老王劈头盖脸地问:“OpenClaw 的 Memory 机制和 RAG 很相似,了解吗?”
透过厚厚的近视镜片,我碰到了他那双对技术依然充满好奇的眼睛。我明白他想听的不是一个肤浅的答案:“必须啊。OpenClaw在唤起记忆时用到了混合检索,和我做的派聪明 RAG 项目异曲同工,也有 BM25、rerank 这些。”
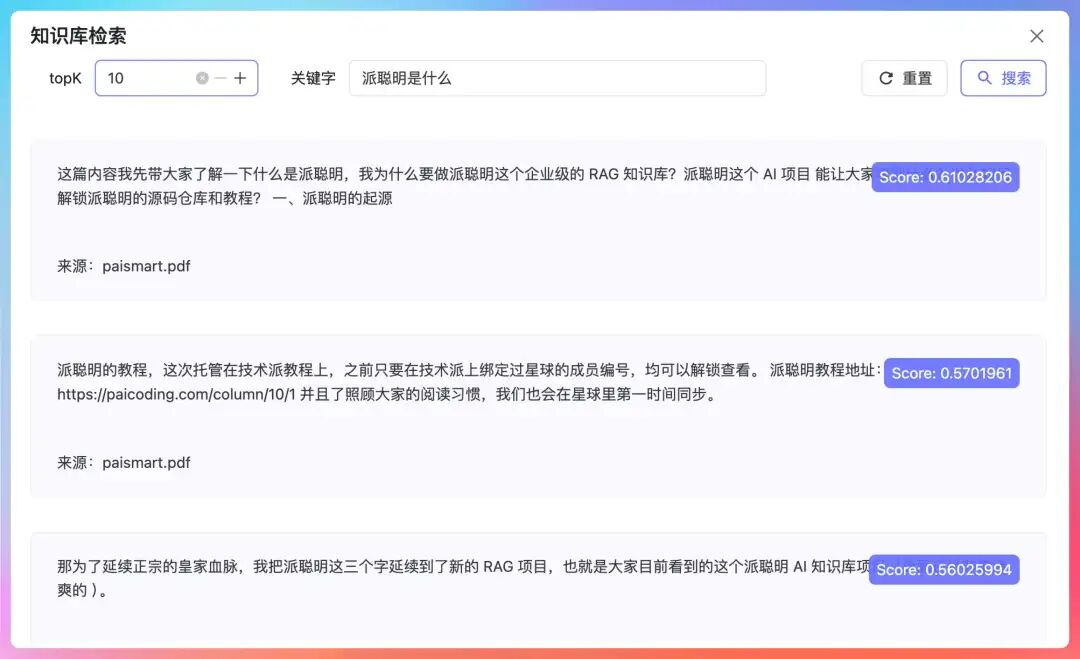
“你小子,看来是做了功课的。” 老王扶了扶快要掉到嘴巴上的眼镜,把右手顺势摆在桌面上,继续问,“OpenClaw 的 Memory 分了两层,一层是会话级别的,一层是长期记忆的,它们之间有什么区别?”
不得不承认,老王不是那种浮于表面的面试官。他真有研究,对技术有渴望,我也想成为像他一样钻研透彻的人。
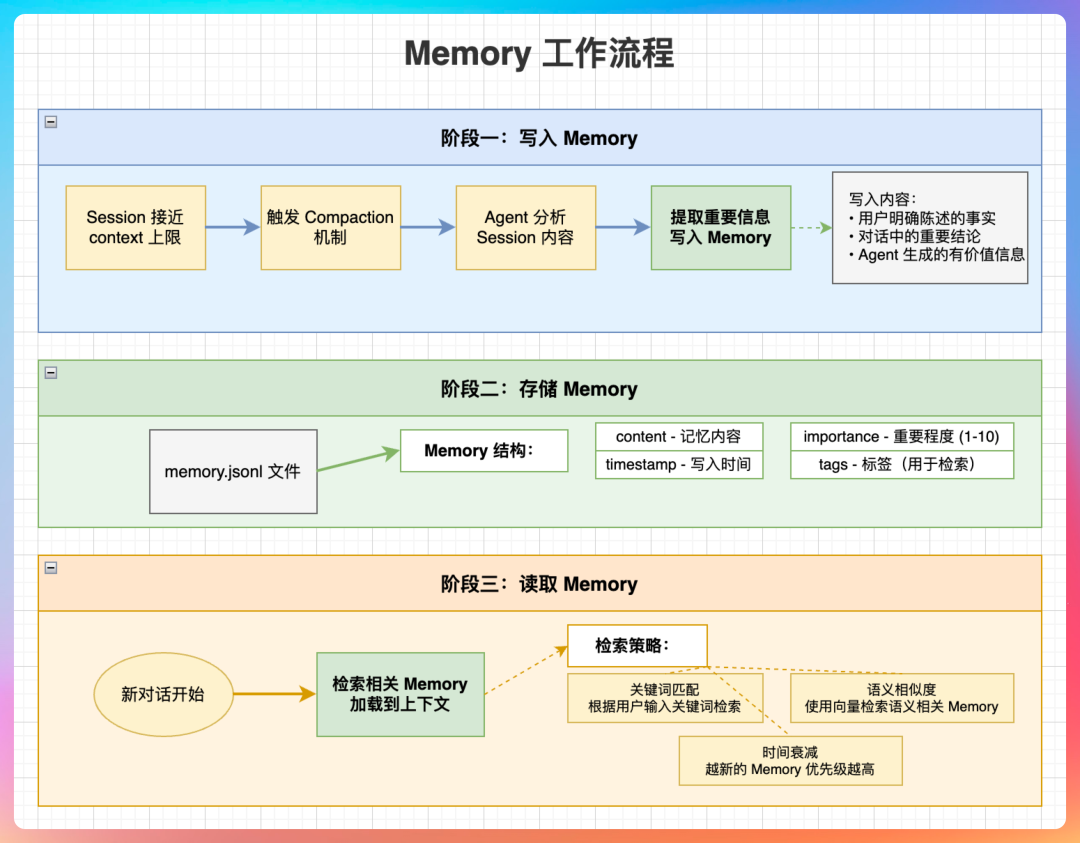
01、Memory 和 Session 的区别?
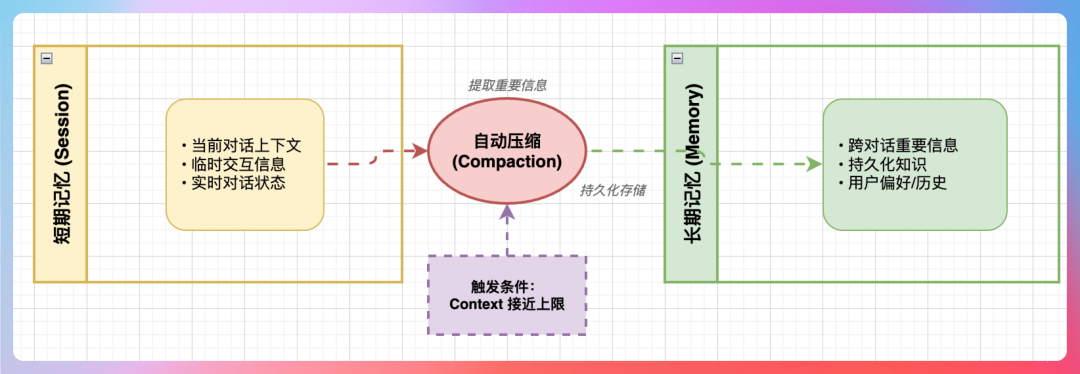
“王哥,Memory 是 OpenClaw 最核心的机制之一,它让 Agent 有了‘记忆’的能力。”

短期记忆
短期记忆存储在 ~/.openclaw/agents/{agentId}/sessions/*.jsonl 文件中,由系统自动记录。
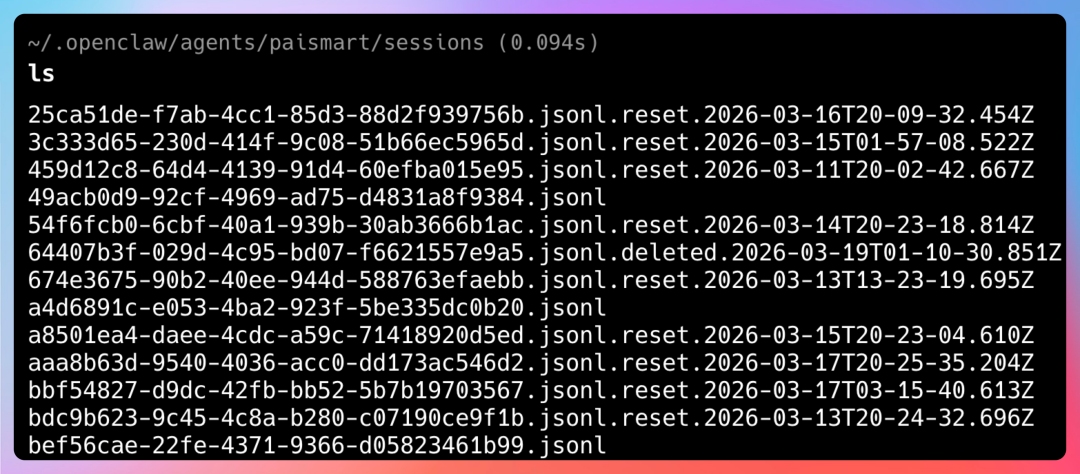
每次和 Agent 对话,OpenClaw 就会自动将对话内容追加到 JSONL 格式的会话日志文件中。这是最原始的、未经处理过的记忆,就像对话的“流水账”。
长期记忆
长期记忆则存储在 ~/.openclaw/workspace/MEMORY.md 和 memory/*.md 文件中。这些文件可以手动创建,但通常交给 OpenClaw 自动生成。
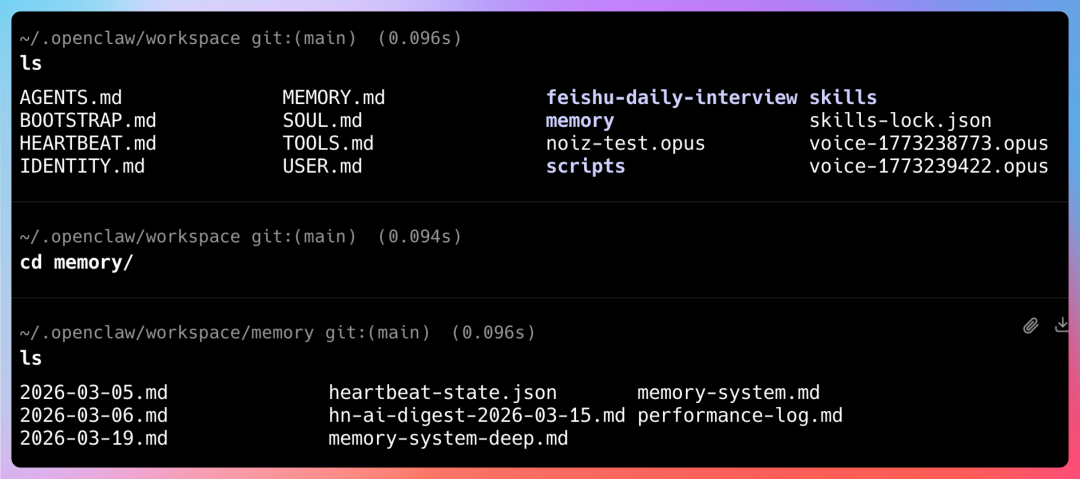
你可以把它理解为从短期、琐碎的对话记录中,提炼出来的需要 Agent 重点记住的精华内容。比如用户的身份信息、性格特点、回答偏好等。
举个例子,你告诉 Agent:“我是 Java 后端开发,回答问题时请用 Java 相关技术栈。” 这句话就会被提炼成一条长期记忆,存入 Markdown 文件。下次对话时,Agent 会自动检索到这条记忆,并按照你的偏好来回答。
老王追问:“那长期记忆和短期记忆之间是怎么转换的?”
我说:“王哥,问得好,有研究啊。”
02、记忆是如何自动转换的?
“记忆转换主要有两种触发机制。”
机制一:session-memory Hook
当用户执行 /new 命令重置会话时,OpenClaw 会触发一个叫 session-memory 的 Hook,自动将上一个会话中的关键内容转换并写入 Markdown 文件。
这个过程完全自动化,无需手动干预。系统会分析 JSONL 文件里的对话,提取出关键信息——比如用户新表露的偏好、重要的上下文、需要长期记住的事实——然后写入 memory/YYYY-MM-DD.md 这样的日记文件。
机制二:Memory Flush(内存刷新)
这是一个非常关键的自动化机制。
当 Session 的上下文长度接近模型的上限时,OpenClaw 会触发一个压缩(Compaction)机制。此时,Agent 会主动分析当前 Session 的内容,提取出重要信息,然后写入长期 Memory。
老王点点头:“那这些 Markdown 文件是怎么被检索的?总不能每次查询都去遍历所有文件吧?”
03、Memory 的索引到底是怎么建起来的?
“王哥,真正难的不是‘记下来’,而是‘下次还能在几百份文件里把它精准地找回来’。”
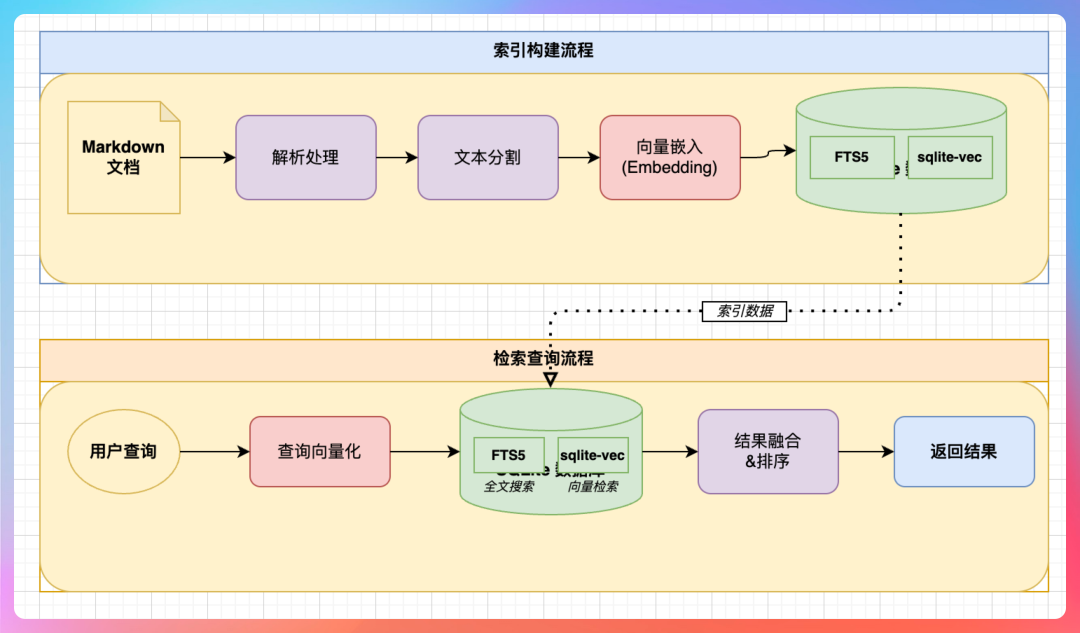
OpenClaw 是这样处理 Memory 的:
- Markdown 文件是记忆本体,也就是 source of truth。
- SQLite 是加速层,负责把这些 Markdown 变成“可快速检索”的东西。
不了解的人可能会误以为 SQLite 文件就是 Memory 本身,其实不然。
那些 Markdown 文件才是记忆的源头,其中:
MEMORY.md:记录的是长期稳定的记忆,偏重“结论”和“偏好”。memory/YYYY-MM-DD.md:属于日记式记忆,偏重“当天发生了什么具体的事”。
OpenClaw 不是“每次查询时去扫描一遍目录”,而是提前把 Markdown 文件切块、建立索引、并存储到 SQLite 文件里。当 Agent 需要查询历史时,直接查询索引即可。这样不仅可以进行关键词匹配,还能进行语义搜索,让 Agent 显得更智能。
从命令行看更直观。执行:
openclaw memory status
这条命令会告诉我们当前 Memory 系统的工作状态:用什么模型、索引建了多少、库文件在哪、全文检索和向量检索是否正常。
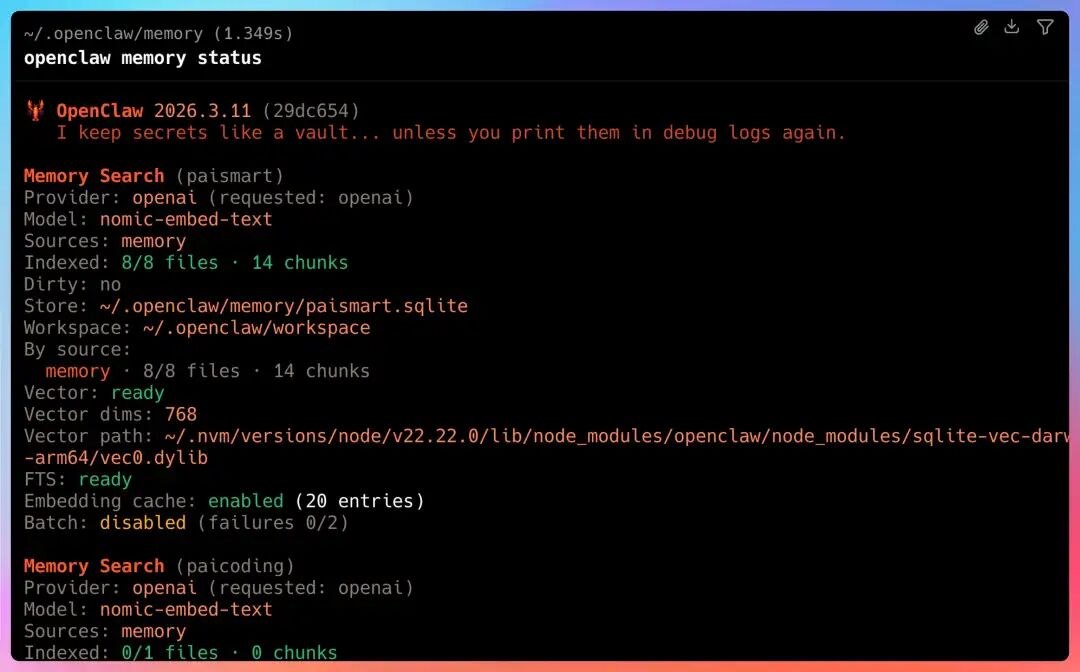
以我这台机器为例,输出关键部分如下:
Provider: openai (requested: openai)
Model: nomic-embed-text
Store: ~/.openclaw/memory/paismart.sqlite
Indexed: 8/8 files · 14 chunks
Vector: ready
FTS: ready
Provider: openai (requested: openai) 表示 Memory 使用的嵌入(Embedding)服务遵循 OpenAI 的接口规范。Model: nomic-embed-text 说明实际用于生成文本向量的模型是 nomic-embed-text。

Store: ~/.openclaw/memory/paismart.sqlite 指出 Memory 的索引实际存储在这个 SQLite 文件里。Indexed: 8/8 files · 14 chunks 表示一共发现了 8 个 Memory 文件,都已建立索引,并被切分成 14 个文本块。Vector: ready 表示向量检索功能正常,即语义搜索可用。FTS: ready 表示全文检索功能正常。FTS 就是 Full-Text Search。
老王对我的信任感增加了,接着问:“建索引时具体做了什么?”
建索引时到底做了什么?
可以概括为四步。
第一步,发现(Discovery)。
OpenClaw 会监控 MEMORY.md 和 memory/*.md 这两个路径。一旦有新增文件或现有文件内容被更新,就把该文件标记为“脏”(dirty),准备为其重新建索引。
第二步,切块(Chunking)。
把 Markdown 文件切分成多个语义块(Chunk),目标是让“一个块只表达一小段相对完整的意思”。这既控制了块的大小,又通过重叠等策略保护了语义的完整性。
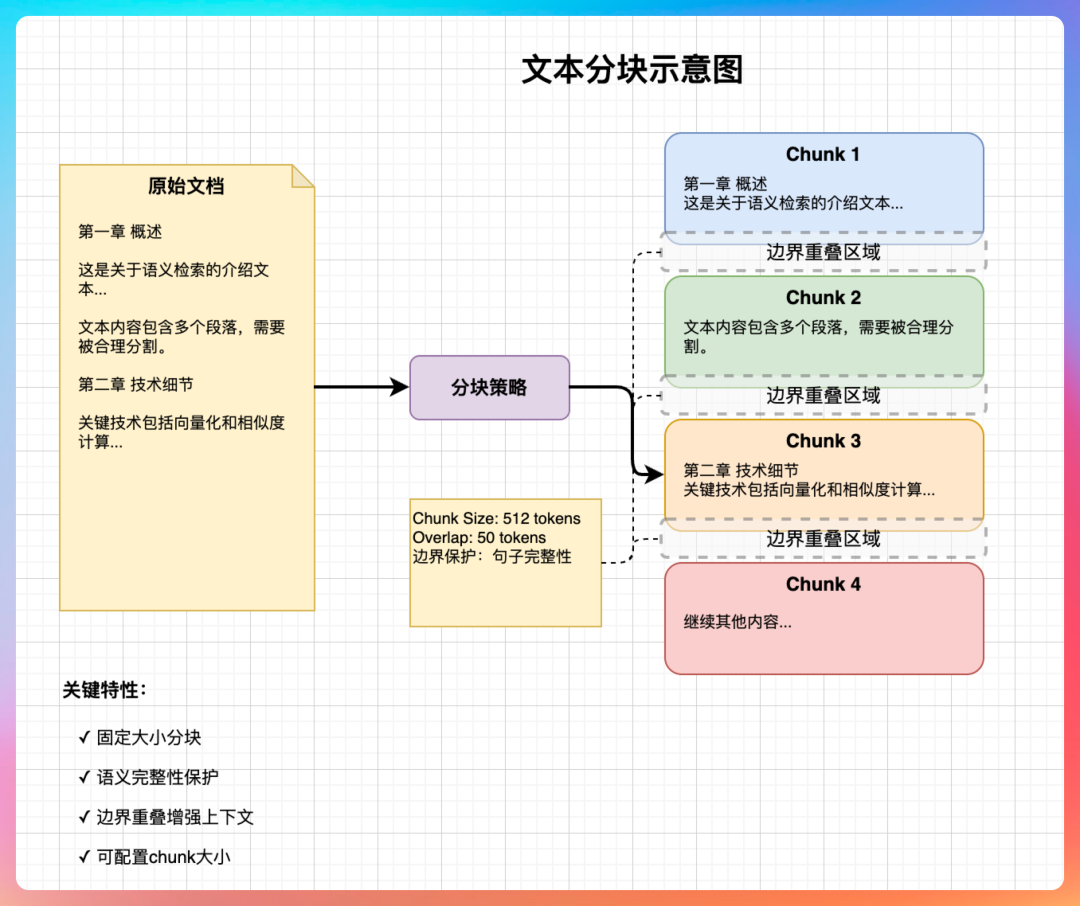
第三步,索引(Indexing)。
每个文本块会并行进行两种索引处理:
- 一路进入向量索引,负责“意思差不多也能搜出来”(语义相似度)。
- 一路进入FTS 全文索引,负责“关键词命中要准确”(字面匹配)。
也就是说,OpenClaw 不是只做向量检索,也不是只做关键词检索,而是采用了混合检索策略。
第四步,落库(Persistence)。
最后,这些文本块的内容、元数据、全文索引、向量索引,都会打包存储到本地的 SQLite 数据库中。
老王点点头:“那检索时到底怎么查?是纯向量,还是纯关键词?”
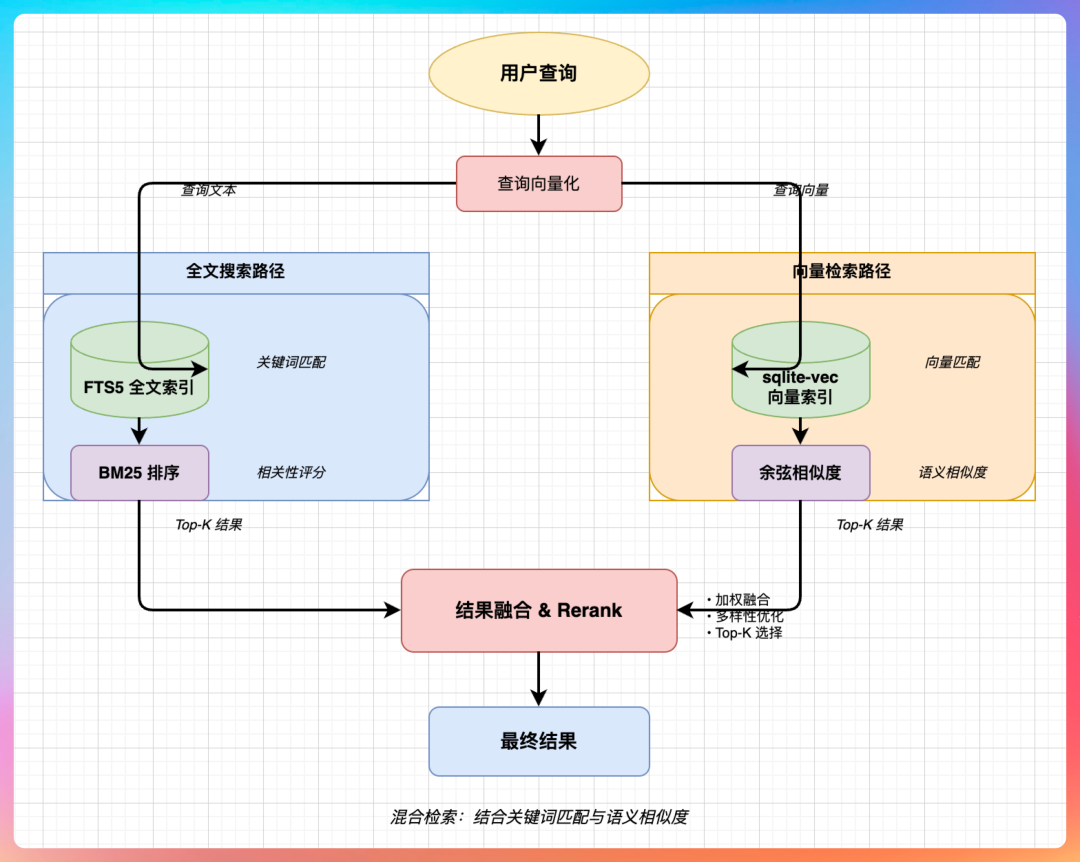
我说:“是混合检索,两者结合。”
04、混合检索为什么比纯向量靠谱?
举个最简单的例子。
如果我们要搜索的是一个明确的术语:memory_search("nomic-embed-text")
这类查询的关键,不在于“语义接近”,而在于“这个字符串必须被精确命中”。如果只依赖向量检索,它可能会把“embedding 模型”、“本地向量索引”这些语义相近但不包含关键字的内容都捞出来,反而漏掉了最关键的直接匹配。
如果用户搜索的是:
上次说过的那个文章写作偏好是什么来着?
这时候,单纯的关键词检索就不够用了,因为用户未必会原样说出“娓娓道来”、“少用你、多用大家和我们”这些原文中的固定字眼。
所以 OpenClaw 的设计思路是:
- FTS5 + BM25 负责精确的词项命中。
- sqlite-vec 负责语义相似的召回。
- 最后把两边的结果进行融合与重排,返回给用户。
为什么是 FTS5?
因为 SQLite 内置的 FTS5 扩展,本质上就是一个轻量级的全文搜索引擎。它比简单的 LIKE '%xxx%' 查询快得多,更重要的是,它懂得“哪些词更重要,哪些结果应该排在前面”——这就是 BM25 算法的价值。
BM25 会综合评估:
- 词频(Term Frequency)
- 文档长度(Document Length)
- 逆文档频率(Inverse Document Frequency,即这个词在整个语料库中是否稀有)
于是,像 memory_flush、session-memory、nomic-embed-text 这类在文档集合中出现较少的专业术语,其匹配结果的权重天然就会更高。
为什么还要 sqlite-vec?
因为 FTS5 主要解决“字面命中”的问题,却解决不了“语义匹配”的需求。比如用户这样问:
- “上次那个事”
- “之前你记住的偏好”
- “我不是说过不要那种爆款腔吗”
这种问法,字面上未必能精确匹配到原文,但语义是高度接近的。这时候,向量嵌入(Embedding)的价值就体现出来了。
它先把用户的查询(Query)转换成向量,再和库里每个文本块(Chunk)的向量进行相似度计算(如余弦相似度),把语义最接近的片段找出来。可以简单理解为:
query
↓
embedding(query)
↓
和 chunks_vec 里的每个向量算距离
↓
取 top-k 最相似的
这套机制如果放在传统的云服务或SaaS产品里,通常需要一个独立的向量数据库(如派聪明RAG项目就使用了ElasticSearch)。但 OpenClaw 没有这么做。
它利用了 sqlite-vec 这类 SQLite 扩展,直接把向量检索能力内置到了本地的 SQLite 数据库里,极大地简化了部署和架构。
老王听到这儿笑了:“行,概念算你讲明白了。那 Agent 自己到底怎么使用这些 Memory?”
05、检索到记忆之后,Agent 是怎么把它用起来的?
“王哥,这一步才是 Memory 系统真正发挥价值的地方。”
很多人以为 Memory 系统的终点是“查到了”。其实不是,关键在于“怎么用”。
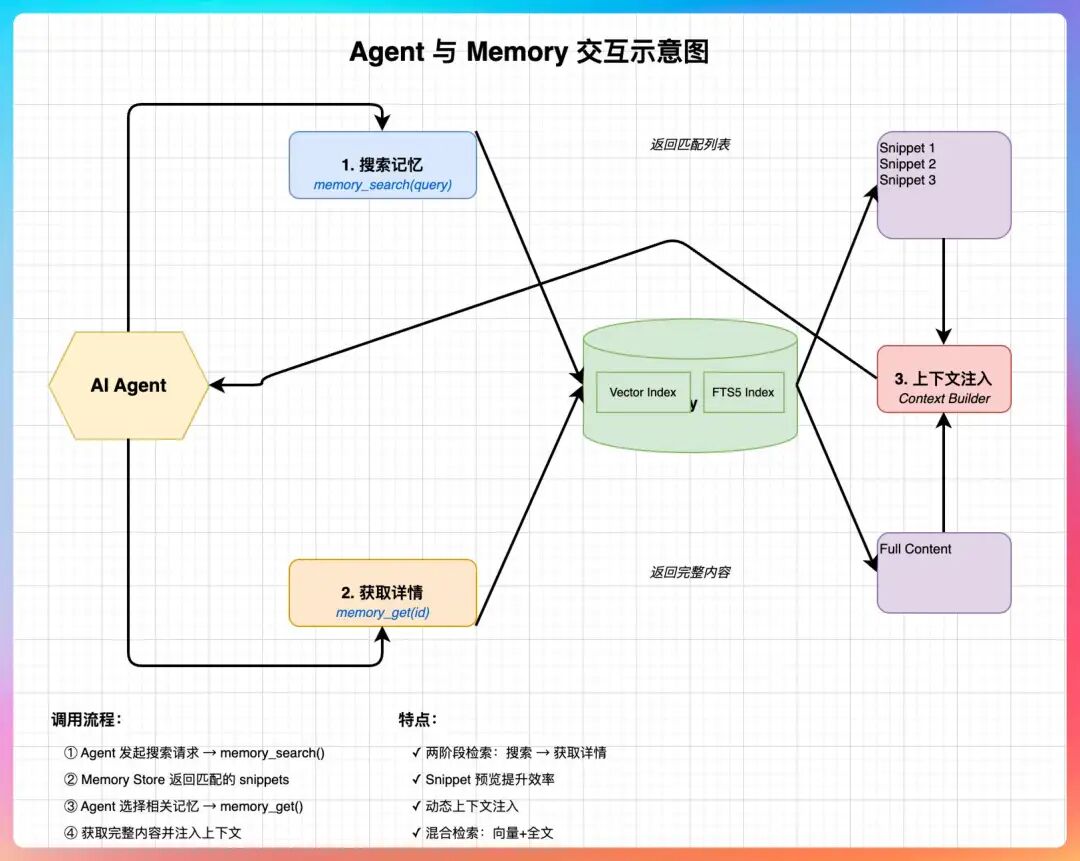
OpenClaw 主要向 Agent 暴露了两个工具函数:
1) memory_search
当 Agent 判断当前问题涉及过去的决策、用户偏好或历史上下文时,它不会傻傻地把整个 memory/ 目录读一遍,而是先发起一次语义搜索。
例如:
memory_search("二哥的文章写作偏好")
返回的不是整篇文档,而是最相关的若干个文本片段(snippet)以及它们所在的文件路径和行号范围。
这样做有两个明显好处:
- 控制 Token 消耗,避免把整个冗长的历史记录一口气塞进有限的上下文窗口。
- 先进行“粗召回”,快速定位到“值得深入阅读”的具体位置。
2) memory_get
如果 memory_search 返回的结果指出,关键信息位于:
MEMORY.md#L1-L16memory/2026-03-19.md#L20-L48
那么 Agent 下一步就可以使用 memory_get 工具,去精确读取这些具体的行段。
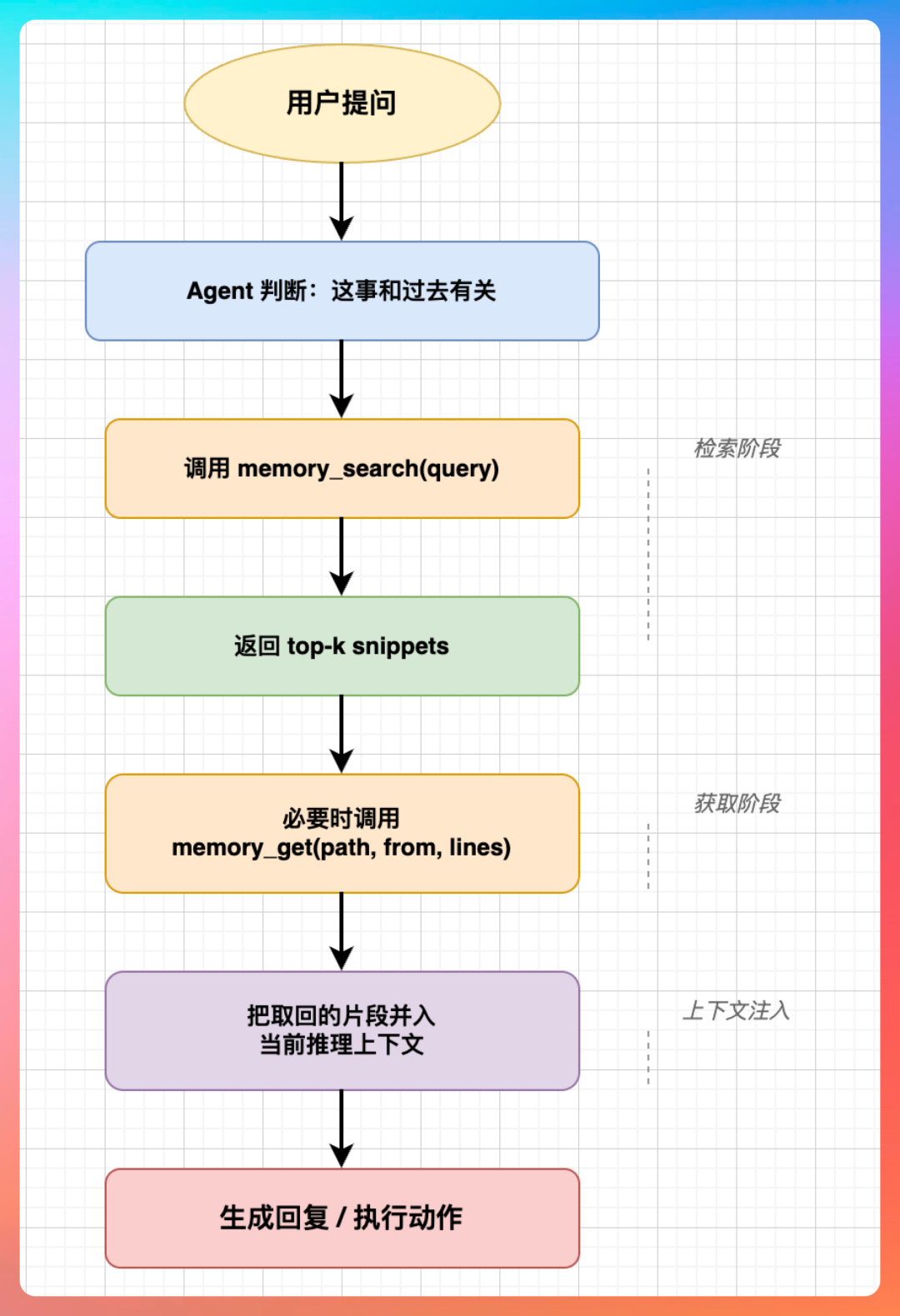
这里有一个特别容易被忽略但至关重要的设计点:
Memory 文件本身的内容,并不是在每一轮对话中都全量注入到上下文的。
像 memory/*.md 这种按天记录的日记文件,默认并不会被塞进上下文窗口。它们是通过 memory_search 和 memory_get 这两个工具,按需、动态地被读取和注入的。
这就完美解释了为什么 OpenClaw 的 Memory 能够“越记越多”,同时又不会把有限的上下文窗口撑爆。
Memory flush 为什么是这个体系里的关键一环?
在会话上下文长度接近触发自动压缩(Compaction)之前,OpenClaw 会悄悄地触发一次 silent memory flush(静默内存刷新)。
也就是说,当系统检测到 session 快要满了、即将启动压缩时,它会自动发起一个“静默回合”,在这个回合里提醒模型:“请把当前会话中值得长期保留的内容,总结并写入 memory/YYYY-MM-DD.md 文件。”
老王听完感慨:“你这理解得够深的。那我再问你一个实际应用的问题,你用 OpenClaw 的 Memory 干过什么真实的场景?”
06、Memory 的最佳实践
“王哥,我给你讲一个我真实在用的场景。”
我有一个专门帮我审核 GitCode 账号的 Agent。如果没有 Memory,每次审核时,我都得反复告诉它一些固定的操作流程,比如:
- 审核完成后,发通知到哪个飞书群。
- 要把用户添加到哪个 GitCode 项目组。
- 审核结果用什么固定格式回复。
这些信息每次重复,非常繁琐。但把它们写进 Memory 就一劳永逸了:
# 用户偏好
## gitcode 审核
- 审核完成后发消息到“技术派-运营群”
- 添加到项目组:技术派-会员组
- 回复格式:@用户 审核通过,已添加到技术派-会员组
## 其他偏好
- 我是 Java 后端开发,回答问题请用 Java 技术栈
- 回复时请简洁,不要废话
这样,每次执行审核任务时,Agent 就会自动检索这些偏好记忆,并严格按照我的要求来执行。
老王听完眼睛一亮:“这个场景实用。”
我说:“还不止。我还让 Agent 记住了我的工作习惯。比如,它知道我喜欢在早上集中处理审核任务,于是会在每天早晨主动提醒我还有多少待审核的申请。”
“来,我们直接让 OpenClaw 现场演示一下。” 执行这条命令:
openclaw memory search "nomic-embed-text"
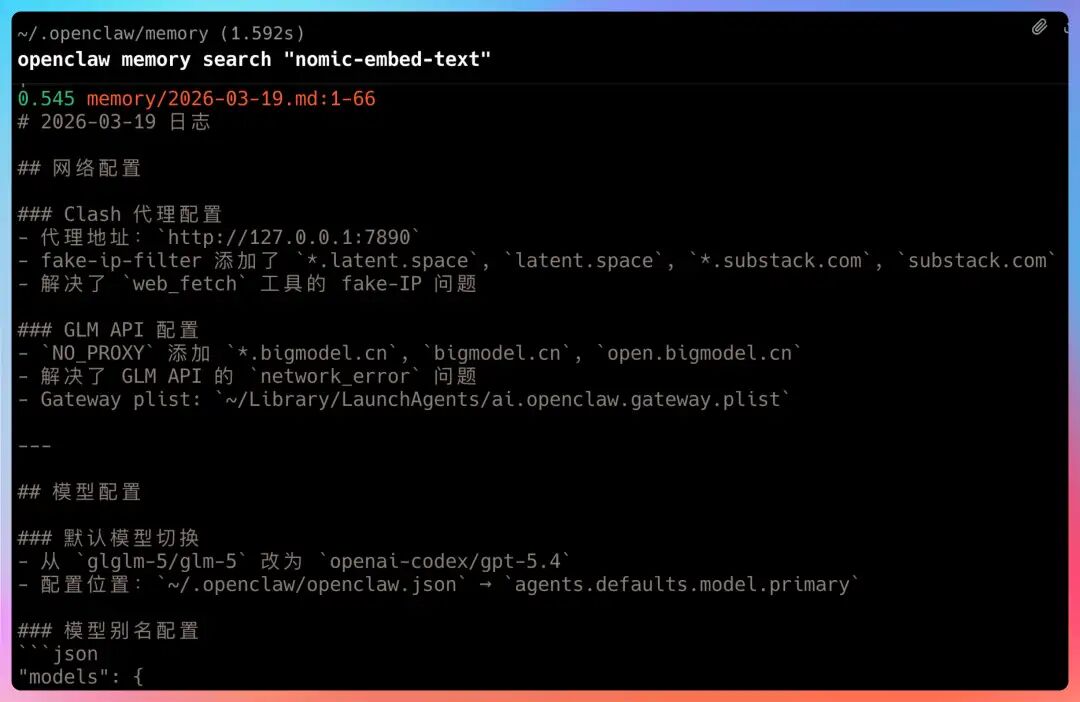
返回结果直接命中了 memory/2026-03-19.md 和 MEMORY.md 中的相关内容,而且都正好包含了“nomic-embed-text”、“embedding 模型”这些关键词。这说明关键词全文搜索(FTS)是切实有效的。
第二次,我们执行一个更依赖语义理解的搜索:
openclaw memory search "上次说过不要那种爆款腔的写法"
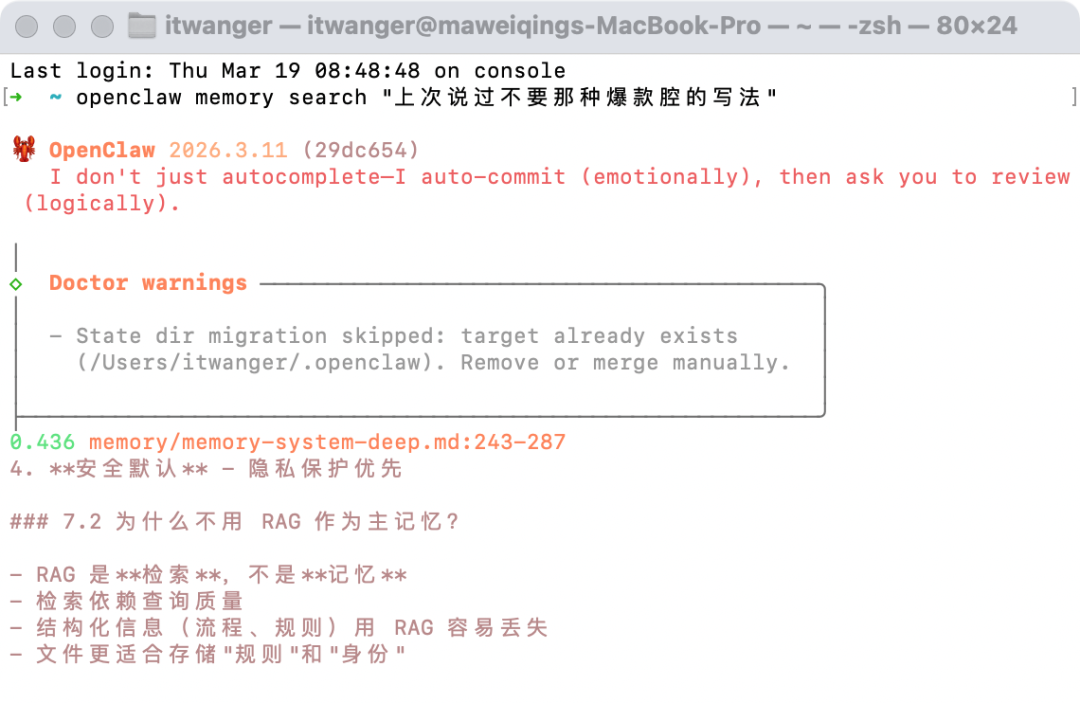
注意,这句查询里并没有直接出现“不要硬做爆款腔”、“娓娓道来”等原文词汇。但返回结果成功找到了 memory/memory-system-deep.md 等文件中,与“写作风格、表达偏好”语义高度接近的内容。这就证明了向量检索(语义搜索)同样可用。
结尾思考
不夸张地说,OpenClaw 的 Memory 机制是我认为最精彩的设计之一。
它精准地解决了 AI Agent 的一个核心痛点:如何让 Agent 拥有持续、可检索的长期记忆,而不是每一次对话都像一次失忆后的初见。
【记忆是智能的基础。没有记忆,就没有真正的智能。】
OpenClaw 通过短期记忆(Session)和长期记忆(Memory)的双层结构,结合强大的混合检索(向量+关键词)能力,实现了一个既轻量又功能强大的记忆系统。
更重要的是,它无需部署和维护复杂的独立向量数据库,仅凭一个增强版的 SQLite 文件就搞定了一切。这才是优秀工程设计的精髓所在:用最简单、最优雅的本地化方案,解决看似复杂的分布式系统问题。这种对技术本质的洞察和简洁实现,值得我们在 云栈社区 深入探讨和学习。
 发表于 2026-3-21 01:19:51
|
查看: 137|
回复: 0
发表于 2026-3-21 01:19:51
|
查看: 137|
回复: 0
