最近深入研究了一些端侧AI推理的技术方案,在此与大家做个系统的分享。
随着人工智能与大模型的迅猛发展,AI已成为各业务场景探索创新的核心驱动力。与此同时,端侧设备算力的持续提升与模型性能的不断增强,让端侧AI的部署与推理成为了业界的热门话题。本文将系统性地介绍市面上主流的端侧推理引擎、大模型部署方案及其背后的关键技术。
端智能的优势
优势
端智能在本地设备上进行推理和决策,无需依赖云端服务器,相比传统的云端智能方案,具备显著优势:
-
低延迟
- 模型运行在本地,省去了网络传输环节,响应速度更快。
- 非常适合智能辅助驾驶等对实时性要求极高的场景。
-
隐私保护
- 用户数据无需上传至云端,从根本上降低了隐私泄露的风险。
-
离线可用
- 在弱网甚至无网络的环境下也能正常运行。
- 极大地提升了用户体验和系统可靠性。
-
降低云端成本
- 无需消耗云端计算资源进行推理,显著节省了云端成本。
- 减少了数据上传,也节省了网络带宽。
算力现状
讨论端侧推理,算力是一个无法回避的核心话题。我整理了常见端侧设备的算力范围(以TOPS,即每秒万亿次操作为单位):
- 智能手机:主流算力约为10~50 TOPS,代表芯片包括苹果A系列、高通骁龙、联发科天玑、华为麒麟。
- 智能汽车:分为座舱芯片和智驾芯片。座舱芯片如高通SA系列(8155P约8 TOPS,8295P约30 TOPS,8775P约70 TOPS)。智驾芯片如英伟达Orin(单颗约250 TOPS),以及蔚来神玑(单颗1000 TOPS)、小鹏图灵(单颗750 TOPS)等国产芯片。
- 可穿戴设备:如智能眼镜、智能手表。旗舰款智能眼镜(如高通AR1+ Gen1)算力约1 TOPS,旗舰智能手表(苹果、华为麒麟A2、高通W5)算力通常不到1 TOPS。
- 智能家居与IoT设备:如晶晨S905X5、全志V853等,算力通常只有几TOPS。
由此可见,各类端侧设备的芯片算力已不容小觑,部分场景下算力甚至相当可观,这为端智能在当前及未来的广泛应用奠定了坚实的硬件基础。
模型量化和蒸馏
要将机器学习模型部署到端侧,通常需要对模型体积和计算需求进行优化。模型量化和知识蒸馏是两种主流优化手段。主流的机器学习框架(如PyTorch、TensorFlow、HuggingFace)均已提供良好支持,本文旨在厘清这两项技术的基础概念。
模型量化
模型量化是模型部署前的常见优化手段,其核心是将模型权重和激活值从高位宽(如FP16浮点数)转换为低位宽(如INT8整数)表示,从而大幅降低计算开销和内存占用。
量化方法分类
按量化时机分类
- 训练后量化:对已完成训练的模型进行量化。无需完整训练数据集,仅需少量校准数据,计算成本低。但可能因逐层独立量化而导致精度损失较大。
- 量化感知训练:在训练过程中模拟量化操作,使模型适应量化环境。优点是精度高,但计算成本也相对较高。
通常,部署前会对模型进行训练后量化,以获得体积更小、推理更快的模型。
按函数形状分类
- 线性量化:采用均匀的量化间隔将浮点数值线性映射到整数范围(例如将FP16范围映射到INT8的[-128, 127])。
- 非线性量化:根据数值分布非均匀划分量化区间(例如对小数值划分更精细)。通常使用查表、对数或分段函数进行映射。
两者的目的都是为了在不同数据分布下,最大限度地减少精度损失。
按零点分类
“零点”是非对称量化中的一个关键参数,用于将浮点数中的“0”映射到整数范围内的某个值,以更好地处理非对称数据分布。
- 对称量化:零点为0,适用于数据在0两侧均匀分布的情况。
- 非对称量化:当激活值范围集中在0以上时,对称量化会浪费一半的整数表示范围。引入零点作为偏移量,可以将数据重新映射到完整的整数范围(如[-128, 127]),从而保持精度。
大模型量化方法
在大模型推理中,通常会针对prefill和解码两个阶段采取不同的量化策略。
Prefill阶段
Prefill阶段会并行处理所有输入token,主要进行矩阵乘法运算。其计算延迟受计算精度影响较大,因此通常会对权重和激活值同时进行量化。
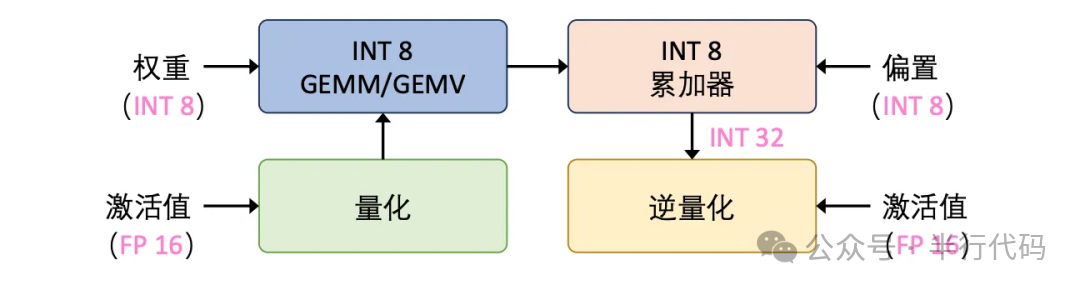
Decode阶段
解码阶段以自回归方式逐个生成token,主要进行矩阵向量乘法。其延迟主要受权重加载影响,因此通常仅量化权重,而保持激活值为高精度。
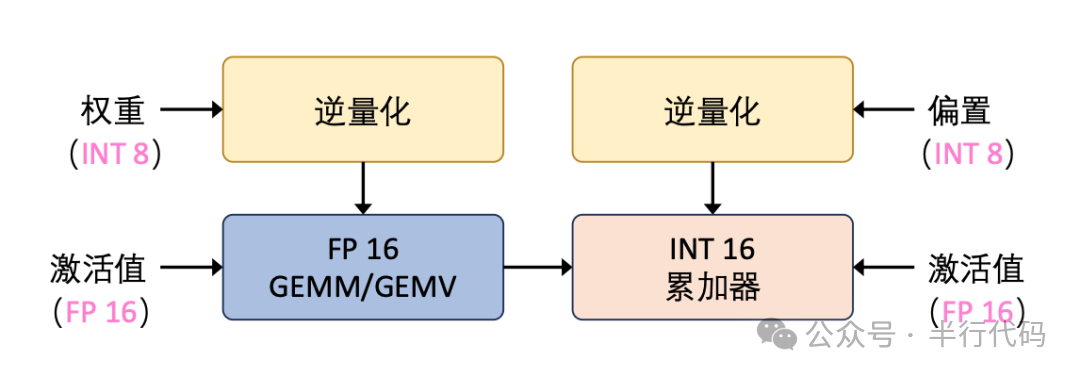
模型知识蒸馏
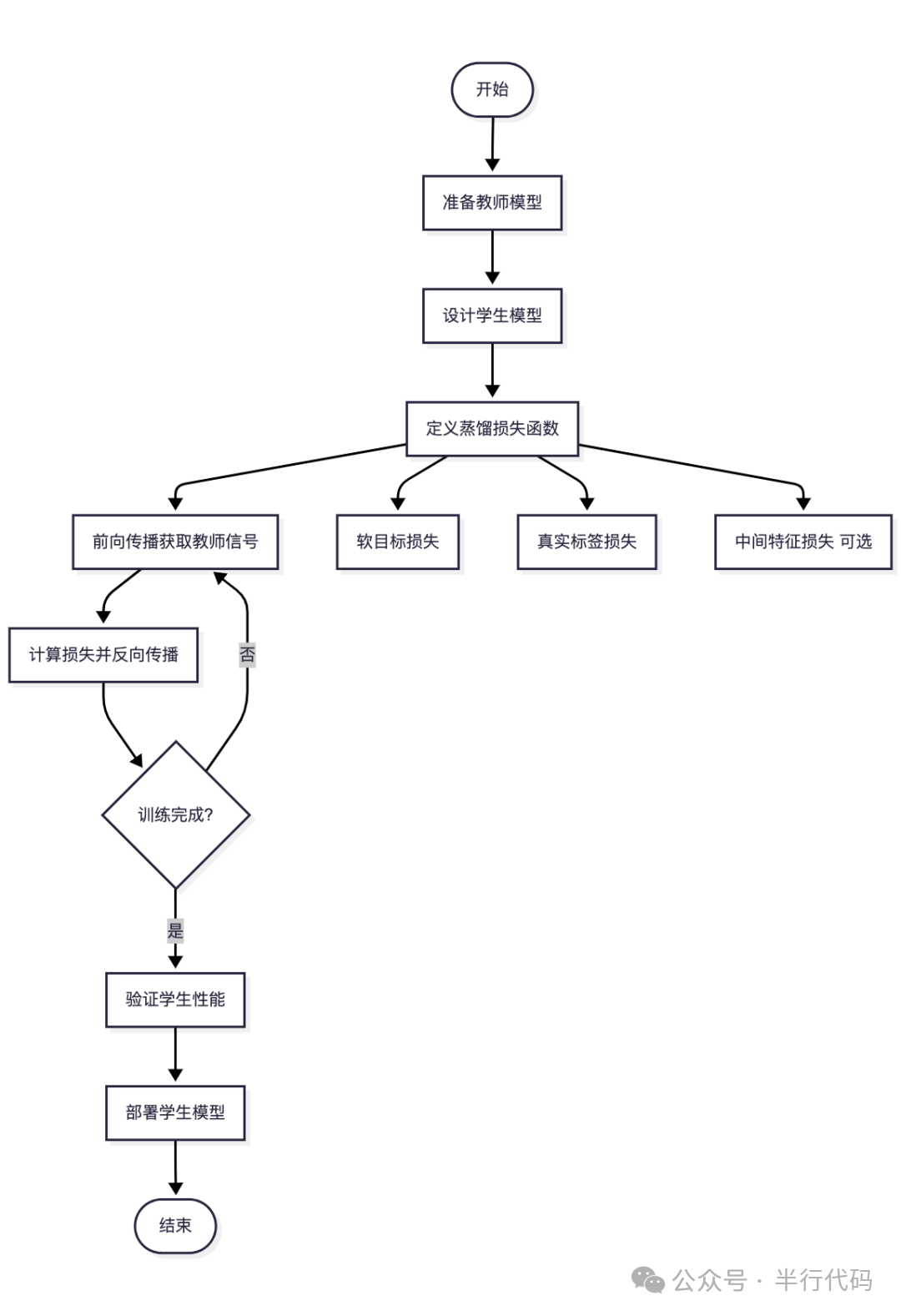
知识蒸馏是另一种常见的模型压缩方法,其核心思想是将一个大型“教师模型”的知识迁移到一个较小的“学生模型”中。根据能否访问教师模型的内部结构,可分为白盒蒸馏和黑盒蒸馏。
- 白盒知识蒸馏:学生模型可以完全访问教师模型的内部输出(如logits)、中间层特征表示甚至梯度信息,能够模仿更细粒度的知识。
- 黑盒知识蒸馏:学生模型只能访问教师模型的输入和最终输出。这种方式有助于保护教师模型的知识产权和隐私。
知识蒸馏的标准流程如下图所示,其中“中间特征损失”仅存在于白盒蒸馏中:
端侧模型推理
ONNX
ONNX和ONNX Runtime
ONNX(开放式神经网络交换格式)是一种开放、通用的深度学习模型表示标准。它允许将PyTorch、TensorFlow等主流框架训练的模型统一导出为.onnx格式文件,已成为不同框架间模型转换的事实标准中间格式。
以下是将BERT模型从PyTorch导出为ONNX格式的示例代码:
import torch
from transformers import AutoModel, AutoTokenizer, AutoConfig, BertForMaskedLM
def main():
tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')
model = BertForMaskedLM.from_pretrained('bert-base-chinese')
model.eval()
text='北京是[MASK]国的首都'
inputs = tokenizer(text, return_tensors='pt')
input_names = ['input_ids','attention_mask', 'token_type_ids']
output_names = ['logits']
//导出.onnx
torch.onnx.export(
model,
args=(inputs["input_ids"], inputs["attention_mask"], inputs["token_type_ids"]),
f='results/onnx/model.onnx',
input_names=input_names,
output_names=output_names,
do_constant_folding=True,
opset_version=14,
dynamic_axes={
"input_ids": {0: "batch", 1: "sequence"},
"attention_mask": {0: "batch", 1: "sequence"},
"token_type_ids": {0: "batch", 1: "sequence"},
"logits": {0: "batch", 1: "sequence"},
},
training=torch.onnx.TrainingMode.EVAL,
verbose=False
)
ONNX文件基于Protocol Buffers定义,核心是一个GraphProto对象,包含输入/输出张量列表、算子节点列表和常量权重等。通过工具(如netron.app)可以可视化其图结构,即便是BERT模型的图结构也已相当庞大。
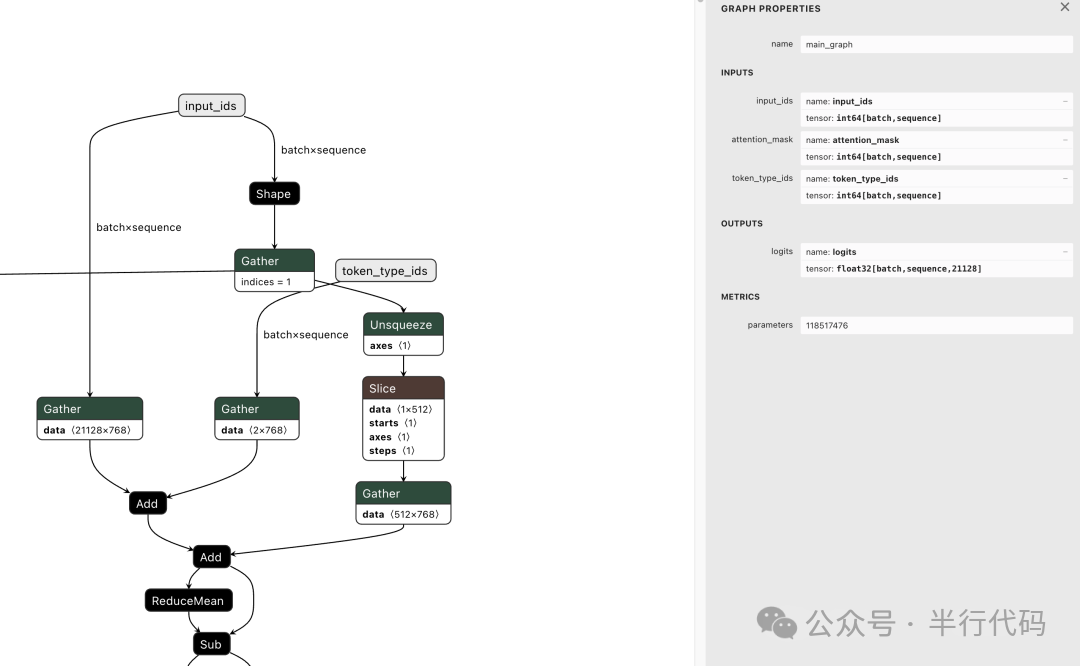
ONNX支持设置动态Shape,以避免推理时因输入尺寸固定而报错。上图也展示了BERT模型输入张量的动态维度设置。
ONNX Runtime是官方的跨平台推理引擎,支持包括Android/iOS在内的多种平台。以下是在Android工程中使用ONNX Runtime进行BERT推理的Kotlin代码示例:
private val session: OrtSession = OrtEnvironment.getEnvironment().createSession(modelFile.absolutePath, OrtSession.SessionOptions())
fun forward(text: String) {
val tokens: List<String> = tokenizer.tokenize(text)
val inputIds : LongArray = tokens.map { tokenizer.tokenToId(it).toLong() }.toLongArray()
val seqLen = inputIds.size
val attentionMask = LongArray(seqLen){1}
val tokenTypeIds = LongArray(seqLen) {0}
val environment = OrtEnvironment.getEnvironment()
val inputIdsTensor = OnnxTensor.createTensor(
environment, arrayOf(inputIds)
)
val attentionMaskTensor = OnnxTensor.createTensor(
environment, arrayOf(attentionMask)
)
val tokenTypeIdsTensor = OnnxTensor.createTensor(
environment, arrayOf(tokenTypeIds)
)
val ortInputs = mapOf(
"input_ids" to inputIdsTensor,
"attention_mask" to attentionMaskTensor,
"token_type_ids" to tokenTypeIdsTensor
)
// 寻找[MASK] 位置
val maskIndex = inputIds.indexOf(103)
// 推理
val outputs = session.run(ortInputs)
val logitsTensor: OnnxTensor? = (outputs.get("logits") as? Optional<OnnxTensor>)?.get()
logitsTensor?.let {logitsTensor->
val logits = logitsTensor.value as Array<Array<FloatArray>>
val maskLogits = logits[0][maskIndex]
val probs = softmax(maskLogits)
// 取出top5 [MASK] 位置概率
val topK = getTopK(probs, 5)
val results = topK.map { (id, prob) ->
tokenizer.idToToken(id) to prob // 词表映射
}
}
}
ONNX Runtime内存管理与架构设计
ONNX Runtime采用多层内存分配策略来优化内存使用:
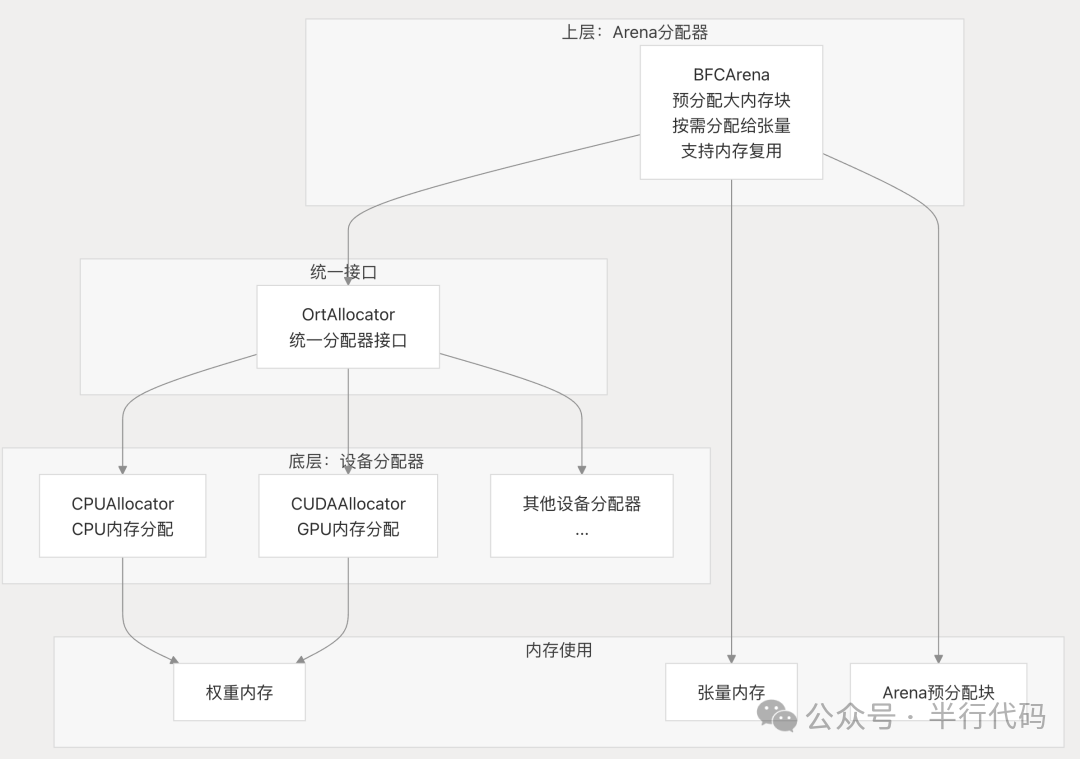
- 上层Arena分配器:预分配大块内存,按需分配给张量使用,支持内存复用,减少推理过程中的频繁分配。
- 底层设备分配器:为权重内存、Arena预分配块等提供统一接口,处理不同设备(CPU、GPU)的内存分配与释放。
这种设计减少了内存波动,增强了可配置性和可扩展性,但初始化时有内存规划开销,且Arena可能存在内存浪费。
ONNX Runtime通过Execution Provider机制支持多平台后端。EP将ONNX模型算子映射到特定硬件后端的实现上,例如NVIDIA CUDA、Android/iOS NNAPI/CoreML、高通QNN等。
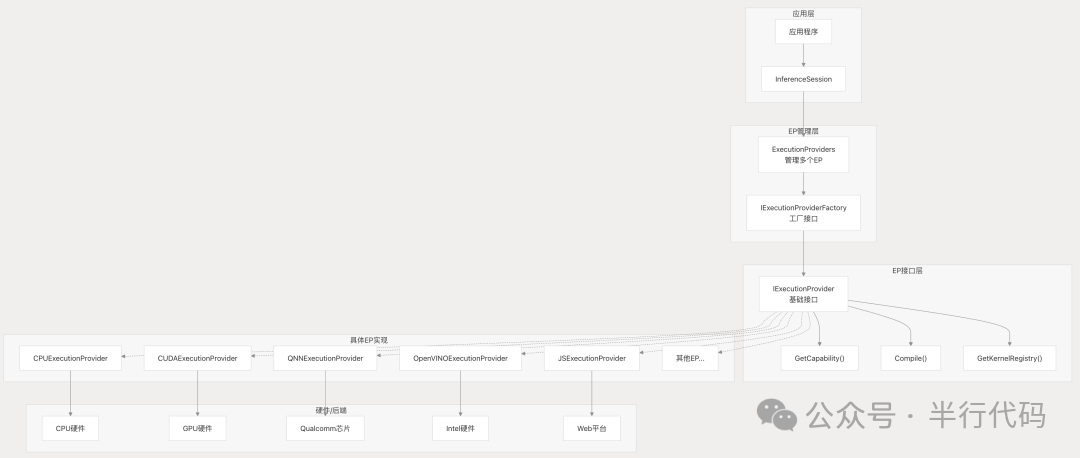
对于NPU等需要首次编译模型的硬件平台,ONNX Runtime引入了EP Context机制,将耗时的编译结果缓存起来,后续推理直接加载缓存,跳过重复编译。
Google AI Edge - LiteRT
Google推出的边缘计算推理框架LiteRT,是其TensorFlow Lite框架的继承者,支持高性能ML推理,并通过LiteRT-LM支持生成式AI。它支持部署.tflite模型,流程通常包括获取/准备模型、(可选)优化、集成到边缘平台并选择后端。

推理流程
在Android上,可以使用Kotlin代码进行LiteRT推理:
val compiledModel = CompiledModel.create("/path/to/mymodel.tflite",CompiledModel.Options(Accelerator.CPU))
val inputBuffers = compiledModel.createInputBuffers()
val outputBuffers = compiledModel.createOutputBuffers()
inputBuffers.get(0).writeFloat(input0)
inputBuffers.get(1).writeFloat(input1)
// 推理并读取输出
compiledModel.run(inputBuffers, outputBuffers)
val output = outputBuffers.get(0).readFloat()
inputBuffers是一个List<TensorBuffer>,用于存放输入张量。以BERT模型为例,需要将inputIds、attentionMask、tokenTypeIds通过TensorBuffer#writeFloat写入。
硬件加速与内存管理
LiteRT支持GPU和NPU硬件加速。
- GPU加速:创建GPU友好的缓冲区,实现GPU内存零拷贝,并支持异步执行以最大化并行性。
- NPU加速:提供统一接口对接不同厂商NPU(如高通QNN、联发科NeuroPilot),提升性能并支持零拷贝缓冲区。支持AOT(提前编译,适合大模型)和JIT(运行时编译,适合小模型)两种模式。
LiteRT通过Delegate机制实现硬件加速。Delegate是一种可插拔接口,每类Delegate对应特定的优化后端。在模型加载时,LiteRT会将计算图中可加速的子图委托给对应的Delegate进行编译和执行,不支持的算子则回退到CPU。
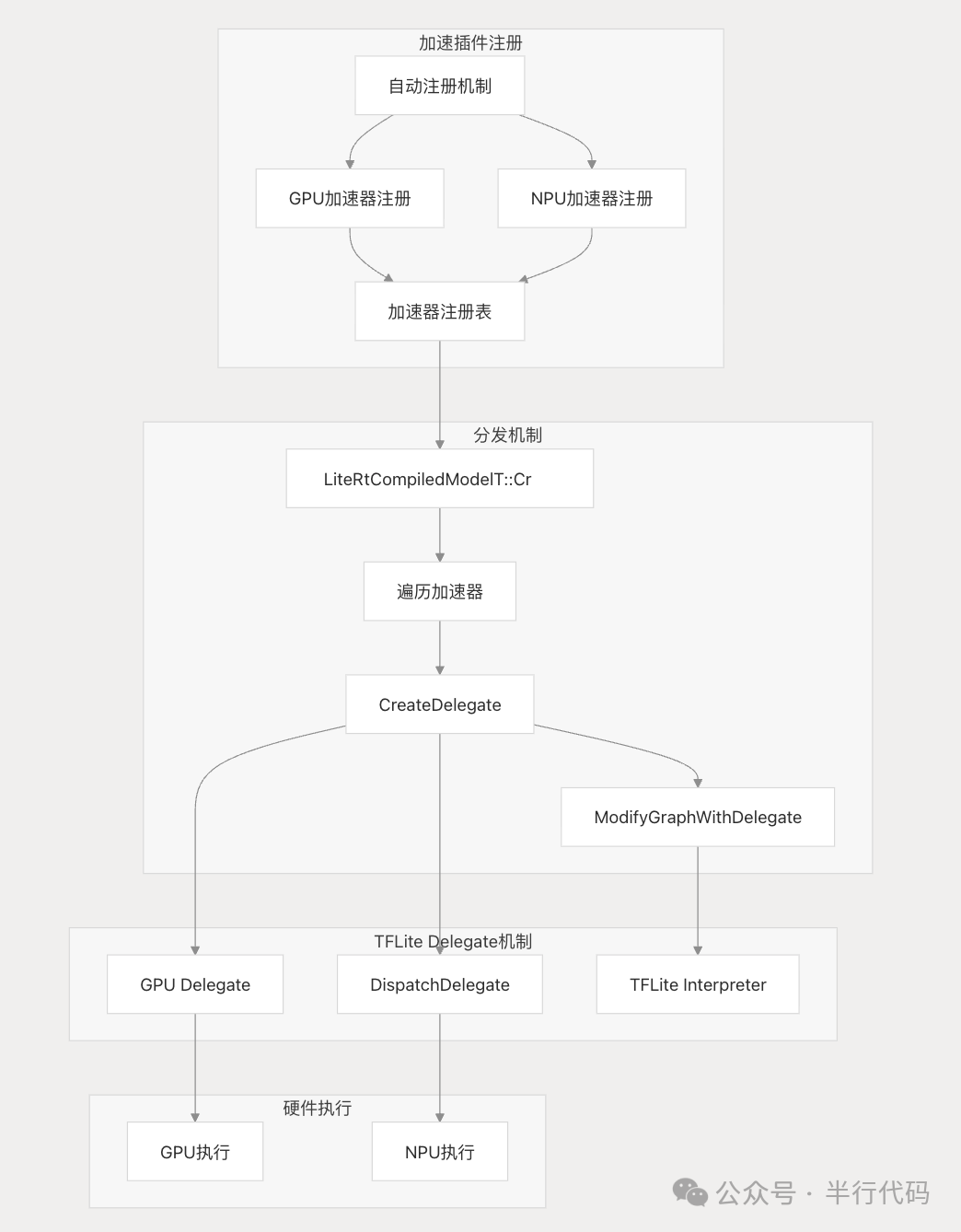
LiteRT设计了多种内存分配策略来优化内存使用:
typedef enum TfLiteAllocationType {
kTfLiteMemNone = 0,
kTfLiteMmapRo,
kTfLiteArenaRw,
kTfLiteArenaRwPersistent,
kTfLiteDynamic,
kTfLitePersistentRo,
kTfLiteCustom,
kTfLiteVariantObject,
kTfLiteNonCpu,
} TfLiteAllocationType
| 类型 |
含义 |
用途 |
kTfLiteMmapRo |
只读内存映射 |
加载模型权重,节省内存 |
kTfLiteArenaRw |
临时读写的内存池 |
中间激活值 |
kTfLiteArenaRwPersistent |
持久化读写内存池 |
推理过程中需要保存的状态 |
kTfLiteDynamic |
动态分配内存 |
动态shape张量 |
kTfLitePersistentRo |
准备阶段预计算张量内存 |
模型准备阶段计算的张量 |
kTfLiteCustom |
自定义内存 |
外部传入缓冲区,例如摄像头帧 |
kTfLiteVariantObject |
C++类型擦除对象 |
存储任意C++对象 |
kTfLiteNonCpu |
非CPU内存 |
GPU/NPU的零拷贝张量 |
硬件加速
GPU加速
CPU推理通常以逐层顺序调度方式执行,并行能力有限。GPU则拥有大量并行计算单元,非常适合计算密集型的推理任务。移动端GPU加速通常基于OpenGL、OpenCL、Vulkan或Apple Metal API。
以LiteRT为例,可以在创建模型时指定启用GPU加速:
ERT_ASSIGN_OR_RETURN(auto env, Environment::Create({}));
LITERT_ASSIGN_OR_RETURN(auto compiled_model, CompiledModel::Create(env, model, kLiteRtHwAcceleratorGpu));
并在代码中注册GPU支持的特定算子。
GPU后端会在初始化时自动注册。在Android平台上,注册顺序通常为:通用GPU(OpenGL)加速、OpenCL加速、WebGPU加速、Vulkan加速。
- OpenGL:生态成熟,普及度高,主要用于图形渲染。
- OpenCL:用于通用并行计算,常见于科学计算和机器学习预处理。
- Vulkan:新一代高性能、低开销的图形与计算API。
那么,为什么并非所有推理都跑在GPU上呢?主要原因如下:
- 开销问题:GPU启动需要数据拷贝、着色器/内核编译、CPU-GPU同步等开销。对于小模型,这些开销可能超过计算本身。
- 内存带宽:移动设备上GPU与CPU共享内存,带宽有限,频繁的数据拷贝会抵消加速收益。
- 功耗:GPU功耗显著高于CPU。
- 兼容性与碎片化:不同设备对OpenGL/OpenCL/Vulkan的支持程度差异大。
- 开发调试难度:GPU编程和调试比CPU更复杂。
因此,针对NPU加速或深度优化CPU推理,有时是比通用GPU加速更优的选择。
NPU加速
NPU是专为AI计算设计的硬件加速单元,针对矩阵乘法、卷积等神经网络操作进行了高度定制化优化,在能效比上远超CPU和GPU。
同一AI任务在手机硬件上不同单元的对比:
| 维度 |
CPU |
GPU |
NPU |
| 架构特点 |
少核(4-8),高单线程性能,强控制逻辑 |
多核(数百数千),擅长并行计算 |
专用AI核心,无通用指令集 |
| 推理速度 |
慢,主要依赖软件库 |
中等 |
快,硬件原生支持 |
| 能耗 |
中高,负载高易发热 |
高 |
非常低 |
| 内存带宽 |
频繁访问内存 |
高带宽(但移动端共享内存) |
片上SRAM + 数据流架构,减少外部访问 |
| 精度支持 |
支持FP32/FP64,效率低 |
支持FP16/INT8 |
支持INT8/INT4/FP16,部分支持混合精度 |
从能效比看,NPU是移动端模型推理的首选。市面上主流NPU及配套SDK包括:高通骁龙的AI Engine Direct(QNN)、联发科天玑的NeuroPilot、华为麒麟的达芬奇架构CANN、苹果的Apple Neural Engine(ANE)。
高通QNN
理解QNN前,需了解其前身Qualcomm Snapdragon Neural Processing SDK(SNPE)。SNPE需要将模型转换为专用的.dlc格式,且整个模型必须部署在单一后端。为充分发挥骁龙平台异构硬件(CPU/DSP/NPU)的协同优势,高通推出了QNN。QNN提供统一的硬件抽象层,支持算子级细粒度调度,实现真正的异构计算。
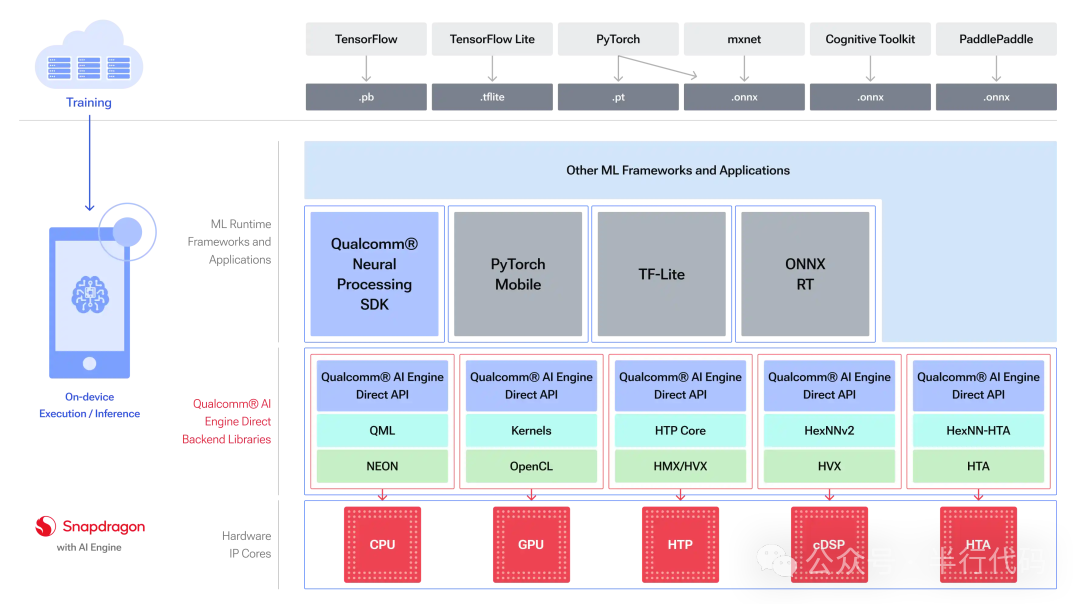
QNN通过转换工具将PyTorch、TFLite、ONNX等格式的模型转为中间表示,经量化等优化后,最终生成QNN模型API调用(cpp文件)。
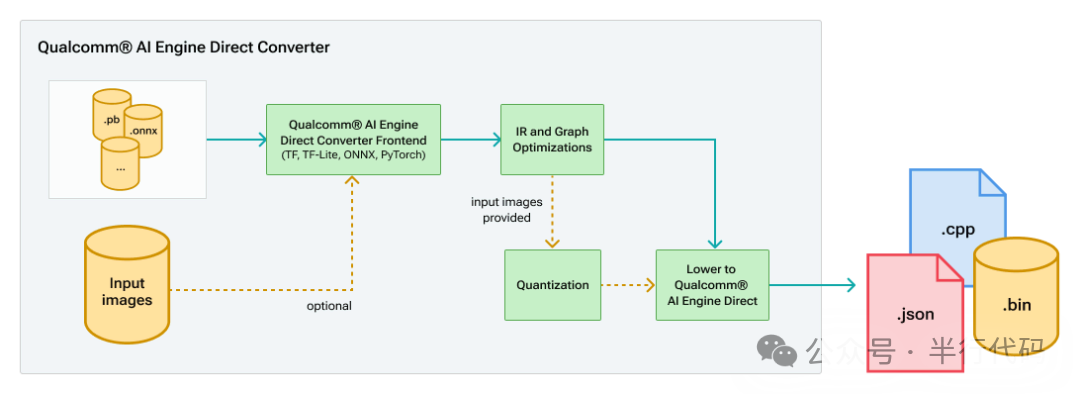
使用生成的so库进行推理时,首次初始化会因图编译而耗时较长。编译完成后可将二进制缓存至本地,或使用qnn-context-binary-generator工具进行离线预编译以加速首次运行。
华为CANN
华为CANN包含ATC模型转换工具和acl API库。ATC在转换过程中会进行算子调度、权重重排、内存优化等操作。
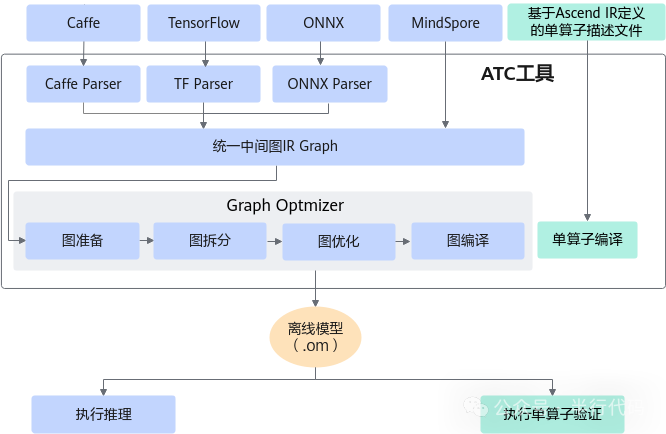
- 开源框架模型通过解析器转为统一的IR Graph。
- IR Graph经过一系列优化后,编译为
.om离线模型。
- 通过acl API加载
.om模型并执行推理。
端侧可使用C++版本的acl API,模型加载与推理代码示例如下:
// 假设以下变量已在类/函数中声明:
// uint32_t modelId_;
// void* modelMemPtr_ = nullptr;
// void* modelWeightPtr_ = nullptr;
// aclmdlDesc modelDesc_ = nullptr;
// aclmdlDataset* input_ = nullptr;
// aclmdlDataset* output_ = nullptr;
const char* omModelPath = "../model/xx.om";
// Step 1: 查询模型所需内存
size_t modelMemSize_ = 0, modelWeightSize_ = 0;
aclError ret = aclmdlQuerySize(omModelPath, &modelMemSize_, &modelWeightSize_);
// Step 2: 分配模型内存
ret = aclrtMalloc(&modelMemPtr_, modelMemSize_, ACL_MEM_MALLOC_HUGE_FIRST);
ret = aclrtMalloc(&modelWeightPtr_, modelWeightSize_, ACL_MEM_MALLOC_HUGE_FIRST);
// Step 3: 加载模型
ret = aclmdlLoadFromFileWithMem(omModelPath, &modelId_, modelMemPtr_, modelMemSize_, modelWeightPtr_, modelWeightSize_);
// Step 4: 获取模型描述
modelDesc_ = aclmdlCreateDesc();
ret = aclmdlGetDesc(modelDesc_, modelId_);
// Step 5: 准备输入
size_t modelInputSize = aclmdlGetInputSizeByIndex(modelDesc_, 0);
void* modelInputBuffer = nullptr;
ret = aclrtMalloc(&modelInputBuffer, modelInputSize, ACL_MEM_MALLOC_HUGE_FIRST);
ret = aclrtMemcpy(modelInputBuffer, modelInputSize, inputBuff, modelInputSize, ACL_MEMCPY_HOST_TO_DEVICE);
input_ = aclmdlCreateDataset();
aclDataBuffer* inputData = aclCreateDataBuffer(modelInputBuffer, modelInputSize);
ret = aclmdlAddDatasetBuffer(input_, inputData);
// Step 6: 准备输出
output_ = aclmdlCreateDataset();
size_t outputSize = aclmdlGetNumOutputs(modelDesc_);
for (size_t i = 0; i < outputSize; ++i) {
size_t buffer_size = aclmdlGetOutputSizeByIndex(modelDesc_, i);
void* outputBuffer = nullptr;
ret = aclrtMalloc(&outputBuffer, buffer_size, ACL_MEM_MALLOC_HUGE_FIRST);
aclDataBuffer* outputData = aclCreateDataBuffer(outputBuffer, buffer_size);
ret = aclmdlAddDatasetBuffer(output_, outputData);
}
// Step 7: 执行推理
ret = aclmdlExecute(modelId_, input_, output_);
size_t outBufferSize = aclmdlGetOutputSizeByIndex(modelDesc_, 0);
void* hostOutput = malloc(outBufferSize);
aclrtMemcpy(hostOutput, outBufferSize,
aclGetDataBufferAddr(aclmdlGetDatasetBuffer(output_, 0)),
outBufferSize, ACL_MEMCPY_DEVICE_TO_HOST);
free(inputBuff)
Android NNAPI
Android NNAPI是Android 8.1后Google推出的硬件加速方案,提供了一套C API用于构建和执行模型推理图。它定义了通用算子、编译-执行流程及厂商驱动接口标准。硬件厂商基于此实现自己的驱动,缺乏驱动的设备则回退到CPU执行。NNAPI旨在统一访问五花八门的硬件加速器,实现“一次开发,处处加速”。
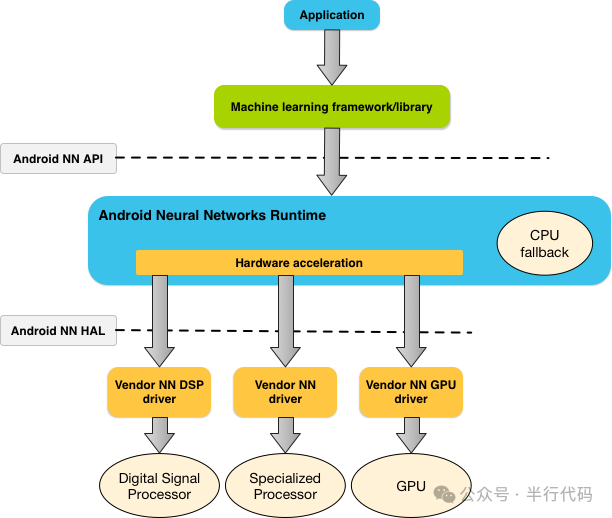
然而,现实挑战重重:厂商实现质量参差不齐,部分性能甚至不及CPU;缺乏有效的调试工具,开发如同黑盒;厂商更倾向于推广自家方案,不愿被Google标准束缚。因此,NNAPI已于Android 15正式弃用。
端侧大语言模型
端侧大模型推理优化
大语言模型参数量巨大,在端侧部署面临独特挑战:资源约束严格(模型权重可能超过设备可用内存),且需要专门的推理优化(如模型量化、KV Cache管理)。
LLM通常以自回归方式生成文本。给定提示词(prompt)后,推理分为两个阶段:
- Prefill(预填充)阶段:模型一次性并行处理整个prompt,计算所有token的上下文表示,并初始化生成所需状态。
- Decode(解码)阶段:模型以自回归方式逐个生成输出token,每一步都基于之前所有token进行预测。
:::tips
主流大模型基于Transformer的自注意力机制。每个词会生成三个关键向量:Q(查询)、K(键)、V(值)。在自回归过程中,理解整个句子的语义需要依赖前面所有词语的K、V向量。
:::
为避免每生成一个新token都重新计算整个历史序列的注意力(产生大量重复计算),引入了KV Cache机制:
- 在Prefill阶段,计算并缓存输入prompt中每个token的K、V向量。
- 在Decode阶段,每生成一个新token,只需计算当前token的Q向量,然后与缓存中的所有历史K、V进行注意力计算。
KV Cache虽大幅提升效率,但也占用大量内存(尤其在生成长文本时),成为端侧优化的重点。整个推理过程可简化为下图:

llama.cpp
llama.cpp是一个用纯C/C++实现的高效大语言模型推理开源项目,无需依赖GPU或深度学习框架。它高性能、轻量级、跨平台,除Llama系列外,还支持GPT、Qwen2.5及LLaVA等多模态模型。
其工程架构清晰:
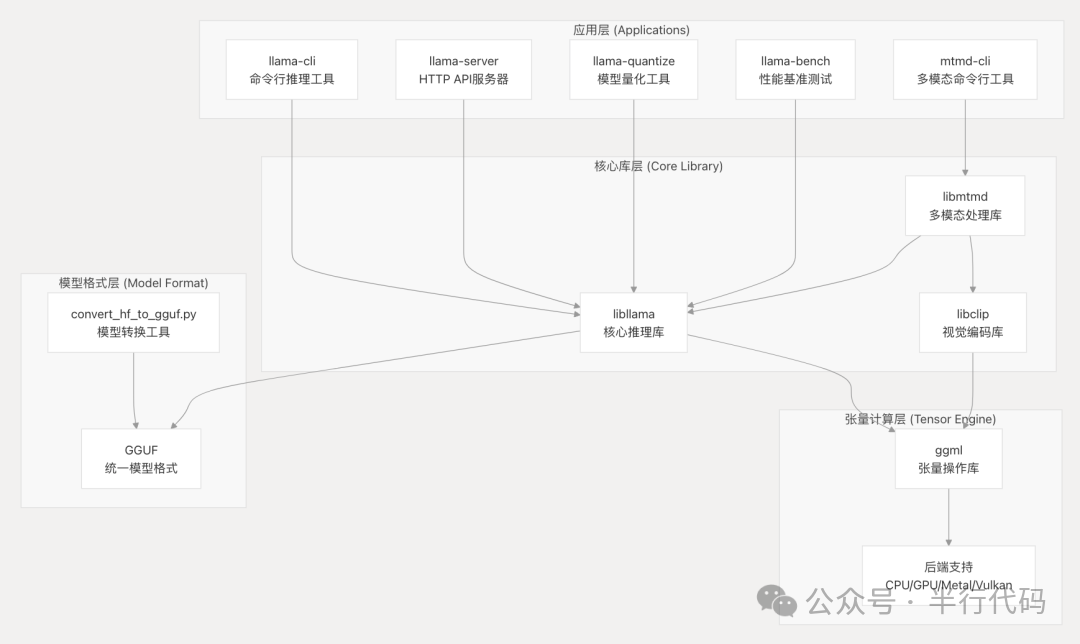
核心包括推理库、底层ggml张量计算引擎以及模型格式转换工具(统一转为GGUF格式)。
推理流程
以下简述在Android端使用llama.cpp(C++核心)进行推理的关键步骤:
- 初始化与加载模型
// 初始化环境
ggml_backend_load_all_from_path(path_to_backend);
llama_backend_init();
// 加载GGUF模型
const auto model_path = env->GetStringUTFChars(jmodel_path, 0);
auto model = llama_model_load_from_file(model_path, model_params);
// 准备阶段,初始化上下文等对象
auto *context = init_context(g_model);
g_context = context;
g_batch = llama_batch_init(BATCH_SIZE, 0, 1);
g_chat_templates = common_chat_templates_init(g_model, "");
g_sampler = new_sampler(DEFAULT_SAMPLER_TEMP);
2. **Prefill流程**
Prefill阶段会对系统提示词和用户输入进行模板化处理和分词,然后分批解码(`decode_tokens_in_batches`)。模板拼接逻辑在`chat.cpp`中,会根据模型元数据区分不同模型的提示词格式。
3. **Decode自回归过程**
```cpp
while (true) {
generateNextToken()?.let { utf8token ->
if (utf8token.isNotEmpty()) emit(utf8token)
} ?: break
}
generateNextToken的核心逻辑包括:采样获取下一个token ID,接受该token,准备下一次decode的输入,执行解码,并将token转换为字符串输出。核心推理函数llama_decode的内部流程涉及批次验证、分配、循环处理微批次等步骤。

KV Cache优化
为应对超长序列和计算图节点数限制,llama.cpp会将输入token拆分为多个“微批次”独立处理,并共享KV Cache。KV Cache根据模型类型采用多态实现,如标准连续缓存、滑动窗口缓存等。
并行计算
llama.cpp采用异步计算与同步采样相结合的设计,以平衡吞吐量与结果正确性。
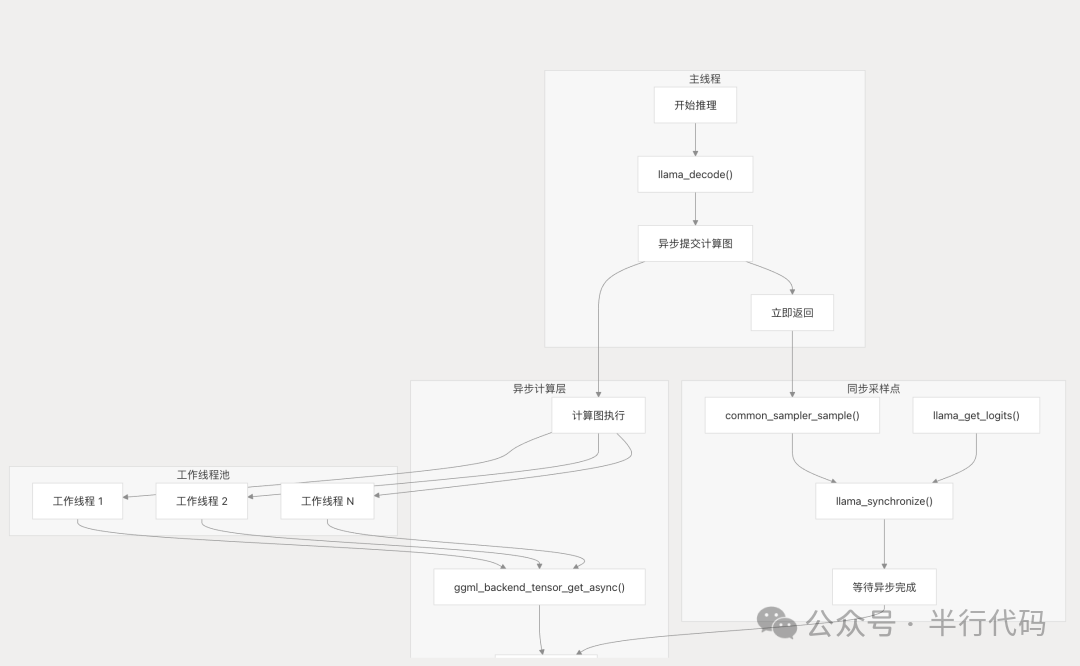
其底层实现了自定义的线程池结构(ggml_threadpool),在图计算时进行任务调度。
LiteRT-LM
LiteRT-LM是Google基于LiteRT框架开发的大语言模型推理框架(截至2025年12月仍处于Alpha阶段)。它将分词、Prefill、Decode等步骤显式拆分为组件,通过Pipeline组合,并提供状态管理和内存复用。支持Gemma3-1B、Qwen2.5-1.5B等模型,以及CPU、GPU、NPU多种后端。
架构设计
核心API包括:
- Engine:负责加载模型及资源(如分词器),创建会话。
- Conversation:表示一次有状态的对话,封装了Session,处理复杂任务如上下文维护、Prompt模板等。
- Session:提供会话的底层控制,支持手动管理Prefill、Decode等细节。
框架采用五层设计(用户接口、核心运行时、执行后端、组件层、基础层),架构清晰。
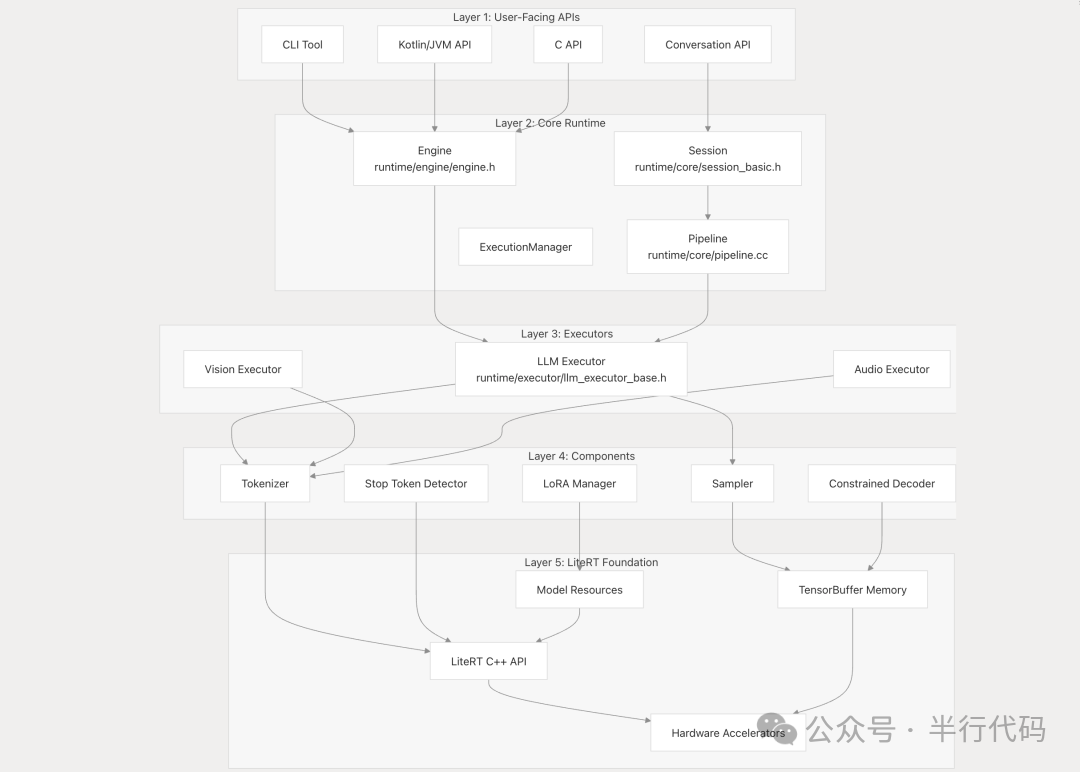
Pipeline定义了Prefill、Decode、流式解码等核心组件,作为会话层与执行器的中间层。
推理过程
Prefill和Decode任务被提交到线程池中执行,当前线程仅负责任务调度。具体执行由LlmExecutor的不同子类(静态Shape、动态Shape、NPU专用)完成。
为处理长序列,LiteRT-LM使用“工作组”机制将长序列拆分为多个子任务,优化内存效率。
KV Cache与内存管理
在GPU等并行硬件上,同时读写同一内存区域可能导致数据竞争。LiteRT-LM的静态Shape执行器采用了双缓冲区机制来解决此问题:
input_kv_cache_buffers_ = &kv_cache_buffers_1_;
output_kv_cache_buffers_ = &kv_cache_buffers_2_;
每次KV Cache更新后,写入输出缓冲区,然后交换输入/输出缓冲区指针。这避免了数据竞争,并通过指针交换实现了零拷贝,性能高效。
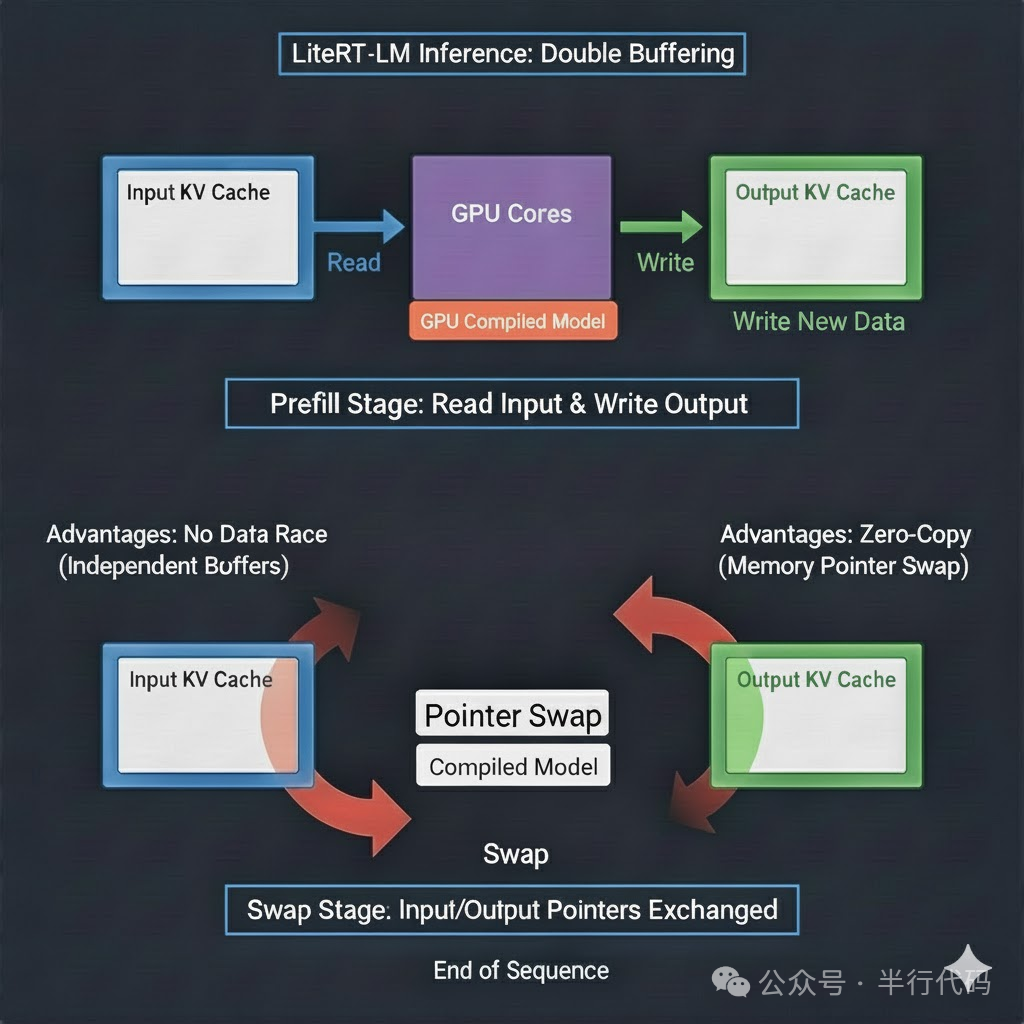
对于动态Shape执行器,由于shape可能频繁变化,通常采用单缓冲区,并在容量不足时进行动态扩容。
高度封装方案
Google还提供了一些集成度更高的端侧AI解决方案,如MediaPipe和ML Kit。
MediaPipe提供了一套库和工具,用于快速接入通用的机器学习场景。
- MediaPipe Tasks:部署解决方案的跨平台API。
- MediaPipe模型:预训练模型库。
开发者可以使用提供的或自己的.tflite模型(需保持输入兼容)。MediaPipe还提供了Model Maker模型定制工具和在线Studio体验平台。其底层技术基于LiteRT框架。
目前支持生成式AI、视觉、文本、音频等数十种任务类型,为常见AI需求提供了开箱即用的解决方案。
ML Kit
ML Kit是Google推出的移动端SDK,封装了一系列端侧AI功能,包括生成式AI(摘要、改写)、视觉(OCR、人脸检测)、自然语言(翻译、智能回复)等。
在Android上,模型文件可通过Google Play服务动态下载和更新,不计入应用存储空间。这非常适合海外通过Google Play分发的应用,能有效控制应用体积并简化模型更新。
端模型资源部署
Google Play for On-device AI
端侧模型体积庞大,不可能全部打包进APK,动态下发是必然选择。Google Play for On-device AI库融合了App Bundle和Google Play的分发优势,支持自定义模型分发规则(如按SoC、设备型号、RAM等条件)。
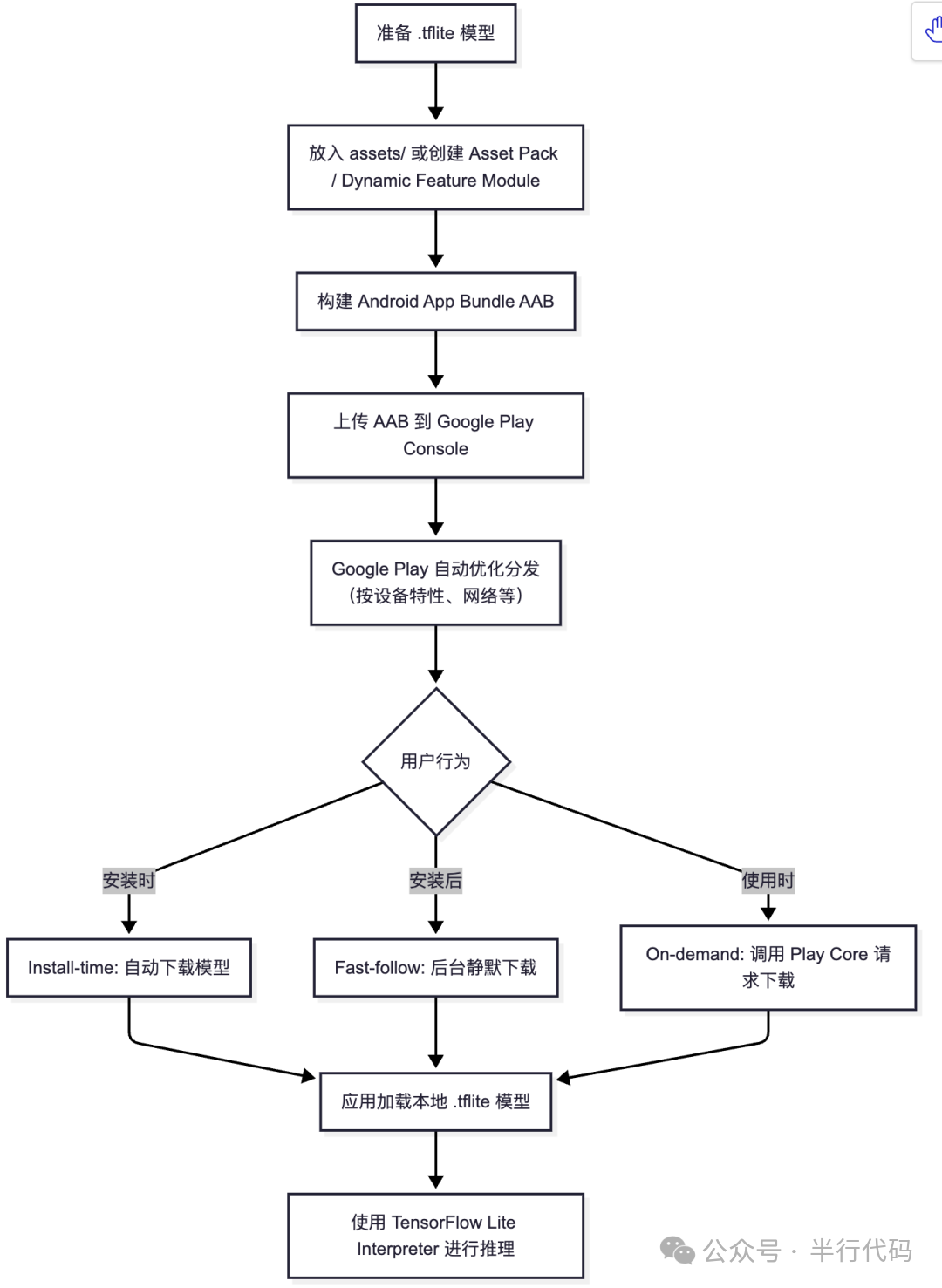
下载成功后,通过AiPackManager API获取模型路径。这套体系为Android开发者,特别是面向全球市场的应用,带来了诸多好处:有助于隐私合规、节省CDN带宽成本、并利用Google Play的全球CDN网络提升下载性能与可靠性。该方案目前处于Beta阶段,值得海外开发者关注。
端侧AI技术的蓬勃发展,离不开模型优化、推理框架和硬件加速三者的协同演进。从基础的量化蒸馏,到高效的推理引擎(如ONNX Runtime、LiteRT),再到专为AI设计的NPU硬件,共同推动了智能 & 数据 & 云能力向边缘设备的延伸。希望本文的解析能为你探索端侧AI的实践之路提供有价值的参考。如果你想了解更多深度技术解析或与同行交流,欢迎访问云栈社区。
 发表于 2026-1-19 06:10:41
|
查看: 314|
回复: 0
发表于 2026-1-19 06:10:41
|
查看: 314|
回复: 0
