FAST-Prefill 这项工作非简单映射算法,本质是硬件-算法深度协同的范例,其基于 Flex-Prefill 的计算模式与数据流特征,定制数据通路与访存策略。其不仅提供实用加速方案,更确立了一种方法论启示——针对特定工作负载,精巧的架构设计往往比通用算力堆砌更高效。
关键词:FPGA 加速、稀疏注意力、长上下文 LLM、预填充阶段、动态稀疏模式
当大语言模型需要处理 128K Token 的长文本时,预填充阶段的计算量会爆炸式增长。FAST-Prefill 提出了一种基于 FPGA 的动态稀疏注意力加速方案,通过创新的硬件架构设计,在保持模型精度的同时实现了 2.5 倍的 TTFT 速度提升和 4.5 倍的能效提升。
想象一下,让大语言模型阅读一本数百页的小说并回答其中的问题。在这个过程中,模型首先需要处理整本书的内容——这就是 LLM 推理中的“预填充阶段”。当输入文本变长时,预填充阶段的自注意力计算量呈平方级增长,成为整个推理过程的性能瓶颈。
近年来,稀疏注意力技术被提出来解决这个问题。它的核心思想很直观:每个Token不需要与所有其他Token交互,只需关注其中的一小部分。但问题在于,这种稀疏模式是“动态”的——不同输入文本有不同的稀疏模式,同一个文本中不同的注意力头也有各自独特的模式。
这种动态特性让 GPU 陷入了尴尬境地:
- 一方面,生成稀疏索引需要复杂的控制流和数据依赖;
- 另一方面,稀疏的 KV 缓存访问模式导致数据重用率低、内存带宽利用率不足。
GPU 虽然计算能力强,但在这种内存密集型任务中难以发挥优势。这正是 FPGA(现场可编程门阵列)的机会所在。FPGA 具有可定制的存储层次和计算流水线,能够为特定工作负载设计专用的数据通路。来自南加州大学的研究团队在 FPGA’24 会议上提出的 FAST-Prefill,正是首个针对动态稀疏注意力长上下文预填充阶段的 FPGA 加速器。
本文将深入解读 FAST-Prefill 的工作机制,探讨它如何通过创新的硬件架构设计,在保持模型精度的同时,实现比 NVIDIA A5000 GPU 快 2.5 倍的性能提升和 4.5 倍的能效提升。

图 | FAST-Prefill: FPGA Accelerated Sparse Attention for Long Context LLM Prefill (来源:arXiv:2602.20515)
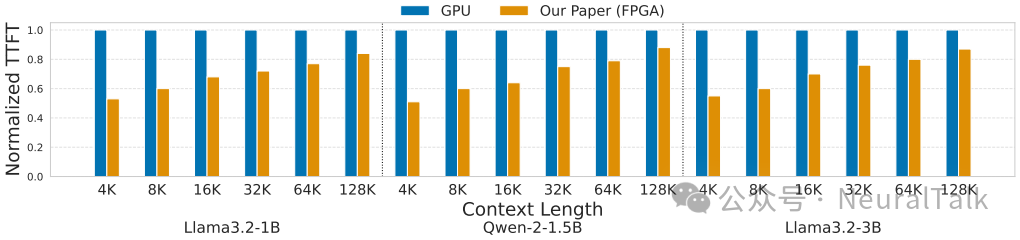
图 1 | FAST-Prefill 与基准 GPU 实现的首令牌生成时间(TTFT)对比。结果显示 FAST-Prefill 在所有模型和上下文长度下均表现更优,且随上下文长度增加优势更显著。
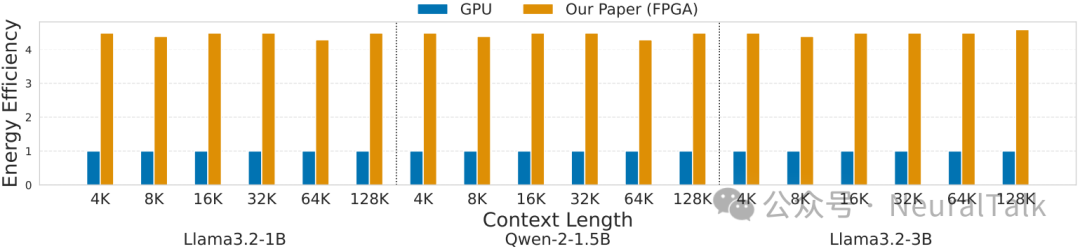
图 2 | FAST-Prefill 与基准 GPU 实现的能效对比。FAST-Prefill 凭借 FPGA 的低功耗特性与架构级的访存优化,实现了最高 4.5 倍的能效提升。
一、背景:理解 LLM 推理的两个阶段
在深入 FAST-Prefill 的设计之前,我们需要先理解 LLM 推理的基本流程。
1.1 预填充阶段 vs. 解码阶段
LLM 推理包含两个截然不同的计算阶段:
预填充阶段:模型处理完整的输入序列,生成第一个输出 Token。在这个阶段,输入是一个完整的 Token 序列 $X_{1:S}$,模型通过矩阵乘法生成 Query(Q)、Key(K)和 Value(V)矩阵:
$$Q = X W_q, \quad K = X W_k, \quad V = X W_v$$
其中 $W_q$、$W_k$、$W_v$ 是多头自注意力的权重矩阵。然后,模型计算因果多头自注意力:
$$\text{Attention}(Q,K,V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V$$
最后通过前馈网络(FFN)处理:
$$Y = \text{FFN}(\text{Attention}(Q,K,V))$$
解码阶段:模型自回归地逐个生成后续 Token,每次迭代只处理最新生成的 Token。这意味着预填充阶段的矩阵-矩阵乘法变成了解码阶段的矩阵-向量乘法。
对于长上下文应用如文档摘要、代码生成、多轮问答等,预填充阶段的计算复杂度随上下文长度 $S$ 呈平方级增长 $O(S^2)$,导致生成第一个 Token 的延迟(TTFT,Time To First Token)急剧增加。
1.2 动态稀疏注意力:解决方案与挑战
为了缓解这个问题,研究者提出了稀疏注意力。下图展示了 Flex-Prefill 算法的工作原理:将注意力矩阵划分为大小为 $b$ 的块,通常 $b=128$ 或 $256$,然后为每个注意力头选择一部分块进行计算。
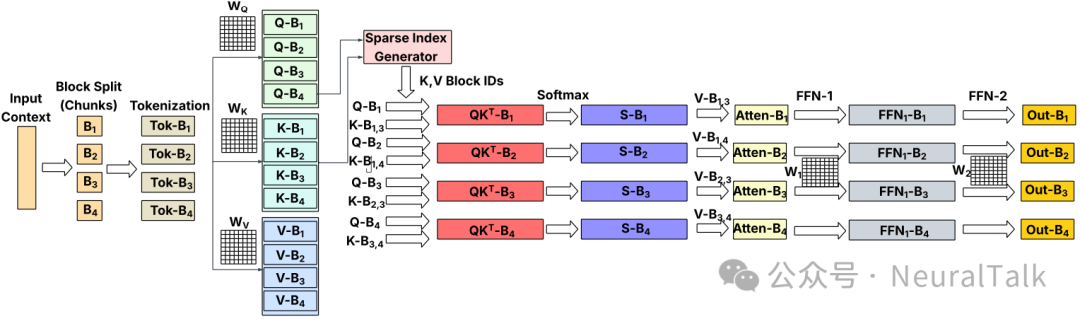
图 3 | 基于稀疏注意力的预填充工作流。每个查询块仅与稀疏索引指定的 KV 块交互,大幅减少计算量。
Flex-Prefill 算法为每个注意力头动态选择两种稀疏模式之一:
- 垂直-斜线模式:选择沿对角线或列的块
- 查询特定模式:块分布在注意力矩阵的不同行和列
算法通过计算 Jensen-Shannon 散度来决定每个头采用哪种模式,确保在计算效率和模型质量之间取得平衡。
这种动态稀疏注意力虽然大幅减少了计算量,但也带来了新的挑战——这正是 FAST-Prefill 要解决的核心问题。
二、三大核心挑战
研究团队识别出在 FPGA 上加速动态稀疏注意力的三个关键挑战:
2.1 挑战 1:稀疏索引生成产生大量中间张量
生成稀疏索引需要对所有 Key 块与最后一个查询块向量进行评分,以识别最相关的块。
以 128K Token的上下文长度为例,每个注意力头会产生 128×128K 的中间结果,超过 2GB 的存储需求。再加上 softmax、指数运算和块池化操作,总中间张量可达 4GB。
关键洞察:这些中间张量太大,无法存储在片上,而频繁的片外访问会爆炸式增加延迟。传统的算子融合技术在这里效果有限,因为它们主要融合逐元素操作,而非不同维度的操作。
2.2 挑战 2:稀疏模式依赖的 KV 缓存访问
KV 缓存的大小约为 3-4GB,只能存储在片外(HBM)。但稀疏注意力导致每个查询访问不同的 KV 向量子集,不像密集注意力那样所有查询都访问完整的 KV 缓存。
这带来三个问题:
- 无效的预取:预取时机至关重要——太早浪费片上资源,太晚导致流水线停顿
- 带宽利用率低:按需获取导致大量小块内存读取
- 重复获取:在组查询注意力中,KV 块在不同注意力头间缺乏重用
2.3 挑战 3:DSP 资源限制矩阵乘法吞吐量
长上下文推理需要大量块级矩阵乘法。
在 U280 FPGA 上,仅使用 DSP(数字信号处理器)最多只能实现 6 个 32×32 的脉动阵列,远远不足以并行处理所有矩阵乘法操作。
三、FAST-Prefill 的架构创新
面对这些挑战,FAST-Prefill 提出了一套完整的硬件解决方案。下图展示了整体架构:
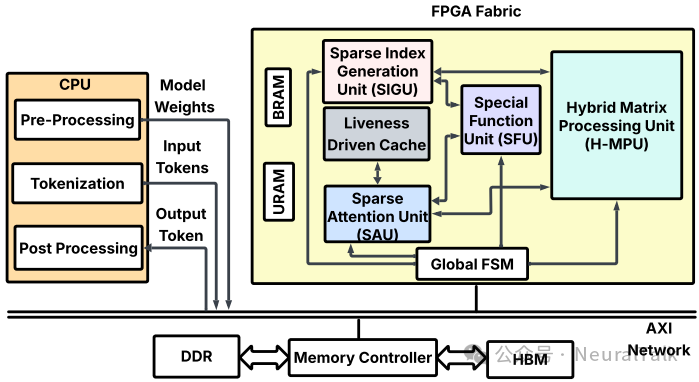
图 4 | FAST-Prefill 整体架构。整合了稀疏索引生成、稀疏注意力计算等核心单元,通过定制化数据通路优化长上下文预填充。
主要组件包括:
- 全局有限状态机:协调各阶段执行
- 特殊功能单元:处理 softmax、归一化和激活函数
- 稀疏索引生成单元:动态生成稀疏模式
- 稀疏注意力单元:执行稀疏注意力计算
- 混合矩阵处理单元:支持高吞吐量矩阵乘法
3.1 创新点 1:流式内存感知的稀疏索引生成
FAST-Prefill 最巧妙的创新在于将稀疏索引生成从“生成-然后聚合”转变为“流式-累积”操作, 如下图所示。
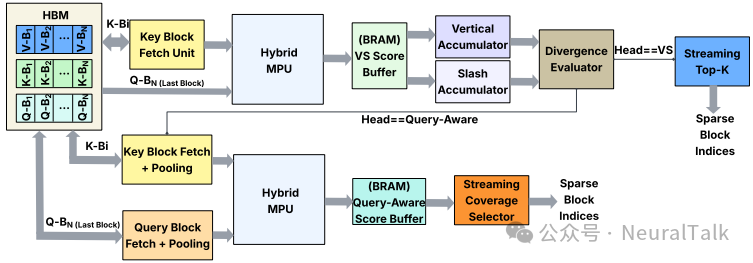
图 5 | 稀疏索引生成单元工作流。以增量聚合的方式计算分数,避免存储庞大的中间张量。
传统的朴素实现需要显式计算中间注意力张量,如 $Q_{\text{last}}K^T$,然后进行池化得到大小为 $H \times N_{\text{blocks}}$ 的注意力图。对于 S=128K,这意味着每头数十兆字节的存储需求。
FAST-Prefill 的设计完全不同:
- 块顺序获取:Key 块严格按递增块顺序从 HBM 获取,确保片外访问是长连续突发,而非头依赖的随机读取
- 增量更新:对每个流式 Key 块,混合 MPU 执行 $Q_{\text{last}}$ 与当前块的点积,不是存储完整的 $Q_{\text{last}}K^T$ 张量,而是增量更新紧凑的逐块统计信息
- 片上累积:逐块统计信息累积在片上的 Score Buffer 中,存储每个头的块级分数
这个设计将中间存储需求从 4GB 降至约 4KB,实现了两个数量级的减少!
- 垂直和斜线累积器:两个专用单元分别维护垂直分数(沿列聚合注意力值)和斜线分数(沿对角线聚合注意力值),随着每个 Key 块流过,实时更新分数缓冲区。
- 流式 Top-k 选择:索引选择阶段不是对整个块列表进行全局排序,而是使用流式 Top-k 选择模块,顺序处理分数缓冲区,维护一个小型候选列表,基于分数比较增量插入块,直到累积和超过阈值 γ。
关键成果:SIGU 不向片外写入任何大于 $H \times N_{\text{blocks}}$ 的中间张量,每个 Key 块只获取一次。通过将分数计算、池化、散度评估和 top-k 选择融合到一个流式流水线中,FAST-Prefill 将稀疏索引生成从不规则、内存受限的操作转变为确定性的、带宽高效的数据通路。
3.2 创新点 2:活性驱动的双级 KV 缓存
第二个核心创新是设计了一个智能的 KV 缓存管理系统,解决稀疏模式依赖的访问问题。
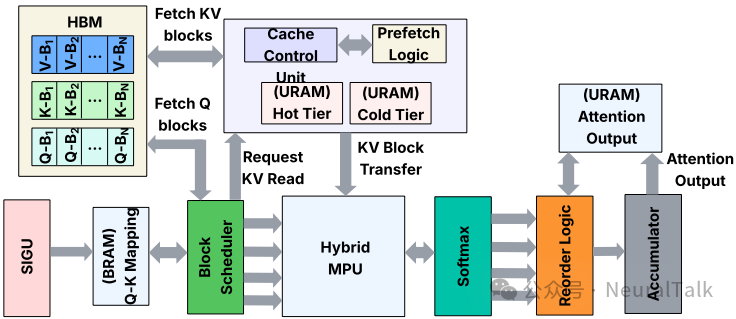
图 6 | 稀疏注意力单元工作流。通过预取与双级缓存管理,最大化片上缓存命中率。
块主调度:不同于遍历查询块或头,SAU 按升序块索引遍历 KV 块。稀疏索引集被转换为紧凑的作业列表表示,每个 KV 块标识符 b 关联一个消费者列表 $\mathcal{C}_b$,表示注意力头 $h$ 和查询块 $q$ 需要这个 KV 块。
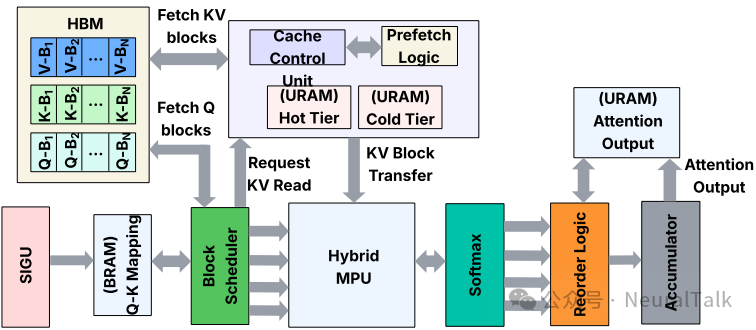
图 7 | KV缓存调度逻辑。展示了块优先执行与键控累积机制。
活性驱动的缓存替换:对于每个 KV 块 b,在作业构建期间计算的块使用计数器作为精确的剩余使用计数器,指示还有多少注意力计算需要这个块。每次消费该块时,计数器递减;当计数器归零时,该块在后续稀疏注意力步骤中不再需要。
这启发了用完即弃的驱逐规则,消除了不必要的重取。但缓存大小有限,如何进一步提高效率?
双级缓存结构:缓存被划分为两个区域:热 KV 层和冷 KV 层,标签存储在 BRAM 中。剩余使用次数超过静态阈值 $\theta_{\text{hot}}$(总查询块的 50%)的块进入热区,重用有限的块进入冷区或完全绕过缓存。这防止了中等重用块驱逐高重用块,避免缓存颠簸。
协作预取:轻量级本地 FSM 维护一个有限的展望窗口,按块索引顺序查看即将到来的 KV 块,并咨询剩余使用计数器确定块是否会被使用以及应该放置在哪里。剩余使用为零的块完全跳过,已在缓存中的块不被重取。预取请求仅在相应缓存区域有足够空间时发出,防止过早驱逐活动块。
键控累积:由于按 KV 块顺序执行而非查询顺序执行,每个查询块的偏序结果无序到达。FAST-Prefill 不使用复杂的重排序网络,而是使用键控累积:每个作业记录携带目标头和查询块的标识符,偏序结果在确定地址上累加到分块累加器存储器中。这实际上起到了重排序缓冲区的作用,同时保持硬件轻量。
3.3 创新点 3:混合矩阵处理单元
第三个创新点解决了 DSP 资源限制问题。关键洞察是:INT8 乘法可以分解为位平面运算,使用 LUT(查找表)实现高效实现。
数学基础:给定 8 位有符号整数 a 和 b,可以表示为:
$$a = \sum_{i=0}^{7} a_i 2^i, \quad b = \sum_{j=0}^{7} b_j 2^j$$
乘积计算为:
$$a \times b = \sum_{i=0}^{7} \sum_{j=0}^{7} (a_i \& b_j) 2^{i+j}$$
每个部分积简化为 AND 操作后移位,非常适合 LUT 实现。但直接实例化所有 8×8 位平面交互既不面积高效也不延迟最优。
半字节划分:将每个 8 位操作数分解为高 4 位和低 4 位半字节:
$$a = a_H \cdot 2^4 + a_L, \quad b = b_H \cdot 2^4 + b_L$$
乘法展开为:
$$a \times b = (a_H b_H) 2^8 + (a_H b_L + a_L b_H) 2^4 + (a_L b_L)$$
每项对应 INT4 乘法,可以用小型 LUT 高效实现。这种半字节级分解显著减少延迟并优化资源,同时保持精确算术语义。
混合实现:在 Xilinx U280 FPGA 上,混合 MPU 设计了 6 个基于 DSP 的 32×32 阵列和 6 个基于位平面的 32×32 阵列。处理单元中的乘法使用 INT8 精度,累积使用 INT32 精度。
四、实验评估
4.1 实验设置
研究团队在 Xilinx Alveo U280 FPGA 上实现了 FAST-Prefill,并与 NVIDIA RTX A5000 GPU 上的 Flex-Prefill 实现进行比较。
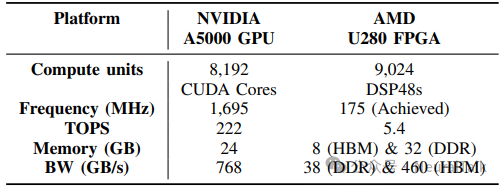
表 1 | GPU 与 FPGA 平台的硬件参数对比。
上表是 GPU 和 FPGA 平台的硬件参数对比,可以看出:
- GPU 拥有更多计算单元和更高算力,但主频高、功耗大;
- FPGA 的 DSP 单元数接近 GPU 的 CUDA 核心数,且具备 HBM+DDR 的混合内存架构,虽峰值算力低,但可通过架构定制化提升稀疏场景的实际利用率,内存带宽的差异化也适配了不同的访存需求。
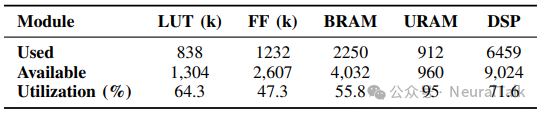
表 2 | FAST-Prefill 在 FPGA 上的资源利用率。
上表是 FPGA 资源使用情况,可以看出 URAM 利用率达 95%,充分利用了片上大容量存储优化 KV 缓存,DSP 利用率 71.6%,LUT 利用率 64.3%,资源分配与架构设计高度匹配,既满足了稀疏索引生成和矩阵运算的算力需求,又未出现资源过度占用的情况,实现了资源的高效利用。
4.2 精度评估
研究团队使用 RULER 基准测试评估模型精度,比较了三种配置:
- Flex-Prefill (BF16):原始 BF16 精度实现
- Flex-Prefill (INT8):权重量化到 INT8,但矩阵乘法需要反量化到 16 位
- FAST-Prefill:W8A8 量化,所有计算在 INT8 精度下完成
下表是 RULER 基准精度比较, 数值越高越好
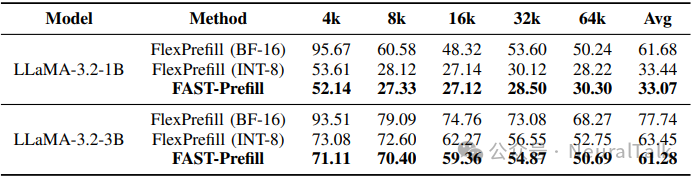
表 3 | RULER 基准测试的精度对比(数值越高精度越好)。
结果显示,FAST-Prefill 的 W8A8 量化实现了与 INT8 Flex-Prefill 相似的精度,验证了硬件设计的数值准确性。
4.3 性能评估
FAST-Prefill 相比 GPU 实现的性能对比如前文图1所示。
在不同上下文长度(4K 到 128K Token)上,FAST-Prefill 相比 GPU 实现实现了 1.5 倍到 2.5 倍的 TTFT 加速。这一加速归功于:
- 稀疏索引生成的自定义内核,通过操作融合减少片外内存流量
- 活性驱动的双级缓存,通过片上缓冲区增加数据重用
- 混合 MPU 设计,提高矩阵乘法吞吐量
相比之下,GPU 实现由于缺乏重用导向的高效 KV 缓存块预取,频繁发生不规则的片外内存访问。此外,GPU 将大部分稀疏索引生成逻辑卸载到 CPU,进一步增加了延迟。
4.4 能效评估
FAST-Prefill 相比 GPU 实现的能效对比如前文图2所示。
FAST-Prefill 实现了高达 4.5 倍的能效提升(Token/Joule)。这凸显了 FPGA 在特定工作负载上的能效优势——通过定制数据通路和减少不必要的片外访问,大幅降低了功耗。
4.5 消融研究
下图显示了缓存对 TTFT 的影响。
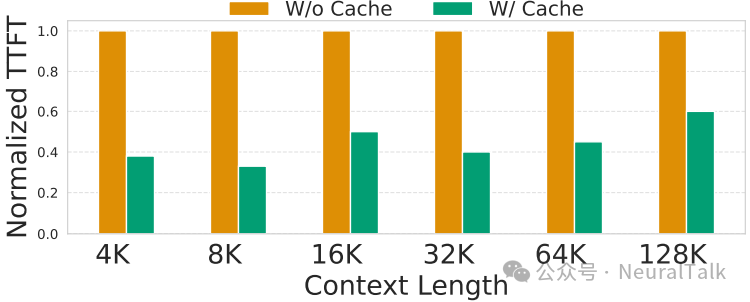
图 8 | 消融实验:缓存对 TTFT 的影响。
实验结果显示,比较有无活性驱动缓存(16 MB)的设计而言:
- 有缓存设计比无缓存设计 TTFT 降低 2.5 倍
- 65%的命中率显著减少了片外内存访问
下图是混合 MPU 对 TTFT 的影响:
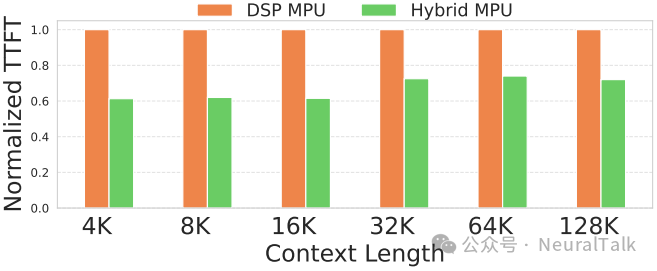
图 9 | 消融实验:混合矩阵处理单元(MPU)对 TTFT 的影响。
比较混合 MPU 与纯 DSP MPU,可以看出:
- 混合 MPU 更好,其提供 1.8 倍延迟加速
- 如果不采用混合 MPU 设计,约 85%的 LUT 资源将闲置
五、相关工作
近年来,FPGA 上的 LLM 推理加速成为研究热点。
| 加速方向 |
代表工作 |
主要技术特点 |
| 解码阶段加速 |
FlightLLM、CD-LLM |
定制解码数据流架构,优化吞吐与延迟,适用于 <1024 Token上下文 |
| 量化技术 |
Tereffic、LUT-LLM、Tellme |
支持三值等极端量化;定制内核适配量化权重;Tellme 统一优化预填充与解码,适配边缘 FPGA |
| 异构计算 |
EdgeLLM、TeraFly |
EdgeLLM 采用 CPU-FPGA 协同;TeraFly 实现多节点 FPGA 联合调度,提升解码并行性与扩展性 |
| 长上下文加速 |
AccLLM |
基于单一注意力稀疏模式优化,融合权重稀疏性与混合精度(FP16/INT4),支持 ≤8K Token长序列推理 |
FAST-Prefill 的创新之处:与上述工作不同,FAST-Prefill 是首个面向动态稀疏注意力的长上下文预填充阶段 FPGA 加速器。它同时处理多种动态稀疏模式,支持高达 128K Token的上下文长度,并通过创新的硬件架构解决了稀疏索引生成、KV 缓存访问和矩阵乘法吞吐量三大核心挑战。
六、结论与展望
FAST-Prefill 展示了 FPGA 在动态稀疏注意力长上下文 LLM 预填充阶段的显著加速能力:相比 GPU,实现 2.5× TTFT 加速与 4.5× 能效提升,同时保持模型精度。其核心贡献在于三项协同设计创新:
- 流式内存感知的稀疏索引生成,降低索引开销;
- 活性驱动的双级 KV 缓存,将不规则随机访问转化为可预测流式访问;
- 混合矩阵处理单元(MPU),以 LUT 补 DSP 不足,提升资源均衡性。
该工作本质是硬件-算法深度协同的范例:非简单映射算法,而是基于 Flex-Prefill 的计算模式与数据流特征,定制数据通路与访存策略。
未来可拓展方向明确:集成 N:M 稀疏性、块剪枝等正交压缩技术,有望进一步降低延迟。随着长上下文应用(如全书理解、长视频分析、多轮深度对话)兴起,预填充效率正成为关键瓶颈。
FAST-Prefill 不仅提供实用加速方案,更确立了一种方法论启示——针对特定工作负载,精巧的架构设计往往比通用算力堆砌更高效。 对这类硬件-算法协同设计感兴趣的朋友,欢迎在云栈社区交流讨论。
 发表于 2026-3-5 14:28:09
|
查看: 235|
回复: 0
发表于 2026-3-5 14:28:09
|
查看: 235|
回复: 0
