生成式检索已成为大模型时代构建推荐系统的核心技术方向,但其大规模落地一直面临着一个显著的工程瓶颈:如何高效地对模型输出施加业务约束。
传统推荐系统中,要筛选“最近7天发布的视频”,只需在数据库查询中添加一个过滤条件。然而,在基于大模型的生成式检索中,模型更像一个概率性的“创作者”,它并非查询数据库,而是通过“猜测”来生成内容。如果不加以约束,其输出结果可能完全不符合业务要求。
通用的技术方案是使用前缀树来约束模型的生成路径。但这套方案在现代的 GPU 或 TPU 这类硬件加速器上运行效率极低。原因在于,树形结构依赖指针跳转,其内存访问模式是高度不规则和分散的。这与 TPU 等加速器偏爱的、整齐划一的向量化数据流处理模式背道而驰,导致计算单元大量时间处于空闲等待状态,严重拖慢整体速度。
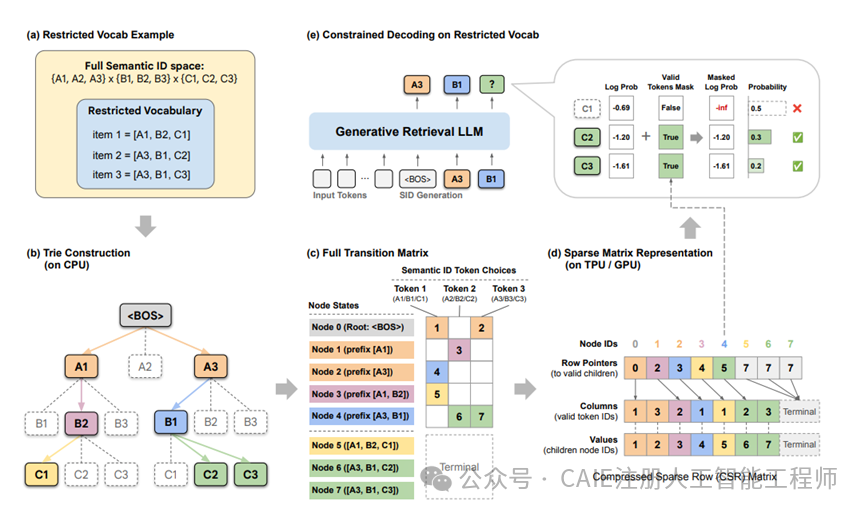
研究表明,如果在 CPU 上计算前缀树(Trie)再传递给 TPU 进行推理,整个过程的耗时会直接翻倍。对于服务全球数十亿用户的超大规模系统而言,这种开销是难以承受的。
近期,来自 Google DeepMind 和 YouTube 的研究团队联合开源了一种创新的约束解码算法 STATIC ,从根本上解决了这一硬件瓶颈。面对“树结构在加速器上跑不动”的挑战,研究人员转换思路:既然树形结构低效,何不将其“压扁”,转换为矩阵呢?
他们洞察到,前缀树本质上是一个状态机,每个节点代表一个状态,节点间的跳转即是状态转移。将这些转移关系完整记录下来,便构成一个巨大的矩阵。在拥有数千万候选物品的实际场景中,绝大多数转移路径并不存在,因此这个矩阵是高度稀疏的。利用压缩稀疏行格式来存储这个矩阵,原本动态、不规则跳转的树结构,就变成了一组静态、连续的数组。
这好比将一张复杂的城市路网图,替换成一本清晰的交通时刻表。对于 TPU 而言,在路口频繁“停车看路牌”判断方向非常低效,而按照“时刻表”进行高带宽的连续内存读取和线性查找,则是其擅长的工作,效率因此大幅提升。
仅有数据结构优化还不够,算法层面也需同步革新。STATIC 设计了一个名为“向量化节点转移核”的算法,巧妙地规避了硬件最厌恶的动态分支问题。在传统树结构中,每个节点的子节点数量不一,导致在 GPU 上并行处理时,不同线程的工作负载严重不均衡(即“线程束发散”问题)。
STATIC 采用了一种“硬核”策略:无论一个节点实际有多少个有效子节点,所有线程都按照当前层最大的子节点数量来读取数据。例如,若最多有 100 个分支,则统一读取 100 个数据项。多读取的部分通过掩码机制屏蔽掉即可。这种在传统 CPU 看来是“冗余计算”的操作,在 AI 加速器上反而是最高效的,因为它保证了所有计算单元同步、整齐地工作,消除了等待和空闲。
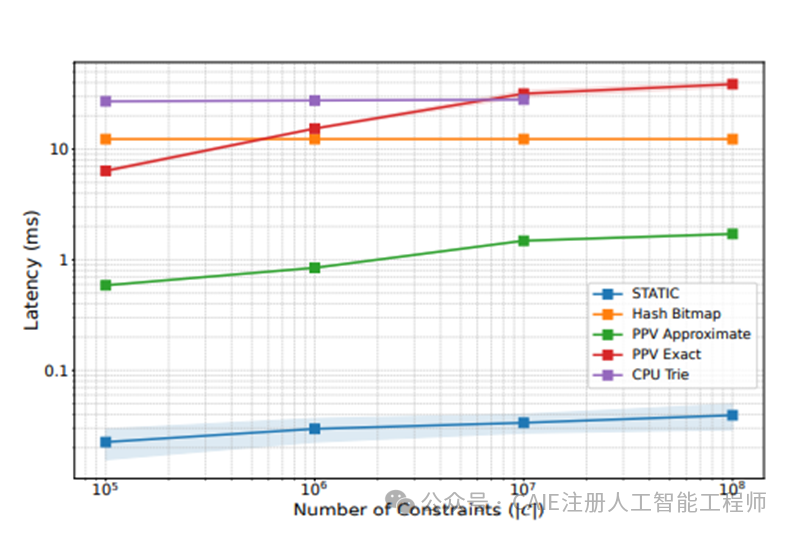
研究团队在 YouTube 的大规模推荐系统上进行了实测。面对一个包含 2000 万新鲜视频的约束词表,传统的 CPU Trie 方法每一步解码带来的额外延迟高达 31.3 毫秒。而 STATIC 方案,每一步的额外延迟仅为 0.033 毫秒。
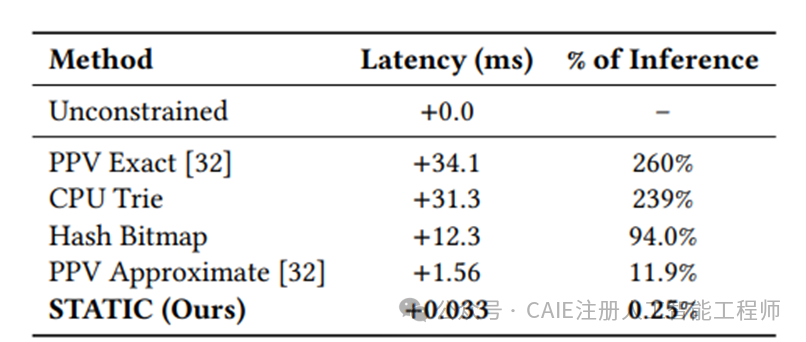
这意味着,STATIC 的速度比当前最先进的 PPV 方法快了约 1000 倍,实现了数量级上的性能飞跃。这使得我们能够在几乎不影响系统整体吞吐量的前提下,对模型输出施加严格、复杂的业务约束,确保生成结果100%有效。
此外,该方案在内存使用上也极具优势。约束 2000 万物品所需的内存占用上限仅为 1.5GB。随着约束物品数量的增加,延迟的增长曲线近乎水平,这种卓越的可扩展性对于电商大促等库存量瞬时暴增的场景至关重要。

谷歌已将这项核心 算法 在 GitHub 上开源:https://github.com/youtube/static-constraint-decoding 。这对于所有正在探索 生成式检索 与 RAG 应用落地的开发者和研究者而言,是一个重要的工程利器。这项研究也充分展示了,在 人工智能 系统走向大规模生产应用时,软硬件协同优化与底层 算法 创新的巨大价值。
对这类前沿的 开源实战 项目感兴趣的朋友,可以关注 云栈社区 获取更多深度技术解读和行业动态。 |  发表于 2026-3-4 07:45:21
|
查看: 264|
回复: 0
发表于 2026-3-4 07:45:21
|
查看: 264|
回复: 0
