向量检索技术,已是当今推荐系统、搜索引擎等核心业务的基石。尤其是在深度学习模型广泛应用的背景下,如何从海量向量中高效找到“近邻”,直接决定了在线服务的响应速度和业务效果。
传统的 CPU 向量检索方案,例如 HNSW,在应对大规模、高并发的真实场景时,其性能与成本往往成为瓶颈。为此,微信基础架构团队将目光投向了 GPU 加速方案,并率先将 NVIDIA 推出的 Cagra(CUDA Accelerated Graph-based Retrieval Algorithm)算法大规模应用于核心线上业务。本文便来分享这次从算法原理到生产落地的完整实践。
Cagra 算法原理:为GPU而生的图索引
Cagra 是 RAPIDS cuVS 库的核心组件,其核心思想是构建一个近似 k-近邻图(k-NN graph),查询时通过启发式图遍历快速定位目标。
你可能熟悉 HNSW(Hierarchical Navigable Small World)算法,Cagra 在它基础上,针对 GPU 的并行架构做了深度定制:
- 单层图结构:摒弃了 HNSW 复杂的多层结构,采用单层图设计,这有利于 GPU 显存的连续访问,减少随机访存开销。
- 固定出度:图中每个节点的邻居数量(出度)是固定的,相比之下 HNSW 只需出度小于等于一个最大值。固定出度让 GPU 上的内存分配和线程调度更加规整、高效。
- 批量化检索策略:HNSW 每次选择一个点进行扩展,而 Cagra 会同时从候选集中选取一批(比如
batch_size 个)未被探索的点进行并发扩展,然后统一更新候选集。这种“齐头并进”的策略,极大地挖掘了 GPU 的并行计算潜力。
为了让这张图在 GPU 上跑得又快又准,构建时需要着重考虑两点:一是保证全图的连通性,确保从任意节点出发都能到达其他节点,这是检索准确率的基石;二是优化遍历效率,在 GPU 的批量处理机制下,让访问尽可能均匀地分散到更多节点,反而比依赖少数中心节点(hubs)能更快收敛。
工程化改造:让实验室算法适应生产环境
论文中的算法往往面向离线场景,但我们的目标是为高并发在线推荐服务提供动力。为此,我们与 NVIDIA 技术团队紧密合作,对 Cagra 进行了多项关键改造。
1. 建图优化:降低内存依赖
原论文采用 NNDescent 算法建图,需要大量 Pinned Memory(锁页内存),在生产环境的容器化部署中难以规模化。我们设计了渐进式子图优化方案:先随机构建一个连通图,然后通过多次小范围遍历筛选出子图进行精细优化,再逐步扩散至全图,并辅以一轮连通性调整。这套方案在保证与全图 NNDescent 相同召回率的前提下,大幅降低了对特殊内存的依赖。
2. 性能表现:数量级的提升
在实际生产数据集(千万级高维向量)上的测试结果令人振奋:
- 建库性能:在保证召回率(Recall@10 > 0.9)的前提下,传统 HNSW 需要数十分钟甚至数小时,而 Cagra 将建索引时间缩短至原来的 1/30 以下,仅需几分钟。
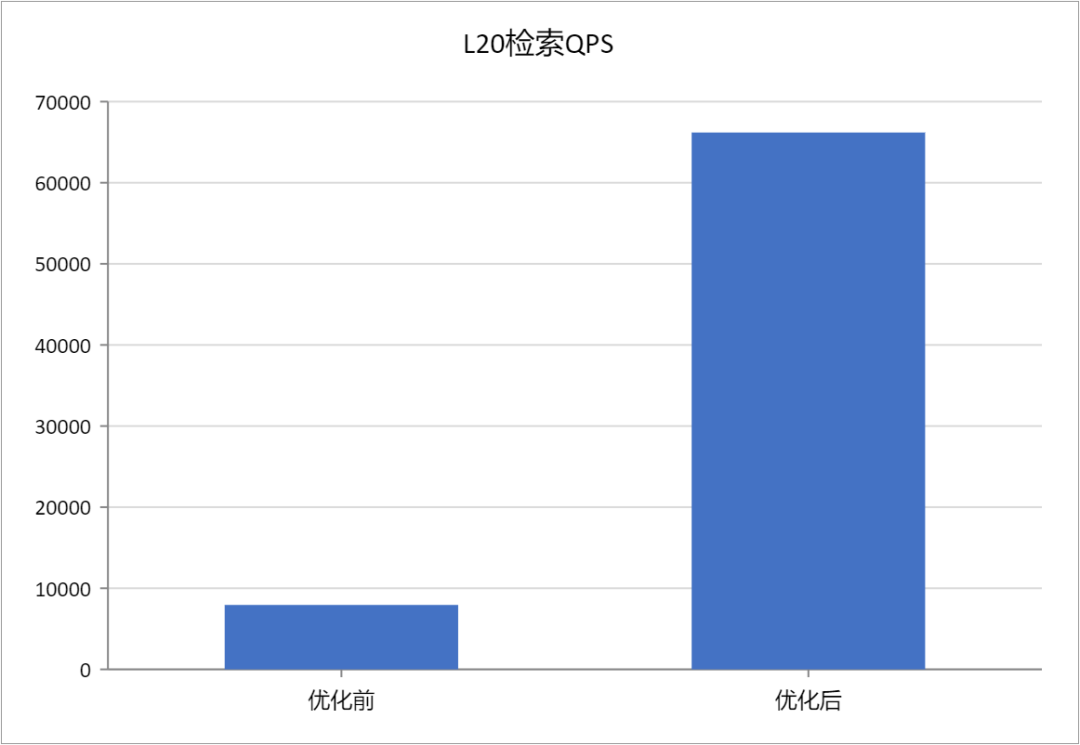
- 检索吞吐:测试表明,随着查询批处理大小(Batch Size)的增加,Cagra 在同等硬件成本下能获得远超 CPU 方案的 QPS(每秒查询数)。Batch 越大,优势越显著,这与推荐系统高并发的特性完美契合。
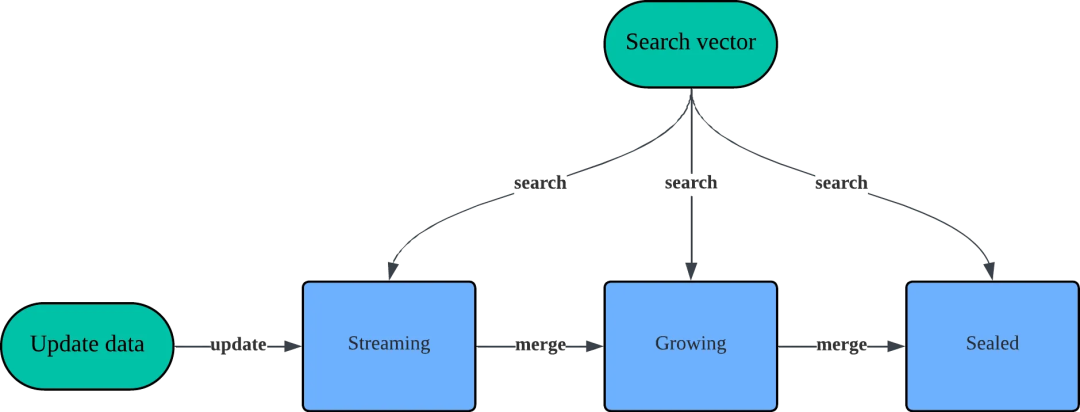
系统架构演进:三层存储巧解更新难题
将强大的 GPU 检索能力无缝接入持续写入的在线服务,是个系统工程。我们为微信的分布式向量检索系统 SimOL 设计了一套类似 LSM-Tree 的三层分层存储架构,巧妙地平衡了数据“新鲜度”与索引更新效率。
-
Streaming 层(流式层)
- 定位:处理最新、最热的数据写入。
- 策略:数据量小但更新极频繁。我们采用 GPU 加速的暴力计算(Brute Force),新数据写入后秒级可见,无需等待索引构建,最大化保证了数据的实时性。
-
Growing 层(增长层)
- 定位:中间缓冲层,承接从 Streaming 层合并而来的数据块。
- 策略:数据量达到中等规模。采用 Cagra 索引,并利用其强大的批量构建能力,在备用 GPU 显存上构建新索引,完成后通过原子切换(Double Buffer)机制更新,实现服务零中断。
-
Sealed 层(封存层)
- 定位:存储基本不再变动的历史海量数据。
- 策略:同样采用 Cagra 索引,追求极致的查询性能和存储密度。
这套架构通过分层处理,让高频更新与批量建索引解耦,同时利用 Cagra 的快速构建能力,实现了全链路的数据时效性与查询高性能。
性能深潜:CPU/GPU协同与并发优化
线上服务是复杂的有机体,仅提升 GPU 算力是不够的,必须让 CPU 与 GPU 协同工作,避免任何一环成为瓶颈。
1. 过滤(Filter)策略优化
业务检索常附带复杂的属性过滤条件。尽管“先过滤再检索”(Pre-filter)理论上召回率更高,但在 GPU 上实现会导致显存占用剧增且延迟不稳定。
我们采用了 Post-filter(后置过滤) 方案:在 GPU 端检索时,适当扩大召回数量(topK),然后将结果交给 CPU 进行属性过滤。为了缓解 CPU 侧随机内存访问的瓶颈,我们对数据进行了分块(Chunk)存储,并优化了数据加载顺序与内存预取(Prefetch)。仅此一项优化,就使单机 QPS 提升了约 25%。
2. 请求聚合与协程唤醒
GPU 喜爱大批量数据,但线上请求是离散的。如果每个请求单独调度,并在 GPU 完成后逐个唤醒处理线程,会产生巨大的 CPU 上下文切换开销。
基于自研的协程框架,我们重构了聚合与分发逻辑:
- 聚合阶段:工作线程先将请求在本地聚合,再跨线程汇总成一个大 Batch 提交给 GPU。
- 唤醒阶段:GPU 处理完成后,采用 “链式广播唤醒” 机制,将需要跨线程通信的次数从“协程总数”级别降至“物理线程数”级别。
这项改造使 CPU 在系统态(System)的资源占用大幅下降,单机吞吐量 再次提升了 65%。
3. 聚合时延的精细控制
Batch 越大,GPU 利用率越高,但等待聚合的时间会增加尾部延迟(P99)。通过对海量线上请求的压测分析,我们找到了一个毫秒级的 “黄金聚合窗口” ,在保障用户体验延迟的前提下,最大化地挖掘了 GPU 的吞吐潜力。
业务落地:效果与收益
最终,我们将这套基于 NVIDIA Cagra 的 GPU 向量检索架构,成功应用于微信视频号推荐系统的召回阶段,取得了切实的业务收益:
- 突破性能瓶颈:彻底解决了以往因 CPU 建库慢导致的数据合并拥堵问题,系统能够轻松应对极高的实时数据写入并发。
- 召回效果提升:更快的索引更新速度,让业务能使用更“新鲜”的向量数据,整体召回率得到显著提升。
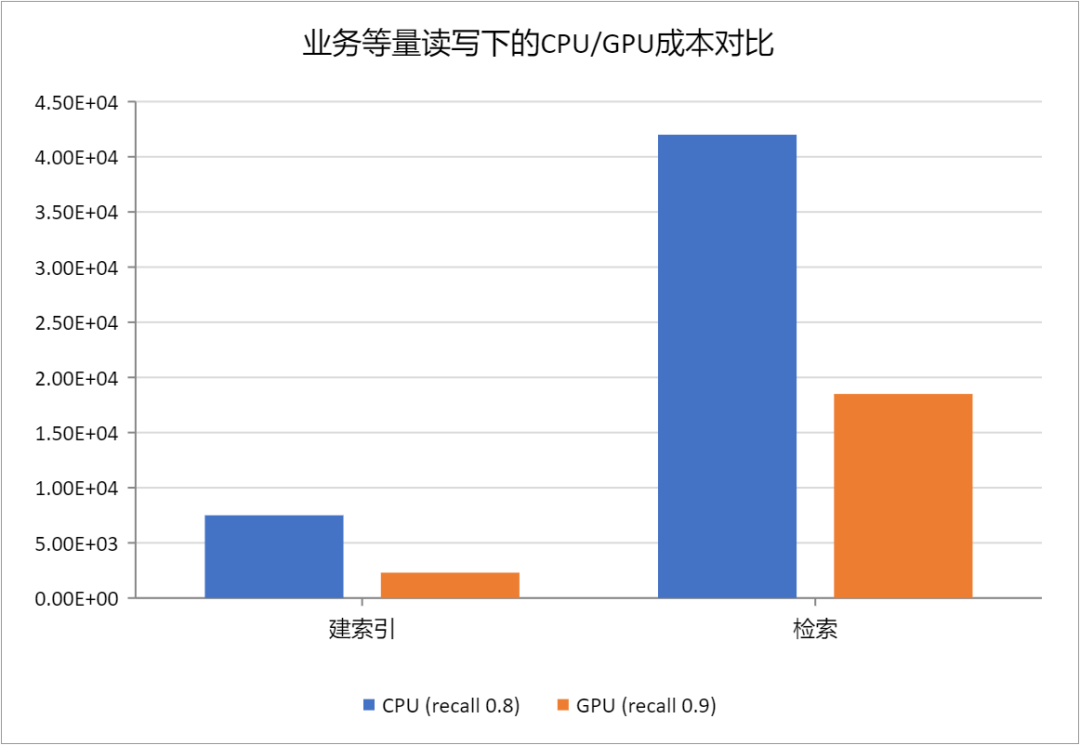
- 成本大幅下降:
- 检索成本:在实现更高 QPS 且召回率更优的条件下,计算资源消耗 降低了 50% 以上。
- 建库成本:得益于 GPU 的极速建图能力,索引构建成本 降低了约 70%。
总结
从 HNSW 到 Cagra,从 CPU 到 GPU,这次技术升级不仅是算力设备的更替,更是一次从算法、工程架构到资源调度的系统性重构。它证明了通过深度优化和精细设计,GPU 加速的向量检索技术完全能够胜任超大规模、高并发的核心在线服务,并在性能和成本上带来质的飞跃。希望微信团队的这次实践,能为业界同行在构建高性能向量检索系统时提供有益的参考。
致谢:感谢 NVIDIA 技术团队在研发过程中提供的技术支持,感谢微信视频号推荐团队在架构升级过程中给予的协作。
 发表于 2026-3-21 01:27:16
|
查看: 87|
回复: 0
发表于 2026-3-21 01:27:16
|
查看: 87|
回复: 0
