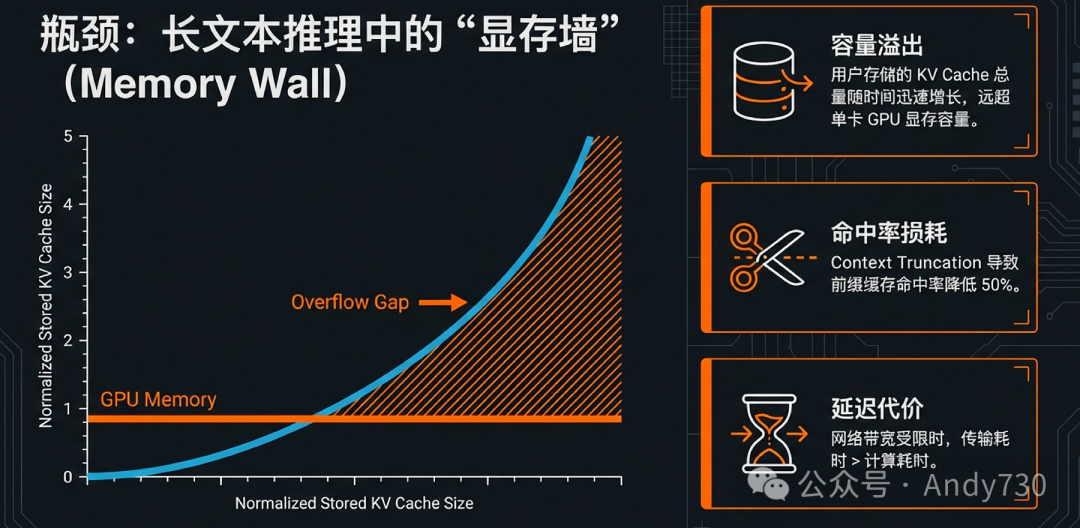
随着大语言模型(LLM)的上下文窗口从数万扩展到百万级别,推理系统正面临日益严峻的延迟挑战。Transformer模型在生成首个Token前必须完成的预填充(Prefill)阶段,其计算开销随输入序列长度呈超线性增长。以复杂任务为例,KV Cache的体积会迅速膨胀——例如Llama-3-34B处理8万Token时产生的缓存高达19GB,几乎与模型权重相当。这种规模的内存占用,在显存仅有24GB的边缘设备(如NVIDIA A10)上,将导致长达12秒的首字延迟(TTFT)。如何突破这一“显存墙”瓶颈?
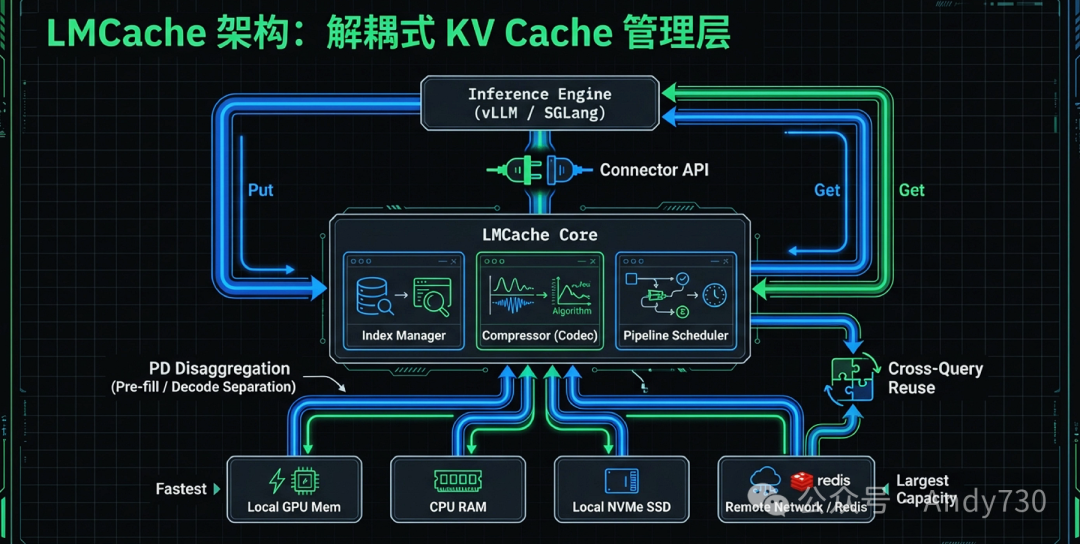
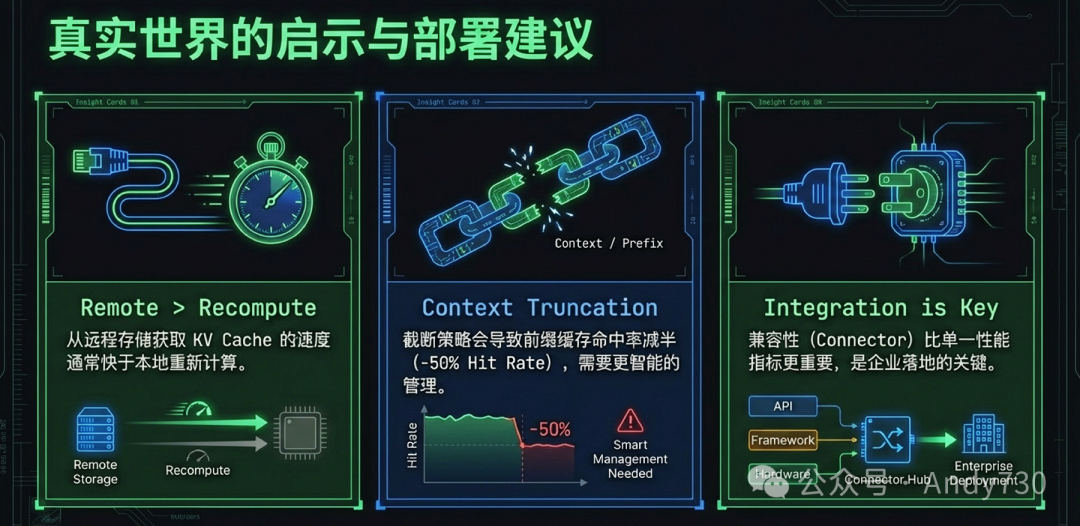
传统的推理引擎(如vLLM和SGLang)通常将KV Cache锁定在本地GPU显存中,导致其无法在不同请求或分布式实例之间高效流转。虽然分布式前缀缓存可以通过网络复用缓存,但在带宽有限(如云端1-10Gbps)的环境下,传输海量张量的延迟往往会超过重新计算的时间。因此,推理系统的优化重心正从单纯的计算加速,转向构建分布式的、解耦式的缓存生态。
协同演进:从算子优化到系统整合
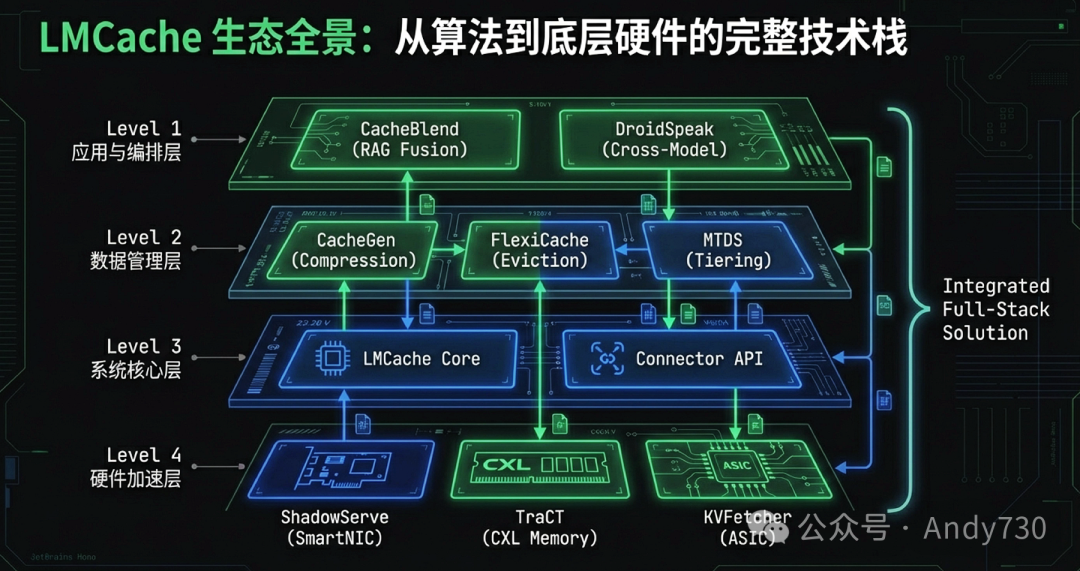
针对上述瓶颈,一系列研究通过算法、逻辑、跨模型共享及底层硬件四个维度,共同构建了LMCache的技术底座:
- 传输与编码层的突破:为了降低网络传输压力,CacheGen首次将KV Cache建模为类似于视频的“张量流”,利用Token间的局部性和层间量化敏感度差异进行压缩。通过Delta编码和自适应量化,该技术能节省高达80%的带宽,而对生成质量的影响可忽略不计。
- 逻辑编排的革新:在检索增强生成(RAG)场景中,输入由乱序的文档块组成,导致传统的前缀缓存失效。CacheBlend通过“选择性重计算”机制解决了这一问题,它基于注意力矩阵的稀疏性,仅需更新约15%的关键Token即可恢复交叉注意力,实现了非连续块的高效融合。
- 语义空间的跨模型共享:DroidSpeak证明了同系列不同规模模型(如Llama-3-8B到70B)在隐藏层特征上具有显著的线性相关性。通过轻量级的线性变换映射,它打破了异构模型间的隔阂,允许不同规模的模型共享同一套前缀缓存。
- 系统架构的解耦管理:LMCache作为整个技术栈的底座,实现了KV Cache生命周期管理与推理引擎的彻底剥离。它建立了基于Token Hash的全局索引协议,并提供标准化连接器(Connector),将缓存存储扩展至CPU、SSD及远程对象存储(如 Redis)等层级介质中。
硬件边界的极致探索
随后的扩展研究进一步压榨了异构硬件的性能上限。ShadowServe将协议栈和解压逻辑完全卸载到智能网卡(SmartNIC),消除了数据平面与模型计算之间的干扰。KVFetcher则巧妙利用GPU内部闲置的NVDEC(视频解码器ASIC)执行解压缩任务,实现了零拷贝写入显存。对于机架级规模,TraCT引入CXL 3.0共享内存特性,通过直接的GPU-CXL DMA绕过传统网络协议栈,实现纳秒级的缓存加载。针对边缘环境,MTDS优化了KV块在HBM、DRAM与SSD之间的动态流动路径。
这些演进表明,KV Cache已经超越了临时计算副产品的地位,正式成为LLM时代的核心数据结构。本文旨在深入剖析这些关键技术,揭示它们如何共同重塑下一代大规模智能推理基础设施。
一、LMCache系统架构:推理引擎的“分布式大脑”
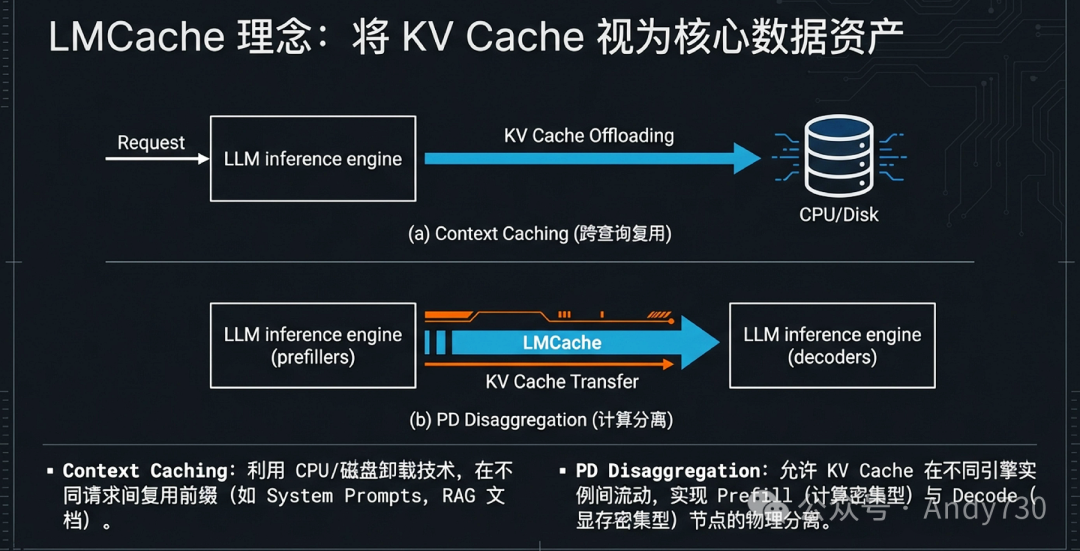
大语言模型推理系统的演进,正在经历从“孤立计算实例”向“分布式存储计算集群”的范式转移。LMCache的核心设计理念在于将KV Cache从推理引擎(如vLLM和SGLang)的内部临时产物,提升为“核心要素”级的数据结构。这一转变要求系统必须具备能够跨越设备边界、兼容多种引擎且具备全局视野的底层架构。
跨越显存瓶颈的层级化存储体系
在传统的推理模式中,KV Cache被严格锁定在单个GPU的显存内,随着请求结束即刻释放。这种模式在处理长文本时面临严峻的显存容量危机。LMCache通过计算与存储的彻底解耦,构建了一个跨越GPU显存、CPU内存、本地磁盘乃至远程分布式后端的层级化存储层。
为了克服小块数据传输带来的带宽利用率不足问题,LMCache引入了可配置块大小(Configurable Chunk Size)技术。系统不再以引擎原生的细粒度页面(通常为16-64KB)为单位进行传输,而是将多个物理页面聚合成更大的数据块(如256个Token组成的Chunk),从而填满PCIe或网络带宽的吞吐上限。
针对不同的硬件环境,这一存储架构表现出极强的适应性:
- 在边缘资源受限场景下,MTDS方案细化了从HBM到SSD的四级数据流动路径,通过感知数据热度动态决定缓存的驻留层级。
- 在机架级数据中心,TraCT则利用CXL 3.0的共享内存特性,构建了跨主机的统一内存池,支持GPU通过直接内存访问(DMA)实现纳秒级的缓存加载,彻底绕过了传统的网络协议栈开销。
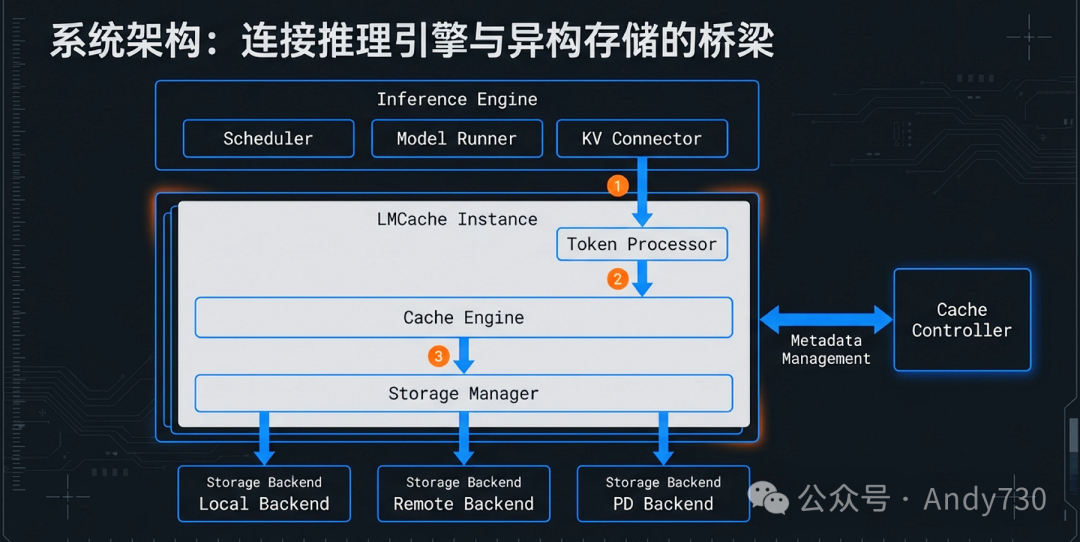
标准化连接器:为快速演进的生态解耦
由于LLM模型架构(如滑动窗口注意力或MLA)和推理引擎更新极快,任何紧耦合的设计都会迅速失效。LMCache设计了一套模块化的标准化连接器(Connector)接口,作为引擎与缓存层之间的“粘合剂”。
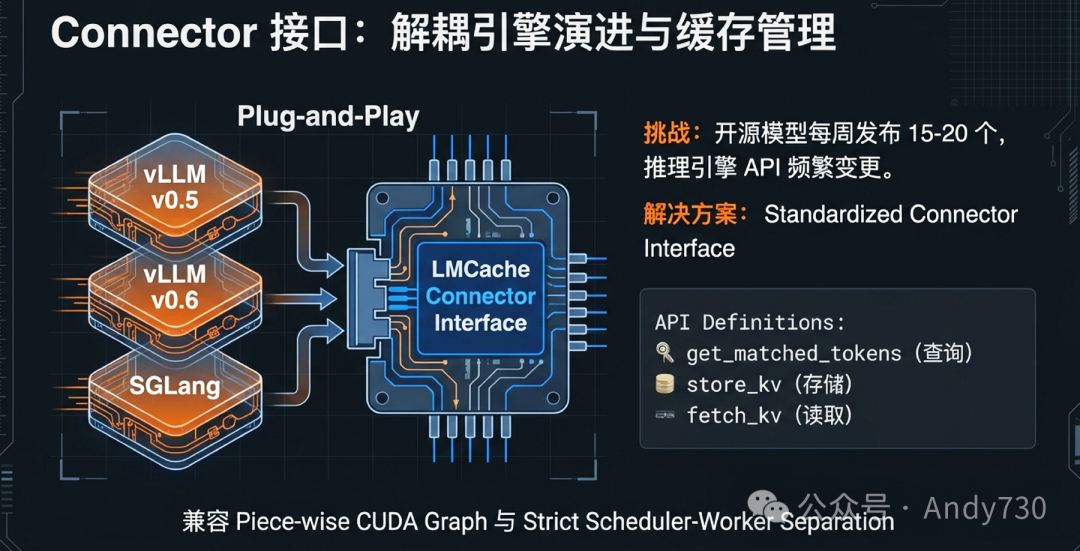
这套接口采用了调度层与执行层分离的哲学:
- 调度侧接口(Scheduler Side):推理引擎的调度器通过
get_num_new_matched_tokens 等函数查询全局缓存状态。如果命中,系统会标记需要从外部加载的物理页面,并提前构建传输元数据。
- 执行侧接口(Model Runner Side):这是一组底层Hook机制。例如,
start_load_kv 在模型执行前启动异步加载流程;wait_load_kv 则在特定Transformer层的计算开始前确保数据已就绪。
这种设计支持层级流水线(Layer-wise Pipelining),即在计算当前层时,系统已经开始在背景中异步拉取下一层的缓存数据。这种计算与I/O的深度重叠最大化了GPU的利用率,将存储加载的延迟有效掩盖在计算任务之下。
全局索引协议:分布式环境下的协作与共享
LMCache不仅仅是单机的加速器,更是一个基于Token Hash协议的分布式缓存管理系统。其核心是一个集中化的控制器(Controller Manager)与分布在各实例中的工作进程(Workers)构成的协同体系。
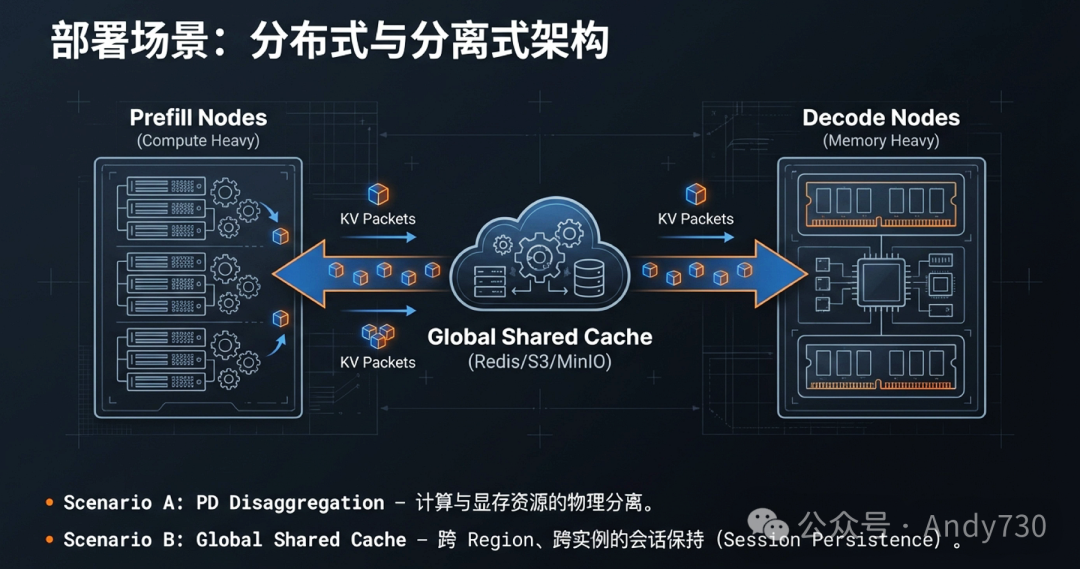
- 全局可见性:控制器维护着整个集群KV Cache状态的实时内存视图。当一个新请求到达路由节点时,调度器可以通过
lookup 接口定位特定Token序列所在的机器位置及存储设备层级。
- 动态迁移与P2P共享:LMCache支持跨节点的P2P缓存获取。当本地缓存未命中时,实例可以发现并从同级节点的CPU内存中快速拉取数据。此外,当实例缩容或负载均衡需要时,通过
move 接口可以实现缓存资产的平滑迁移。
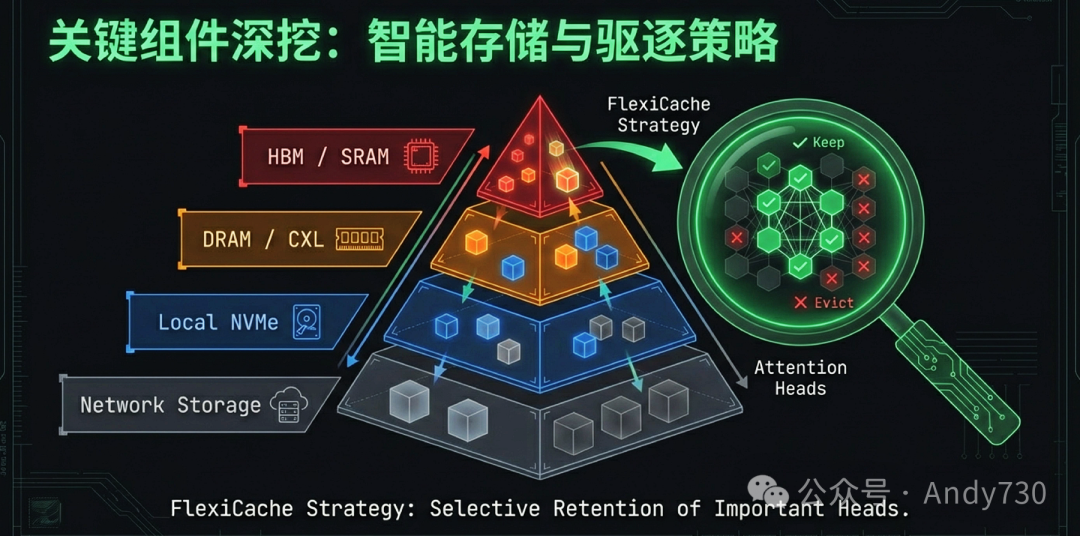
- 感知语义的淘汰机制:系统的“大脑”功能还体现在精细化的管理策略上。例如,配合FlexiCache算法,系统能够感知模型内部不同注意力头的稳定性差异,优先驱逐那些对语义贡献较低的不稳定头数据,从而在显存紧张时依然保持99%以上的模型精度。
通往“感知缓存的计算体系”
LMCache架构的出现标志着一个关键的技术拐点:KV Cache正在从单纯的“加速手段”演变为LLM原生的知识表达形式。
在这一愿景下,推理引擎不再被视为处理孤立Token的工具,而是一套“感知缓存的计算Fabric”。知识以KV Cache的形式被持久化存储在机架级存储池中,计算节点按需调取并缝合这些知识片段。这种从“处理器中心”向“数据中心”的转变,是支撑下一代超长上下文应用、复杂Agent工作流以及兆亿Token级基础设施的必然选择。
二、压缩与传输革命:CacheGen与KVFetcher的协同
在分布式推理架构中,KV Cache的跨节点传输正面临严峻的带宽挑战。在典型的云服务器环境(带宽通常仅为个位数Gbps)中,获取远程KV Cache的网络延迟往往会抵消掉避开重计算所节省的时间,甚至可能导致总延迟超过本地重计算。为了打破这一瓶颈,LMCache技术栈通过CacheGen奠定了张量流建模的算法基础,并利用KVFetcher通过硬件ASIC加速将传输效率推向了极致。
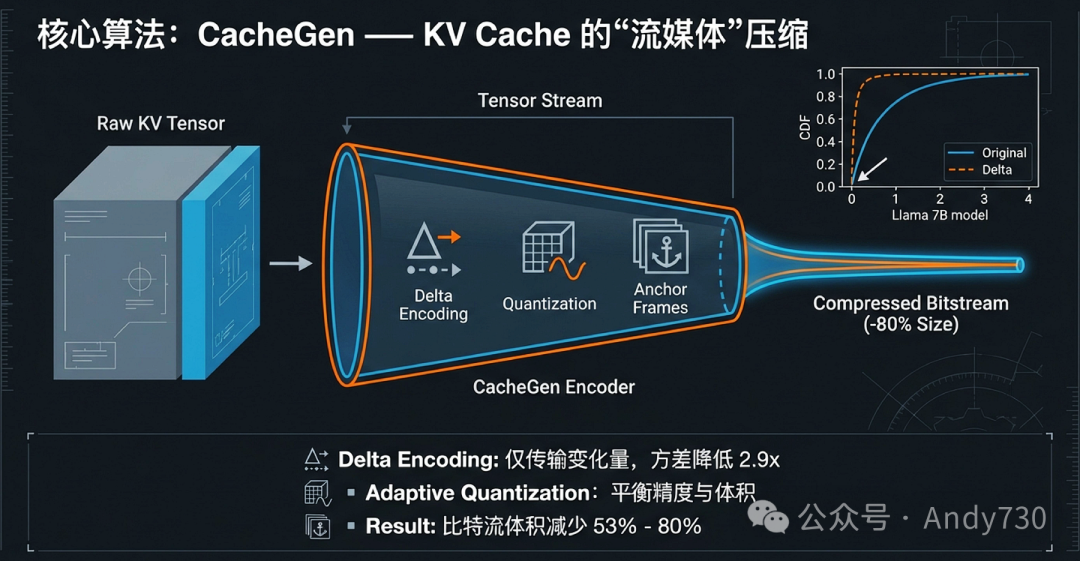
张量流建模:挖掘KV张量的内在规律
CacheGen的核心贡献在于改变了KV Cache的传输范式。它不再将KV Cache视为通用的字节流,而是通过三项深度的统计学洞察,将其建模为类似于视频的“张量流”,从而进行针对性的高压缩编码。
首先,研究发现KV张量在相邻Token之间具有显著的局部性(Locality)。具体而言,相邻Token的残差(Delta)值方差比原始值低2.4到2.9倍。基于此,CacheGen引入了变更编码机制:将Token每10个分为一组,仅对每组首个“锚点(Anchor)”Token进行高精度编码,其余Token则仅记录其相对于锚点的Delta张量。
其次,Transformer模型展现出异构的层损失敏感度。实验证明,模型的前1/3层(浅层)对量化损失极其敏感,因为这些层编码了基础的语义信息;而更深的层由于提取的是高阶抽象特征,对精度损失表现出更强的耐受度。CacheGen借此实施分层量化策略,为浅层分配更多比特,而对深层进行更大幅度的压缩,从而在保证模型精度损失小于2%的前提下,实现了最大化的带宽节省。
最后,针对编码效率,CacheGen发现按“通道-层”组合进行分组的信息增益显著高于按Token维度分组。通过为每个组合维护独立的概率分布,其算术编码器(Arithmetic Coding)能够将比特流体积进一步降低53%。综合这些算法算子,CacheGen在带宽节省上达到了3.5x-4.3x,并将首字延迟(TTFT)缩短了3.2x-3.7x。
硬件加速的跨越:从CUDA干扰到ASIC解放
尽管算法层面实现了极高压缩比,但早期的解压缩方案(如CacheGen原生实现)主要依赖CUDA内核。这在实际生产中引发了严重的资源争抢问题:同时运行解压缩任务与LLM推理会导致两者性能均下降30%以上。此外,CUDA解压过程会导致显存膨胀(Memory Bloat),解码4K Token往往需要预分配数GB的临时缓冲区,是原始KV Cache体积的2.7倍,这极大地限制了推理的Batch Size。
KVFetcher提出了利用GPU内部闲置硬件——视频编解码ASIC(如NVIDIA NVDEC)的方案。这些单元在LLM推理期间通常处于完全空闲状态。KVFetcher将KV Cache重新格式化为视频帧,利用NVDEC进行无干扰解码。
为了实现这一目标,KVFetcher引入了Codec友好型布局,通过将KV张量映射到像素块,充分利用视频编码中的帧间/帧内无损冗余消除能力,而跳过会导致精度损失的离散余弦变换(DCT)步骤。更重要的是,KVFetcher采用了逐帧还原(Frame-wise Restoration)机制:每当一帧视频(包含特定Token的KV片段)完成解码,立即将其映射回显存中的分页内存块。这种精细的流水线设计将解压缓冲区从GB级降至70MB以下,彻底消除了内存压力。
带宽自适应与分块流水线
为了应对波动不定的网络环境,LMCache技术栈采用了一套智能的自适应流处理逻辑。系统将长上下文拆分为多个物理块(如每块256或1.5K Token),使得传输、解码和推理计算能够以流水线方式重叠执行。
在适应策略上,两者各有侧重。CacheGen侧重于量化级自适应:系统根据前一分块的实际吞吐量预测带宽,动态降低编码级别,并在带宽极低时自动回退到发送原始文本,由GPU在本地重新计算,以确保满足服务水平目标(SLO)。
KVFetcher则引入了分辨率自适应机制。在不牺牲计算精度的前提下,它通过调整视频分辨率(如从1080P切换到240P)来精细调节每块传输的数据量。这种方法在处理网络抖动时比固定配置方案节省了约21%的耗时。通过算法压缩与底层硬件ASIC的深度解耦与协同,KV Cache传输已从系统瓶颈转变为LLM分布式基础设施中的高效加速节点。
三、RAG场景下的“缝合”艺术:CacheBlend的选择性重计算
在检索增强生成(RAG)和多代理工作流中,大语言模型的输入通常由多个从数据库检索出的文本块(Chunks)拼接而成。这种场景下,KV Cache的复用面临着比传统单文档续写更复杂的逻辑挑战。CacheBlend的核心价值在于,它解决了如何在不损失精度的前提下,将这些离散、预计算好的“知识块”高效缝合到推理过程中的难题。
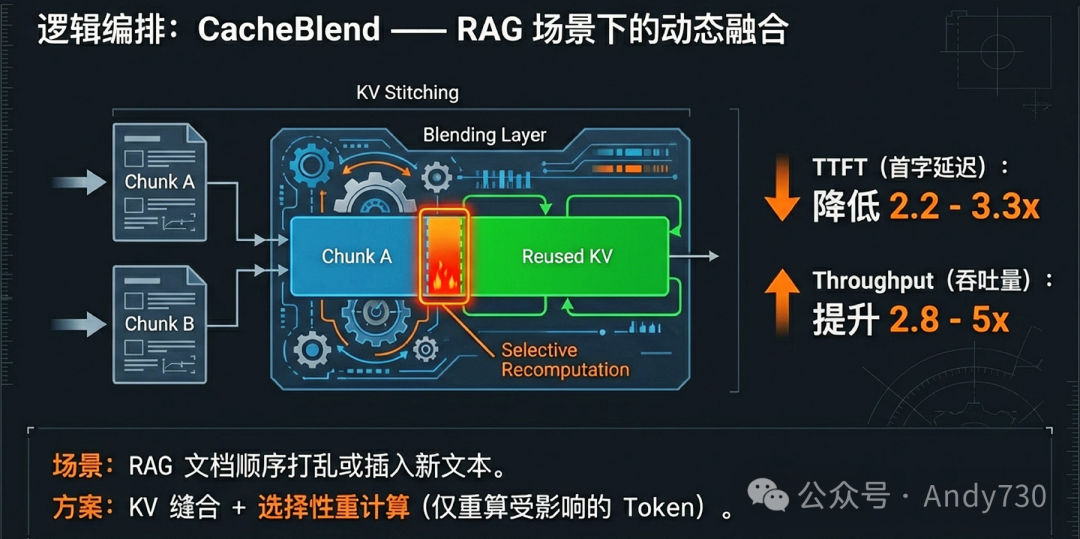
超越前缀匹配:解决RAG中的“交叉注意力缺失”
传统的KV Cache缓存策略(如vLLM和SGLang原生的Prefix Caching)高度依赖前缀匹配。这种方法仅能复用位于输入序列最开端的缓存块。但在RAG场景中,虽然大部分文档块是重复使用的,但检索出的文档顺序会随查询变化而变动。除了第一个块以外,后续所有块都因为其前面的上下文改变而无法直接通过前缀匹配复用,导致系统的首字延迟(TTFT)几乎回退到全量重计算的水平。
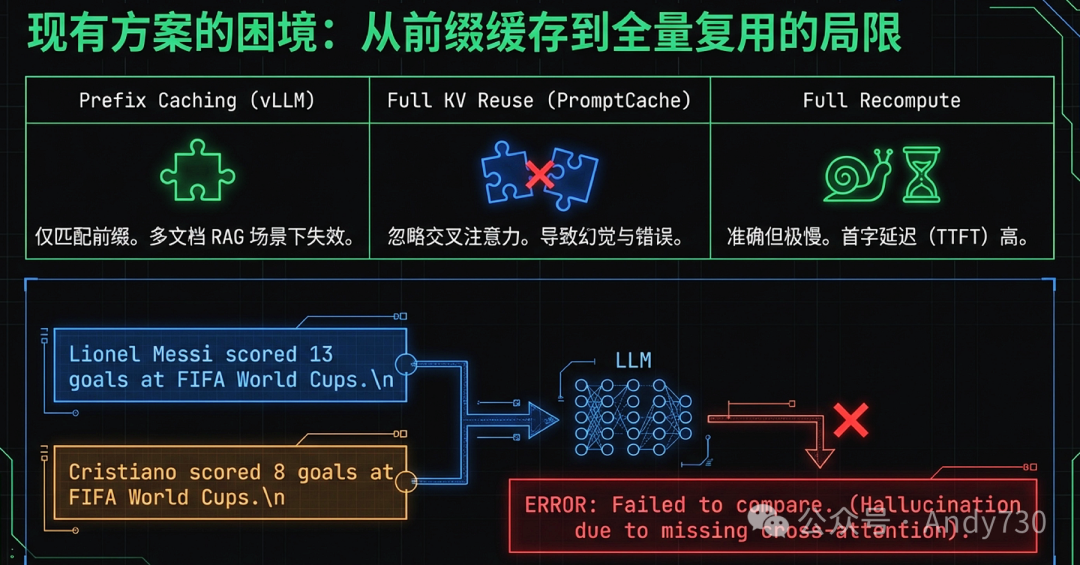
如果采取激进的“全量复用”方案,即直接拼接预计算好的块并调整其位置编码,则会忽略块与块之间的交叉注意力(Cross-attention)。交叉注意力承载了不同文本片段间的语义关联信息。研究表明,忽视这一信息会导致模型无法联合理解多个文档块,从而产生错误的响应。CacheBlend通过一套“缓存融合”机制打破了这一僵局,使其能够复用所有匹配块的缓存,并以极小的代价恢复必要的交叉注意力。
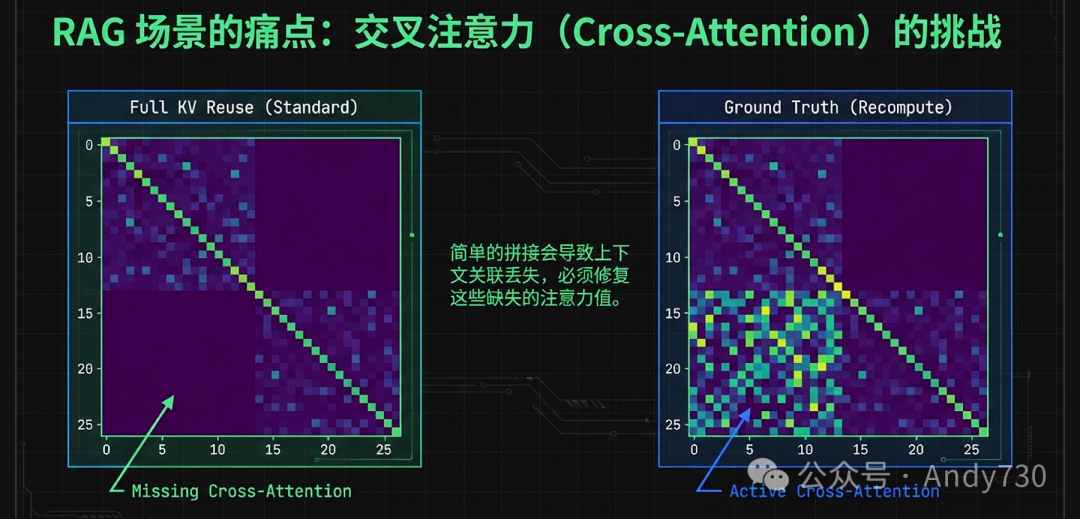
选择性重计算:基于稀疏性的高效缝合逻辑
CacheBlend的核心算子是选择性重计算(Selective Recompute),其理论基础源于Transformer注意力矩阵的高度稀疏性。
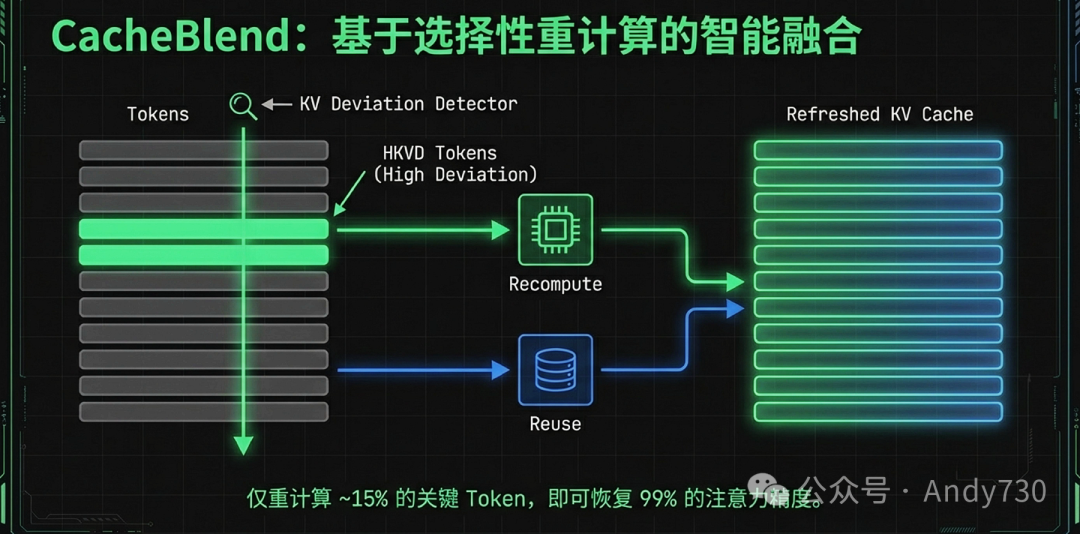
- HKVD令牌的识别:系统定义了KV偏差(KV Deviation),用于衡量复用缓存与全量计算结果之间的绝对差异。那些具有高偏差的Token被称为HKVD(High-KV-Deviation)Token。
- 15%的关键比例:实验证明,在每一层中仅需选择性地更新约10%-20%(通常为15%)的关键Token,即可将注意力偏差降低到极小水平,生成与全量重计算质量几乎一致的响应。这意味着系统可以节省约85%的预填充计算量。
- 逐层过滤算法(Gradual Filtering):为了避免识别HKVD令牌时引入额外的全量计算开销,CacheBlend引入了逐层过滤策略。由于相邻层间的Token偏差具有强相关性,系统会根据前一层的计算结果动态筛选下一层需要重计算的Token。这种方案在LLM通常超过30层的架构中,能显著降低计算负担。
系统架构:计算与I/O的深度掩盖
CacheBlend在系统实现上与LMCache的解耦架构深度融合,通过流水线设计最大化硬件效率。
其核心组件缓存融合器(Fusor)负责在GPU内存中执行选择性更新任务。CacheBlend巧妙地利用了重计算的时间:当系统对第 $i$ 层执行Token更新计算时,会同步从本地磁盘或网络后端加载第 $i+1$ 层的预计算KV Cache。这种层级异步加载机制使得重计算的时间开销往往能被掩盖在I/O延迟之下,实现了“计算近乎免费”的效果。
此外,系统内置的加载控制器(Loading Controller)会根据当前硬件存储介质(如SSD或RAM)的性能和网络带宽,动态计算最适合的重计算比例。如果I/O较慢,它会适当增加重计算比例以利用空闲算力;若I/O极快,则降低比例以追求极致的TTFT。
性能跃升:重塑RAG的用户体验
在多项 RAG 基准测试中,CacheBlend 展现了显著的性能优势:
- 延迟与吞吐:相比全量重计算,CacheBlend将TTFT降低了2.2x-3.3x。在相同的延迟约束下,推理吞吐量提升了2.8x-5x。相比于MapReduce等其他RAG优化方法,其TTFT优势甚至可达2-5倍。
- 精度保持:在多跳问答(2WikiMQA, Musique)和摘要任务中,CacheBlend的得分与昂贵的全量计算相比,下降幅度通常小于0.01-0.03,用户几乎无法察觉到精度损失。
- 并发优势:随着Batch Size增大,预填充阶段的开销愈发显著,此时CacheBlend对系统整体延迟的优化效果会更加突出。
通过这种精密的“缝合”技术,CacheBlend成功将海量、动态检索出的知识以极低成本融入了长文本推理系统,为大规模RAG应用提供了坚实的底座。
四、内存精细化管理:FlexiCache的头稳定性视角
在长文本推理中,KV Cache随序列长度线性膨胀的特性极大地压缩了GPU显存的可用空间,限制了系统的并发处理能力。虽然前缀缓存(Prefix Caching)有效解决了跨请求的复用问题,但在单一请求的生成(Decode)阶段,如何管理庞大的KV Cache依然是一个核心挑战。FlexiCache通过挖掘模型内部注意力头(Attention Head)的稳定性,实现了从“层级”到“头级”的精细化内存管控。

挖掘注意力头的内在规律
传统的KV Cache策略通常基于全局规则对Token进行筛选。然而,FlexiCache提出了一个关键的经验观察:不同注意力头在解码步骤中,其关键页面的选取展现出显著且各异的时间稳定性(Temporal Stability)。
并非所有的注意力头都表现一致。研究发现,模型中约75%的头属于稳定头(Stable Heads),它们在连续的解码步骤中倾向于持续关注相同的Token集合;而剩下的25%则是不稳定头(Unstable Heads),其关注点频繁跳跃。这种稳定性模式被证明是模型固有(Model-intrinsic)的属性,即便在不同任务间切换,不稳定头的重叠率依然高达0.83。由于稳定头对上下文的贡献具有持久性,系统可以据此在显存不足时进行选择性驱逐,优先保留贡献更持久的头数据。
进化的层级化内存模型
基于这种稳定性差异,FlexiCache构建了一套精细的存储策略,将KV Cache管理从“全量驻留”转变为“按需驻留”。
针对占比25%的不稳定头,FlexiCache将其全部页面保留在GPU显存中,以避免频繁传输导致的延迟。而对于75%的稳定头,系统仅在GPU中保留最重要的Top-K页面,将其余页面无损地迁移至主机内存(DRAM)中。
为了在不加载完整数据的情况下实时评估这些离线页面的重要性,FlexiCache引入了MinMax缓存解耦技术。该技术将每个KV块的极值向量驻留在GPU中,充当“雷达”实时扫描,确保当离线页面变得重要时,系统能精准地将其重新从内存“提拔”回显存。
消除I/O墙与系统碎片化
在频繁移动KV Cache的过程中,减少延迟和CPU指令开销至关重要。FlexiCache通过三项关键优化解决了系统层面的性能难题:
- 稳定性感知重排(Stability-aware Reranking):不稳定头每步都进行重排,而稳定头则以较低频率(如每16步)进行。这一策略使稳定头的重排速度提升了2.44倍。
- 脏数据追踪与块复用:针对细粒度管理导致的块表(Block Table)膨胀,系统仅传输发生变更的“脏”段。同时,通过物理块回收技术,直接在GPU侧交换被驱逐和被提拔的块地址,避免了开销昂贵的CPU内存分配器调用。
- 异步I/O流水线:FlexiCache调度器通过暂时挂起执行内存重载的单个请求,同时允许批次中其他请求继续解码,实现了I/O传输与计算的有效重叠。
性能与精度的平衡
FlexiCache的精细化管理在长文本、长生成场景下展现了卓越的效率。对于长上下文请求,该系统能将GPU显存占用降低高达70%。在离线服务中,它提升了1.38x–1.55x的总吞吐量,并将在线服务的每Token生成延迟(TPOT)降低了1.6x–2.1x。
与永久丢弃Token的有损压缩方案不同,FlexiCache始终在内存中保留完整备份。这种设计使其在几乎所有任务中都能保持99%以上的原始模型精度。通过从头稳定性的视角重构内存管理,FlexiCache证明了:对KV Cache的精细管控不应仅停留在时间维度,更应深入到模型结构的语义特性中,使其成为真正可调度、可精简的动态资源。
结语
LMCache技术栈的演进标志着大语言模型推理系统进入了新的阶段。通过算法优化、系统重构与硬件协同的深度整合,该体系证明了即便是面对长达数百万Token的超长上下文,推理系统的效率瓶颈依然可以被有效突破。
在算法层面,CacheGen对KV张量的分布特性进行了深度建模,配合DroidSpeak对异构模型语义相关性的发掘,成功将KV Cache的传输体积缩减了80%以上,并实现了跨模型的动态复用。同时,CacheBlend通过对注意力机制稀疏性的逻辑重构,仅需重计算约15%的关键Token即可恢复完整的交叉注意力,解决了RAG场景下非连续块复用的难题。
在系统架构与硬件压榨上,LMCache实现了计算与存储的完全解耦,将推理引擎从单纯的“处理器”转变为感知缓存的分布式系统。通过标准化连接器,它不仅无缝兼容vLLM和SGLang等主流引擎,还借助于ShadowServe在智能网卡上的协议卸载、KVFetcher对GPU媒体ASIC的利用,以及TraCT基于CXL 3.0构建的机架级内存池,彻底消除了I/O路径上的双向干扰。这些全方位的优化,使得系统在处理长文本任务时,首字延迟显著降低,吞吐量提升高达15倍。
KV Cache的本质:LLM原生的知识表达
从深层技术视角来看,KV Cache不仅仅是推理过程中的瞬时副产品,它本质上是LLM对知识的一种原生表达形式。
这一洞察促使缓存策略从“临时”向“持久”转变。在LMCache的逻辑下,KV Cache成为了一种持久化的数据资产,可以在不同的查询请求、实例节点甚至是不同的模型版本之间流动共享。随着缓存规模迅速增长并远超GPU显存容量,构建从HBM、DRAM到SSD和远程存储的多级动态存储管理体系已成为必然选择。例如FlexiCache基于注意力头稳定性的精细化管理,能够根据头的贡献度动态决定其在不同存储层级的驻留,从而在不损失精度的前提下极大释放了显存压力。
未来愿景:构建“感知缓存的计算Fabric”
展望未来,KV Cache将脱离单纯的“加速工具”范畴,演变为类似于文件系统或数据库的通用数据结构,支撑起下一代LLM基础设施。
在复杂的Agentic工作流中,KV Cache将作为一种标准的通信媒介,在执行不同任务的专用模型之间快速交换推理状态,实现低延迟的多模型协同。随着推理规模向万亿级Token扩展,底层基础设施将演变为一种“感知缓存的计算Fabric”:推理不再被视为独立的孤立会话,而是一个持续的、能够实时调取并融合全集群知识的过程。
LMCache所建立的全局索引协议和标准化API,正在为这种AI原生数据的流转铺平道路。在LLM时代,能够高效管理和流转KV Cache的系统,将在智能基础设施的竞争中占据核心先机。对于希望深入探讨相关技术的开发者,可以在云栈社区持续关注更多前沿架构与实践分享。
 发表于 2026-2-19 00:51:59
|
查看: 265|
回复: 0
发表于 2026-2-19 00:51:59
|
查看: 265|
回复: 0
