昨日晚间,阿里巴巴Qwen团队正式开源了Qwen3.5小型模型系列,包括Qwen3.5-0.8B、Qwen3.5-2B、Qwen3.5-4B和Qwen3.5-9B四款尺寸。该系列模型专为端侧设备设计,可在消费级硬件上运行。

模型发布后迅速引发技术社区热议。特斯拉CEO埃隆·马斯克也现身评论区,并留下了“Impressive intelligence density”(令人惊叹的智能密度)的评价。
性能基准:小模型,大能耐
根据官方发布的基准测试结果,Qwen3.5-9B在多项关键评测中表现突出。
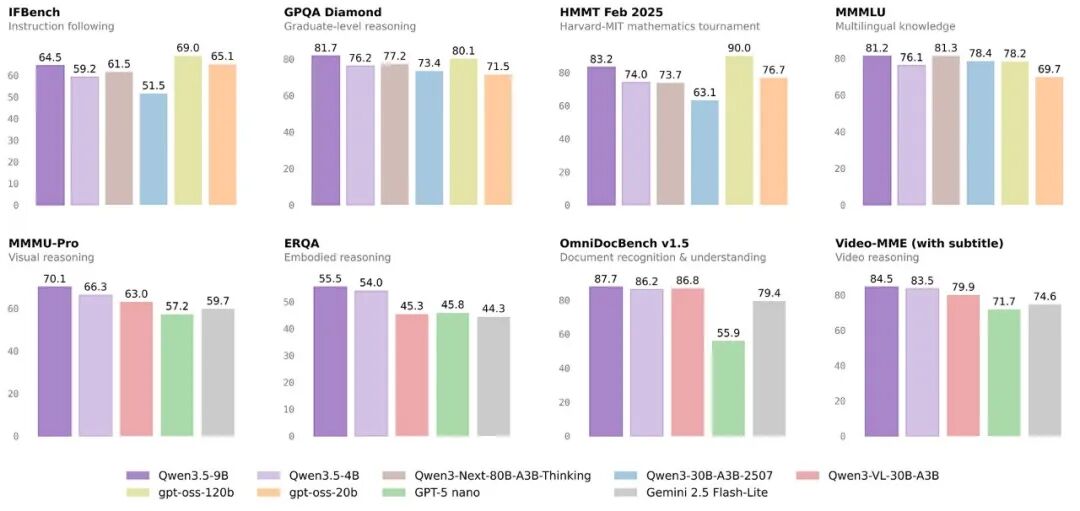
在指令跟随(IFBench)、研究生水平推理(GPQA Diamond)、数学竞赛(HMMT)、视觉推理(MMMU-Pro)等多个维度上,Qwen3.5-9B的表现超越了GPT-OSS-20B、GPT-5 nano、Gemini 2.5 Flash-Lite等知名模型,甚至在某些任务上领先于参数量大得多的自家前辈模型(如Qwen3-Next-80B)。
作为更小的版本,Qwen3.5-4B的表现也已接近9B模型,在多语言知识、视觉推理、文档理解等任务上可与更大模型媲美,但在纯数学推理等复杂任务上存在差距,这也是小规模模型的普遍挑战。
模型定位:从边缘设备到轻量级智能体
该系列所有模型均基于统一的Qwen3.5基座架构开发,采用Apache 2.0协议开源,支持商用,并允许进行LoRA或全量微调。其设计目标明确,旨在以更少的计算资源提供可用的智能:
- 0.8B/2B版本:主打小巧与高速,是移动设备、IoT边缘设备部署以及需要低延迟实时交互场景的首选。
- 4B版本:具备更强的性能和多模态能力,适合作为轻量级AI智能体的核心“大脑”,在性能与资源消耗间取得平衡。
- 9B版本:结构紧凑,但官方称其性能可媲美体积大13倍的gpt-oss-120B模型。它适合需要较高智能水平但显存资源受限的服务器端部署,是性价比较高的通用模型选择。
目前,所有模型及其基座版本均已在国内的魔搭社区和国际的Hugging Face平台开源。对于热衷于探索前沿项目的开发者来说,这无疑是一次上手实践的绝佳机会。
开发者热议:笔记本跑赢云端?手机也能用?
模型一经发布,立即吸引了全球开发者的体验与讨论。
一位开发者指出,9B模型在MMMU-Pro基准测试上以13分的优势击败GPT-5-Nano是其最大亮点,这意味着一款能在笔记本电脑上本地运行的模型,性能却超越了需要云端部署的旗舰级“纳米”模型,证明了“架构优势大于参数数量”。
另一位开发者展示了更具想象力的应用场景:在Mac Mini上结合Qwen 3.5与OpenClaw等工具,可以打造一个24/7不间断工作的“AI员工”,其成本低于雇佣一名初级人类员工月薪。
性能实测方面,有开发者分享,在AMD Ryzen™ AI Max+ 395平台使用Q4_K_XL量化,并开启完整的256K上下文窗口时,Qwen3.5-9B的推理速度可达约30 token/s,且所需显存低于16GB。他对模型在多语言、通用知识和视觉输入上的强劲表现感到惊讶。
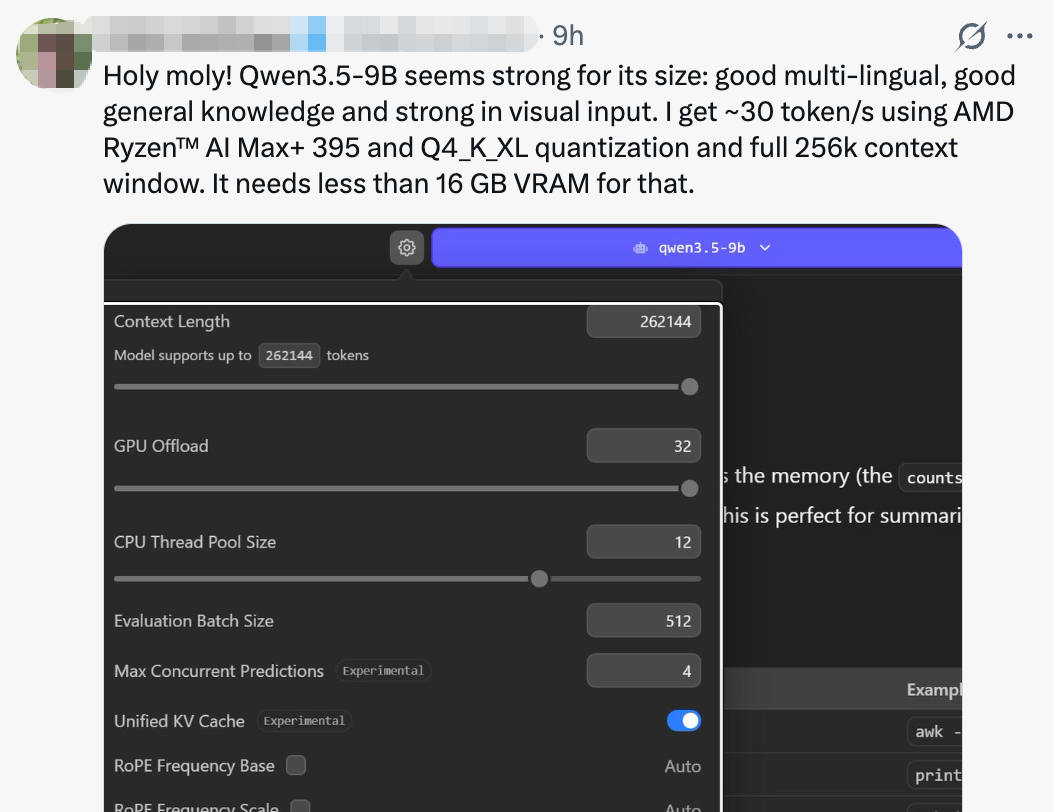
更有网友声称,该系列模型甚至能在手机上运行,引发了关于“如何在iPhone上运行”的热烈讨论。

当然,也有开发者保持了冷静的审视,指出例如4B模型在GPQA Diamond(研究生水平推理)等困难基准上的准确率仍有较大提升空间,提醒社区需理性看待小型模型当前的能力边界。
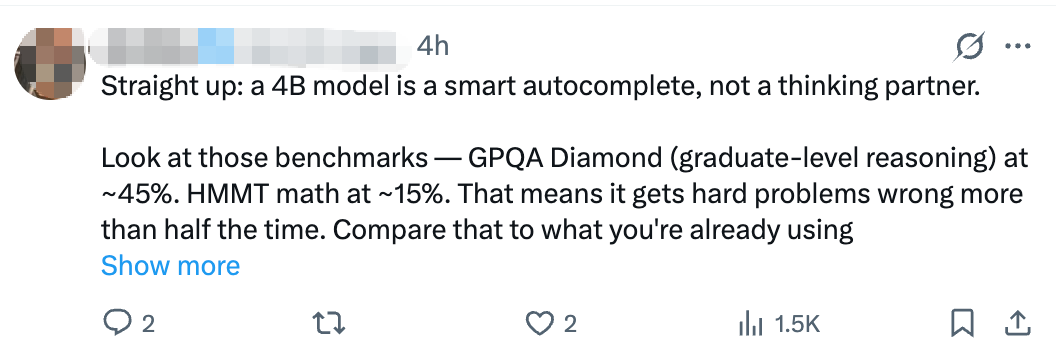
尽管如此,小型模型在特定能力上已达到部分云端部署模型的水平,这已足够让其在实际的端边侧应用场景中发挥价值。
模型家族与获取
至此,Qwen3.5模型家族已形成较为完整的阵容:
- 1个大尺寸模型:Qwen3.5-397B-A17B
- 3个中型尺寸模型:Qwen3.5-122-A10B、Qwen3.5-35B-A3B、Qwen3.5-27B
- 4个小尺寸模型:Qwen3.5-0.8B、Qwen3.5-2B、Qwen3.5-4B、Qwen3.5-9B
模型获取地址:
附:Qwen3.5-9B与Qwen3.5-4B在更广泛基准测试中的完整成绩表。
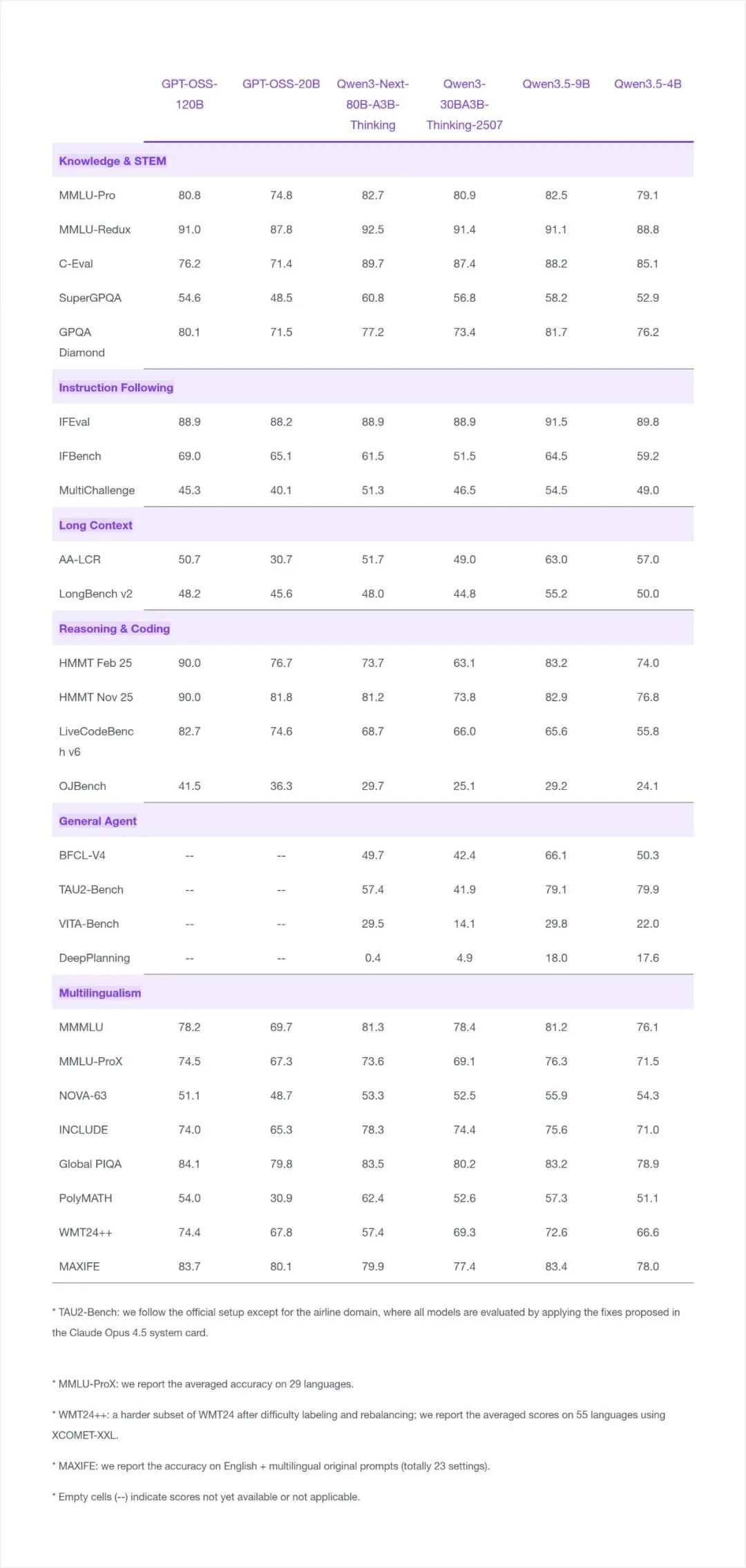
模型的快速迭代与开源释放,为人工智能的应用落地提供了更多轻量级选择。对于广大开发者和技术爱好者而言,这意味着可以在更低的硬件门槛上,进行模型微调、智能体构建等实验与创新。想了解更多前沿技术动态与实践心得,欢迎持续关注云栈社区。 |  发表于 2026-3-4 08:31:28
|
查看: 280|
回复: 0
发表于 2026-3-4 08:31:28
|
查看: 280|
回复: 0
