正确性验证 + benchmark + 加速比对比
python skills/optimized-skill/kernel-benchmark/scripts/benchmark.py my_kernel.cu \
--ref=my_ref.py --M=4096 --N=4096
Triton用户也只需一行:
python skills/optimized-skill/kernel-benchmark/scripts/benchmark.py my_triton_kernel.py \
--backend=triton --ref=my_ref.py --M=4096 --N=4096
提示:--backend不填时,脚本按文件后缀自动推断——.py走Triton,.cu走CUDA。
1.3 完整体验:一条命令启动多轮迭代优化
真正的价值在于多轮迭代优化。一条命令即可启动“Benchmark → NCU剖析 → 策略记忆 → 下一版本”的完整闭环:
# CUDA算子:3轮迭代优化
python skills/optimized-skill/operator-optimize-loop/scripts/optimize_loop.py my_kernel.cu \
--ref=my_ref.py --max-iterations=3 --M=4096 --N=4096
# CUTLASS算子:3轮迭代优化
python skills/optimized-skill/operator-optimize-loop/scripts/optimize_loop.py my_cutlass.cu \
--backend=cutlass --ref=my_ref.py --max-iterations=3 --M=4096 --N=4096
# Triton算子:3轮迭代优化
python skills/optimized-skill/operator-optimize-loop/scripts/optimize_loop.py my_triton.py \
--backend=triton --ref=my_ref.py --max-iterations=3 --M=4096 --N=4096
其中--max-iterations是除算子文件外的唯一必填参数。完成后,你会在算子同目录下看到optimize_runs/run_YYYYMMDD_HHMMSS/目录,内含每一轮的benchmark结果、NCU报告、优化提案和最终摘要。
1.4 只检查环境
不确定环境是否就绪?加一个--preflight-only就能做完整的环境检查:
python skills/optimized-skill/operator-optimize-loop/scripts/optimize_loop.py my_kernel.cu \
--max-iterations=1 --preflight-only
这会生成preflight_check.md和preflight_check.json,列出GPU型号、驱动版本、nvcc/ncu路径、PyTorch CUDA状态等信息。
1.5 在AI Agent中使用(推荐姿势)
本项目的设计初衷是作为AI编码智能体的“技能包”。如果你使用支持类似Codex技能的Agent,最简单的方式是直接让其调用优化流程。Agent会自动阅读每一轮的NCU报告,生成下一版算子,并在策略记忆的约束下持续迭代。
二、架构总览与设计哲学
2.1 项目定位:不是库,是“技能”
传统GPU算子优化库(如CUTLASS、Triton)提供的是算子实现本身。而cuda-optimized-skill提供的是优化过程的标准化编排能力。它假设上游有一个AI编码智能体,由智能体负责“理解代码、提出优化方案、生成新版本算子”,而本项目则负责“跑benchmark、抓NCU报告、判定策略成败、记住经验教训”。
项目由四个子模块构成:
skills/optimized-skill/
├── kernel-benchmark/ # 统一benchmark入口
├── ncu-rep-analyze/ # NCU性能剖析与诊断
├── operator-optimize-loop/ # 多轮迭代主编排引擎
└── reference/ # 按后端组织的优化知识库
├── cuda/
├── cutlass/
└── triton/
四个模块的关系:knowledge驱动proposal,benchmark + NCU提供evidence,optimize-loop完成闭环编排,strategy-memory沉淀经验。
2.2 三后端统一:一套流程,三种武器
项目同时支持三类GPU编程后端:
- CUDA:原生
.cu文件,暴露extern "C" void solve(...)接口
- CUTLASS:同样是
.cu文件,但使用NVIDIA CUTLASS模板库
- Triton:Python
.py文件,暴露约定式接口
三者共享完全相同的评测-剖析-迭代流程。这种设计的精妙之处在于:AI智能体无需关心底层后端差异,只需按统一协议交付算子文件,优化引擎就能自动完成后续全部工作。
三、Benchmark引擎:统一的性能度量基座
3.1 CUDA/CUTLASS的签名解析与自动装配
Benchmark引擎(benchmark.py)是整个系统的“度量衡”。对于CUDA/CUTLASS后端,它做了一件巧妙的事情——自动解析C函数签名,动态构造调用参数。
# 来源:skills/optimized-skill/kernel-benchmark/scripts/benchmark.py
def parse_solve_signature(cu_file: str):
"""从 extern "C" void solve(...) 中提取参数列表"""
with open(cu_file, "r", encoding="utf-8") as f:
content = f.read()
pattern = r'extern\s+"C"\s+void\s+solve\s*\(([\s\S]*?)\)\s*\{'
match = re.search(pattern, content)
if not match:
raise ValueError(f'Cannot find \'extern "C" void solve(...)\' in {cu_file}')
raw = match.group(1)
raw = re.sub(r"/\*.*?\*/", "", raw) # 去注释
raw = re.sub(r"//[^\n]*", "", raw)
raw = " ".join(raw.split())
params = []
for token in raw.split(","):
# ... 逐参数匹配类型和名称
is_const = "const" in token
# 指针参数 → 自动分配CUDA tensor
# 整型参数 → 从命令行维度参数中读取
这段代码通过正则表达式从.cu源码中提取solve(...)的参数签名,然后根据类型自动分配GPU内存。这意味着:只要你的CUDA内核暴露了标准的solve(...)接口,benchmark引擎就能零配置地为你构造完整的测试环境。
3.2 Triton后端的约定式接口
对于Triton后端,benchmark引擎采用“约定大于配置”的策略:
# 来源:skills/optimized-skill/kernel-benchmark/scripts/benchmark.py
def _setup_triton(solution_file, dim_values, seed=None):
module = load_python_module(solution_file, "_triton_kernel_module")
# 要求模块必须定义 setup() 和 run_kernel()
prepared = module.setup(**setup_kwargs)
# setup() 返回 {"inputs": {...}, "outputs": ["out"]}
reference_inputs = prepared.get("inputs")
outputs = prepared.get("outputs")
Triton模块需实现setup()和run_kernel()两个函数,让benchmark引擎无需了解内核实现细节,实现真正的后端解耦。
3.3 正确性验证:快了但错了,不算数
Benchmark引擎内建了严格的正确性验证流程。当提供reference实现时,引擎会:
- 用相同的随机种子和输入数据,分别运行kernel和reference。
- 逐张量对比输出,计算误差。
- 正确性失败时立即终止,不会产出任何性能数据。
# 来源:skills/optimized-skill/kernel-benchmark/scripts/benchmark.py
def _validate_outputs(kernel_tensors, ref_tensors, output_params, atol, rtol):
all_pass = True
for pname, ptype in output_params:
kt = kernel_tensors[pname].float()
rt = ref_tensors[pname].float()
match = torch.allclose(kt, rt, atol=atol, rtol=rtol)
if not match:
all_pass = False
# 报告第一个错误位置和具体数值差异
diff_mask = ~torch.isclose(kt, rt, atol=atol, rtol=rtol)
bad_idx = diff_mask.nonzero(as_tuple=True)[0]
这个设计原则非常重要:性能优化的前提是正确性。在迭代编排中,正确性失败的版本会被自动标记为rejected。
四、迭代编排引擎:optimize_loop.py的精密流水线
4.1 每轮迭代的强制流程
迭代编排引擎optimize_loop.py是核心。其设计目标是:让每一轮迭代都可复现、有完整证据链、结果可追溯。
# 来源:skills/optimized-skill/operator-optimize-loop/scripts/optimize_loop.py
def main() -> int:
# 1. 解析参数,推断后端
backend = infer_backend(solution_file, args.backend)
# 2. 创建/恢复 run 目录
run_dir = ensure_run_dir(solution_file, args.run_dir)
# 3. 初始化策略记忆
strategy_memory = ensure_strategy_memory(manifest, scope_key, global_memory_file)
# 4. Preflight环境检查
preflight = collect_preflight(args, benchmark_script, solution_file, ref_file, backend)
# 5. 快照当前算子版本
snapshot_file = iter_dir / f"{solution_file.stem}_v{iteration}{solution_file.suffix}"
shutil.copy2(solution_file, snapshot_file)
# 6. 运行benchmark
bench_res = run_command(bench_cmd, benchmark_stdout, benchmark_stderr)
# 7. 运行targeted NCU(5个关键section)
# 8. 运行full NCU(--set full)
# 9. 导入NCU报告为文本
# 10. 判定策略成败,更新记忆
# 11. 选出当前最优版本
# 12. 生成结构化summary
每一轮迭代生成独立的iter_v{i}/目录,包含算子快照、benchmark结果JSON、NCU报告、诊断文本、迭代摘要等完整产物。
4.2 两阶段NCU剖析策略
NCU(Nsight Compute)剖析被设计为两阶段:
第一阶段 targeted——只采集5个最关键的section:
# 来源:skills/optimized-skill/operator-optimize-loop/scripts/optimize_loop.py
TARGETED_SECTIONS = [
"LaunchStats",
"Occupancy",
"SpeedOfLight",
"MemoryWorkloadAnalysis",
"SchedulerStats",
]
def build_targeted_ncu_cmd(args, bench_cmd, out_prefix):
cmd = [args.ncu_bin, "--target-processes", "all",
"--profile-from-start", "on",
"--launch-skip", str(args.launch_skip),
"--launch-count", str(args.launch_count)]
for section in TARGETED_SECTIONS:
cmd.extend(["--section", section])
cmd.extend(["-o", str(out_prefix), "-f"])
cmd.extend(bench_cmd)
return cmd
第二阶段 full——使用--set full采集所有指标,提供完整性能画像。
之所以分两阶段,是因为--set full开销巨大,而targeted的5个section已覆盖90%以上的常见瓶颈。这在效率和信息完备性间取得了平衡。
4.3 Preflight:启动前的安全网
Preflight实现了一套全面的环境预检机制:
# 来源:skills/optimized-skill/operator-optimize-loop/scripts/optimize_loop.py
def collect_preflight(args, benchmark_script, solution_file, ref_file, backend):
# 检查GPU型号、compute capability、driver version
torch_info = probe_torch_cuda(args.gpu)
# 检查 nvidia-smi
nvidia_smi_info = probe_nvidia_smi()
# CUDA/CUTLASS检查nvcc
if backend in {"cuda", "cutlass"}:
nvcc_info = probe_executable(args.nvcc_bin, "nvcc", ["--version"])
# 所有后端检查ncu
if backend_supports_ncu(backend):
ncu_info = probe_executable(args.ncu_bin, "ncu", ["--version"])
# 交叉验证 --arch 与实际 GPU capability
if args.arch and gpu_info.get("sm") and args.arch != gpu_info["sm"]:
warnings.append(f"--arch={args.arch} does not match ...")
所有结果被序列化为JSON和Markdown两种格式,贯穿整个项目。
五、策略记忆机制:让AI不再重蹈覆辙
5.1 问题:AI的“遗忘”与“执念”
没有策略记忆时,AI智能体在多轮优化中容易犯两个错误:
- 遗忘:上一轮尝试过的失败策略,下一轮又重新提出。
- 执念:某个曾经有效的优化方向,在不适用的场景下仍被反复推荐。
策略记忆机制正是为了解决这两个问题。
5.2 指纹计算与分类判定
每一轮迭代的优化策略会从optimization_proposal.md中提取为标签,然后计算唯一指纹:
# 来源:skills/optimized-skill/operator-optimize-loop/scripts/optimize_loop.py
def build_strategy_fingerprint(backend: str, tags: list[str]) -> str:
canonical = {"backend": backend, "tags": tags}
raw = json.dumps(canonical, sort_keys=True, ensure_ascii=False)
return hashlib.sha1(raw.encode("utf-8")).hexdigest()[:16]
每个策略被分类为三种结果之一:
def classify_strategy_outcome(record, previous_record):
# benchmark失败 → rejected
if record.get("benchmark_rc") != 0:
return ("rejected", "benchmark_failed")
# 正确性失败 → rejected
if bench.get("has_reference") and correctness.get("passed") is False:
return ("rejected", "correctness_failed")
# NCU失败/缺失 → rejected
# 比上一轮更快 → positive
if current_median < previous_median:
return ("positive", "faster_than_previous")
# 否则 → negative
return ("negative", "slower_or_equal_to_previous")
5.3 两级记忆:当前run + 全局
策略记忆存储在两个层级:
- 当前run:存在
run_manifest.json的strategy_memory.current_run字段中。
- 全局:存在
global_strategy_memory.json中,按scope key隔离。
// 来源:global_strategy_memory.json 示例片段
{
"scopes": {
"cutlass__cutlass_softmax__...": {
"positive": {
"693f19f37331ba8b": {
"tags": ["register_cached_exp", "rowwise_softmax_shape_specialization", ...],
"last_outcome": "positive",
"evidence": {"baseline_median_ms": 0.14894, "current_median_ms": 0.10317}
}
},
"negative": {
"f5f0e39777db3029": {
"tags": ["keep_vectorized_single_pass", "register_fragment_expansion", ...],
"last_outcome": "negative"
}
}
}
}
}
下一轮迭代开始时,系统自动合并两级记忆,生成约束。blocked列表中的策略指纹被禁止再次使用,preferred列表中的被优先融合。这等于给AI智能体装上了“集体记忆”。
六、最优版本选择:严格的资格赛
不是每个跑出数字的版本都有资格参与“最优版本”评选。规则非常严格:
# 来源:skills/optimized-skill/operator-optimize-loop/scripts/optimize_loop.py
def choose_best_iteration(iterations):
candidates = []
for item in iterations:
# 条件1:full NCU报告必须存在
if ncu_required and not item.get("full_report_exists"):
continue
# 条件2:有reference时,正确性必须通过
if bench.get("has_reference") and not correctness.get("passed"):
continue
# 条件3:必须有有效的median和average
if kernel.get("median_ms") is None or kernel.get("average_ms") is None:
continue
candidates.append(item)
# 排序:median最低 → average最低 → 更早的版本优先
return min(candidates, key=lambda item: (
item["benchmark_result"]["kernel"]["median_ms"],
item["benchmark_result"]["kernel"]["average_ms"],
item["iteration"],
))
设计哲学:
- full NCU报告是硬性要求——没有完整性能剖析证据,即使数字再漂亮也不认可。
- 正确性是一票否决——快了但错了,直接淘汰。
- 排序优先看median而非average——因为median对噪声更鲁棒。
这与“一条命令跑通”的简洁体验形成对比:入口极简,标准极严。
七、实战效果:CUTLASS Softmax优化案例
项目仓库中记录了一个真实优化案例:使用CUTLASS后端对softmax算子进行4轮迭代优化,对标PyTorch原生softmax。
python skills/optimized-skill/operator-optimize-loop/scripts/optimize_loop.py \
example/cutlass_softmax.cu \
--backend=cutlass --ref=example/cutlass_softmax_ref.py \
--max-iterations=3 --rows=4096 --cols=1024
从全局记忆文件中可以看到完整优化轨迹:
| 版本 |
策略标签 |
结果 |
Kernel median (ms) |
| v0 |
baseline |
positive |
0.14894 |
| v1 |
vectorized_float4_io, thread_retile_128, register_cached_exp |
positive |
0.10317 |
| v2 |
retile_64_for_higher_ilp, register_fragment_expansion |
negative |
0.14587 |
| v3 |
approximate_exp_path, revert_to_128_tile, arithmetic_only_tuning |
positive |
0.10245 |
v2试图通过缩小tile到64来提高指令级并行度,结果反而导致性能回退——这个策略的指纹被记入negative,后续不会再被采用。v3则聪明地回退到128 tile(因为v1的记忆显示它有效),同时尝试近似exp路径,最终将kernel median从0.14894ms降到0.10245ms,延迟下降31.2%,相对PyTorch reference加速比达2.04x。
这个案例完美展示了策略记忆的价值:v3之所以能做出正确决策,正是因为它“记住了”v1的成功和v2的失败。
总结与技术价值
cuda-optimized-skill的本质贡献,不在于某一个CUDA内核写得有多快,而在于它重新定义了GPU算子优化的工作范式:
- 从人类经验驱动到数据证据驱动:每一轮优化决策都基于benchmark数字和NCU报告中的具体硬件计数器,而非直觉。
- 从一次性手工调优到可复现的自动化闭环:一条命令即可启动完整流水线,每一步都有结构化产物。
- 从“调完就忘”到有记忆的持续进化:策略记忆机制让优化经验跨轮次、跨任务沉淀,AI智能体越用越聪明。
- 从单一后端到三后端统一编排:CUDA、CUTLASS、Triton共享一套评测和迭代框架,降低了多后端切换的认知负担。
在AI编码智能体快速发展的今天,这个 开源项目 指向了一个值得关注的方向:AI不仅可以写代码,还可以像一个有经验的性能工程师那样系统性地优化代码——前提是,你给它配上正确的“工具”和“记忆”。
而你要做的,可能真的只是一条命令。对于想要深入探讨 CUDA 高性能计算与AI工程化实践的开发者,欢迎在 云栈社区 交流分享。
 发表于 2026-4-19 04:07:24
|
查看: 240|
回复: 0
发表于 2026-4-19 04:07:24
|
查看: 240|
回复: 0
