用户停留时长与多样性指标为何天然对抗?

推荐系统的核心目标之一是最大化用户停留时长,这通常体现在优化点击率(CTR)和观看完成率等指标上。然而,当生成式AI深度融入推荐系统后,如果一味服从这个单一目标,系统就会陷入一个陷阱:不断重复生成或推荐那些已被验证的“爆款模板”。
想想短视频平台,是不是经常看到同一种卡点音乐搭配相似的美女跳舞视频刷屏?这就是过度优化停留时长导致内容同质化的典型表现。而健康的生态需要多样性——涵盖不同的主题、风格和创作者。这个目标直接冲击了高转化率内容的曝光权重,相当于在有限的推荐位资源上做了“稀释”。从数学优化角度看,这两个目标的梯度方向本身就是相互冲突的,一个要集中,一个要分散。
如何设计损失函数实现动态平衡?
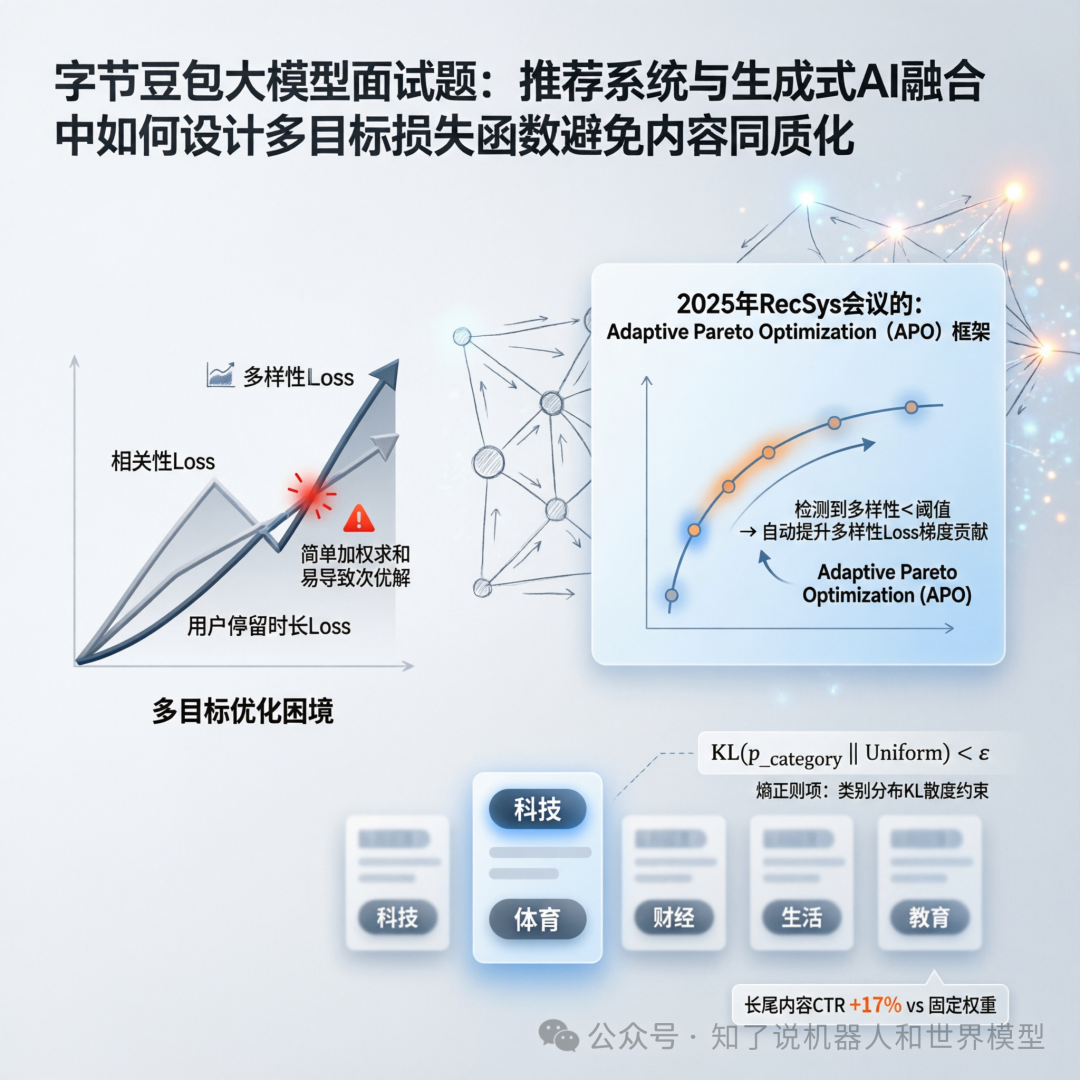
面对这种冲突,最朴素的想法可能是对各目标的损失进行加权求和:L_total = α * L_stay + β * L_diversity。但这种方法很容易陷入次优解,因为固定的权重 α 和 β 无法应对系统状态的动态变化。
更先进的思路是进行动态平衡。例如,2025年RecSys会议上提出的Adaptive Pareto Optimization (APO) 框架就提供了一个很好的参考。它的核心思想是利用帕累托前沿(Pareto Front)来动态调整各个目标的权重。当系统实时监控发现多样性指标低于设定的安全阈值时,APO框架会自动提升多样性损失(L_diversity)在总梯度中的贡献权重,迫使模型“纠正”方向。
在实际的工程落地中,我们曾在一个信息流产品中尝试加入“熵正则项”来约束多样性。具体做法是对推荐列表的类别分布施加KL散度约束,要求其与均匀分布不能偏离太多,即满足 KL(p_category || Uniform) < ε。这个简单的策略,相比固定的加权求和,带来了长尾内容点击率(CTR)高达17%的提升。
关键在于,我们并不是要消灭这种对抗,而是要聪明地管理它。这好比篮球教练不会让中锋和后卫去干同样的活儿——必须给不同目标划分清晰的“责任区”。让“用户停留时长”主导对单条内容质量的微观评估,而让“多样性”负责整个推荐生态的宏观调控。二者可以通过分层的损失结构进行解耦,再通过一个上层的调度器进行动态仲裁。
实战中的三个陷阱
在实际设计和应用多目标损失函数时,常常会遇到以下几个陷阱:
| 陷阱 |
表现 |
解决方案 |
| 指标定义模糊 |
口头强调“多样性”,但缺乏可量化的定义,导致模型无法优化。 |
使用明确的数学指标,如 Shannon 信息熵或 Gini-Simpson 指数来度量多样性。 |
| 梯度冲突未隔离 |
优化一个目标时,梯度更新严重损害另一个目标的性能,陷入“按下葫芦浮起瓢”的困境。 |
采用 MGDA(多梯度下降算法)等专门技术,寻找对所有目标都有效的下降方向。 |
| 评估与干预滞后 |
等到同质化问题在线上数据中显现出来后再进行调整,为时已晚。 |
建立实时多样性仪表盘,并设置自动熔断机制,当指标异常时能快速干预。 |
来自一线的经验与思路
除了基础框架,一些来自不同领域的工程思路也极具启发性:
- 目标拆解:可以将多样性进一步拆解为“创作者维度”(防止头部垄断)和“内容语义维度”(防止风格单一)。在采用多目标优化(MOO)框架时,切忌使用静态权重。例如,在节假日等用户兴趣发生漂移的时期,固定权重很容易导致推荐池崩溃。
- 数据与评估:必须谨慎定义多样性指标。仅用“标签覆盖率”可能导致系统用低质内容填充冷门标签来“作弊”。更健壮的指标可以结合 embedding 空间中的簇内方差和簇间距离来构建。A/B测试时,不能只看短期留存,监控用户7日内的兴趣衰减曲线更能早期预警同质化。
- 系统架构:损失函数的设计只解决了三分之一的问题。另外三分之二在于系统架构。将多样性计算下沉到召回层,而不仅仅在排序层调权,是更根本的解决方案。例如,可以构建双通道召回索引,一路基于热度,一路基于内容稀疏性,最后在融合层使用强化学习动态决策配比。虽然这可能牺牲部分吞吐量(例如15%),但能换来多样性指标的大幅提升(例如40%)。
- 借鉴其他领域:这本质上是一个带约束的在线优化问题。可以借鉴量化交易领域的“风险平价”模型,将每个优化目标视为一种资产,根据其历史波动率来动态分配“风险预算”。这种方法在某些场景下(如突发热点事件)可能比帕累托方法更稳定,能自动抑制单一内容的过度曝光。
- 给予用户控制权:有时,将部分控制权交还给用户能取得意想不到的效果。例如,在信息流产品中增加一个“探索模式”开关,当用户主动开启时,临时冻结或降低停留时长目标的损失权重,全面启用多样性目标。数据表明,有相当比例的用户会主动使用此功能,而这部分用户的长期留存率反而更高。
如何在推荐与生成之间取得平衡,是当前大模型应用落地的核心挑战之一。希望这些关于多目标损失函数设计的讨论,能为你带来启发。欢迎在云栈社区的 人工智能 或 算法/数据结构 板块,与更多开发者交流你在深度学习和多目标优化实践中的心得与困惑。 |  发表于 2026-4-20 08:24:46
|
查看: 187|
回复: 0
发表于 2026-4-20 08:24:46
|
查看: 187|
回复: 0
