随着扩散大语言模型(dLLM)的兴起,其并行生成能力为高效推理带来了新的可能。然而,这种新范式也带来了新的性能瓶颈。一项针对 NVIDIA RTX A6000 GPU 的实证分析显示,dLLM 的采样阶段耗时可占总推理延迟的 70%。这主要是因为采样需要进行全词表扫描、大量内存读写和非规则的 Token 更新操作,而这些恰恰是以通用矩阵乘法为核心的现代神经网络处理器(NPU)的软肋。

为了从根本上解决这个问题,来自帝国理工学院和剑桥大学的研究团队提出了一种名为 d-PLENA 的新型 NPU 架构。它通过一套软硬件协同设计,专门优化了扩散采样中的非 GEMM 操作。实验结果表明,在相同工艺节点下,d-PLENA 相比 NVIDIA RTX A6000 实现了最高 2.53 倍的加速。这一突破性成果为未来高效能、低延迟的 dLLM 部署,无论是云端还是边缘设备,提供了关键的硬件设计思路。更多前沿的人工智能硬件加速讨论,也欢迎在云栈社区交流。
一、 问题根源:为什么传统硬件在采样阶段效率低下?
自回归大模型(LLM)的解码是串行的,容易受内存带宽限制。扩散大语言模型通过并行去噪来缓解这个问题,但也带来了新的计算模式。
采样成为主要瓶颈:如图1所示,尽管基于 Transformer 的去噪模型层占据了大部分浮点运算,但后续的采样阶段(包括全词表归约、Top-K 选择和掩码更新)却贡献了大部分的端到端延迟。尤其是在采用双 KV-Cache 的 MoE 模型上,这一比例高达 71%。
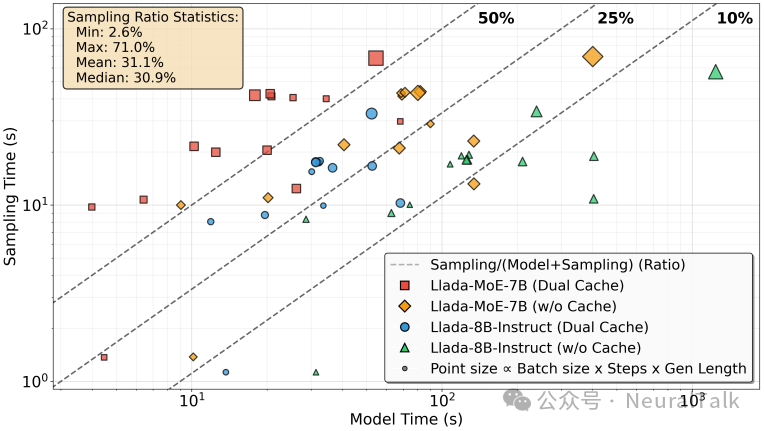
图1:采样阶段(Sampling Time)在多种配置下都贡献了主要延迟,占比平均值达31.1%。
采样阶段的核心操作与传统的 Transformer 层计算截然不同:
- 内存密集型:每个扩散步骤需要处理维度为
B×L×V 的 logits 张量(B为批大小,L为序列长度,V为词表大小,可达12万以上)。这导致巨大的内存访问需求。
- 控制与归约密集型:需要频繁执行寻找最大值、求和、排序(Top-K)和条件选择等操作。
- 非规则访存:基于置信度分数选择性地更新掩码 Token,导致内存访问模式不规则。
现有的 NPU(如 PLENA)专为 GEMM 和注意力计算优化,对上述操作缺乏高效的硬件支持,要么产生巨大指令开销,要么被迫将采样卸载到 CPU,严重拖累整体效率。
二、 d-PLENA 架构:为采样而生的专用设计
d-PLENA 的设计哲学是识别并硬件加速扩散采样中不变的核心原语,包括词表扫描、归约、排序和掩码选择。其核心架构如图2所示。
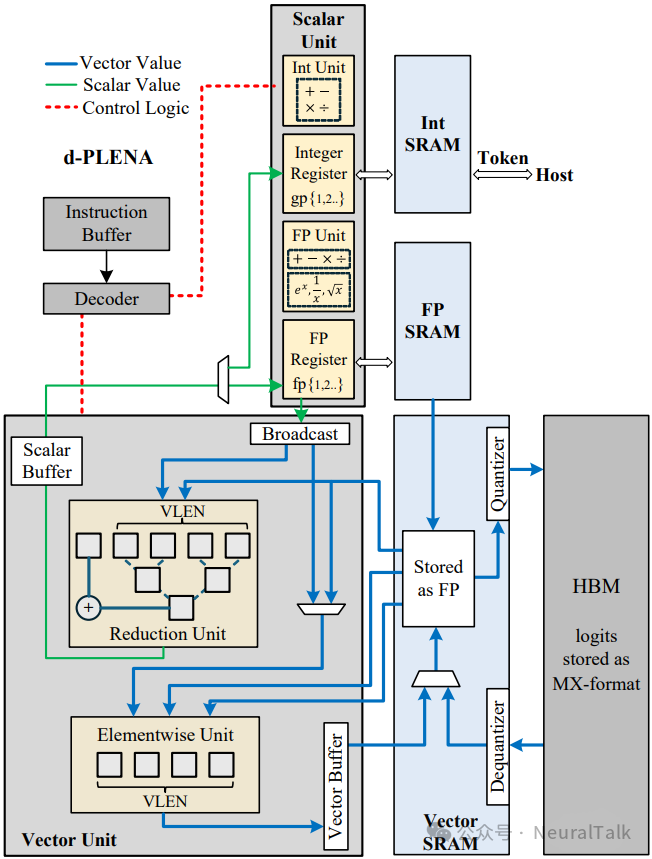
图2:d-PLENA 架构核心,采用解耦的混合精度存储层次和专用计算单元。
1. 解耦的混合精度存储层级
为了高效处理采样中的异构数据并减少内存碎片,d-PLENA 将片上存储解耦为三个独立部分:
- 向量 SRAM:存放从 HBM 流式加载并经过解量化的 logits 数据(如 BF16 格式)。
- 浮点 (FP) SRAM:专门存储置信度分数等标量浮点中间结果。
- 整数 (INT) SRAM:隔离存储 Token ID 等整型数据,并通过 FIFO 直接与主机交互,减少控制路径干扰。
2. 专用计算单元
执行核心针对采样操作进行了特化:
- 向量单元:包含归约单元(用于快速计算最大值、求和等)和逐元素计算单元。
- 浮点单元 (FPU):原生硬件支持
exp, 1/x, sqrt 等超越函数,加速 Softmax 类计算。
3. 硬件友好的算法转换
为了让硬件更高效地执行,研究团队将标准的 Softmax 计算重构为 “Stable-Max” 形式。
Algorithm 1 Algorithmic Transformation: Software Softmax vs. Hardware-Friendly Stable-Max
1: Method 1: STANDARD SOFTMAX (PyTorch-like)
2: max_idx ← argmax(logits)
3: p ← softmax(logits)
4: x0_p ← p[max_idx]
5: METHOD 2: STABLE-MAX (NPU-OPTIMIZED)
6: m ← max(logits)
7: exp_shifted ← e^(logits-m)
8: sum_exp ← ∑ exp_shifted
9: x0_p ← 1.0/sum_exp
公众号 · NeuralTalk
算法1:将 Softmax 拆解为可被专用硬件单元(归约、FPU)高效执行的原子操作。
这种转换将计算分解为:归约单元求最大值 m -> FPU 计算 exp(logits-m) -> 归约单元求和 -> FPU 计算倒数。中间结果可以原地写回向量 SRAM,极大提高了内存利用率。
三、 定制指令集与四阶段采样流程
d-PLENA 扩展了一套轻量级指令集(ISA),将采样的关键操作映射为单条硬件指令,极大降低了调度开销。
| Instruction Format |
Description |
V_RED_MAX_IDXD (rd, rs1, rs2, rs3) |
向量归约操作,同时找出最大值及其索引。 |
S_ST_FP (rd, rs1, imm) |
将标量浮点值从 FP 寄存器存储到 FP SRAM。 |
S_ST_INT (rd, rs1, imm) |
将标量整数值从 GP 寄存器存储到 INT SRAM。 |
S_MAP_V_FP (rd, rs1, imm) |
将 L 个 FP 格式元素从 FP SRAM 传输到 Vector SRAM。 |
V_TOPK_MASK (rd, rs1, rs2, k_scalar) |
执行 Top-k 排序并生成掩码。 |
V_SELECT_INT (rd, rs1, rs2, rs3) |
基于掩码的逐元素选择操作(对应 torch.where)。 |
结合定制的指令集,整个扩散采样流程被组织成四个清晰的硬件执行阶段,如算法2所示。

算法2:硬件感知的块内采样流程,通过 V_chunk 参数适配不同内存容量的设备。
采样四阶段:
- 阶段❶ (HBM → Vector → Scalar):从 HBM 预取 logits 分块 (
V_chunk) 到向量 SRAM,并行执行归约计算(如 V_RED_MAX_IDX),得到置信度分数和候选 Token ID 的标量。
- 阶段❷ (Scalar):将标量结果分别写回 FP SRAM (
S_ST_FP) 和 INT SRAM (S_ST_INT)。
- 阶段❸ (Scalar (FP) → Vector → Scalar (INT)):从 FP SRAM 重构置信度向量,使用
V_TOPK_MASK 指令生成需要更新的 Token 位置掩码。
- 阶段❹ (Scalar (INT)):根据掩码,使用
V_SELECT_INT 指令从 INT SRAM 中选择新的 Token 更新序列。
这种设计通过 V_chunk 参数实现了灵活性:在资源受限的边缘设备上,可以设置较小的 V_chunk 进行分块处理;在资源充足的场景,可以设置为整个词表大小 V 以最大化数据复用和性能。
四、 实验结果:性能与能效的双重优势
研究团队通过周期精确仿真和综合,对 d-PLENA 进行了全面评估。
1. 性能大幅超越 GPU
在相同的采样工作负载 (B=32, T=16, L=64, V=128k) 下,d-PLENA 与 NVIDIA RTX A6000 的对比如表2所示。
| Performance |
A6000 |
d-PLENA(512) |
d-PLENA(1024) |
d-PLENA(2048) |
| Latency (ms) |
2.51 |
3.41 (0.73×) |
1.79 (1.40×) |
0.99 (2.53×) |
| Vector SRAM |
- |
8 MB |
8 MB |
8 MB |
| Int SRAM |
- |
8 kB |
8 kB |
8 kB |
| FP SRAM |
1 kB |
2 kB |
4 kB |
8 kB |
表2:d-PLENA 在不同 VLEN 配置下均优于 GPU,最高实现 2.53 倍加速。
当向量长度 (VLEN) 配置为 2048 时,d-PLENA 实现了 2.53 倍 的加速。指令级分析(表3)显示,其执行周期中近50%是高效的向量操作,而标量和控制开销被成功控制在12%以下,证明了专用指令集的有效性。
2. 适应边缘部署的可扩展性
d-PLENA 并非只能用于高性能场景。图5(d) 显示,通过调整块大小 V_chunk,在片上 SRAM 占用很小(<64kB)的情况下,当 V_chunk 超过约 4k 条目后,延迟和带宽即接近饱和。这意味着无需巨大的片上缓存即可获得高效能,非常适合边缘部署。
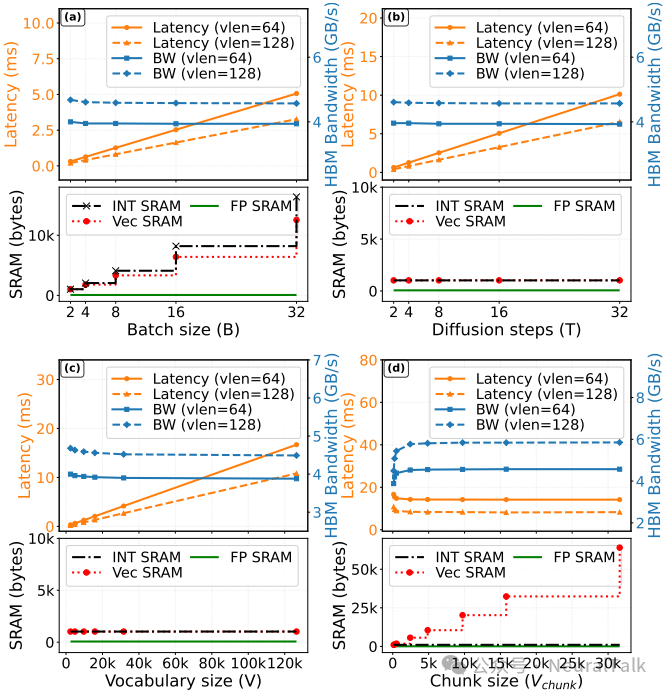
图5:参数分析表明,增大分块大小 (V_chunk) 可有效摊薄开销,片上SRAM占用主要由批大小 (B) 和分块大小 (V_chunk) 决定。
3. 面积与功耗评估
综合结果显示(表4),d-PLENA 的硬件开销可控。向量单元面积与 VLEN 线性增长,而标量控制部分面积恒定且较小。在 VLEN=512 的适中配置下,总功耗约为 382mW,对于许多边缘应用场景而言是可接受的。
| VLEN |
Vector Area (mm²) |
Total Power (mW) |
| 512 |
0.731 |
381.72 |
| 1024 |
1.464 |
762.65 |
| 2048 |
2.931 |
1524.58 |
表4:不同 VLEN 配置下的综合后面积与功耗(标量区域面积恒定为 661 µm²)。
五、 结论与展望
d-PLENA 的工作表明,随着大模型生成范式的演进,硬件设计也必须进行相应的创新。通过专门针对扩散采样中的核心原语(归约、排序、选择)进行硬件加速和存储层次优化,可以释放被传统 GEMM 中心化设计所束缚的性能。
这项研究为未来 NPU 的设计提供了一个重要方向:支持更丰富的非 GEMM 原语。随着模型量化技术的进步,采样阶段作为“长尾瓶颈”的问题将愈发突出,而类似 d-PLENA 的专用化设计将是攻克这一瓶颈的关键。其对边缘部署的友好设计也展示了专用硬件架构在多样化场景下的潜力。
 发表于 2026-2-12 02:30:02
|
查看: 165|
回复: 0
发表于 2026-2-12 02:30:02
|
查看: 165|
回复: 0
