来源: 机器之心
本文约6000字,建议阅读15分钟。
在电商和信息流中,你看到的商品和内容列表,大多不是随机的。它们背后是推荐系统在毫秒内完成的特征理解和排序。当前主流推荐模型多采用判别式范式,即一次性打分来预测用户与商品的交互概率。这种方式高效,但面对兴趣多变、意图复杂的用户时,其局限性开始显现:它更擅长回答“是不是”,而不擅长回答“你真正想要什么,以及为什么”。
近年来,随着大语言模型在语义理解和推理能力上的突破,业界开始探索一种新的范式——生成式推荐。它试图将推荐从“一次判断”转变为“多步生成”。具体而言,模型不再直接为候选商品打分,而是将商品表示为离散的语义ID序列,通过自回归解码逐步生成这些ID。每一步生成都像是一次推理,逐步补全用户意图的线索,最终定位到目标商品。这种范式更贴近人类的决策过程,有望捕捉更细粒度的个性化偏好。
然而,将这一理想转化为工业级应用,挑战重重。生成过程必须“可推理、可控且稳定”。电商场景用户行为信号噪声高、兴趣多样且变化快,如果沿用传统的自回归解码,早期的微小偏差容易被后续步骤不断放大,推理路径可能收敛到少数固定模式,导致生成精度受限、长尾兴趣覆盖不足,最终难以命中用户真实需求。
针对上述核心挑战,阿里国际智能技术团队提出了基于推理增强范式的生成式推荐模型 REG4Rec。该模型从表征学习、训练目标和推理策略三个层面进行了系统性设计,旨在激活生成式推荐的个性化潜力。目前,这项成果已被数据挖掘领域顶级会议 ICDE 2026 接收。

从匹配到生成:关键在于推理能力
阿里团队在生成式推荐领域的探索并非一蹴而就。此前,他们已将残差式语义ID 引入召回阶段的负采样(WWW’25 ESANS),并构建了能处理多模态异构token的行为大模型基座(SIGIR’25 HeterRec)。这些工作表明,生成式范式的核心不仅在于“能生成”,更在于“会推理”。在构建REG4Rec的过程中,团队总结了三大核心挑战:
- 码本信息分布不均,步间语义割裂:现有方法多采用残差层级语义token,易导致语义信息过度集中在浅层,深层token信息量衰减。这使得不同层级的学习难度不一,训练难以稳定收敛。更重要的是,层级间的语义关联弱,后续生成难以有效利用前序信息,每一步都像是在新空间里重新开始。
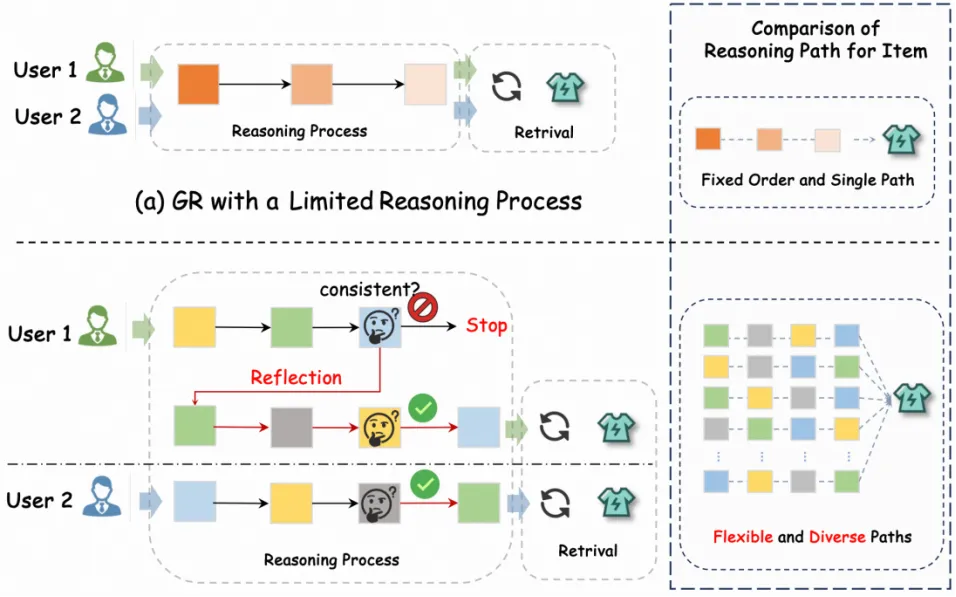
- 解码路径固定,缺乏个性化:现有方法通常固定语义ID的生成顺序,相当于为所有用户预设了同一条推理轨迹。这限制了模型刻画“个体化决策路径”的能力,压缩了个性化表达空间。
- 自回归解码的误差累积:传统生成解码缺乏对当前状态的显式评估与修正机制。一旦早期token出现偏差,错误会在后续步骤中持续传导和放大,导致最终结果与目标相去甚远。
REG4Rec:系统化设计,让推荐“会思考”
为应对这些挑战,REG4Rec从语义ID表征、推理路径建模、训练和部署四个层面进行了端到端的设计。
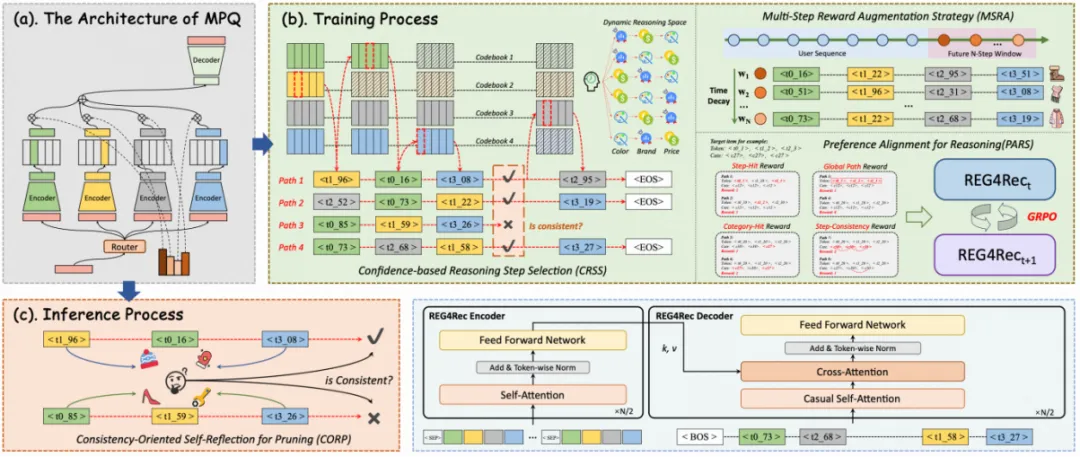
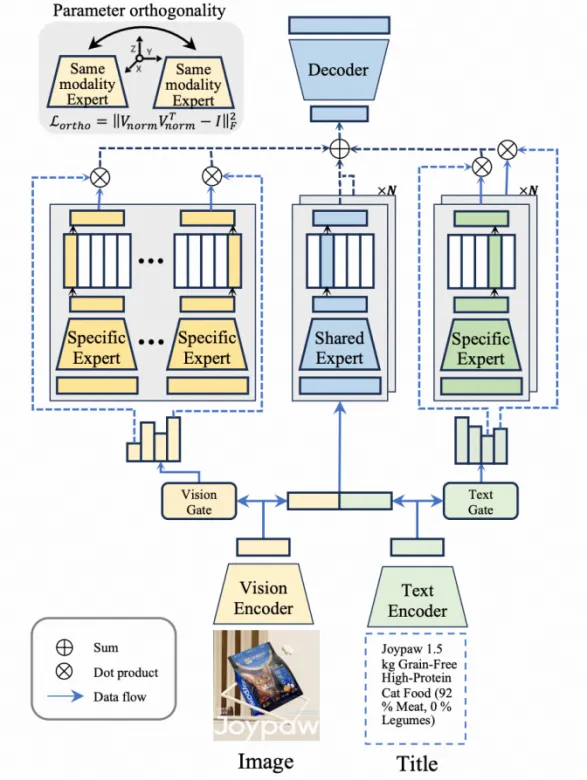
1. 超长并行语义码本 (MMQ)
针对残差码本的缺陷,团队提出了基于MoE的并行语义码本方案 (WSDM’26 MMQ)。该方案通过多个专家从不同语义视角编码商品,生成一组平行的语义token。同时引入路由机制,为各token维度清晰分工,避免语义信息过度集中。这使得码本规模与推理步数能够更稳健地扩展,为长链路推理的Scaling Up奠定基础。模型的目标也从“压缩商品表示”转向“刻画用户兴趣空间”。
2. 上下文感知的动态推理路径
REG4Rec打破了固定解码顺序的限制。在每一步生成前,模型会综合用户历史行为、实时意图及已生成的token前缀,自适应地决定下一步从哪个语义维度(如品牌、价格、颜色)进行解码。这使得解码路径能围绕用户当前关注点动态变化,形成更贴近个体决策逻辑的推理轨迹,显著扩展了可探索的个性化表达空间。
3. 基于GRPO的推理增强训练
受大语言模型中强化学习对齐的启发,REG4Rec在训练阶段引入GRPO框架进行偏好对齐,引导模型探索更优的推理路径。奖励函数精心设计了三类信号:
- 结果奖励:根据生成结果与目标商品语义ID的命中程度给予奖励,缓解误差累积。
- 过程奖励:包含“类目命中奖励”(对齐中间目标)和“语义一致性奖励”(约束推理漂移),保障生成连贯性。
- 集合检索松弛奖励:与线上检索逻辑对齐,只要命中足够多的语义token即给予奖励,提升长尾覆盖与鲁棒性。
4. 线上部署:反思剪枝与多步松弛
在推理阶段,REG4Rec引入“一致性自反思剪枝”机制。在Beam Search扩展路径时,会对生成轨迹进行在线“自检”,及时剪除语义不连贯的路径,优先保留一致性高的候选,提升输出稳定性。
在检索阶段,采用“多步松弛”策略,允许少量token不匹配的候选进入召回集合。这降低了局部预测偏差导致的漏召风险,在几乎不增加开销的情况下,进一步提升了对长尾兴趣和相似商品的覆盖能力。
性能验证:离线领先,线上收益显著
离线实验在多个公开数据集和工业数据集上进行。结果显示,REG4Rec在Recall和NDCG等核心指标上均显著优于现有的判别式与生成式基线。
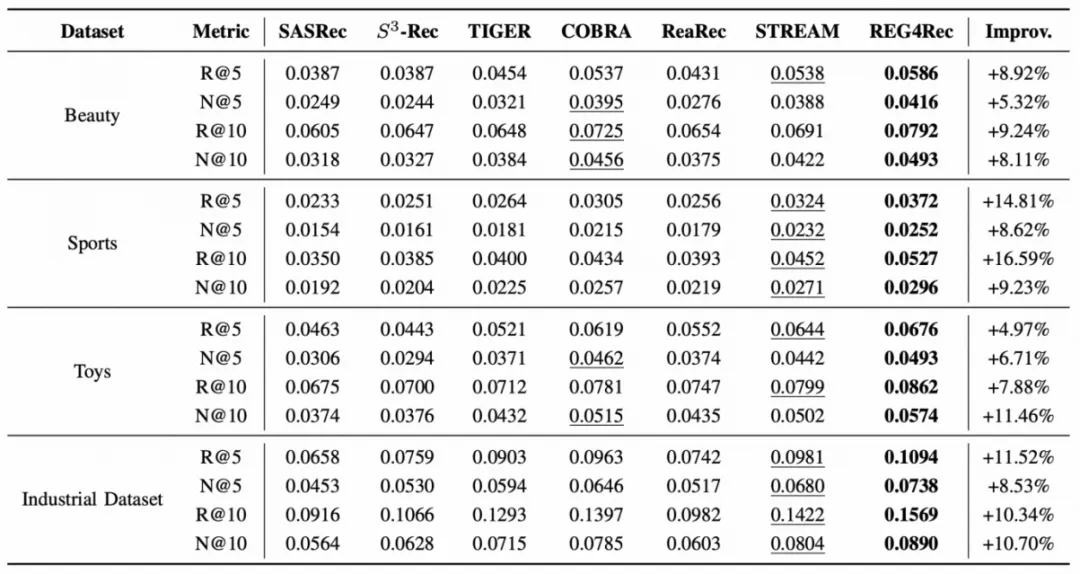
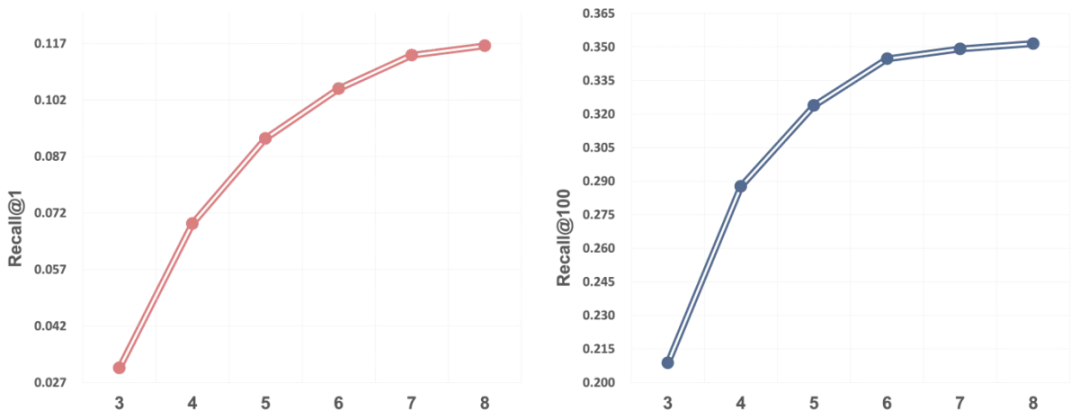
更重要的是,在并行码本支持下,REG4Rec展现出随着推理步数增加而性能持续提升的Scaling Up特性。例如,当推理步数从3步增至5步时,Recall@1提升了123%。这表明多步推理能逐步细化用户意图,带来效果增益。
线上A/B测试在阿里巴巴Lazada的推荐广告场景进行,并已完成全流量推全。REG4Rec带来了显著的商业收益提升。

工程优化:确保大规模业务可用
为使REG4Rec能在工业级场景高效运行,团队从训练和推理两端进行了深度优化。
训练优化聚焦于加速迭代。通过增加IO读取线程、对Embedding查询进行GPU化、采用分层混合精度训练(动态衡量不同层对精度的敏感度)以及算子融合编译等手段,将单次训练时间缩短至原来约一半。

推理优化则结合了LLM的通用优化与生成式推荐的定制化设计。通用优化包括应用KV Cache、量化、FlashAttention等。定制优化则针对生成式召回中beam size增大会导致计算膨胀的问题,引入TreeAttention控制规模,并开发高性能融合算子(基于Triton/CUDA)进一步降低延迟。

总结与展望:生成式推荐走向“深度推理”
REG4Rec的实践表明,生成式推荐正在从“能生成”走向“会推理”。通过将推理过程显式地纳入生成本身,模型得以在多步决策中持续思考和修正,从而更精准地捕捉用户意图。
展望未来,仍有多个方向值得深入探索:
- 更结构化的反思纠偏机制:将反思从规则过滤升级为模型内生的推理能力,让模型能显式识别并修正早期偏差。
- 更具差异性的多目标建模:针对点击、转化等不同价值密度的行为,设计更有针对性的推理路径与训练目标。
- 更自适应的奖励融合机制:探索更智能的信号权衡策略,在命中率、语义连贯性、检索覆盖等多目标间实现帕累托最优。
这项研究不仅是算法上的创新,更是对下一代推荐系统形态的一次有力探索。随着大语言模型与推荐技术的进一步融合,具备深度推理能力的生成式推荐或将成为解决数据挖掘领域个性化难题的关键路径。对前沿AI推荐技术感兴趣的朋友,可以关注云栈社区的“人工智能”板块,获取更多深度讨论和资源。
相关前置工作:
[1]. ESANS: Effective and Semantic-Aware Negative Sampling for Large-Scale Retrieval Systems. WWW ‘25.
[2]. Heterrec: Heterogeneous information transformer for scalable sequential recommendation. SIGIR ‘25.
[3]. MMQ: Multimodal Mixture-of-Quantization Tokenization for Semantic ID Generation and User Behavioral Adaptation. WSDM ‘26.
 发表于 2026-3-28 07:52:30
|
查看: 227|
回复: 0
发表于 2026-3-28 07:52:30
|
查看: 227|
回复: 0
