没有 KV Cache,大模型推理慢到不可用;有了 KV Cache,上下文一长,显存又被撑爆。围绕这一矛盾,过去三年涌现了三条清晰的优化路线:用 PagedAttention 等系统手段管好内存、用 GQA/MLA 等架构设计从源头压缩缓存量、用驱逐和量化在推理时动态“瘦身”。本文从显存公式讲起,带你走遍这三条路,最后给出直击痛点的工程选型建议。
引言
把一个 128K Token 的长文档塞进 LLaMA-2 70B,显存表针直接打满——80GB 的 A100 就这样被一个请求击穿。同一时期,用原生 HuggingFace 跑推理的团队发现,GPU 利用率徘徊在 30% 以下,吞吐量低得令人沮丧;而切换到 vLLM 之后,同样的硬件,吞吐量提升数倍乃至一个数量级。更戏剧性的是 DeepSeek-V2 的发布:官方报告显示,在同等输出质量下,其推理成本比 LLaMA-2 便宜接近 10 倍。
这三件事的幕后主角,都是同一个东西:KV Cache。
先给出一个精确的定义,以免后文有歧义:
KV Cache = 在自回归解码过程中,缓存每层每个注意力头的 Key 和 Value 向量,避免对历史 Token 重复计算 Attention。
Transformer 解码器每生成一个新 Token,都需要对所有历史 Token 做一次全量 Attention 计算。如果不缓存,第 $T$ 步就要重新计算前 $T-1$ 个 Token 的 K、V——这是 $O(T^2)$ 量级的冗余。KV Cache 把这些向量存下来,让每步解码只需处理当前新 Token 的 K/V 投影,避免对历史 Token 的重复计算。从这个角度看,KV Cache 是让 LLM 推理“可用”的基础设施,不是可选优化,是必选项。
但硬币的另一面同样残酷:缓存是有代价的。以 LLaMA-2 70B 为例(GQA,8 个 KV head),每个 Token 的 KV Cache 占用约 $2 \times 70B \times 2 / 8 / 1024^3 \approx 0.33 MB$(FP16),128K Token 的上下文约需 40 GB——这还没算模型权重本身的 140 GB。显存,就这样被撑爆了。
这是 KV Cache 的核心矛盾:没有它,LLM 慢到无法使用;有了它,上下文一长,显存就被撑爆。
过去三年,围绕这个矛盾出现了三条很不一样的解法,而且每条都拿到了不错的数字:
- 系统层:更聪明地管理内存,而非死板地预分配。vLLM 的 PagedAttention 把 KV Cache 的碎片化问题消灭殆尽,吞吐提升 2–4×;而前缀共享与 Prefill/Decode 解耦等系统设计,则进一步把吞吐和资源利用率往上推。
- 架构层:从模型设计源头压缩 KV Cache。DeepSeek-V2 提出的 MLA(Multi-head Latent Attention)将 KV Cache 的存储量压缩了约 93%(相对于其前代 32-head MHA 架构),代价几乎可以忽略不计。
- 算法层:推理时动态裁剪,丢掉“不重要”的 KV。PyramidKV 只保留全量 KV Cache 的 12%,在长文本基准上性能与全量相当。
接下来的文章会沿着这三条路走一遍:先算清楚 KV Cache 到底占多少显存,然后看系统层怎么管内存、架构层怎么压缩、推理时怎么驱逐和量化、超长上下文怎么卸载到 CPU/磁盘上,最后给一张工程选型指南和对未来趋势的判断。
如果你在部署 LLM 推理服务、设计新模型架构,或者只是想真正搞懂 “为什么 vLLM 这么快”,这篇文章是为你写的。更多深入的系统架构讨论,欢迎关注云栈社区。
一、KV Cache 到底在缓存什么
1.1 为什么不缓存就会爆炸
现代大语言模型的推理遵循自回归(autoregressive)范式:每次只生成一个 Token,将其追加到上下文后,再预测下一个。这个过程看似简单,却在 Transformer 的注意力机制中隐藏着严重的计算冗余。
设当前已生成序列为 $x_{1:t-1}$,第 $t$ 步需要预测第 $t$ 个 Token。Decoder 层的 Self-Attention 计算如下:
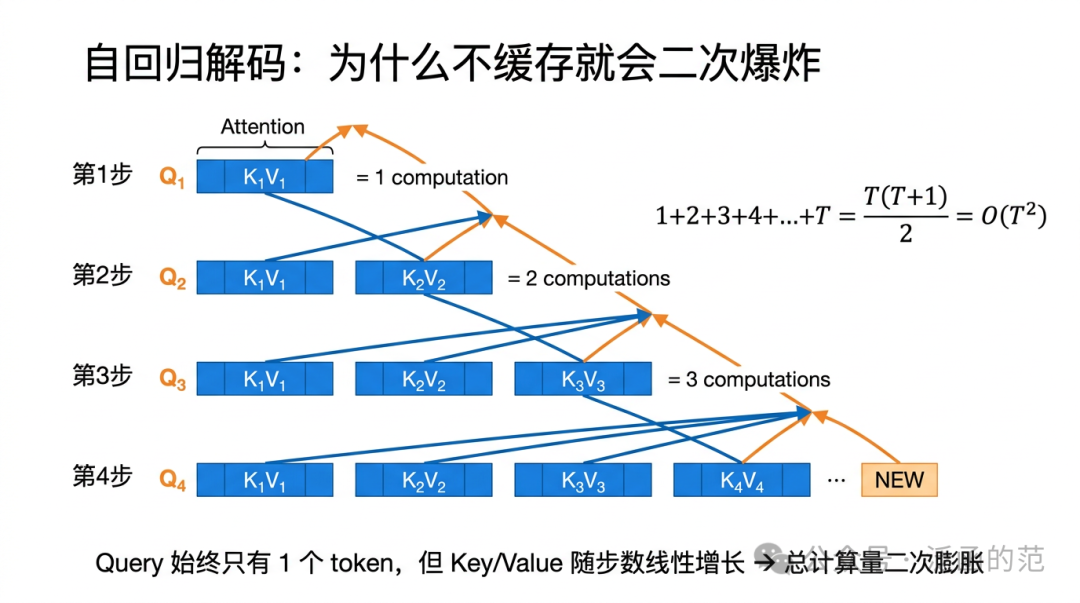
关键点在于:Query 只来自当前新 Token $x_t$,而 Key 和 Value 需要覆盖整个历史序列 $x_{1:t-1}$。这意味着,若不做任何缓存,在生成第 $t$ 步时必须重新对 $x_{1:t-1}$ 的所有 Token 计算一遍 $K$ 和 $V$——而这些 $K, V$ 在第 $t-1$ 步时已经算过了。
如果按最朴素的方式做自回归生成:每生成一个新 Token,都把整个长度为 $t-1$ 的前缀重新跑一遍 forward,那么第 $t$ 步单层 Self-Attention 的计算代价约为 $O(t)$,累计总代价为:
$$1+2+3+...+T = \frac{T(T+1)}{2} = O(T^2)$$
这也是为什么“完全不做缓存”在长上下文下几乎不可用。需要说明的是,若只从
重复计算历史 Token 的 K/V 投影这个角度看,冗余量随生成过程累计为
$O(T^2)$;但从整个解码 forward 的总计算量看,朴素实现的增长更接近
$O(T^3)$。
1.2 把算过的 K、V 存下来
解决上述冗余的思路非常自然:把已经计算过的 K、V 保存下来,下一步直接复用。这就是 KV Cache 的本质。
具体而言,在每一层 Attention 中维护两个缓存张量 $K_{\text{cache}}$ 和 $V_{\text{cache}}$。第 $t$ 步生成时:
- 仅对新 Token $x_t$ 计算 $q_t, k_t, v_t$;
- 将 $k_t$、$v_t$ 追加(append)到缓存:$K_{\text{cache}} = [K_{\text{cache}}, k_t]$, $V_{\text{cache}} = [V_{\text{cache}}, v_t]$;
- 用当前 $q_t$ 与完整缓存 $K_{\text{cache}}$、$V_{\text{cache}}$ 做 Attention。
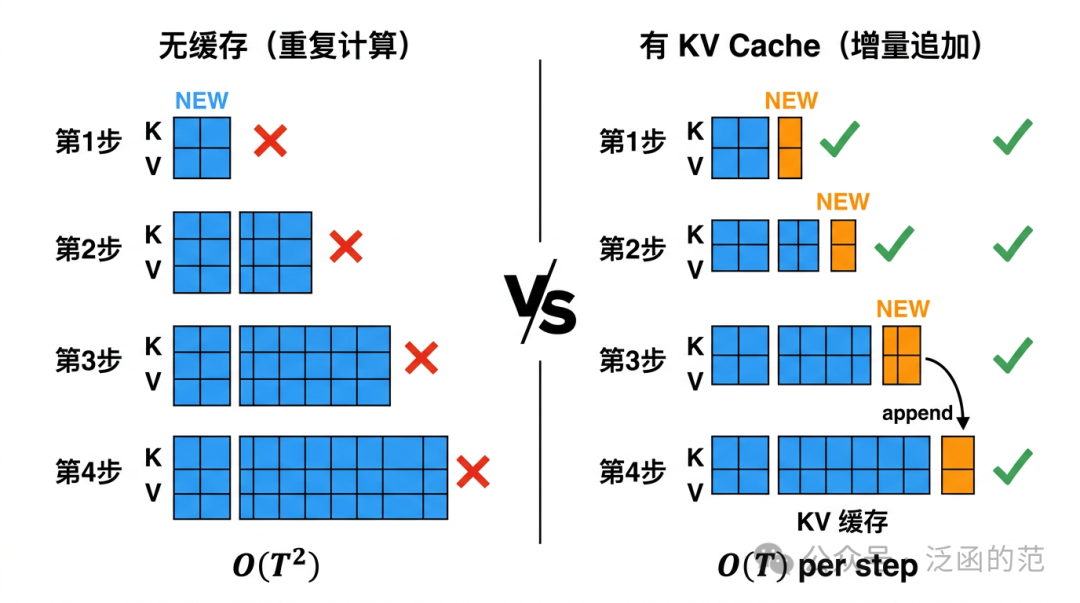
每步只需计算 1 个 Token 的 Q/K/V 投影。需要注意的是,KV Cache 节省的主要是历史 Token 的 K/V 重复投影与整段前缀的重复 forward,而不是把 Attention 点积本身彻底消掉。使用 KV Cache 后,第 $t$ 步仍需让当前 Query 与历史 $t-1$ 个 Token 的 K/V 做一次 Attention,单步主代价仍近似为 $O(t)$,因此生成 $T$ 个 Token 的累计 Attention 访问/计算量仍是 $O(T^2)$。但相比无缓存时反复重跑整段前缀,实际吞吐通常会有数量级上的改善。
代价是内存:缓存的大小随序列长度 线性增长,每新增一个 Token,所有层的 K/V 缓存各增加一行。这一线性代价在长上下文场景下会积累成可观的显存压力,引出下一节的精确计算。
顺便交代一下后文会反复出现的两个术语:LLM 推理分两步走——Prefill 把整段输入一次性吃进去,算出初始 KV Cache,这一步主要吃算力;Decode 则是一个 Token 一个 Token 往外吐,每步都要读一遍已有的全部 KV Cache,主要吃带宽。后面所有的优化,基本都在围着这两步做文章。
常见误区:FlashAttention 和 KV Cache 不是一回事:
- FlashAttention 解决的是 Prefill 阶段 Attention 矩阵 $QK^T$ 的显存爆炸问题,它通过分块计算(Tiling)避免将巨大的 Attention 矩阵物化到显存中;
- KV Cache 解决的是 Decode 阶段自回归生成的重复计算问题。
FlashAttention 并没有消除 KV Cache 的存储需求,两者是正交且互补的。
1.3 算一笔账:KV Cache 到底占多少显存
下面把显存占用的计算拆开,让数字说话。
基本计数
对于单个请求、单层 Attention,KV Cache 存储了 $L$ 个 Token 的 Key 和 Value。若模型使用 $H_{kv}$ 个 KV head,每个 head 的维度为 $d$,则单层、单请求的缓存大小为:
$$\text{Cache}_{\text{per\_layer}} = 2 \times L \times H_{kv} \times d \times \text{bytes\_per\_element}$$
模型共有
$N_{\text{layer}}$ 层,因此完整的 KV Cache 大小为:
$$\text{Cache}_{\text{total}} = N_{\text{layer}} \times \text{Cache}_{\text{per\_layer}}$$
其中 float16 和 bfloat16 均占 2 bytes。
以 LLaMA-2-7B 为例手工验证
LLaMA-2-7B 的参数:$N_{\text{layer}}=32$,$H_{kv}=32$(MHA,KV head 数等于 Q head 数),$d=128$,dtype 为 float16(2 bytes)。
序列长度 $L=32768$(即 32K Tokens):
$$\text{Cache}_{\text{total}} = 32 \times 2 \times 32768 \times 32 \times 128 \times 2 \approx 16 \text{ GB}$$
若将上下文扩展到 128K:
$$\text{Cache}_{\text{total}} \approx 16 \text{ GB} \times 4 = 64 \text{ GB}$$
各主流模型对比
| 模型 |
层数 $N_{\text{layer}}$ |
KV heads $H_{kv}$ |
$d$ |
32K Token |
128K Token |
| LLaMA-2-7B |
32 |
32 (MHA) |
128 |
16 GB |
~64 GB |
| LLaMA-3-8B |
32 |
8 (GQA) |
128 |
4 GB |
~16 GB |
| LLaMA-3-70B |
80 |
8 (GQA) |
128 |
10 GB |
~40 GB |
| DeepSeek-V2 (MLA) |
60 |
$d_c=512, d_R=64$ |
— |
~2.1 GB |
~8.2 GB |
LLaMA-3-8B 采用 GQA(Grouped Query Attention),将 KV head 从 32 缩减到 8,KV Cache 直接降为 LLaMA-2-7B 的 1/4。DeepSeek-V2 使用 MLA(Multi-head Latent Attention),不再缓存完整 K/V,而是缓存低维潜变量 $c_{KV}$($d_c=512$)与解耦的位置 Key($d_R=64$),压缩更为极致(MLA 的公式详见第三章)。
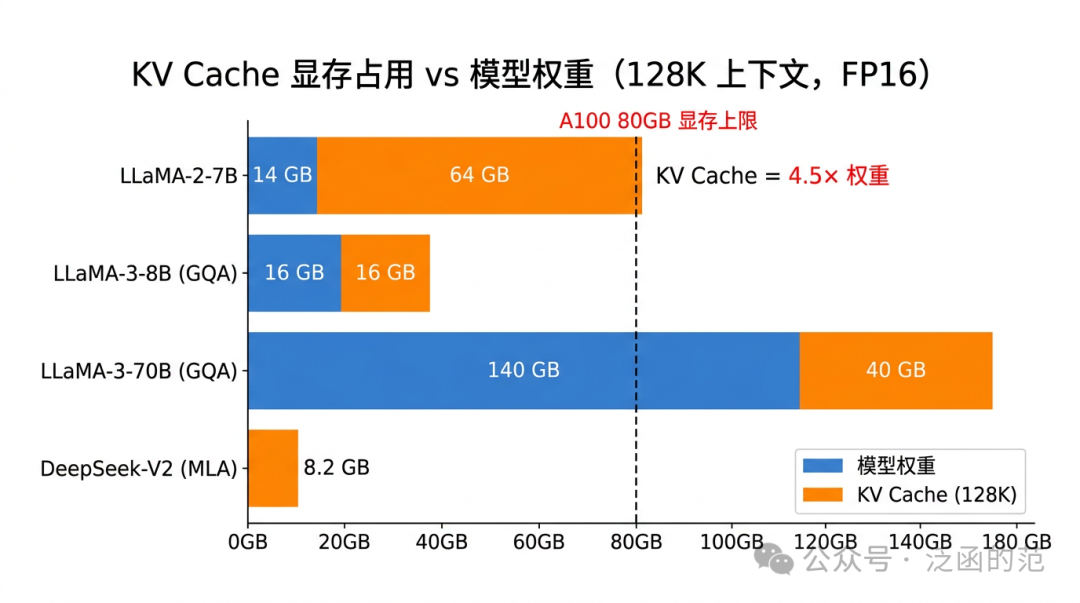
换句话说,128K 上下文时 LLaMA-2-7B 的 KV Cache 约 64 GB,而模型权重才 14 GB——缓存是权重的 4.5 倍。长上下文推理的显存瓶颈根本不在权重,而在缓存。
1.4 三个绕不开的工程难题
KV Cache 用线性内存换取了计算效率,但在工程落地中暴露出三个相互独立又彼此关联的挑战:
| 挑战 |
描述 |
对应解法 |
| 显存不够 |
长上下文 KV Cache 超出 GPU VRAM 上限,单卡无法容纳 |
量化(INT8/INT4 KV)、Token 驱逐、CPU Offloading、架构级压缩(GQA/MLA) |
| 内存碎片 |
不同请求序列长度各异,静态预分配导致严重浪费,动态分配又引入碎片 |
PagedAttention(以固定大小“页”管理 KV Cache,按需分配) |
| 重复缓存 |
多个并发请求共享相同的系统提示(system prompt),却各自独立缓存一份 |
Prefix Caching / RadixAttention(共享前缀的物理内存页) |
三个问题的性质不太一样:显存不够是硬天花板,碎片影响的是吞吐,重复缓存则在 RAG 和多轮对话场景里特别突出。搞清楚这一点之后,后面各章的技术就不会觉得乱了——它们不是在相互竞争,而是各管各的层面。
二、把内存管好:PagedAttention 与前缀缓存
显存够大就万事大吉了吗?并不是。就算塞得下,如果管得不好,照样跑不快。
2.1 预分配连续显存有多浪费
在 vLLM 出现之前,主流推理框架对 KV Cache 按请求最大长度预分配连续显存,带来两类经典浪费:
内部碎片:预分配 4096 Token 空间,实际生成 200 Token 就结束,剩余 3896 Token 的空间浪费。批量服务中碎片率可达 50–80%。
外部碎片:不同长度请求交错分配释放后,留下大量不连续空洞,总空闲显存足够却无法满足新的连续分配请求。
搞过操作系统的人看到这里会会心一笑——这不就是没有虚拟内存时代的老问题吗?vLLM 做的事情,说白了就是把分页机制搬到了 KV Cache 上。
2.2 PagedAttention:像 OS 一样做分页
vLLM 提出了 PagedAttention 机制,将 KV Cache 切分为固定大小的“Block”(默认 16 Token/Block),物理上不要求连续,通过“Block Table”维护逻辑到物理的映射。序列长度 $L$、Block 大小 $B$ 时,请求需 $\lceil L/B \rceil$ 个 Block,按需分配。
逻辑序列(Token 0 到 T-1)
逻辑 Block 0 [Token 0 .. 15] → 物理 Block #42
逻辑 Block 1 [Token 16 .. 31] → 物理 Block #7
逻辑 Block 2 [Token 32 .. 47] → 物理 Block #91
...
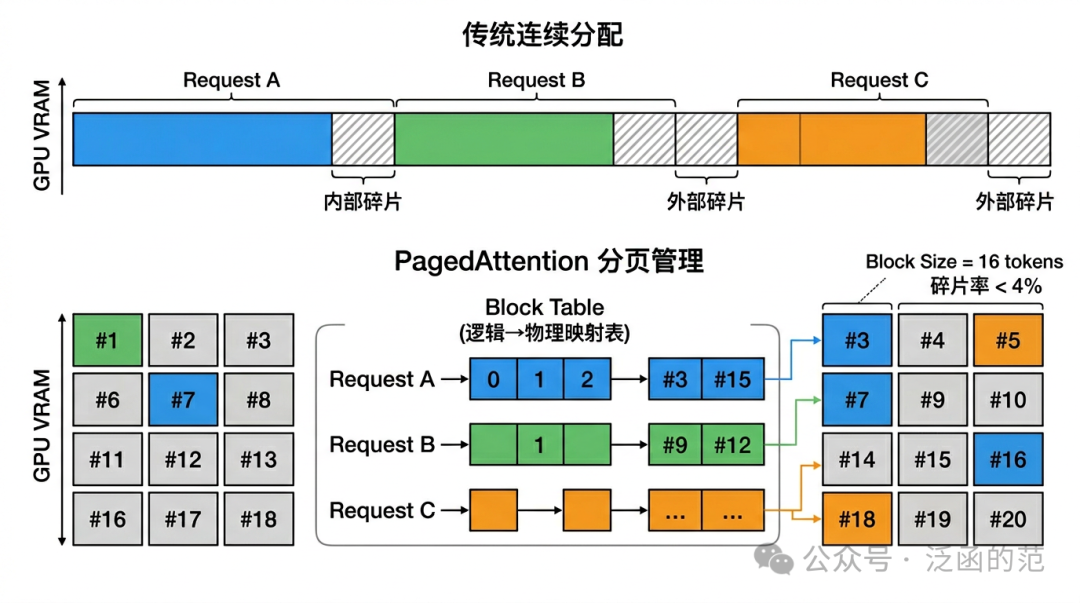
Attention 计算时,GPU kernel 通过 Block Table 查找物理地址,按逻辑顺序拼接 K/V 向量参与计算。从模型角度看,KV Cache 依然是一段连续序列;从内存角度看,物理存储是分散的。
三大优势:
- 近零碎片:内部碎片仅在最后一个 Block($L \mod B \neq 0$ 时平均 <4%),外部碎片因 Block 定长而消除。
- Copy-on-Write 共享:Beam Search 中多个 Beam 通过引用计数共享前缀 Block,写入时才复制,与 OS 的 fork() 语义一致。
- 高吞吐与 Continuous Batching:碎片减少使更多请求可同时驻留 GPU,配合 continuous batching(请求逐个加入/退出 batch,不必等整批完成),有效 batch size 大幅提升。
实测下来,在 A100 上 vLLM 比 FasterTransformer 快 2–4 倍,比 Orca 快 1.7–2.7 倍——注意,这里没有做任何模型层面的改动,纯靠内存管理就拿到了这个数字。
2.3 RadixAttention:别重复算相同的前缀
PagedAttention 管好了单个请求的内存,但还有一种浪费它没管到:一套 AI 客服系统里,每个用户请求都带着同一段 2000 Token 的 System Prompt,每次都要重新 Prefill 一遍。RAG 场景里同一篇文档被翻来覆去引用,也是一样的重复劳动。
SGLang 提出的 RadixAttention 用 Radix Tree 维护全局 KV Cache 池,每条路径对应一段已缓存的 Token 序列。
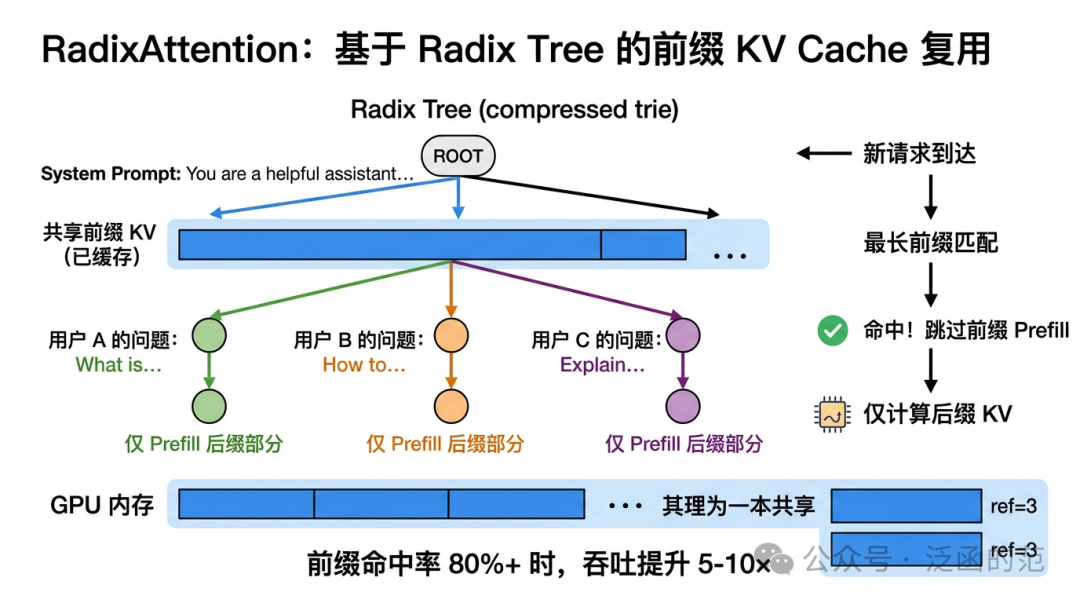
新请求到来时:
- 将请求的 Token 序列在 Radix Tree 中进行最长前缀匹配;
- 匹配命中的前缀部分直接复用已有 KV Cache,跳过这部分 Prefill 计算;
- 仅对未命中的后缀部分执行 Prefill,并将结果追加到树中。
当显存不足时,采用 LRU(Least Recently Used) 策略驱逐最近最少使用的树节点(节点对应的 Token 序列),释放对应的 KV Cache Blocks。
效果很直观:如果 System Prompt 占请求总长的一半,命中就省一半 Prefill。在前缀高度复用、命中率很高的 SaaS/RAG workload 中,SGLang 相比 vLLM 的公开结果可达到 5–10× 的吞吐优势;但这并不是对所有 workload 都成立的普适结论。
2.4 Chunked Prefill 与 FlashDecoding:单机内的极致压榨
在单机或中小集群内,长上下文还会带来两个棘手的微观问题。这里说的两类优化,更多是近两年在 vLLM、TensorRT-LLM 等推理系统中逐渐普及的工程实践;其中 FlashDecoding 则可视为长上下文 Decode 加速的一条代表性技术路线。
- 长 Prefill 饿死 Decode:如果一个长文档请求(如 100K Token)进入系统,它的 Prefill 会长时间霸占 GPU 算力,导致其他正在 Decode 的请求卡顿(长尾延迟)。Chunked Prefill(分块预填充)的解法是将长 Prefill 切分成多个小块(如 512 Token 一块),与 Decode 请求混合组装成 Batch。这样既能保持 GPU 高利用率,又能保证 Decode 的平滑输出。
- 长 Decode 算力闲置:当上下文极长时,Decode 阶段单 Token 算 Attention 会因为并行度不够(只在一个 Sequence 维度上跑)而变慢。FlashDecoding 技术在 Decode 阶段将长 KV Cache 在 Sequence 维度上切分,分配给多个 SM 并行计算最后再 Reduce,从而显著改善长上下文下的 Decode 速度。
2.5 Mooncake:把 Prefill 和 Decode 拆开
规模再大一些——比如 Kimi 那种数十万并发的量级——又会遇到一个更深层的矛盾:Prefill 和 Decode 本质上是两种完全不同的工作负载(前者吃算力,后者吃带宽),硬要混在一批 GPU 上跑,互相打架。
Mooncake 提出了以 KV Cache 为中心的解耦架构:
- Prefill/Decode 集群物理分离:各自使用最适配的 GPU 型号,独立扩展。
- KV Cache 卸载到分布式存储池:Prefill 完成后,KV Cache 通过 RDMA 传输到独立的 DRAM/NVMe 存储池,Decode 集群按需拉取。
- 缓存感知调度:新请求优先路由到前缀 KV 命中率最高的节点,最大化复用。
- 早期拒绝:过载时提前拒绝低优先级请求,避免长尾延迟。
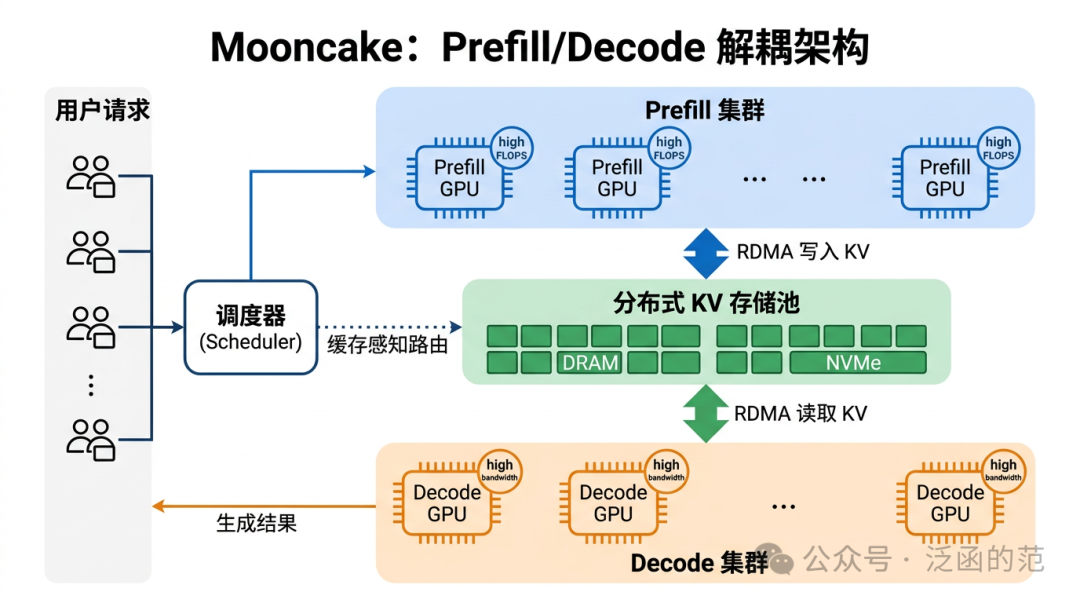
说到底,Mooncake 做的事情是把 KV Cache 从“推理过程的副产物”提升成了“系统架构的中心”。听着有点夸张,但在生产环境里确实如此:调度策略、网络拓扑、存储选型,最终都绕着 KV Cache 转。
到这里,系统层面能做的事情基本讲完了。但不管怎么管理,KV Cache 的总量最终还是由模型架构决定的——要想从根子上减少缓存量,得回到模型设计本身。
三、从模型设计上动刀:MQA、GQA、MLA
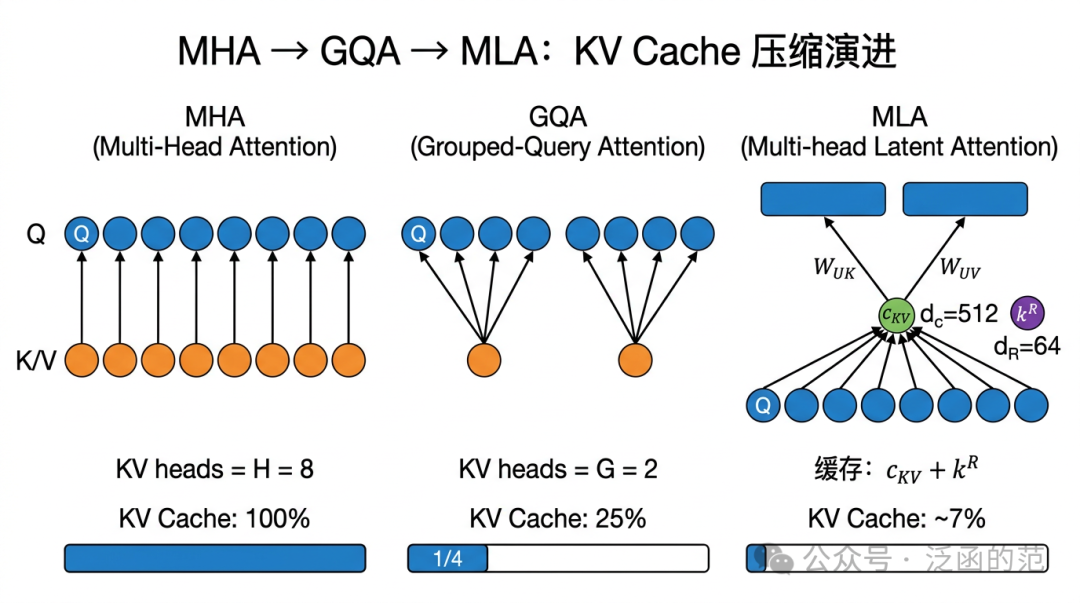
既然 KV Cache 大小正比于 KV head 数和每 head 的维度,那最直接的思路就是:能不能在模型设计阶段,就把需要缓存的东西做少、做小?这条路从 MQA 走到 GQA 再到 MLA,每一步都在试探“共享到什么程度,质量才开始下降”。
3.1 MHA 为什么那么费显存
标准 MHA 中,每个注意力头拥有独立的 K/V 投影矩阵 $W_K, W_V$,推理时每生成一个 Token,所有层所有头的 K/V 向量都要追加缓存:
$$\text{Cache}_{\text{per\_token}} = 2 \times N_{\text{layer}} \times H \times d \times \text{bytes\_per\_element}$$
对于 LLaMA-2-7B($N_{\text{layer}}=32$,$H=32$,$d=128$,float16),每新增一个 Token,KV Cache 增加 $2 \times 32 \times 32 \times 128 \times 2 \approx 0.5 \text{ MB}$,即 0.5 MB/Token。32K Token 时总计约 16 GB,与模型权重本身(~14 GB)相当。
这里有一个关键洞察:KV Cache 的大小取决于 KV head 数 $H_{kv}$,但模型的表达能力主要取决于 Q head 数。两者并不需要相等。如果能只砍 KV head 而保留 Q head,缓存就小了,质量却不一定降。
3.2 MQA:32 个 Q head 共用 1 组 K/V
MQA 思路直接:所有 Query head 共享同一组 K/V。
KV head 数量从 $H$ 降至 1,KV Cache 压缩比为 $1/H$。对于 32 头模型,压缩比约 32x,KV Cache 理论上减少 96.9%。
问题显而易见:一组 K/V 要同时伺候 32 个 Q head,压力太大了。实际跑下来,MQA 在长上下文和多步推理上质量掉得明显,训练也不太稳定。PaLM、Falcon 当年用它主要是算力紧张时的妥协,GQA 出来之后基本没人再选 MQA 了。
3.3 GQA:分组共享,目前的主流选择
GQA 在 MHA 和 MQA 之间取得折中:将 $H$ 个 Q head 分为 $G$ 组,每组共享一组 K/V。
KV head 数量从 $H$ 降至 $G$,KV Cache 压缩比为 $G/H$。常用配置:
| 配置 |
Q heads |
KV heads |
KV Cache 比 MHA |
代表模型 |
| GQA-8 |
32 |
8 |
25% |
LLaMA-3-8B/70B, Qwen2 |
| GQA-4 |
32 |
4 |
12.5% |
Mistral-7B |
| GQA-1 (= MQA) |
32 |
1 |
3.1% |
— |
注意 $G=1$ 退化为 MQA,$G=H$ 退化为 MHA,$G$ 是一个连续可调的超参数。
“升训”(Uptrain)技巧:将每 $H/G$ 个 KV head 的权重取平均合并,再少量微调(约 5% 原始训练量)即可从 MHA 转换为 GQA,无需从头训练。
目前 LLaMA-3、Gemma、Mistral、Qwen2 等主流模型均已采用 GQA。以 LLaMA-3-8B(8 KV heads)为例,32K 的 KV Cache 约 4 GB,比 LLaMA-2-7B(MHA,~16 GB)减少 4 倍。
3.4 MLA:DeepSeek 怎么做到 93% 压缩的
GQA 减少了 KV head 数,但每个 head 仍保有完整 $d$ 维。DeepSeek-V2 提出 MLA,更激进地对 K/V 联合低秩压缩,推理时只存储压缩后的潜在变量。
对输入 $x$,通过下投影矩阵 $W_{DKV}$($d \times (d_c + d_R)$)得到联合压缩表示:
$$[c_{KV}, k^R] = x W_{DKV}$$
然后通过上投影矩阵还原 K/V:
$$K = c_{KV} W_{UK}, \quad V = c_{KV} W_{UV}$$
其中
$d_c=512, d_R=64$(DeepSeek-V2 配置),而
$d=4096$。由于
$c_{KV}$ 同时承载 K 和 V 的全部信息,等效压缩比约为
$2d / (d_c + d_R) \approx 14\times$。
到了推理阶段,因为 $W_{UK}, W_{UV}$ 是固定参数,所以根本不需要存完整的 K 和 V——只存 $c_{KV}$ 和一个额外的位置 Key 向量 $k^R$($d_R=64$,下面会讲),用的时候再还原就行。KV Cache 实际存储量变成了:
$$\text{Cache}_{\text{per\_token}} = N_{\text{layer}} \times (d_c + d_R) \times \text{bytes\_per\_element}$$
注意此处没有传统公式中的“
$2 \times H_{kv}$”因子,因为
$c_{KV}$ 是 K 和 V 的联合压缩表示,只需存储一份。对 DeepSeek-V2(
$N_{\text{layer}}=60$,
$d_c=512$,
$d_R=64$)而言,每 Token 每层仅需缓存 576 个元素,相比其前代 DeepSeek-67B(32 个 KV head,每 Token 每层
$2 \times 32 \times 128 = 8192$ 个元素)压缩约 93%。
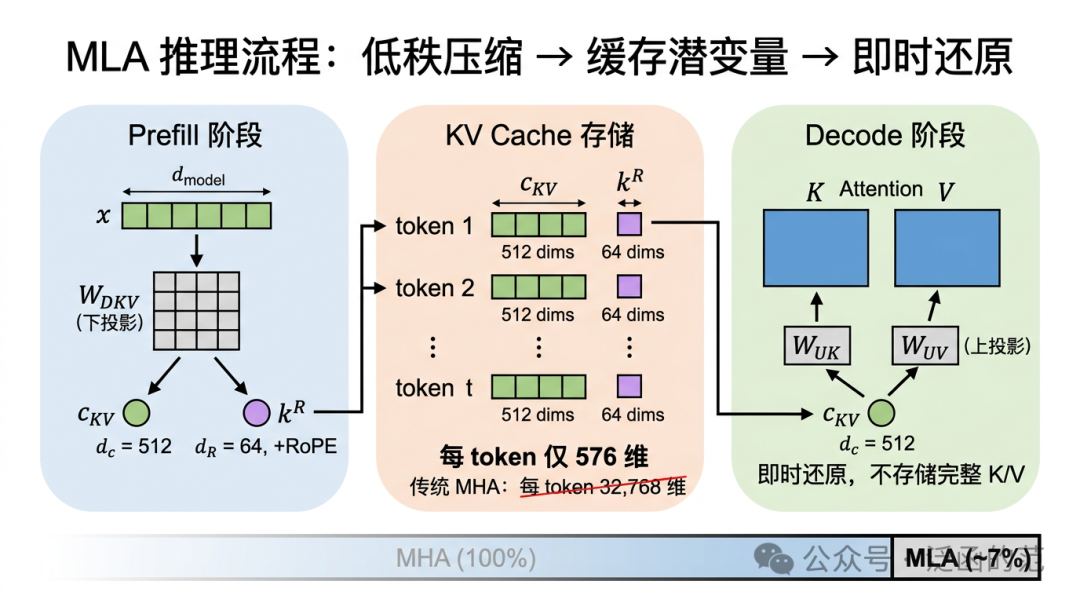
还有一个细节值得说一下:直接对 $c_{KV}$ 施加 RoPE 会破坏低秩结构(旋转是位置相关的,使 $c_{KV}$ 无法共享 $W_{UK}$)。MLA 的做法是把位置编码和内容解耦——单独维护一个位置 Key $k^R$($d_R=64$),只在它上面施加 RoPE,和内容 Key 拼接后一起参与 Attention。这样 $c_{KV}$ 本身不含位置信息,上投影矩阵可以正常还原。
三个方案放在一起比较:
| 指标 |
MHA(参照) |
GQA-8 |
MLA |
| KV Cache 大小(相对 MHA) |
100% |
25% |
~7%(vs 32-head MHA) |
| 模型质量 |
基准 |
接近 MHA |
公开实证中表现很强,部分对比优于对应基线 |
| 是否需要重训 |
— |
可升训 |
必须从头训练 |
更谨慎地说,MLA 至少已经证明了一点:把 KV Cache 压得很小,并不必然意味着质量下降。在 DeepSeek 系列的公开结果里,MLA 没有表现出明显的能力折损,甚至在部分对比中优于对应基线。至于这部分收益究竟有多少应归因于 MLA 本身、多少来自训练数据、MoE 结构和训练 recipe,严格说还不能简单下定论;但 MLA 确实是 DeepSeek 低推理成本的重要组成部分。
3.5 CLA:相邻层能不能共用 KV
CLA 从层间共享这一正交维度入手。核心发现:相邻层的 KV 表示高度相似(余弦相似度 >0.9),因此可以每隔 $s$ 层共享一组 KV Cache。步长为 2 时,KV Cache 直接减少 50%。
更重要的是,CLA 与 GQA 是正交可叠加的。两者可以同时使用:
$$\text{Cache}_{\text{GQA+CLA}} \approx \frac{G}{H} \times \frac{1}{s} \times \text{Cache}_{\text{MHA}}$$
相比标准 MHA,组合方案 GQA+CLA 将 KV Cache 压缩约 8 倍,性能损失有限(实验显示困惑度上升 < 2%)。
3.6 放在一起比较
| 方案 |
KV Cache(相对 MHA) |
是否需要从头训练 |
质量影响 |
代表模型 |
| MHA(基准) |
100% |
— |
基准 |
GPT-2/3、早期 Decoder-only LLM |
| MQA |
~3%(H=32) |
是 |
明显下降 |
PaLM、Falcon |
| GQA-8 |
~25% |
可升训(5% 成本) |
接近 MHA |
LLaMA-3、Qwen2、Gemma |
| MLA |
~7%(vs 32-head MHA) |
必须从头训练 |
表现很强,部分对比优于对应基线 |
DeepSeek-V2/V3/R1 |
| CLA(步长 2) |
~50% |
是 |
轻微损失 |
研究阶段 |
| GQA-8 + CLA |
~12.5% |
是 |
有限损失 |
未来方向 |
一句话总结:压缩越狠,训练成本越高。手上有现成模型想提速的,GQA 升训最务实;有预算从头练旗舰模型的,MLA 是目前最激进、也最有代表性的路线之一;想在 GQA 基础上再挤一点的,CLA 是个不错的加法项。
架构层面做完了“治本”的工作,但并不是所有场景都能换模型。如果模型已经定了,上下文又很长,还有没有别的办法?有——在推理过程中,把那些“不重要”的 KV 条目剪掉。
四、推理时扔掉“不重要”的 KV
Token 驱逐的思路很朴素:既然 Attention 分布是高度不均匀的(Top-20% 的 Token 往往吃掉 80% 以上的权重),那些长期没人搭理的 Token,占着显存也是浪费。
4.1 为什么能扔:Attention 本来就很稀疏
研究者归纳出两类必须保留的 Token:
Heavy Hitters:持续累积高 Attention Score 的 Token(语义核心词、关键实体等),在层间和步间都具有高稳定性。
Attention Sink:序列开头 1–4 个 Token(如 <BOS>),在所有层所有步都获得异常高分。这与语义无关,是 Softmax 归一化的结果——模型将“剩余”注意力倾泻到始终可见的 Sink Token 上。移除 Sink Token 会导致模型崩溃。
两类发现催生了几条相近但并不完全相同的路线:在线累计分数驱逐(H₂O)、基于 Query 感知的一次性压缩(SnapKV、PyramidKV 等),以及基于 Sink 的流式推理(StreamingLLM)。它们都在回答“哪些 KV 值得保留”,但判据和时机并不一样。
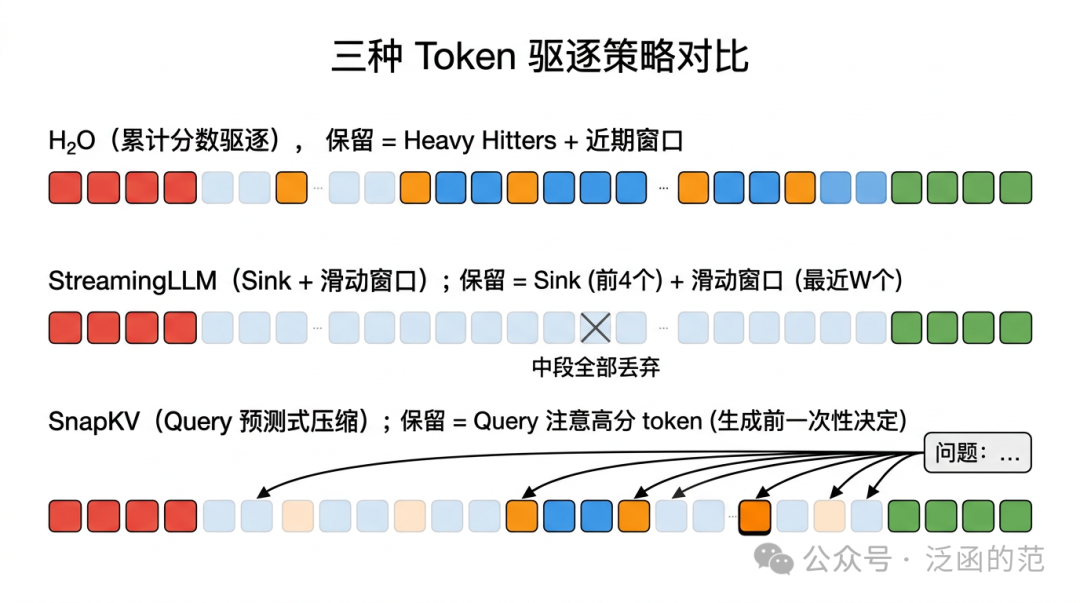
4.2 H₂O:按累计分数淘汰
H₂O 维护每个 Token 的累计 Attention Score,超出预算时驱逐低分 Token,保留:
- Heavy Hitters(历史高分 Token):累计分数 Top-$k$ 的 Token;
- 近期 Token(Recent Window):最后 $w$ 个 Token,保留短程局部 Attention。
实测下来,只保留 20% 的 KV 就能在多个基准上接近全量性能。不过 H2O 有个先天缺陷:它是边生成边驱逐的,Token 一旦被踢掉就回不来了。另外,累计分数天然偏向“老资格” Token,如果后面突然出现一个重要的新 Token,它可能还没积累够分数就被淘汰了。
4.3 StreamingLLM:只留开头和最近,中间全扔
StreamingLLM 解决无限长度流式推理问题。核心发现:移除序列开头 1–4 个 Token 的 KV 会导致困惑度骤升至 $10^3$ 以上——这些 Sink Token 是 Softmax 归一化的“排水口”,模型在训练中强化了对其的依赖。
策略:
完全丢弃序列中段的所有 KV,仅保留 4 个 Sink Token 和最近 $W$ 个 Token(通常 $W$ = 1024 或 4096)的 KV Cache,总 KV 预算固定为 $4+W$,与序列总长度无关。
实验中 StreamingLLM 跑过 400 万 Token 的流式推理,困惑度一直很稳定,而且不需要任何微调。但代价也很明确:中段历史全没了。你让它“回忆一下半小时前聊了什么”,它做不到。所以这个方案天然适合实时对话、同声翻译这类“只关心最近内容”的场景,拿来做长文档 QA 就不行了。
4.4 SnapKV:先看问题再决定留谁
SnapKV 提出生成前一次性完成 KV 压缩:Prefill 完成后,问题 Token 对上下文的注意力模式已隐含“哪些 Token 与回答最相关”的信息。SnapKV 取 Prefill 末尾 $n$ 个 Token 作为“观察窗口”,计算其对历史 Token 的 Attention Score:
$$S_j = \max_{i \in \text{window}} \text{Attention}(q_i, k_j)$$
高分 Token 经聚类合并后保留,避免相邻相似 Token 重复计入预算。在 LongBench 上用同样的 KV 预算,SnapKV 明显优于 H₂O——毕竟“先看问题再决定保留谁”,比“按历史分数一刀切”要靠谱得多。
4.5 PyramidKV:底层多留,高层多砍
PyramidKV 发现:底层 Attention 分布均匀(需大预算),高层 Attention 高度集中(Top-5% Token 承接 >90% 权重,可大幅裁剪)。据此设计层级自适应预算:
$$\text{Budget}_l = \alpha \cdot \text{Budget}_{\text{total}} \cdot (1 - \frac{l}{N_{\text{layer}}})^\gamma$$
结果是只用 12% 的 KV 预算(约 8 倍压缩),LongBench 平均性能就能和全量持平,比给每一层分同样预算的策略好不少。
4.6 RazorAttention:检索头保留,局部头裁剪
RazorAttention 从 Head 功能分化角度切入:约 30% 的 head 负责长程检索(检索头),约 70% 仅关注局部(非检索头)。
RazorAttention 策略:
- 检索头:保留完整 KV Cache。
- 非检索头:仅保留最近 $W$ 个 Token + 少量“补偿 Token”的 KV Cache。
“补偿 Token”是从完整上下文中选出的少量代表性 Token,防止语义漂移。检索头怎么找?在少量校准数据上跑一遍 Attention 分析就行,一次性的开销,不影响线上性能。工程上也比较友好——不改 Attention 的数值逻辑,和 FlashAttention 完全兼容。
4.7 五种方法放在一起看
| 方法 |
驱逐时机 |
重要性判据 |
压缩率 |
优势场景 |
局限 |
| H₂O |
实时(每生成步) |
累计 Attention Score |
5–10x |
通用 NLP 任务 |
被驱逐 Token 不可恢复 |
| StreamingLLM |
实时(滑动) |
位置(Sink + 近期) |
无限 |
无限流式对话 |
无法回溯中段历史 |
| SnapKV |
生成前(一次性) |
Query 预测性分数 |
5–10x |
长文档 QA |
需要完整 query 信息 |
| PyramidKV |
生成前(一次性) |
层级感知预算 |
~8x |
长上下文通用任务 |
层间预算分配需调参 |
| RazorAttention |
生成前(一次性) |
Head 功能类型 |
3–5x |
工程集成友好 |
需离线识别检索头 |
需要强调一点:所有驱逐方法都不是无损的。在合同审查、代码全局理解这类需要精确检索的任务上,驱逐掉的 Token 可能恰好包含关键信息。benchmark 平均分好看不代表你的业务场景也好用——上线前一定要在自己的任务上测一遍。
五、用更少的 bit 存 KV
驱逐是“少存几条”,量化则是“每条存少几个 bit”——两者思路互补,可以叠加使用。不过别以为权重量化的经验可以直接搬过来,KV Cache 的统计特性和权重有本质区别。
5.1 fp16 → int4 → int2,能省多少
标准推理使用 float16 或 bfloat16 格式(均为 2 字节/元素)。若将 KV Cache 量化为更低精度:
| 精度 |
字节/元素 |
相对 float16 压缩比 |
| float16 / bfloat16 |
2 bytes |
1x(基准) |
| int8 |
1 byte |
2x |
| int4 |
0.5 bytes |
4x |
| int2 |
0.25 bytes |
8x |
以 LLaMA-2-7B 为例,在 128K Token 上下文下其 KV Cache 约 64 GB,int8 量化可降至约 32 GB,int4 量化降至约 16 GB——使原本需要多卡 A100 才能容纳的缓存,压缩至单卡可承载的范围。
而且量化的好处不止省显存——Decode 阶段往往是典型的 Memory-bandwidth bound(访存瓶颈),每步都要读一遍全部 KV Cache。将 fp16 压成 int4,意味着每步 Decode 从 HBM 读取的数据量理论上可减少 75%,这不仅是“装得下”的问题,也为显著提升 Decode 吞吐创造了条件。实际能提升多少,还取决于反量化开销、kernel 融合程度,以及系统是否真的被 KV 读取带宽主导。
5.2 Key 和 Value 为什么不能用同一种量化方式
Key 和 Value 的统计特性截然不同,不能简单套用权重量化方法:
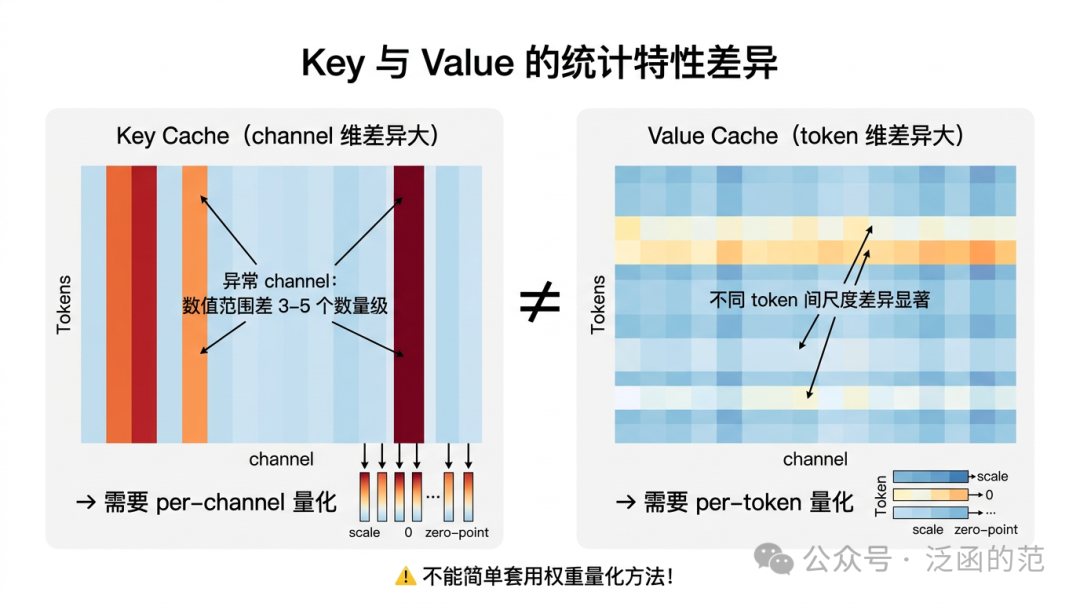
- Key Cache:channel 维分布差异极大(不同 channel 数值范围可差 3–5 个数量级),需 per-channel 量化。
- Value Cache:channel 维相对均匀,但不同 Token 间尺度差异显著,需 per-token 量化。
- RoPE 的影响:RoPE 对 Key 施加位置相关旋转($R_{\theta}$),若在 RoPE 后量化,per-channel 参数会随位置变化。解决方案是 pre-RoPE 量化:在旋转前量化 K,计算时先反量化再施加 RoPE,避免位置扰动叠加量化误差。
5.3 KIVI:K 按 channel 量化,V 按 token 量化
KIVI 根据 K/V 统计差异采用非对称策略:
- Key:2-bit per-channel 量化;Value:2-bit per-token 量化
- 近期 Token 缓冲区:最近 $B$(64–128)个 Token 保持 float16 全精度——近期 K/V 被高权重频繁访问,量化误差直接累积到输出;旧 Token 影响被注意力权重稀释,容忍更大误差。
在 Llama-2、Mistral 上实测,2-bit KV 量化的性能和 float16 基本没差别,显存省了约 2.6 倍,batch size 能多跑 4 倍。
5.4 KVQuant:四种技巧组合压到 3-bit 以下
KVQuant 面向更极端压缩(~3-bit),系统性组合四种技术:pre-RoPE 量化(避免位置扰动)、非均匀量化(NF4 等,匹配接近高斯的激活分布)、per-channel 缩放、outlier 提取(单独以 fp16 存储极端值,通常 <1%)。在单 A100 上实现约 100 万 Token 推理,8-GPU 扩展至 1000 万 Token。
实际效果:2.35-bit 等效精度下困惑度只比 fp16 高了 0.1–0.2。做个对比——LLaMA-2-7B 跑 100 万 Token 上下文,fp16 的 KV Cache 要 512 GB(得 7 块 A100 的显存),KVQuant 直接压进一块卡里。
5.5 ZipCache:重要 Token 存高精度,其余存低精度
ZipCache 将量化精度与 Token 重要性联合优化:显著 Token 保持 float16,非显著 Token 降低精度甚至驱逐。
显著性分数同时用于两个决策:是否驱逐和使用何种量化精度。相比单独使用驱逐或固定精度量化,联合优化在同等压缩比下精度保持更好。
5.6 MiniCache:相邻层的 KV 合着存
MiniCache 从深度维度(跨层)入手压缩 KV Cache。这里的核心发现与第三章提到的 CLA 架构不谋而合,再次证明了“跨层冗余”是 LLM 的普遍特性。只不过 CLA 需要从头训练模型,而 MiniCache 将其做成了无需重训的推理期优化:通过层间重参数化将相邻层的 KV Cache 合并存储,在不改变单层量化精度的前提下额外获得约 2x 的压缩。该方法与 KIVI、KVQuant 等逐层量化方案正交可叠加。
5.7 四种量化方案对比
| 方法 |
有效压缩比特 |
Key 量化粒度 |
Value 量化粒度 |
特殊处理 |
需要微调 |
会议 |
| KIVI |
2-bit |
per-channel |
per-token |
近期 Token 保 fp16 |
否 |
ICML 2024 |
| KVQuant |
~3-bit |
per-channel + outlier 提取 |
非均匀 |
pre-RoPE 量化 |
否 |
NeurIPS 2024 |
| ZipCache |
混合(fp16/int4) |
按显著性 |
按显著性 |
量化+驱逐联合 |
否 |
NeurIPS 2024 |
| MiniCache |
深度维度合并 |
跨层合并 |
跨层合并 |
层间重参数化 |
否 |
NeurIPS 2024 |
这些量化方案有一个共同的实用优点:不需要微调,拿来就能用。不过也别太激进——数学推理和代码生成这类对注意力精度敏感的任务,2-bit 以下可能会掉 1–5 个点。具体能接受多少损失,还是得在你自己的任务上跑一把。
六、GPU 装不下?往 CPU 和磁盘上搬
量化和驱逐都是在 GPU 显存内部“做减法”。如果减完了还是装不下呢?那就只能往外搬了——把 KV Cache 从 GPU 卸到 CPU 内存甚至磁盘上。
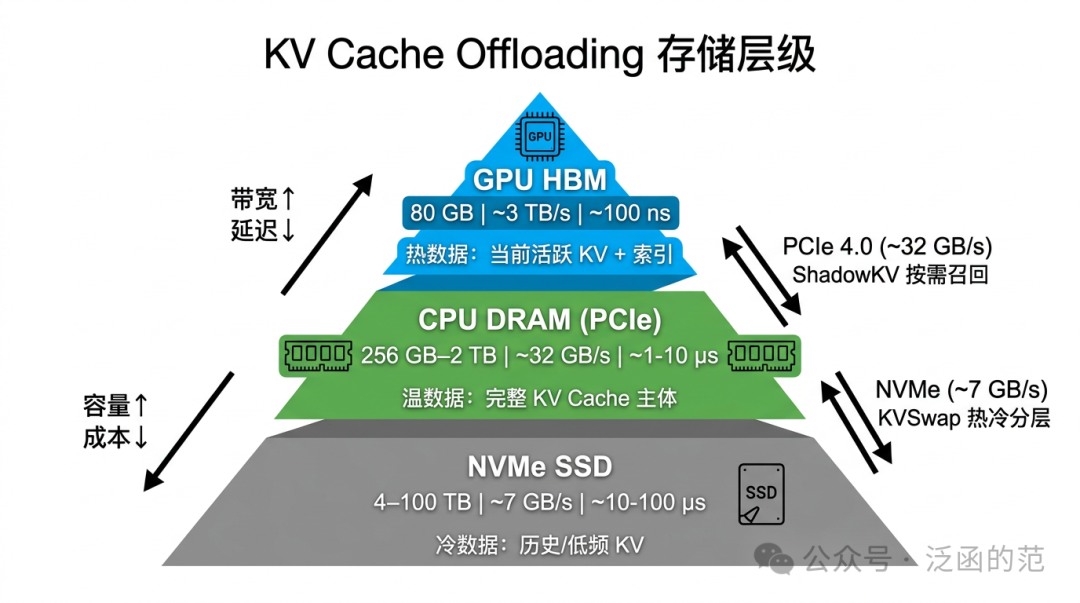
6.1 HBM → DRAM → NVMe,越往下越慢
| 存储层 |
典型容量 |
典型带宽 |
访问延迟 |
| GPU HBM(A100 80G) |
80 GB |
~3 TB/s |
~100 ns |
| CPU DRAM(经 PCIe 4.0) |
256 GB – 2 TB |
~32 GB/s |
1–10 μs |
| NVMe SSD |
4 TB – 100 TB |
~7 GB/s |
10–100 μs |
从 HBM 到 DRAM 带宽下降约 100x,到 NVMe 再降 4–5x。KV Offloading 的核心挑战是在带宽梯度约束下隐藏 I/O 延迟。LLaMA-2-7B 在 1M Token 下的 fp16 KV Cache 约 512 GB,远超单卡容量;int4 量化后仍需约 128 GB,必须跨越 GPU-CPU 边界。
6.2 ShadowKV:完整 KV 放 CPU,按需召回
ShadowKV:GPU 上仅保留 Key 的低维压缩摘要(稀疏索引),完整 KV Cache 存放在 CPU DRAM。每步 Attention 前,用 GPU 上的摘要估算 Top-K 重要 Token,通过 PCIe 按需召回其完整 K/V,仅对这些 Token 计算 Attention。
在单 A100 + 512 GB DRAM 的配置下,ShadowKV 能跑到约 1M Token 的上下文,Decode 吞吐只掉了 20% 左右。
6.3 多机场景:把 KV Cache 分布存
数千 GPU 并发场景需要分布式 KV Cache 存储。
Infinite-LLM 将 KV Cache 分布存储在多机 DRAM 中,Attention 分片并行计算后 All-reduce 合并。
Mooncake 在生产规模实现 Prefill/Decode 解耦 + 分布式 KV 存储池 + 缓存感知路由(详见第二章)。
6.4 KVSwap:手机上怎么跑长上下文
KVSwap 面向移动端/边缘设备(GPU 4–8 GB,DRAM 16–32 GB,NVMe 数 TB),采用热/冷 KV 分层 + 带宽感知预取 + 降级量化(存入 NVMe 时压缩为 int4/int2)。在 16 GB DRAM + 1 TB NVMe 下支持约 100K Token,Decode 速度约为纯 DRAM 方案的 60–70%。
此外,StreamingLLM(见第四章)可视为最激进的“逻辑 Offloading”:直接丢弃中段 KV,仅保留 Sink + 滑动窗口,以牺牲全文检索换取无限流式推理。
选 Offloading 方案时,最重要的不是算法有多聪明,而是你的硬件带宽够不够。PCIe 带宽、NVMe 读写速度、RDMA 是否可用——这些硬约束决定了方案能不能跑得动。别拿 spec 上的理论峰值算,用实测数字。
七、到底该选哪个方案
前面讲了这么多方案,落到具体项目上到底该选哪个?下面试着给一张“地图”。
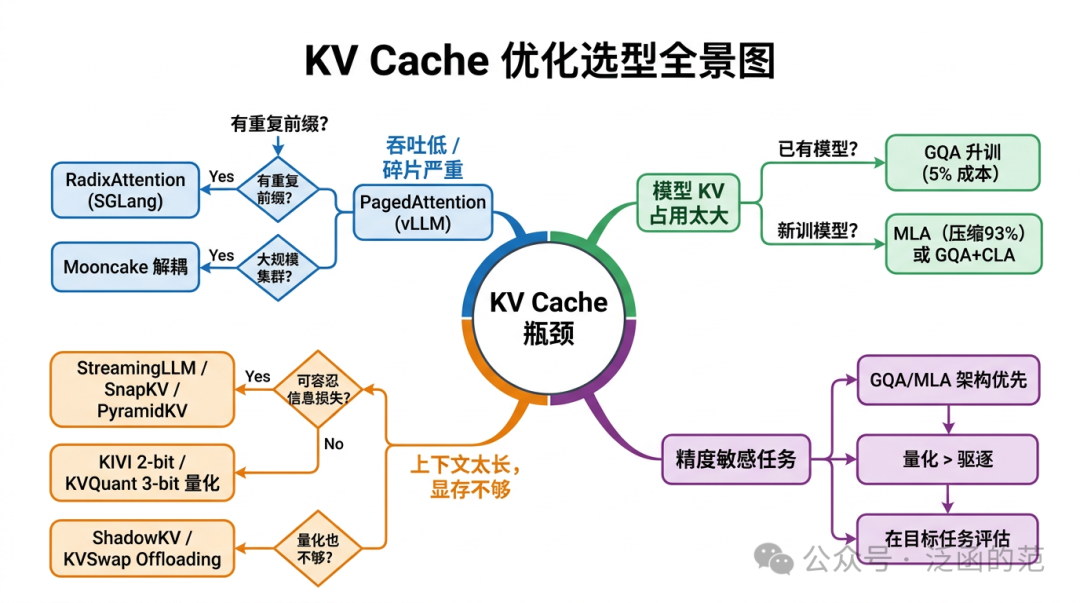
7.1 从瓶颈出发的决策树

7.2 六个场景,各走哪条路
| 场景 |
首选方案 |
可叠加 |
关键注意 |
| 多用户 SaaS |
PagedAttention + RadixAttention |
GQA 模型 |
前缀命中率 >50% 才有收益 |
| RAG 长文档 QA |
GQA + SnapKV/PyramidKV |
int8 量化 |
不适合 StreamingLLM(需全文检索) |
| 移动端/边缘 |
GQA/MLA + KIVI 2-bit |
KVSwap 磁盘卸载 |
确认目标平台 int2/int4 kernel 支持 |
| 新模型设计 |
MLA(极致)或 GQA-8(成熟) |
CLA 跨层共享 |
MLA 需训练之初确定 $d_c, d_R$ |
| 超长流式对话 |
StreamingLLM |
GQA 模型 |
不支持历史回溯,需应用层持久化 |
| 大规模集群 |
Mooncake 解耦架构 |
量化 + Radix Tree |
需 RDMA 基础设施,小规模 ROI 低 |
7.3 四个容易踩的坑
误区一:驱逐总是安全的。 LongBench 平均分可能掩盖特定任务的严重退化。PyramidKV “12% 匹配全量”是多任务平均;在 PassageRetrieval 等全文检索子任务上,性能下降可超过 10 个百分点。建议:在实际业务任务上评估,合同审查、代码理解等优先量化而非驱逐。
误区二:2-bit 量化一定损失大。 KIVI 实验表明,2-bit KV 量化在多数 NLP 基准上与 fp16 无显著差异——KV 的量化误差经 softmax 加权后被平滑。例外是数学推理和代码生成(可能下降 1–5%)。建议:先跑 2-bit 对比实验再决策。
误区三:有条件就该用 MLA。 GQA 可从已有 MHA 低成本升训(5% 训练量),CUDA kernel 和框架支持成熟。MLA 必须从头训练,kernel 优化复杂,目前仅 DeepSeek 框架有深度支持。建议:已有模型优先 GQA;新训旗舰模型考虑 MLA。
误区四:技术可以随意叠加。 MLA + per-channel 量化($c_{KV}$ 统计特性不同于原始 K/V,需重新校准)、驱逐 + 量化(简单串联会导致误差传递)、StreamingLLM + PagedAttention(频繁 Block 释放需验证)都存在相互干扰风险。建议:优先选择已有研究验证的组合,叠加前在目标任务上单独和联合评估。
八、接下来会往哪走
最后聊聊这个领域接下来可能往哪走。
8.1 三条路开始合流
过去三年,系统、架构、算法这三条路基本是各走各的。但越来越多的工作开始把它们混着用:
量化 × 驱逐联合:ZipCache 表明,将重要性分数同时用于驱逐和精度分配优于两者独立操作。未来方向是在 Token/Head/Layer 三个维度上联合差异化资源分配。
架构 × 系统协同:MLA 的 512 维 $c_{KV}$ 天然适配 Mooncake 式分布式存储(传输代价远低于完整 K/V)。反过来,网络带宽瓶颈也会促使架构进一步压缩 KV 传输体积。
训练 × 推理联合:现有方法均为纯推理侧优化。但 MLA 已证明:训练时引入低秩约束可让模型主动学习更紧凑的 K/V 表示,质量甚至超过 MHA。将类似思路扩展到量化感知训练(QAT for KV Cache),是值得探索的方向。
8.2 硬件在变,软件方案也得跟着变
硬件这边也在变,有些变化可能直接让今天的某些软件方案变得不再必要:
- CXL 内存池:CXL 3.0 支持 GPU 直接访问扩展 DRAM(单节点数 TB,带宽 ~128 GB/s),直接改善 ShadowKV 类 Offloading 方案的 PCIe 带宽瓶颈。
- HBM3e:H200 峰值带宽达 4.8 TB/s(H100 为 3.35 TB/s),更高带宽使更长的未压缩 KV Cache 也具备可接受吞吐。
- Processing-in-Memory(PIM):Samsung Aquabolt-XL、SK Hynix AiMX 等将计算单元集成到 DRAM 中,KV Cache 的 MV 操作可在内存内完成,从根本上绕过内存带宽限制。仍处早期,但潜力巨大。
8.3 多模态让 KV Cache 问题更严重了
多模态大模型带来量级更大的 KV Cache 压力:一张高分辨率图像可产生 1024–4096 个 Token,10 张图片即超过 4 万 Token;10 分钟视频(1 fps × 256 Token/帧)合计 15 万 Token。帧间时序冗余提供压缩空间,但成熟方案尚未形成。将 MLA 迁移到 VLM 是早期代表性工作。
8.4 压缩可能动了“大海捞针”与安全对齐的奶酪
激进压缩(尤其是 Token 驱逐)在面临越来越严苛的长文本评测(如 NIAH 大海捞针)时,很容易把那根“针”给扔掉,导致长文本检索能力严重退化。此外,它还可能导致安全对齐退化:RLHF/DPO 训练的拒绝行为依赖特定 Token 的精确 Attention 激活,若关键 Token 被驱逐或量化误差影响对齐层计算,安全护栏可能失效。有综述指出,KV 压缩对安全性、事实性和推理一致性的影响是重要研究空白。建议:对激进压缩模型额外进行 Red Team 测试和长文本极细粒度检索测试。
8.5 投机解码(Speculative Decoding)带来的新挑战
投机解码是目前推理加速的当红炸子鸡。它通过小模型一次性生成多个候选 Token,再由大模型一次性验证,把 Decode 阶段从纯 Memory-bound(访存瓶颈)向 Compute-bound(计算瓶颈)拉回了一点。但这要求系统能够高效地并发读取、验证和回滚 KV Cache。如何设计支持高效分支预测和状态回滚的 KV Cache 内存池,将是下一代推理引擎(如 vLLM、TensorRT-LLM)的核心战场。
结语
回头看 KV Cache 这个话题,它其实横跨了三个很不一样的领域:系统工程(怎么管内存)、算法设计(怎么压信息)、模型架构(怎么从源头减少冗余)。三条路各有各的好处和局限,在实际项目中往往是组合着用的。
随着上下文窗口越推越长、多模态输入带来的 Token 数爆炸式增长、设备端推理的需求起来,KV Cache 在未来只会更重要,不会更边缘。搞清楚它的本质和权衡,对于做 LLM 推理系统的人来说,大概是绕不过去的一课。
 发表于 2026-4-18 01:50:48
|
查看: 260|
回复: 0
发表于 2026-4-18 01:50:48
|
查看: 260|
回复: 0
