论文标题:Mixture-of-Depths Attention
论文地址: https://arxiv.org/pdf/2603.15619
代码地址:https://github.com/hustvl/MoDA

创新点
- 针对深度 KV 缓存的非连续读取导致 GPU 利用率低的问题,设计 Flash 兼容的深度 KV 布局,将跨层 KV 按序列位置扁平化存储(长度 T×L),转化为连续块读取,适配 FlashAttention 风格内核。
- 将序列注意力与深度注意力的计算融合在单次前向传播中,共享在线 softmax 状态(无需中间存储),在 64K 序列长度下达到 FlashAttention-2 的 97.3% 效率,且数值精度满足要求。
方法
本文以解决大语言模型深度扩展的信息稀释问题为核心。先从理论层面分析 Transformer 深度流堆叠的现有机制,对比深度残差、深度密集等方法的缺陷,提出融合序列与深度维度的 MoDA 混合注意力机制。该机制让注意力头同时关注当前层序列 KV 和前序层深度 KV,通过单一 softmax 联合归一化并复用参数优化效率。文中还完成了 MoDA 与同类方法的渐近复杂度理论对比。
针对 MoDA 原生实现的硬件效率问题,设计 Flash 兼容的深度 KV 扁平化布局,结合分块感知、分组感知的索引与布局优化,构建共享在线 softmax 状态的融合式计算内核,实现硬件高效的工程化落地。
基于 OLMo2 配方与数据集,在 700M、1.5B 参数量的解码器模型上开展大规模实验。以 OLMo2 为基线,通过变体消融实验确定 MoDA 最优配置,再经模型尺度扩展实验验证其跨尺度性能增益。在多下游任务、多领域验证集上从困惑度、准确率等维度评估效果。
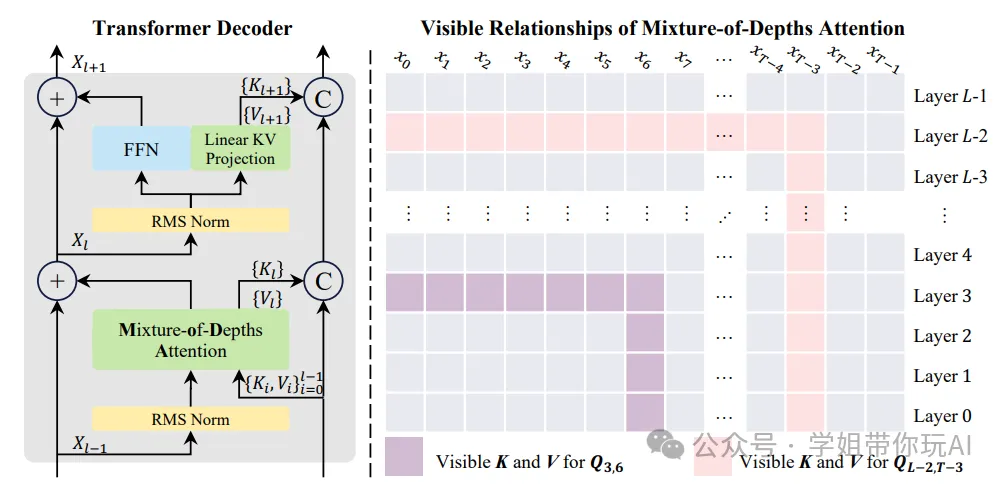
本图直观展示了字节跳动提出的混合深度注意力(MoDA)机制在 Transformer 解码器各层的核心工作形态。它清晰呈现了不同位置查询向量可访问的序列键值(KV)与深度键值(KV)的可见范围,以此体现 MoDA 解决大语言模型信息稀释问题的核心设计。
相比传统因果序列注意力,MoDA 让各层查询除了能访问常规的同层序列 KV 外,还额外允许查询对同一查询位置上前序所有层的深度 KV 对 {Kᵢ,Vᵢ} 进行注意力计算。图中分别标注出了查询向量 Q3,6 和 QL-2,T-3 对应的可见 K、V 集合。
从底层 Layer 0 到高层 Layer L-1,能看到各层会将自身生成的 KV 对留存为深度记忆,后续层的查询可跨层访问这些深度 KV。同时各层仍保留 RMS 归一化、前馈网络投影、线性 KV 投影等 Transformer 解码器的基础模块。深度 KV 与序列 KV 共同构成 MoDA 中查询的注意力对象。
整体架构既延续了 Transformer 解码器的经典层级结构,又通过深度 KV 的跨层可见性实现了动态的深度维度信息聚合。从结构上直观体现了 MoDA 将序列注意力与深度注意力融合的核心设计,也解释了该机制为何能缓解浅层有效特征在深层被稀释的问题。
15 亿参数规模下混合深度注意力(MoDA)与 OLMo2 基线模型的性能对比

本图以 15 亿参数的模型为实验基准,将本文提出的 MoDA 模型与强开源基线模型 OLMo2 进行多维度性能对比,直观呈现了 MoDA 的性能优势。
图中包含四组子图,分别展示了在 C4 数据集上的验证损失,以及 HellaSwag、WinoGrande、ARC-Challenge 三个经典下游任务的准确率表现。横轴均为训练的令牌数量(单位为十亿),纵轴分别对应验证损失值和各任务的准确率百分比。
实验结果清晰显示,在相同的训练令牌规模下,搭载 MoDA 的模型相比 OLMo2 模型,始终拥有更低的 C4 验证损失。同时在三个下游任务上均能实现更高的准确率,且随着训练令牌数量的增加,这种性能优势保持稳定。
这充分证明了在 15 亿参数设置下,MoDA 机制能有效提升模型的语言建模能力和下游任务泛化能力。相比主流的开源基线模型,MoDA 具备显著的性能提升效果。
深度流利用机制的概念对比
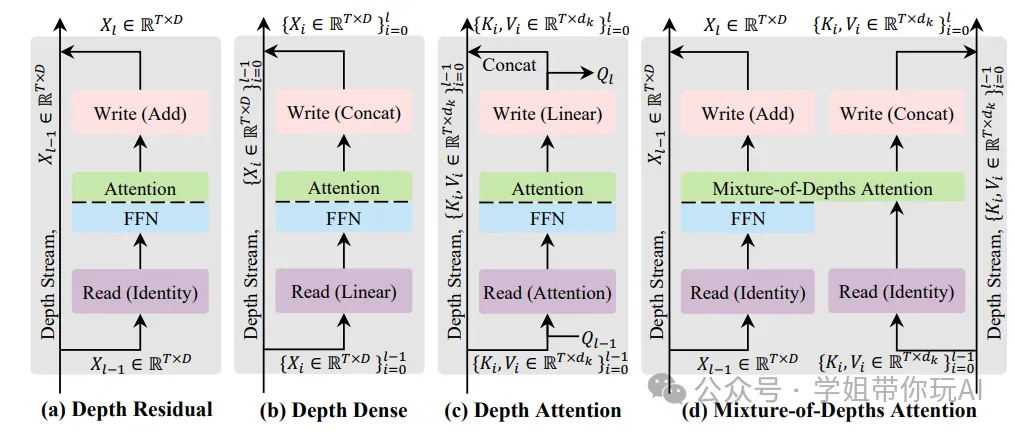
本图从概念层面直观对比了四种 Transformer 深度流的信息利用机制。依次展示了深度残差、深度密集、深度注意力与本文提出的混合深度注意力(MoDA)的核心结构与信息读写逻辑。
四幅子图均围绕 Transformer 深度流的 “读取 - 操作 - 写入” 三步流程展开设计,清晰呈现各机制在深度维度信息处理上的差异。
- 深度残差:以恒等映射读取信息、加法完成写入,仅将深度流压缩为固定尺寸张量,易造成信息稀释。
- 深度密集:通过线性投影读取所有历史表征、拼接完成写入,无信息压缩但计算开销极大。
- 深度注意力:作为过渡形式,以注意力机制数据依赖地读取历史深度 KV 对、拼接当前层 KV 完成写入,降低了开销但未融合序列注意力。
- 混合深度注意力(MoDA):在深度注意力基础上,进一步融合序列与深度注意力,实现更高效的信息聚合。
实验
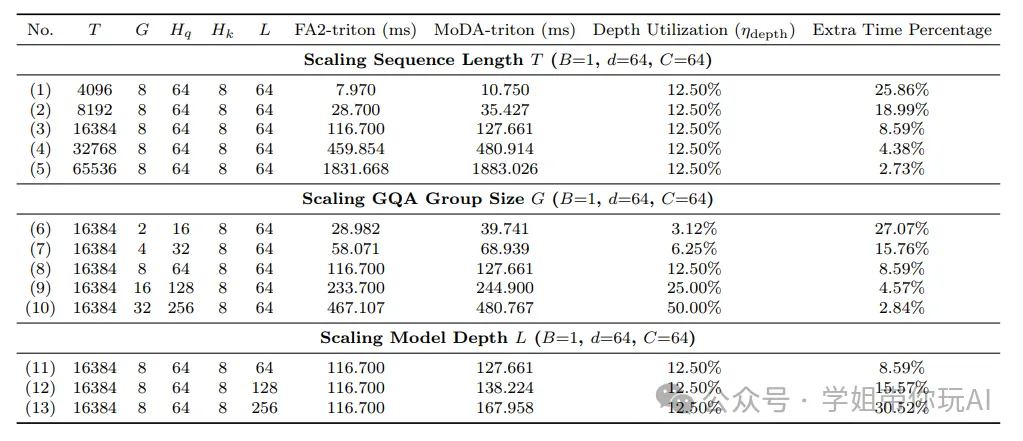
本表以 A100 GPU、bfloat16 数据类型为实验环境,在 “前向 + 反向” 计算设置下,对比了硬件高效版 MoDA 与 FlashAttention-2 Triton 内核的运行效率。
通过设置序列长度 T、GQA 分组大小 G、模型深度 L 三组变量的梯度实验,系统报告了不同配置下两者的运行时间(ms)、MoDA 的深度利用率以及 MoDA 相对 FlashAttention-2 的额外耗时百分比。实验固定批次大小 B=1、头维度 d=64、分块大小 C=64。
- 序列长度扩展:序列长度从 4096 增至 65536 时,MoDA 额外耗时占比从 25.86% 持续降至 2.73%。长序列下深度计算开销被大幅摊薄。
- GQA 分组大小扩展:GQA 分组大小 G 从 2 增至 32 时,深度利用率从 3.12% 提升至 50.00%,额外耗时占比同步从 27.07% 降至 2.84%。分组复用显著提升了深度计算效率。
- 模型深度扩展:模型深度 L 从 64 增至 256 时,FlashAttention-2 运行时间保持恒定,MoDA 运行时间随深度增加逐步上升,额外耗时占比从 8.59% 升至 30.82%。这符合深度 KV 处理量随层数增加而提升的规律。
整体而言,该表量化验证了硬件高效版 MoDA 具备可预测的线性缩放特性。在长序列、高 GQA 分组大小的高利用率场景下,MoDA 能保持与 FlashAttention-2 接近的运行效率。这为 MoDA 的工程化落地提供了详实的效率数据支撑。
本文技术内容由专业社区整理分析,更多深度讨论欢迎访问 云栈社区 的 AI 与深度学习板块。
 发表于 2026-3-28 07:55:42
|
查看: 150|
回复: 0
发表于 2026-3-28 07:55:42
|
查看: 150|
回复: 0
