推荐系统远不止是一个算法,它更像是一条设计精巧的流水线。每个环节都在不同的工程约束下,解决着特定维度的问题。很多入门实现喜欢把“找到相似物品”这一步当作全部,但对于生产级系统而言,关注点分离至关重要——我们需要分层次地管控质量、速度和系统行为。
在动手构建之前,必须想清楚三个基本问题:你要推荐的Item到底是什么(是商品、视频还是新闻?);你关注的用户行为又是什么(点击、购买还是观看时长?);最终衡量系统成功的核心指标如何定义(CTR、转化率还是用户留存)?如果这些定义模糊不清,后续所有的优化都可能偏离方向。
数据层:系统的基石
任何推荐系统都离不开两类核心数据:
- Item数据:包括元信息(如类别、标签)、时间戳(发布时间、更新时间)以及热度指标(浏览量、评分等)。
- 用户数据:主要是用户的交互历史记录(点击过什么、跳过什么)及对应的时间戳。
一个最小化的数据结构示例如下:
items = {
"id": 1,
"genre": ["action", "sci-fi"],
"popularity": 0.8,
"timestamp": 2024
}
user = {
"history": [1, 5, 9],
"recent": [5, 9]
}
候选生成:缩小搜索空间
从成千上万的物品库中直接进行精细排序在工程上是不可行的。因此,第一步的目标是将候选集从数千规模快速缩减到数百。常用手段包括基于内容的过滤、简单规则匹配或高效的向量相似度检索。
candidates = get_similar_items(user["recent"])
这个阶段的核心要求是速度要快、覆盖要广,对精确度的要求可以适当放宽。
过滤层:剔除明显干扰项
在进入精细排序之前,我们需要先做一遍“粗筛”,移除那些明显不该出现的结果。例如,用户已经看过的内容、过时的信息或无效的条目。
filtered_candidates = [
i for i in candidates
if i not in user["history"]
]
别小看这个简单的过滤步骤,它能直接、显著地提升最终推荐列表的整体质量。
特征工程:准备多维决策信号
现在,我们需要为每个通过过滤的候选物品准备一系列用于决策的“信号”。常见的信号维度包括:
- 相似度分数:用户偏好与物品的匹配程度。
- 热度分数:物品的流行度。
- 新鲜度分数:物品发布的时间远近。
这个过程就是将原始数据转化为模型可理解的特征,是决定排序效果的关键一步,与特征工程的核心理念紧密相连。
def compute_features(user, item):
return {
"similarity": sim(user, item),
"popularity": item["popularity"],
"recency": 1 / (current_year - item["timestamp"] + 1)
}
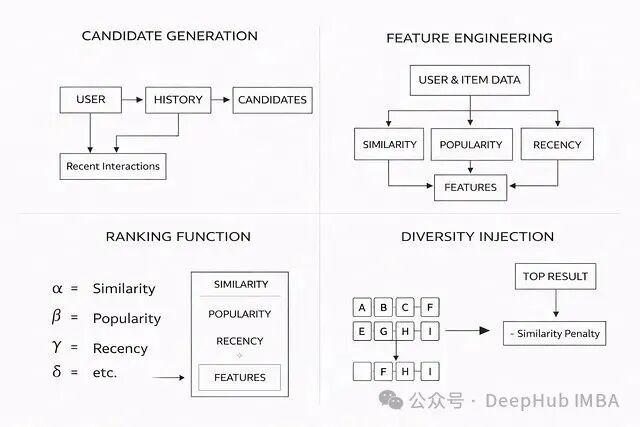
排序层:核心决策引擎
特征准备好了,接下来就需要一个“决策函数”将多个信号融合成一个最终的排序分数。最简单的方式是加权求和:
score = (
0.5 * similarity +
0.3 * popularity +
0.2 * recency
)
这里的权重(0.5, 0.3, 0.2)并不是一成不变的魔法数字。它们需要根据业务目标、用户群体行为模式以及持续的A/B测试结果进行动态调整和优化。
多样性注入:打破“信息茧房”
如果只按分数从高到低输出,推荐结果很容易坍缩到极其相似的一类物品中,使用户感到厌倦。因此,我们需要引入多样性控制。一个简单有效的策略是,在已选出部分结果后,对新候选物品施加一个与已选集合的相似度惩罚。
adjusted_score = score - λ * similarity_with_selected
最终选择与输出
经过以上所有步骤,我们得到一个带有最终调整分数的候选列表。现在,只需选出得分最高的前 N 个:
final_recommendations = sorted(candidates, key=lambda x: x["score"], reverse=True)[:10]
这个列表就是最终呈现给用户的推荐结果。
反馈收集与系统更新
一个没有反馈环的系统是无法进步的。我们必须追踪用户对推荐结果的实际反应,核心事件通常包括:点击、跳过、停留时长等。
feedback = {
"clicked": [item_id],
"skipped": [item_id]
}
这些反馈数据是系统自适应的燃料。例如,我们可以根据点击和跳过行为来动态调整排序模型中不同特征的权重:
if item in feedback["clicked"]:
increase_weight("similarity")
if item in feedback["skipped"]:
decrease_weight("similarity")
完整的Pipeline视图
将以上所有模块串联起来,就构成了一个端到端的推荐系统Pipeline:
用户请求 → 候选生成 → 过滤 → 特征计算 → 排序 → 多样性调整 → 输出结果 → 收集反馈 → 更新模型/权重
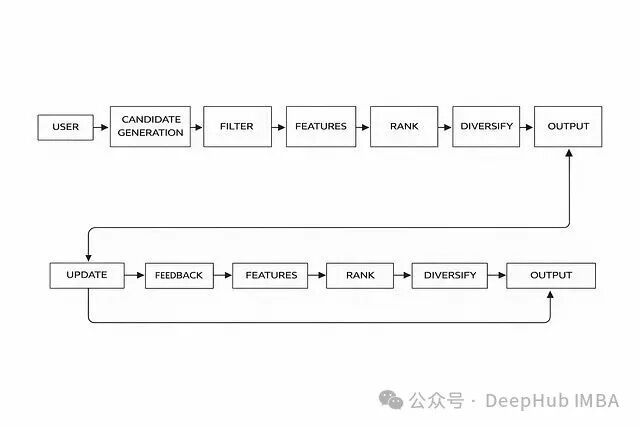
这种分层架构的最大优势在于模块化。每个阶段职责清晰,可以独立进行技术选型、替换和优化,而不会牵一发而动全身。
总结
构建一个推荐系统,其核心挑战不在于找到一个“最准”的相似度算法,而在于如何在速度、多样性、新鲜度等多重约束下,持续选出“最合适”的物品。一个具备清晰分层(有效过滤、多信号排序、反馈闭环)和模块化设计的系统,才真正有能力从实验室走向生产环境,应对真实世界的复杂需求。如果你对构建这样的数据驱动系统感兴趣,欢迎到云栈社区与更多开发者交流实战经验。
 发表于 2026-4-11 05:48:03
|
查看: 148|
回复: 0
发表于 2026-4-11 05:48:03
|
查看: 148|
回复: 0
