持久化层和缓存层的一致性问题,通常也被称为“双写一致性问题”。所谓“双写”,即同一份数据既在数据库保存,也在缓存中保存。
对于一致性,我们常讨论强一致性和弱一致性。强一致性保证写入后立即可读,而弱一致性则不保证立即可读,它致力于在经过一段时间后能读到最新值。在弱一致性模型中,最终一致性应用最为广泛,它确保系统最终会达到一致状态。
我们通常使用Redis来做什么呢?
- 缓存:提高性能,降低响应时间(RT),提升系统吞吐量。
- 分布式锁:协调分布式环境下的资源访问。
为什么 Redis 和 MySQL 数据可能不一致?
这背后有几个核心原因:
- 组件独立性:Redis与MySQL是两个独立的组件,它们之间无法保证操作的原子性。
- 设计目标的差异:两者在性能与一致性上做出了不同取舍。
- Redis追求极致性能,不保证ACID特性。
- MySQL为了保证数据一致性(ACID),在一定程度上牺牲了性能。
- 网络不确定性:分布式环境下,网络延迟和乱序无法保证客户端请求到达服务的先后顺序。
缓存不一致场景分析
让我们基于一些极端并发场景,深入分析几种常见的缓存更新策略及其问题。
先写数据库,再删缓存(Cache Aside)
这是最经典的策略,也称为“旁路缓存”。
- 读:先读缓存。若缓存未命中,则读数据库,并将结果写入缓存。
- 写:更新数据库,成功后删除缓存。
口诀是:写失效,读更新。
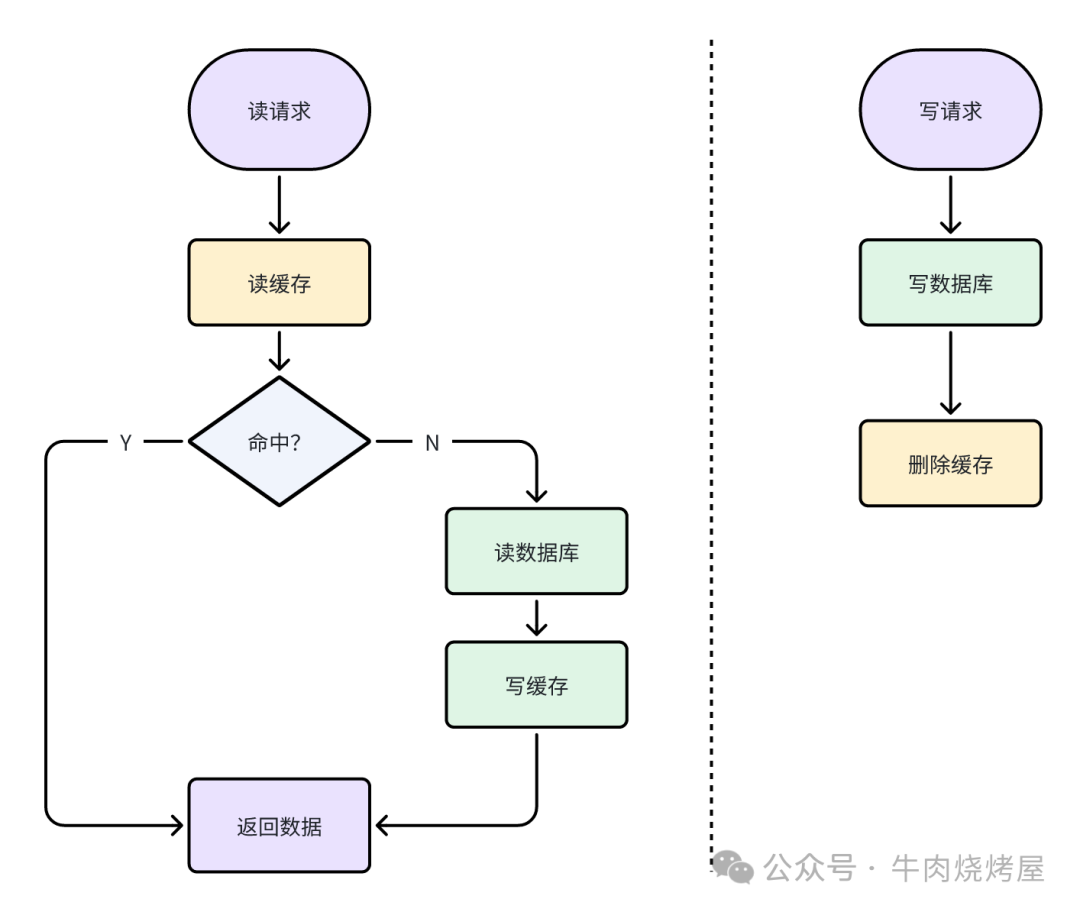
缓存不一致场景
这种策略在特定并发时序下仍会出现不一致:
- 并发读写时序问题:一个读请求在缓存未命中后去读数据库,与此同时,一个写请求更新了数据库并删除了缓存。若读请求的“写缓存”操作晚于写请求的“删缓存”操作,就会把旧数据再次写入缓存。
- 主从延迟:如果写主库、读从库,主从同步延迟可能导致读请求读到旧的从库数据并写入缓存。
- 缓存删除失败:网络抖动或服务异常导致删除缓存失败。
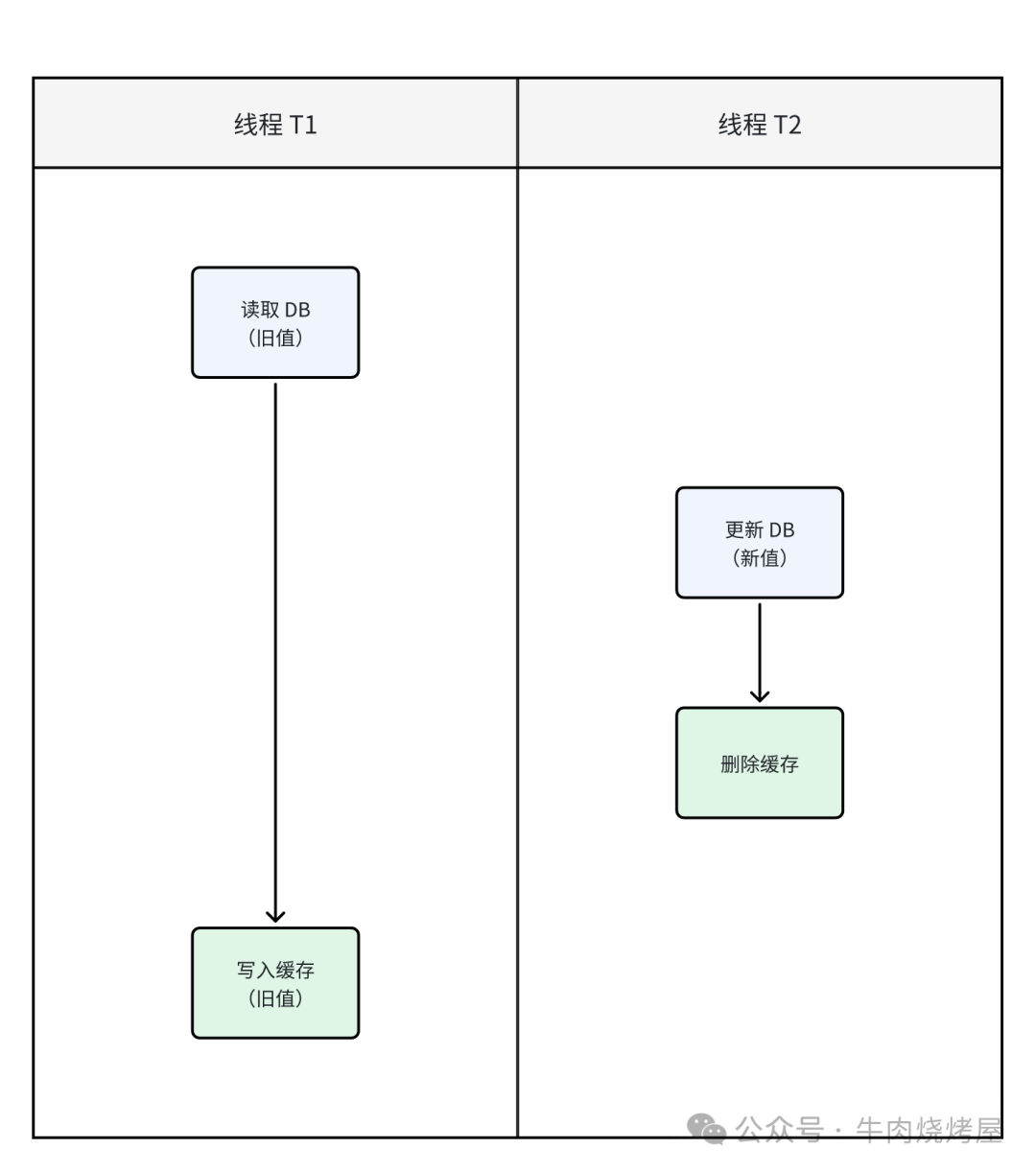
先写数据库,再写缓存(双写)
- 读:先读缓存,未命中则读库回填。
- 写:更新数据库,然后更新缓存。
读和写操作都可能触发写缓存。
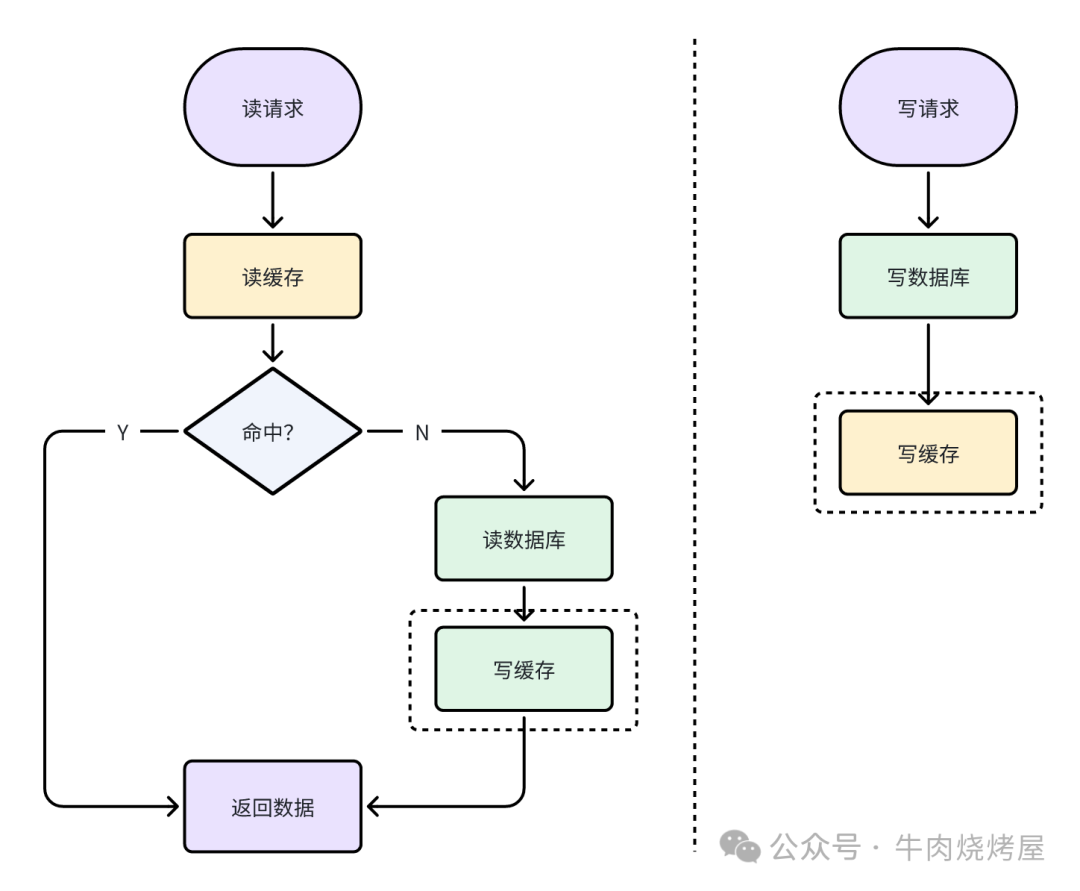
缓存不一致场景
- 情况一:与Cache Aside类似的并发时序问题。
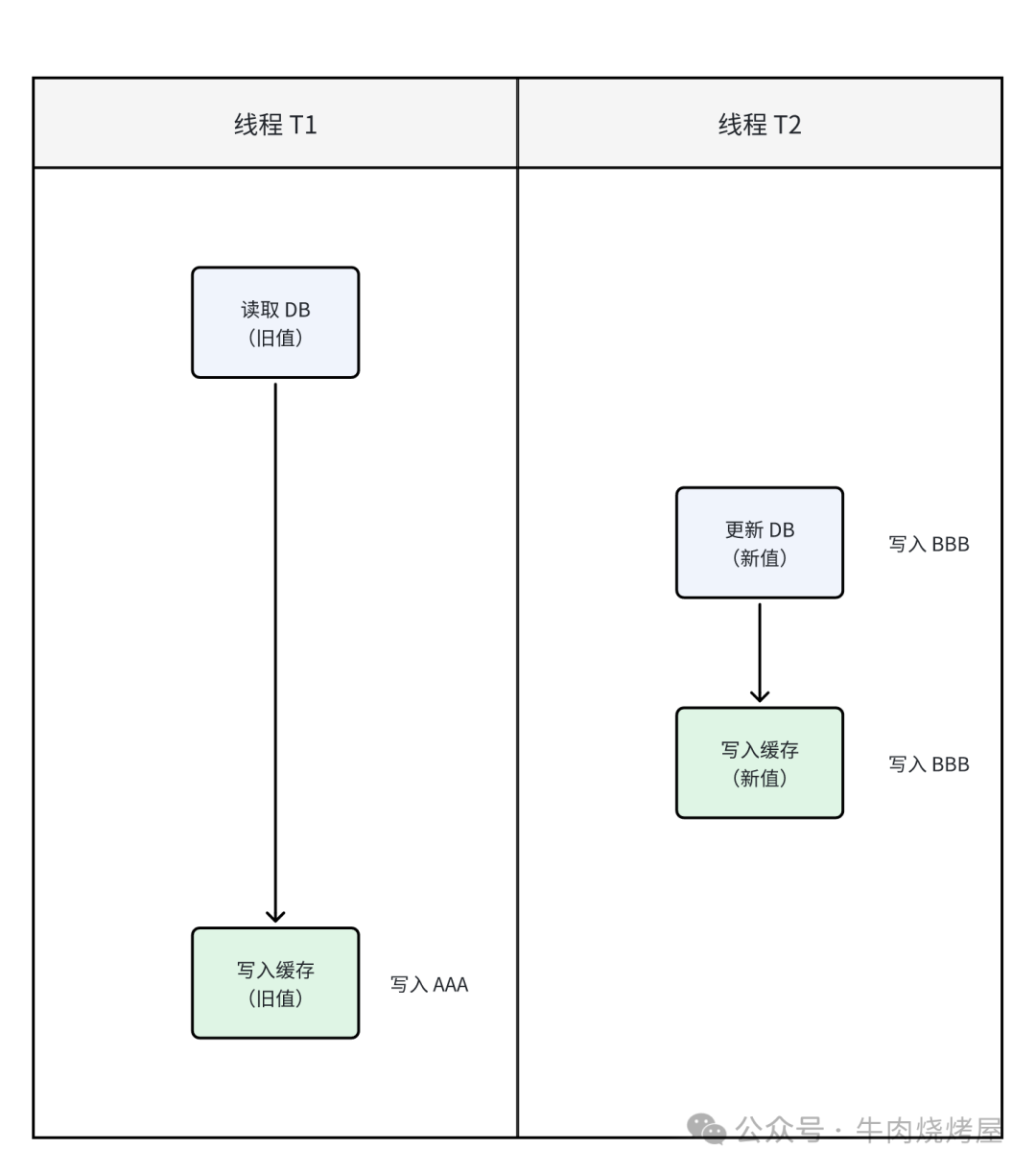
- 情况二:更严重的问题。线程A写数据库后、写缓存前,线程B完成了对数据库和缓存的更新(写入了新值)。随后线程A将自己的旧值写入缓存,覆盖了线程B的新值。
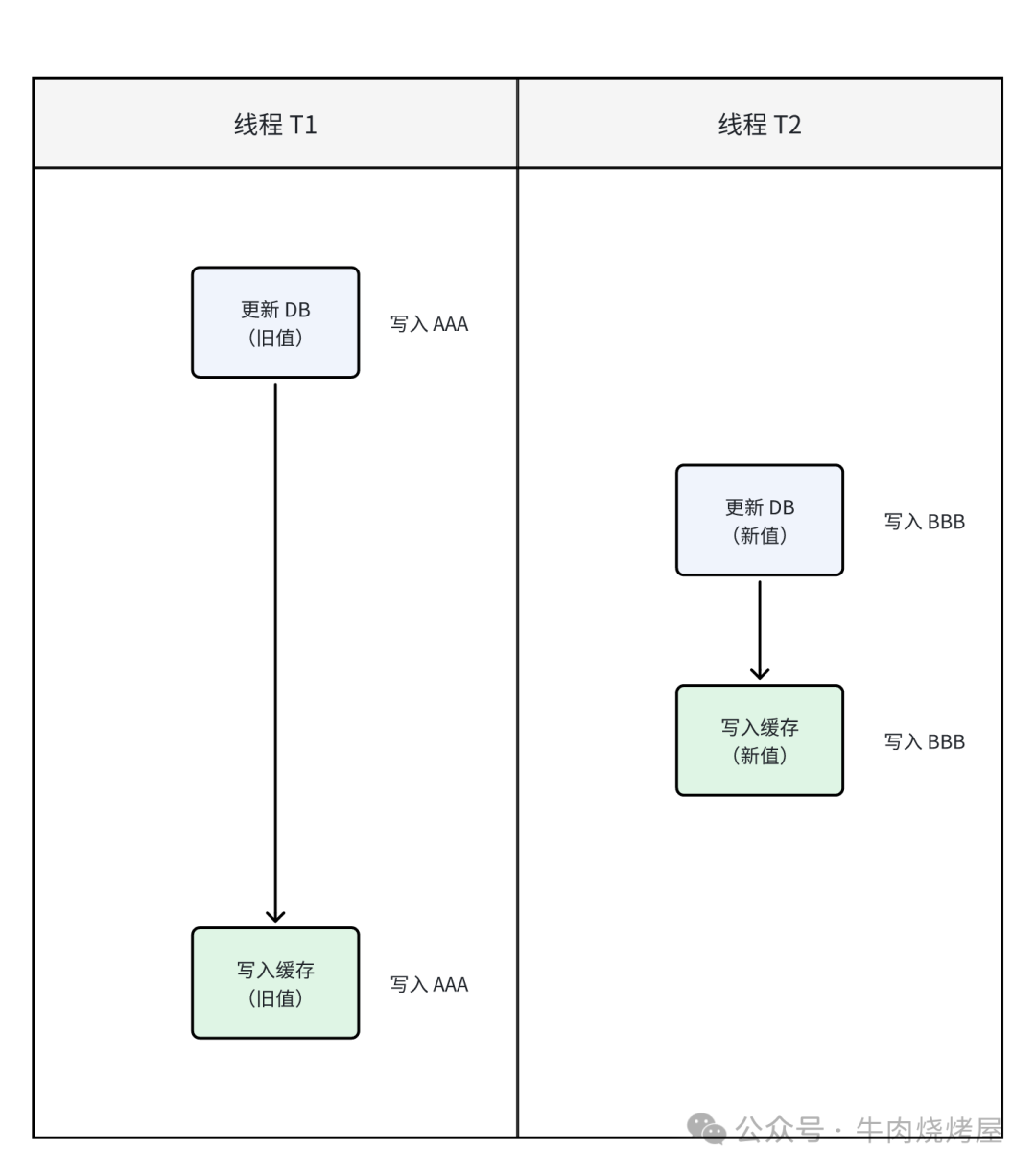
解决方案
- 分布式锁:对同一键值的“写数据库+写缓存”操作加锁,保证原子性,但严重影响性能。
- 乐观锁:为缓存数据引入版本号,写缓存时比较版本,确保新值不被旧值覆盖。
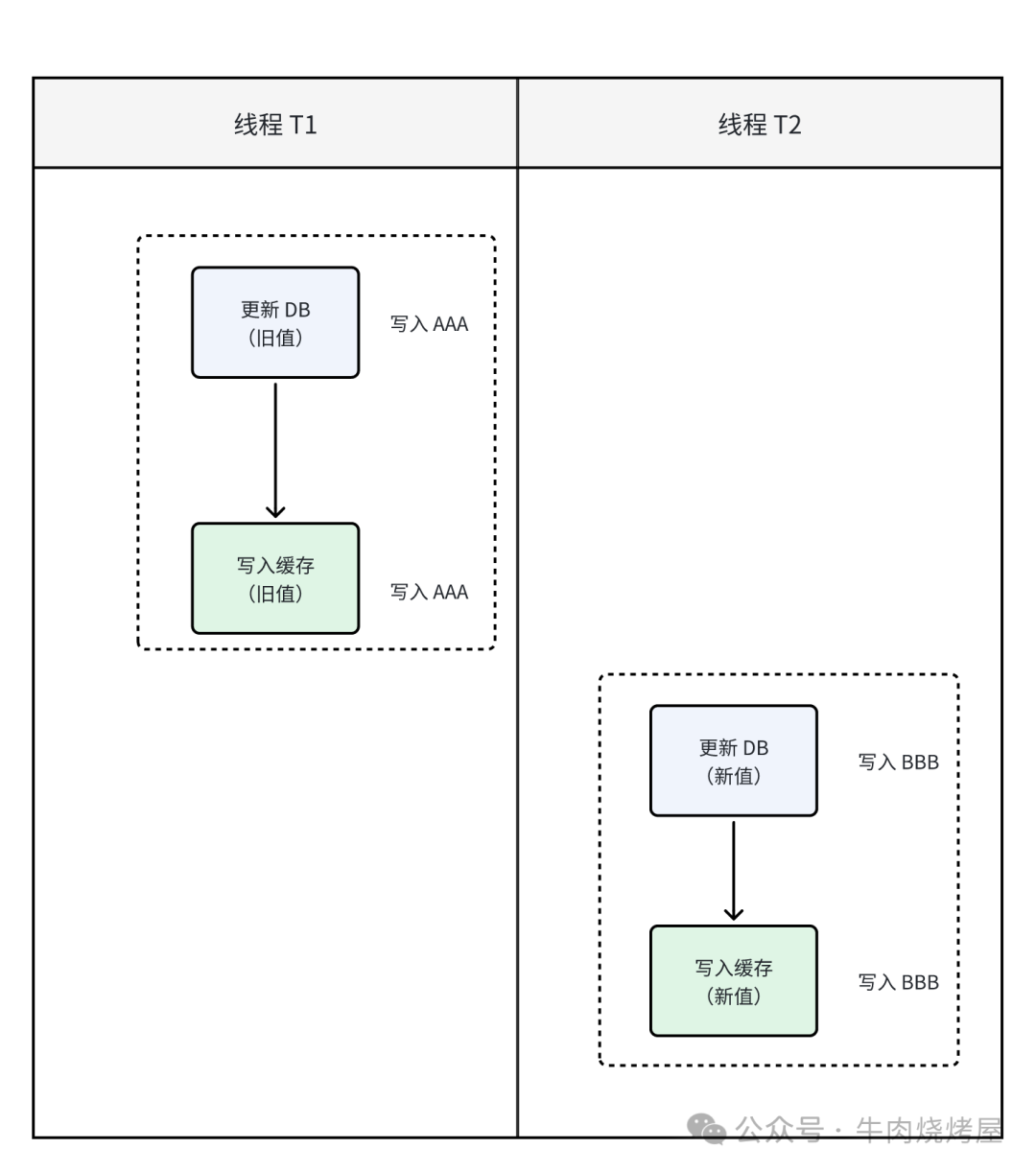
先写缓存,再写数据库
- 读:先读缓存,未命中则读库回填。
- 写:先更新缓存,然后更新数据库。
缓存不一致的场景
最大的问题是无法保证原子性。如果写缓存成功,但写数据库失败,缓存无法回滚(因为数据库事务可以回滚,但Redis操作无法自动回滚)。此时,其他读请求会读到缓存中未被持久化的“脏数据”。
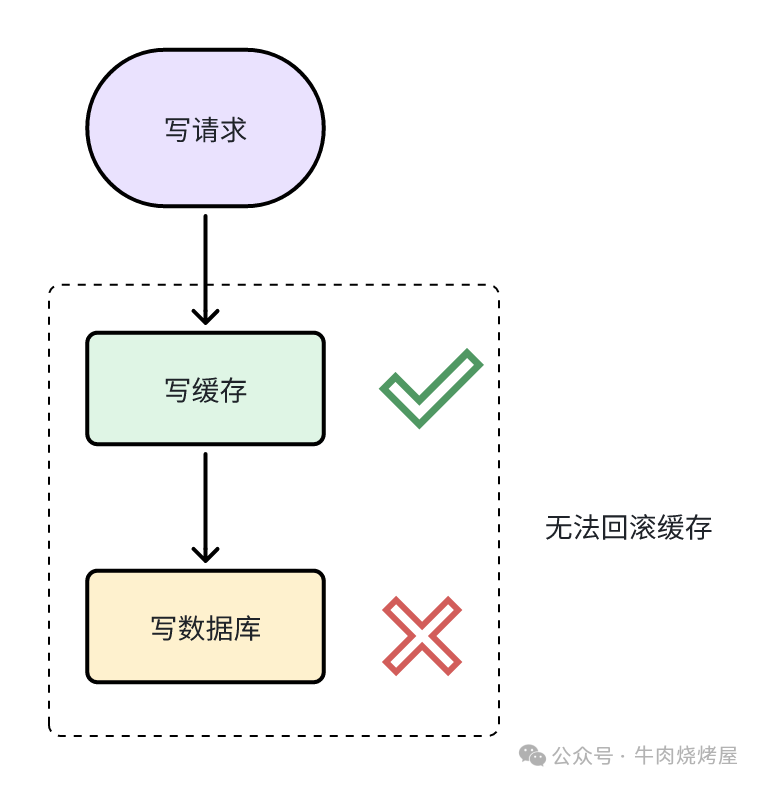
解决方案
- 分布式事务:引入复杂的分布式事务机制(如TCC),在写数据库失败后,执行补偿操作删除缓存。成本高昂,与使用缓存提升性能的初衷相悖。
先删缓存,再写数据库
- 读:先读缓存,未命中则读库回填。
- 写:先删除缓存,然后更新数据库。
缓存不一致的场景
- 缓存击穿:过早删除缓存,可能导致大量请求瞬间穿透到数据库。
- 旧数据回填:在删除缓存后、更新数据库完成前,另一个读请求发现缓存缺失,从数据库读到旧值并回填到缓存中。这在流量大的场景下概率不低。
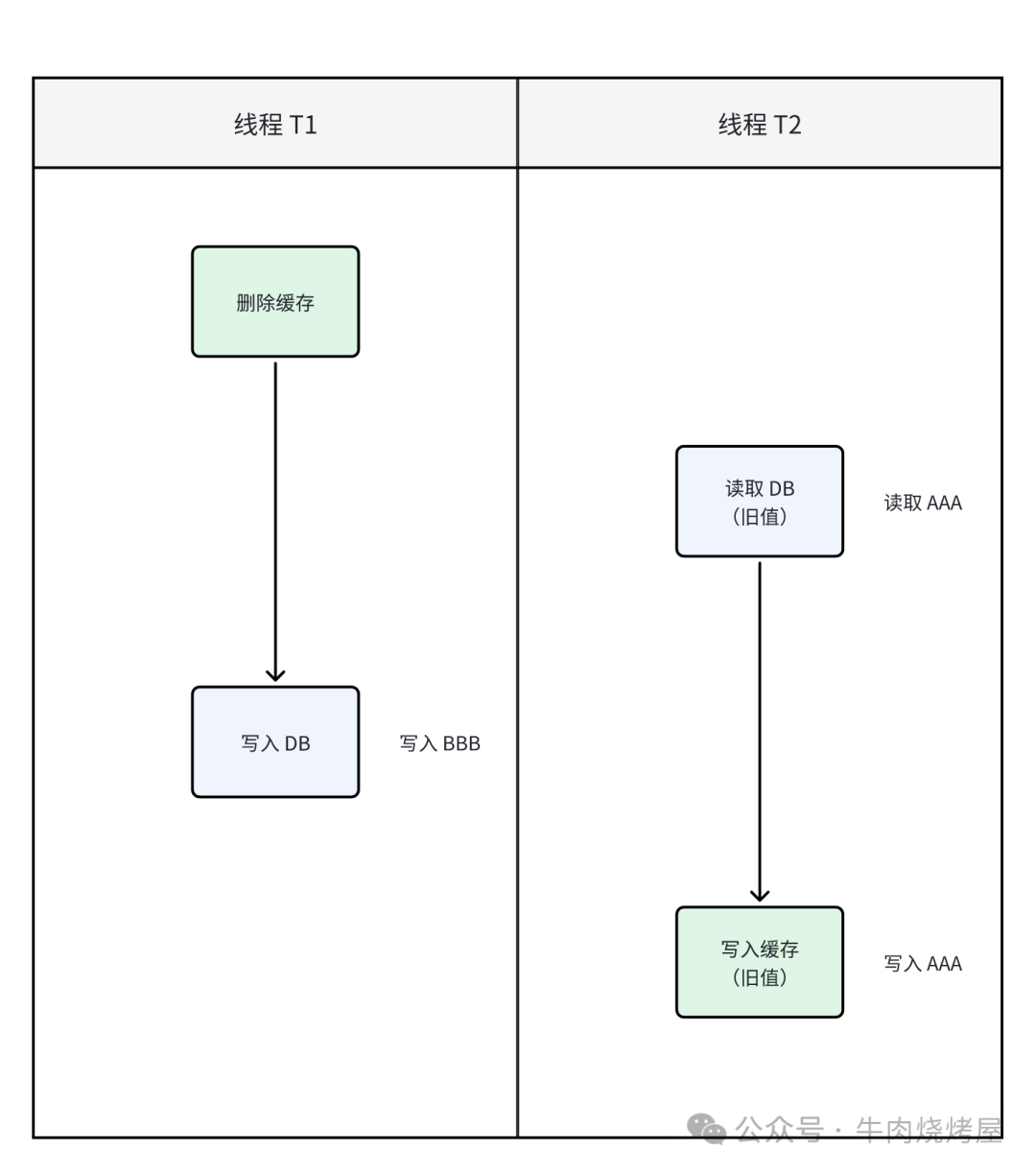
解决方案
- 加锁:每次读写操作都加锁,简单粗暴但性能代价极大。
- 延迟双删。
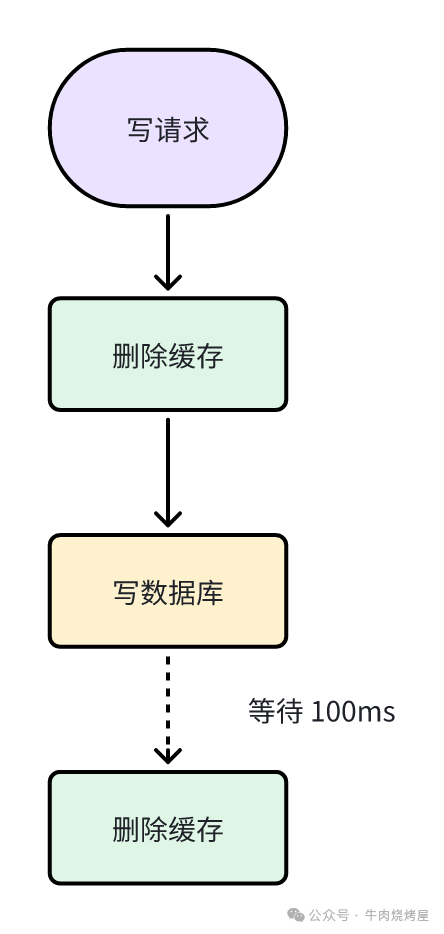
延迟双删
此策略旨在解决“先删再写”策略中旧数据回填的问题。
- 读:先读缓存,未命中则读库回填。
- 写:1. 先删除缓存;2. 更新数据库;3. 等待一段时间后,再次删除缓存。
- 第一次删除:防止其他线程立即读到旧缓存。
- 第二次删除:确保将本线程更新期间,其他线程可能写入的旧缓存清理掉。
存在问题
- 等待时间难以把控:太短可能二次删除无效,太长则不一致窗口期变长且增加响应延迟(虽然可异步,但旧缓存留存时间变长)。
- 代码复杂度增加。
- 仍存在缓存击穿风险。
此方案并未显著降低不一致的概率,且实现成本往往高于收益。
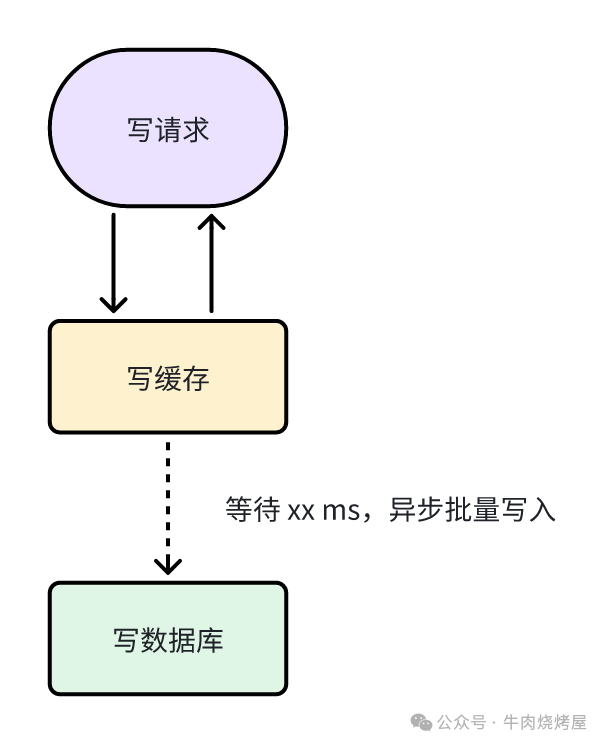
异步写入
写回(Write Back)
数据先写入缓存,异步批量写入数据库,充分利用内存的高性能。
- 读:读缓存,未命中则读库回填。
- 写:写缓存后立即返回成功,异步批量写数据库。
例如,给视频点赞的计数器场景:
-- 原始方案:每次点赞执行1条SQL,3次点赞需执行3次
UPDATE t_video SET `like` = `like` + 1 WHERE id = '1';
UPDATE t_video SET `like` = `like` + 1 WHERE id = '1';
UPDATE t_video SET `like` = `like` + 1 WHERE id = '1';
-- Write Back 聚合:在内存累计后,执行1次
UPDATE t_video SET `like` = `like` + 3 WHERE id = '1';
缓存不一致的场景
- 内存数据有丢失风险(如进程重启)。
- 异步写数据库可能失败,需通过复杂机制(如WAL日志)保证或恢复。
- 不一致窗口期 = 等待聚合时间 + 执行批量写入时间。
应用场景
适用于对写性能要求极高,且可以容忍一定时间数据不一致的场景(如点赞、计数、日志聚合)。
手动/定时更新缓存
例如,对即将上线的活动数据进行预热。问题在于难以精准识别所有热点数据。
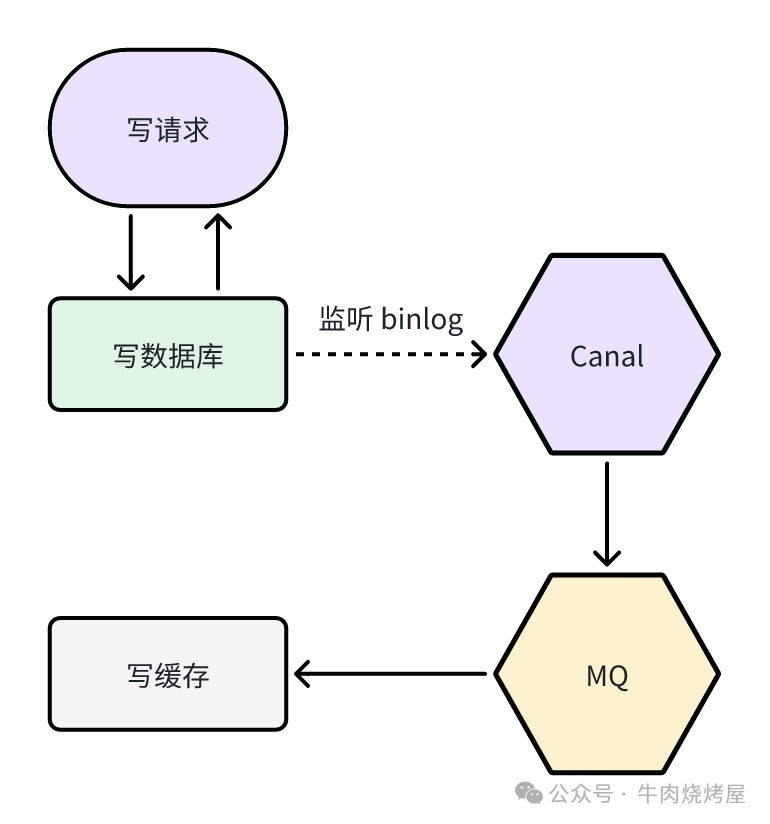
监听 binlog 异步更新缓存
- 写:业务代码直接写数据库。
- 更新缓存:通过Canal等工具监听MySQL的binlog变化,将变更事件发送到消息队列(MQ),由消费者异步更新或删除缓存。
- 读:直接读缓存。
此方案业务代码侵入性低,开发者只需关注数据库逻辑。
优缺点
- 优点:较好地保证最终一致性,业务代码简洁。
- 缺点:从数据库更新到缓存更新链路较长,存在延迟;需要额外维护Canal和MQ,架构复杂度高。
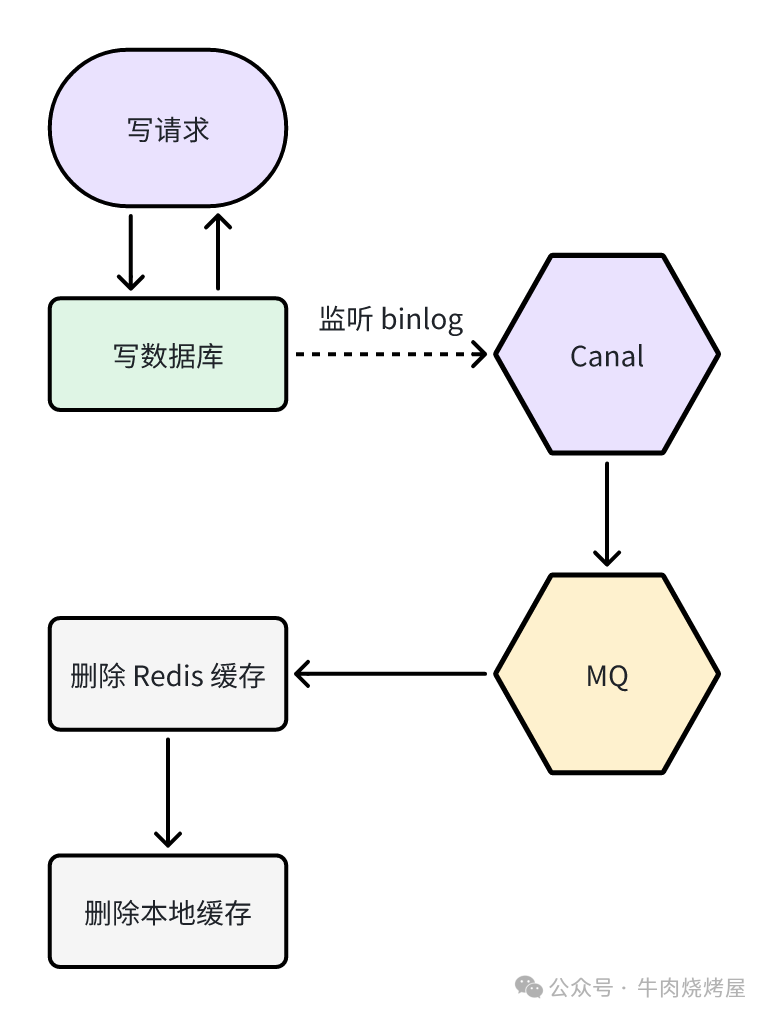
再进一步:本地缓存 + Redis + MySQL
引入本地缓存(如Caffeine、Guava Cache)的好处:
- 性能更高:避免了网络IO和序列化开销,读取速度极快。
- 缓解Redis热Key压力:热门数据在进程内命中,减少对Redis的访问。
本地缓存是一种“去中心化”的思路。但它也带来新问题:
- 内存管理:需限制大小并配合LRU等淘汰策略,防止内存无限增长。
- 编码复杂性。
- 缓存一致性问题升级:需同时维护 本地缓存 vs Redis、Redis vs MySQL 两个层级的一致性。
方案一:足够短的过期时间
采用Cache Aside策略,并为本地缓存设置很短的TTL(例如1秒)。
- 优点:实现简单。
- 缺点:不一致窗口取决于TTL;TTL设太短则缓存命中率低,失去使用价值。
方案二:MQ异步让缓存失效
在“监听binlog”方案基础上更进一步:当监听到数据变更时,通过MQ广播消息,通知集群内所有JVM实例,使其失效对应的本地缓存项。
- 优点:能相对及时地失效本地缓存。
- 缺点:系统复杂度和维护成本很高。
扩展:其它场景的缓存一致性
缓存思想在计算机科学中无处不在。
HTTP 强制缓存 & 协商缓存
浏览器缓存是提升Web性能的关键。
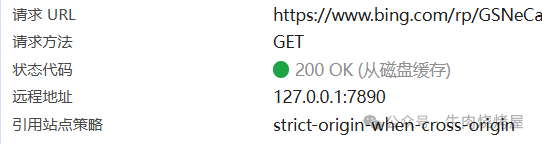
图中状态码200 (from disk cache)即命中了强制缓存
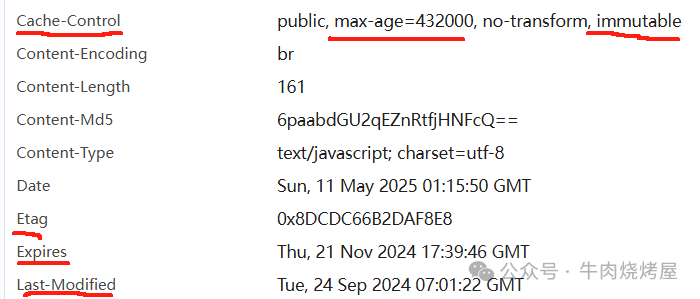
流程:
- 首次请求资源,服务器返回资源及
Cache-Control、ETag、Last-Modified等头部。
- 再次请求,若资源未过期(根据
Cache-Control),直接使用强制缓存(状态码200 from cache)。
- 若资源已过期,浏览器携带
If-None-Match(对应ETag)或If-Modified-Since(对应Last-Modified)发起协商缓存请求。
- 服务器校验:无变更则返回304,浏览器用本地缓存;有变更则返回200和新资源。
解决一致性的方案:过期时间(TTL)、资源指纹(ETag)、最后修改时间(Last-Modified)。
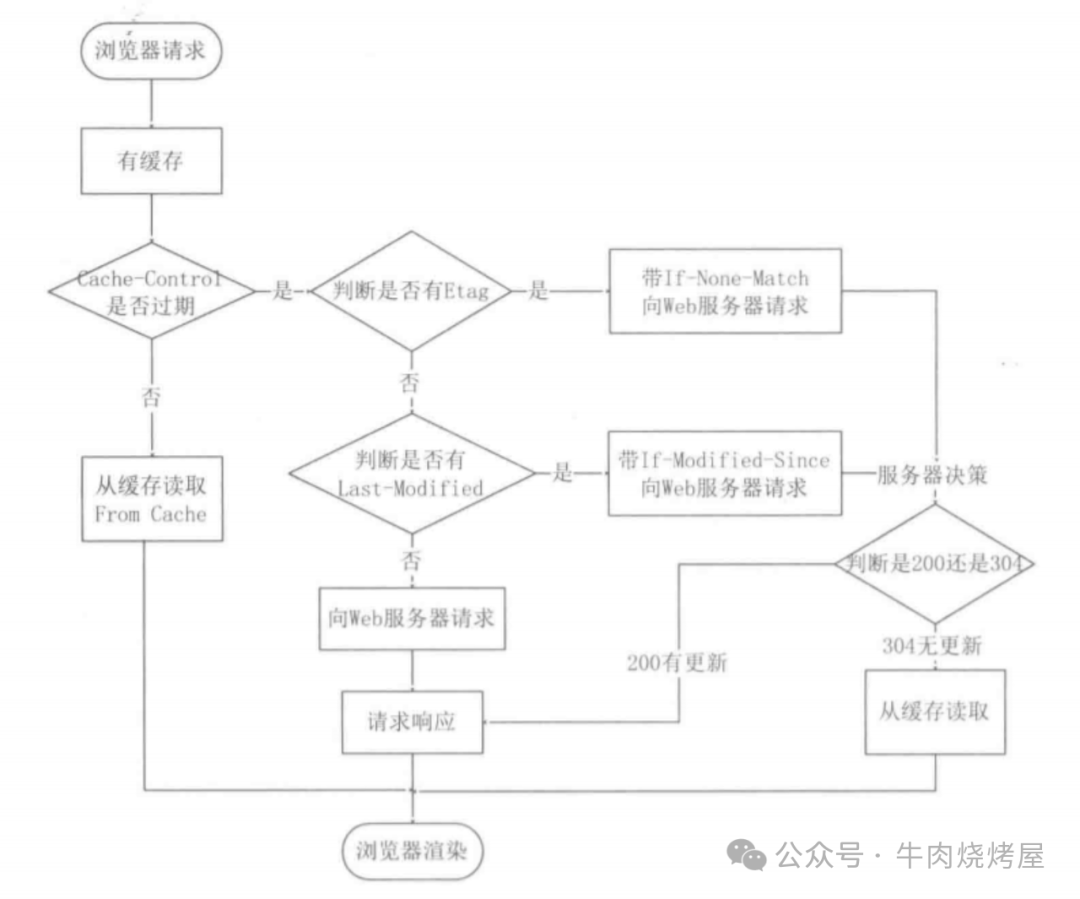
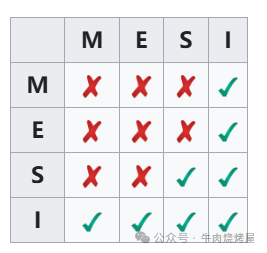
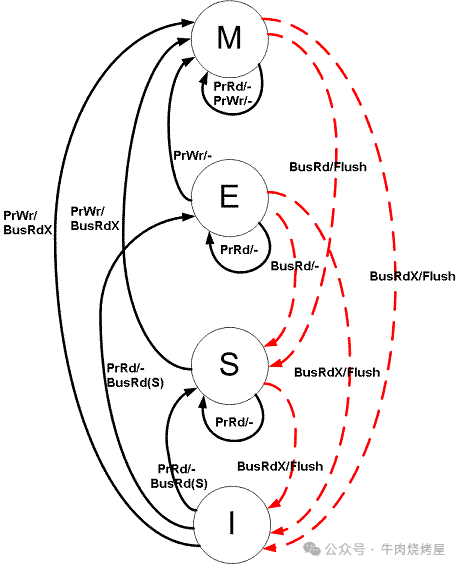
CPU 缓存一致性(MESI协议)
现代CPU有多级缓存,需要保证多个核心之间缓存的一致性,主要依赖MESI协议。
- Modified (M):数据被当前核心修改,与内存不一致,其他核心无副本。
- Exclusive (E):数据仅当前核心有缓存,且与内存一致。
- Shared (S):数据被多个核心共享,所有缓存与内存一致。
- Invalid (I):缓存行数据无效(因其他核心已修改)。
任意两个缓存行的状态相容关系如下:
工作流程
- 核心A修改数据时,会通过总线将其他核心中该数据的缓存行标记为Invalid,然后将自己缓存行设为Modified。
- 核心B读取该数据时,通过总线嗅探发现状态为Invalid,会触发从内存或核心A重新加载数据。
解决一致性的方案:硬件层面的MESI协议及总线嗅探机制。
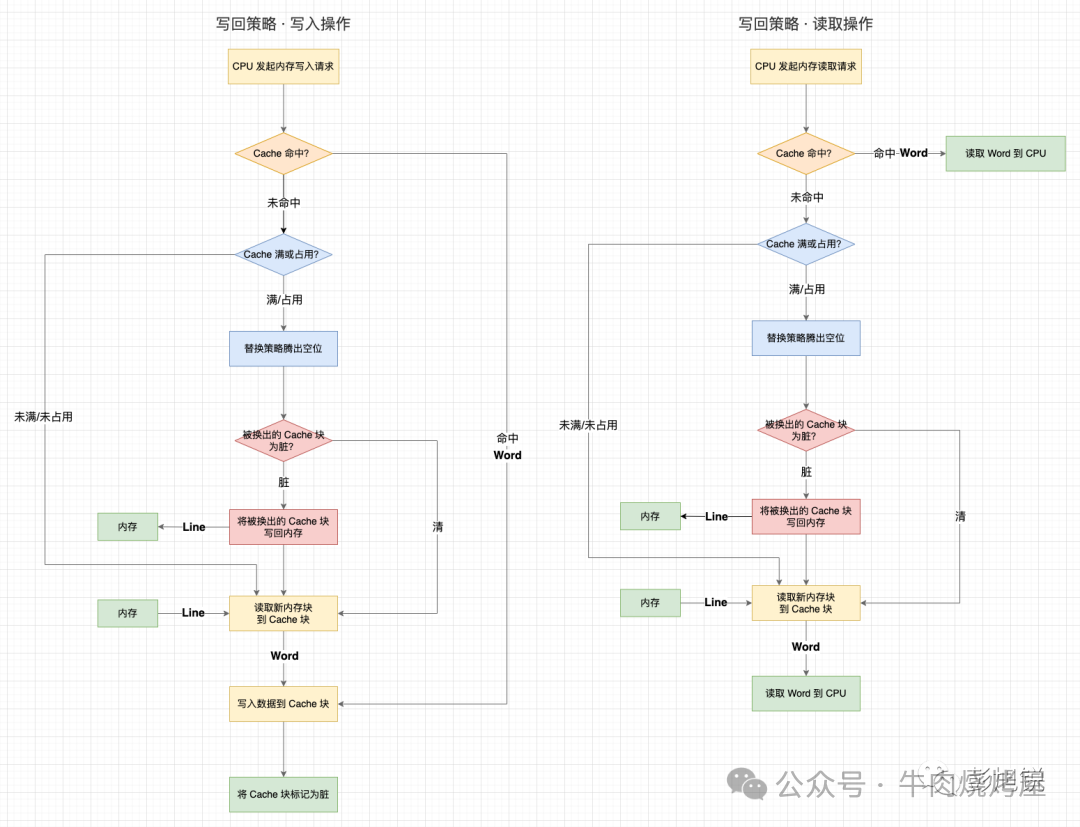
CPU 与内存的一致性(写回策略)
CPU缓存速度远快于内存。为减少对内存的频繁写入,CPU采用写回(Write-Back)策略。
工作原理
- 数据修改仅写入CPU缓存,并标记该缓存行为“脏(Dirty)”。
- 不立即更新内存。
- 当该缓存行因空间不足被淘汰时,才将脏数据写回内存。
解决一致性的方案:脏位标记 + 淘汰时写回。
Linux 的 Page Cache
Page Cache是磁盘数据在内存中的缓存,用于加速磁盘IO。
- 延迟写入:进程写文件时,数据先写入Page Cache的“脏页”,而非直接落盘。由内核线程定期或触发条件时异步刷盘。
- 合并IO:将短时间内对同一磁盘区域的多次写合并为一次IO。
- 预读:根据顺序访问模式预读后续数据到Cache。
int fd = open(“data.txt”, O_WRONLY);
write(fd, “hello”, 5); // 数据写入Page Cache,并未落盘
fsync(fd); // 强制将脏页刷新到磁盘
为什么异常关机可能丢数据? 因为还在Page Cache中未刷盘的脏页会丢失。
解决一致性的方案:脏页写回机制。
MySQL Buffer Pool 与磁盘一致性
InnoDB的Buffer Pool用于缓存表数据和索引页,思想与Page Cache类似。
- 查询时先查Buffer Pool,命中则直接返回;未命中则从磁盘读入。
- 修改数据时,先在Buffer Pool中修改产生“脏页”,然后通过redo log保证持久性,脏页由后台线程刷盘。
- 由于redo log已落盘,即使脏页丢失也能恢复。
扩展:Change Buffer与唯一索引性能
Change Buffer是Buffer Pool的一部分,用于缓存对非唯一二级索引的修改。当索引页不在内存中时,修改先记入Change Buffer,待未来该页被读入内存时再合并(merge)。唯一索引因为要立即检查唯一性约束,无法利用Change Buffer,必须读入索引页,因此写入性能更差。
Buffer Pool 与 Page Cache的“双缓冲”
默认配置下,MySQL读写数据文件会经过:Buffer Pool -> Page Cache -> Disk。这可能导致不必要的内存拷贝。可通过O_DIRECT等方式绕过Page Cache。
解决一致性的方案:脏页写回 + Redo Log(WAL)。
使用建议
- 必须设置过期时间:这是保证最终一致性的最后防线。缓存过期后重新加载,大概率能取得一致状态。
- 慎用分布式事务和锁:使用缓存本意为提升性能,引入分布式事务或锁会严重抵消其收益。既然选择了缓存,通常就意味着接受了非强一致性场景。
- 根据业务场景选择方案:
- Cache Aside:简单高效,不一致概率低,是工程上的主流选择。
- 监听Binlog异步更新:能很好保证最终一致性,但架构复杂。
- Write Back:写性能极高,但存在数据丢失风险,适合可容忍丢失的计数、统计场景。
- 本地缓存:性能极佳,适用于热点数据明确的场景。
- 读多写少:Cache Aside或本地缓存表现良好。
- 读多写多:需要仔细评估一致性要求,可能需结合多种策略。
补充说明
- 最终一致性:在缓存场景中,“一定时间后”通常指的就是缓存的过期时间(TTL)。
- 并发概率问题:缓存不一致本质是并发时序问题。在低流量场景下,任何方案差异都不大,因为极端并发情况很难出现。
- 分布式锁的一致性:单Redis节点的锁无一致性问题。但在主从/集群模式下,需考虑因主从切换或脑裂导致的锁失效问题。
结语
软件架构设计常常面临取舍(Trade-Off)。在缓存一致性问题上,我们几乎无法设计出一个既保证强一致性、又拥有极致性能、还实现高可用的完美方案。
追求强一致性与高性能,在缓存领域本身就是一个难题。工程实践的关键在于,明确为了得到什么(如性能、可用性),而愿意牺牲什么(如强一致性)。因此,Cache Aside策略成为了广泛接受的折中方案——我们以极低的概率赌它不会出现不一致,从而避免为维护强一致性而引入的巨大性能开销。这或许就是工程学的智慧:在理想的正确与现实的效率之间,找到那个可行的平衡点。
希望这篇系统性的梳理,能帮助你在 云栈社区 的日常技术讨论和架构设计中,更从容地应对缓存一致性这一经典挑战。
参考
 发表于 2026-4-7 02:06:41
|
查看: 169|
回复: 0
发表于 2026-4-7 02:06:41
|
查看: 169|
回复: 0
