在AI基础设施领域,今年的硬件产品呈现两大热点。上半年备受关注的是大模型一体机,而下半年,焦点则转向了性能强劲的“超节点”系统。

众多厂商相继推出了各自的超节点产品。然而,随着这些产品的发布与实际部署,相关的讨论与争议也逐渐增多。
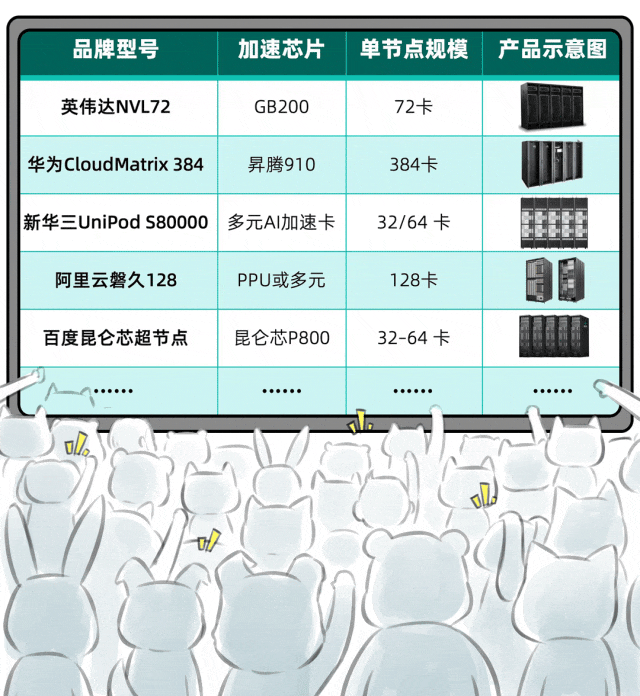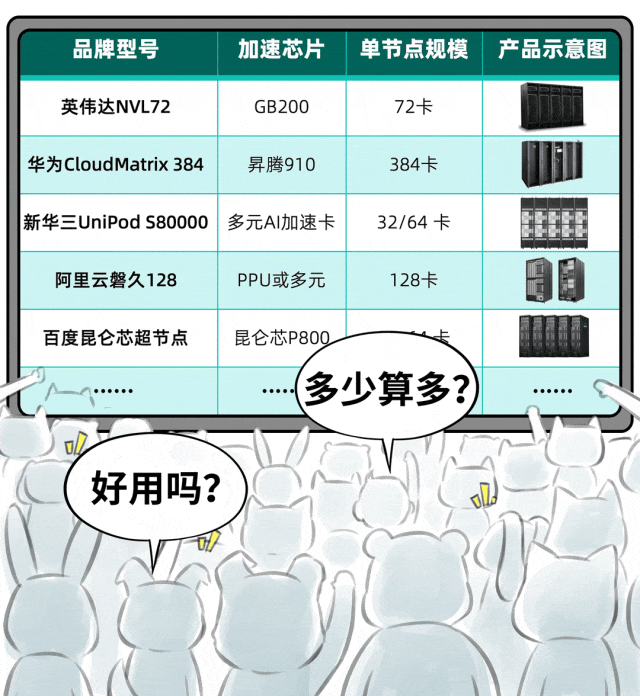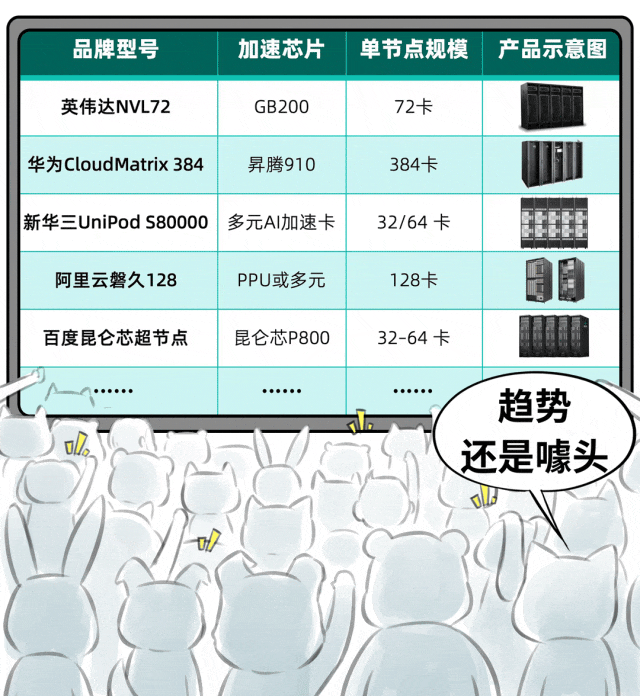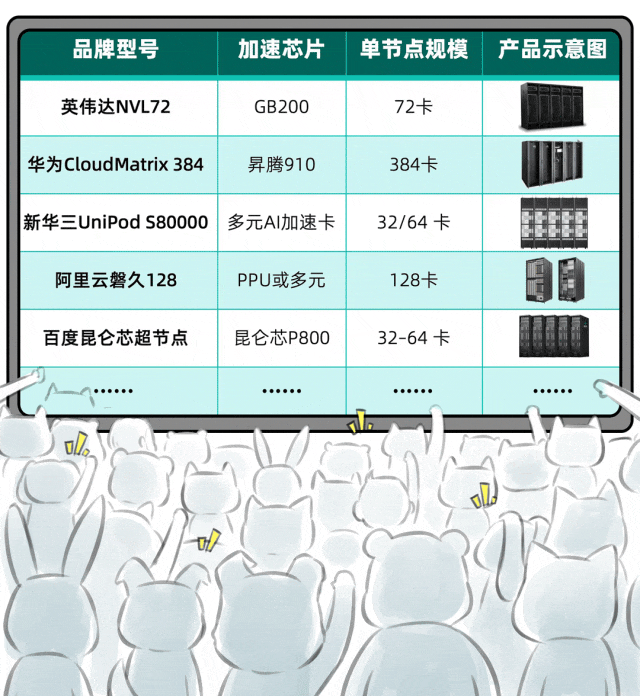
那么,超节点究竟是什么?它在实际应用中价值如何?本文将进行系统性的探讨。
什么是超节点?
首先需要明确一个技术限制:一台标准服务器由于受CPU PCIe通道数、机箱空间、散热及供电等工程因素制约,通常最多只能容纳16张GPU卡。

因此,这类传统服务器早期被称为GPU服务器或AI服务器,如今预装大模型软件后,则常被称为AI一体机或大模型一体机。今年上半年涌现的各类一体机,基本都属于这个范畴。

若想突破上述限制,集成更多GPU卡,就必须在卡间互联技术上寻求突破。
其核心在于采用专门的Scale-Up网络(具备高带宽、低时延、强一致性、内存语义、对等直连等特点,远超RoCE或IB网络),将更多GPU连接起来,定制成一台更大的“单一逻辑”设备。

通常,我们将基于Scale-Up网络实现GPU间高速互联、规模在16卡以上的系统,定义为超节点。

为什么需要超节点?
一个基本事实是:当前绝大多数大模型应用场景,理论上都可以通过多台8卡服务器组建集群(Scale-Out)来完成。即便是参数量巨大的模型,若采用MoE架构并需要张量并行、专家并行等技术,单台8卡或16卡服务器遭遇显存墙时,依然可以通过多台机器基于InfiniBand或RoCE网络组成Scale-Out集群,共同承载被切分后的模型。


然而,这种分布式组网方式存在固有代价。机器间的网络带宽和延迟,无法与单台设备内部的总线互联相比,效率差距显著。
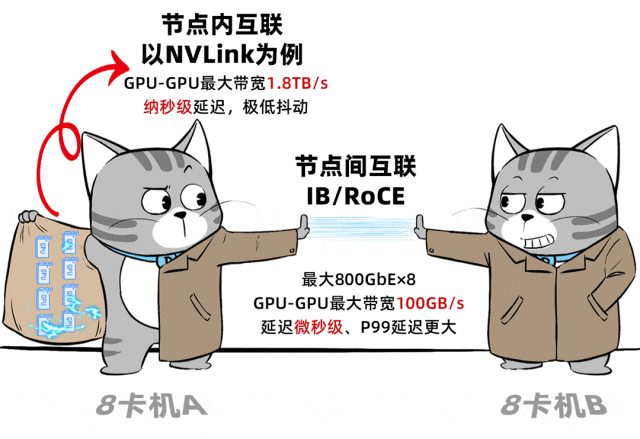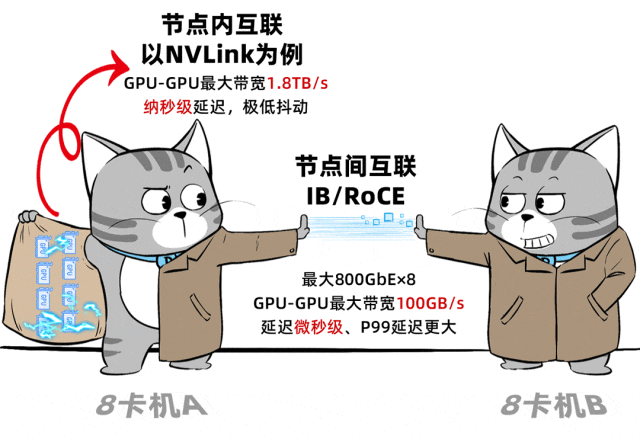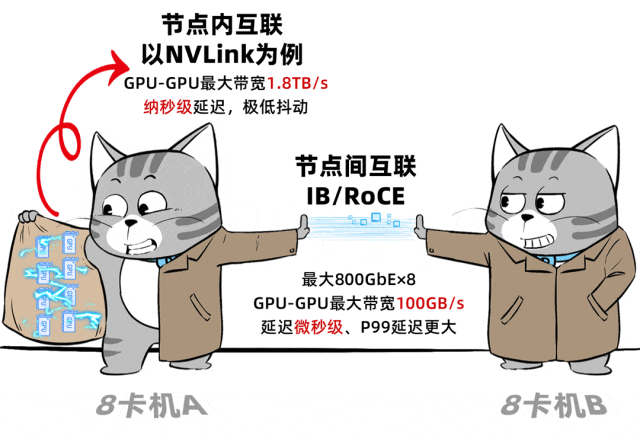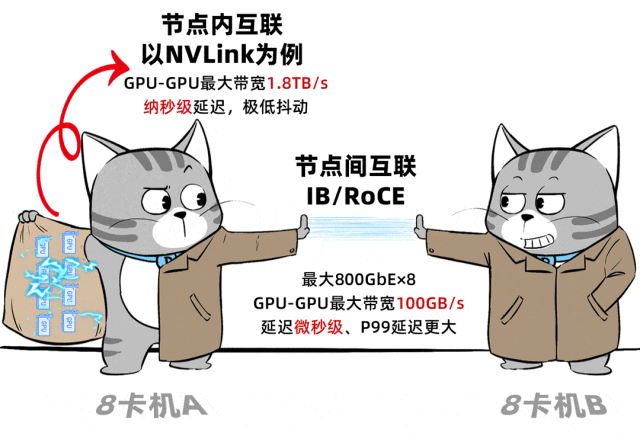
这种带宽与延迟的鸿沟,导致每个计算节点上的显存和内存只能独立工作,无法跨节点形成统一的、可共享的显存池或内存池。在张量并行、专家并行等需要频繁大规模跨卡通信的场景下,训练和推理效率就会大打折扣。

超节点的优势正在于此。通过采用专用的Scale-Up互联标准(如NVLink或开放的UALink),GPU间的通信“天堑变通途”。超节点内所有GPU可以直接进行高速的读写及原子操作,从而形成一个庞大的单体内存/显存域,宛如一张拥有海量核心和显存的“巨型显卡”。

这使得超节点内各GPU能够像同一张卡上的不同核心一样,进行高频、低延迟的数据交换与控制协同。面对超大参数模型、复杂的并行策略、高昂的All-to-All/All-Reduce通信开销以及巨大的KV Cache压力,超节点都能提供更优的处理能力。

超节点是否越大越好?
既然超节点能力强大,是否意味着单个节点的规模越大越好?结论是否定的,盲目追求超大单体规模会带来一系列问题:
1. 成本问题
Scale-Up网络(如NVSwitch等新互联技术)本身的成本就高于Scale-Out网络(如RoCE或IB交换机)。随着节点内GPU数量增加,实现全互联所需的线缆更复杂、距离更长,线缆密度和长度会非线性地推高整体成本。
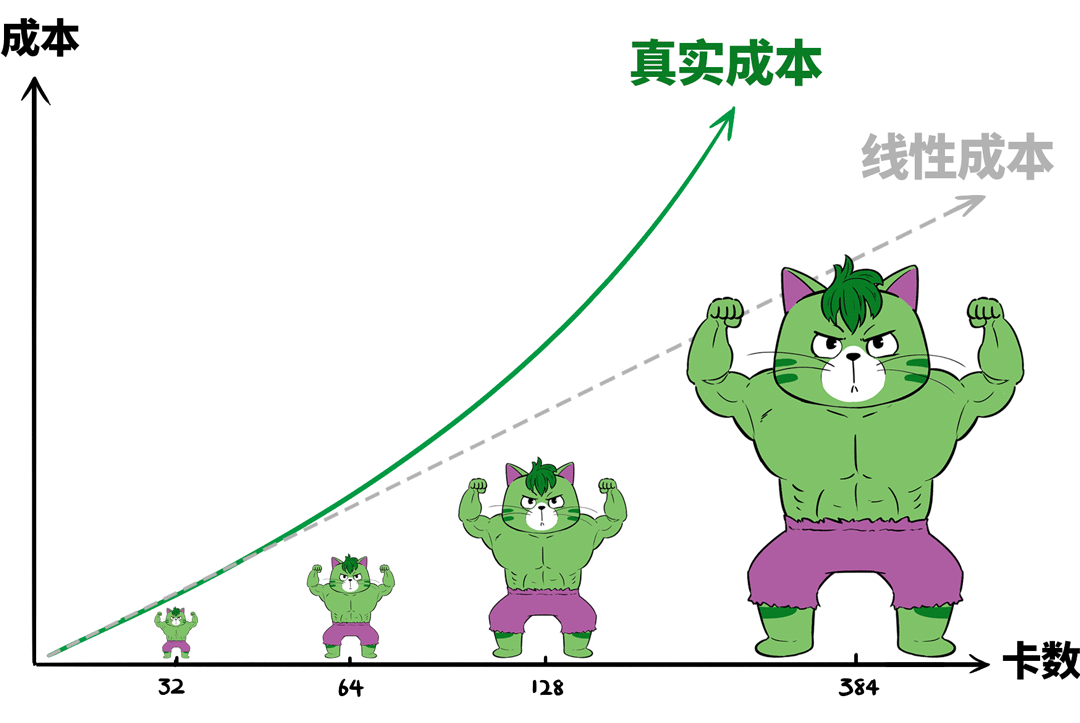
2. 故障率与爆炸半径
节点规模越大,内部关键元器件和连接点就越多,潜在故障点也随之增加(例如大规模光互联)。故障风险上升的同时,为提高系统容错性所付出的额外成本也会急剧增长。

此外,单个节点的故障域会变得过大。一旦发生故障,影响范围更广,业务中断的“爆炸半径”更大。

↓

3. 可维护性与可交付性
过大的超节点往往需要定制高规格机箱、散热、供电及冗余系统,这不仅增加了资本支出(Capex),也显著提升了交付与运维的复杂度与成本。甚至,传统数据中心可能在空间、承重、制冷和供电等方面都需要进行改造,才能适配此类大型设备。

因此,超节点虽好,但需合理规划规模。
如何寻求最佳平衡点?
超节点优势明显,但过大又伴生诸多问题,那么多大规模最为合适?其商业化落地的核心铁律是:每Token成本。
构建AI基础设施的关键在于提升算力利用率,而非盲目追求设备的“庞然大物”所带来的情绪价值。

如前所述,没有Scale-Out方案搞不定的场景,但“搞得定”不等于“搞得好”,优劣需要用每Token成本这把尺子来衡量。

对于那些对节点间通信延迟极度敏感的场景,例如以DeepSeek为代表的大规模MoE模型推理,其通信量大、时延要求苛刻。在此类场景下,采用超节点才有机会获得显著的每Token成本优势。

至于单节点具体多少卡合适,这取决于主流模型的技术特点。在当前国内企业级本地化部署实践中,DeepSeek推理是广泛应用的一类场景,其MoE架构的专家并行、P/D分离部署等特点,要求综合考虑互联成本、通信开销、可靠性,并结合国产AI芯片的性能,找到一个“甜点区”。

基于现有工程经验,对于此类场景,单节点32卡至64卡是一个相对优化的选择。以典型的32卡超节点为例,它可以容纳32路专家并行,将大规模跨卡通信严格限制在一个机箱内部,极大降低通信开销。
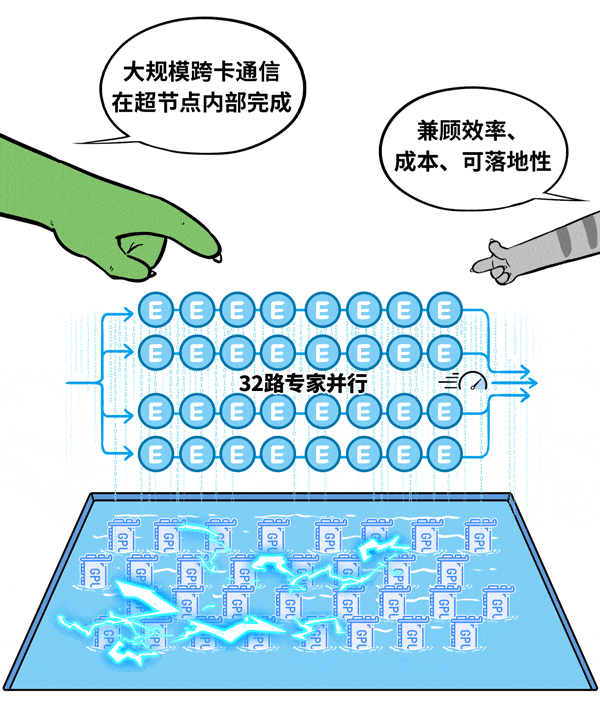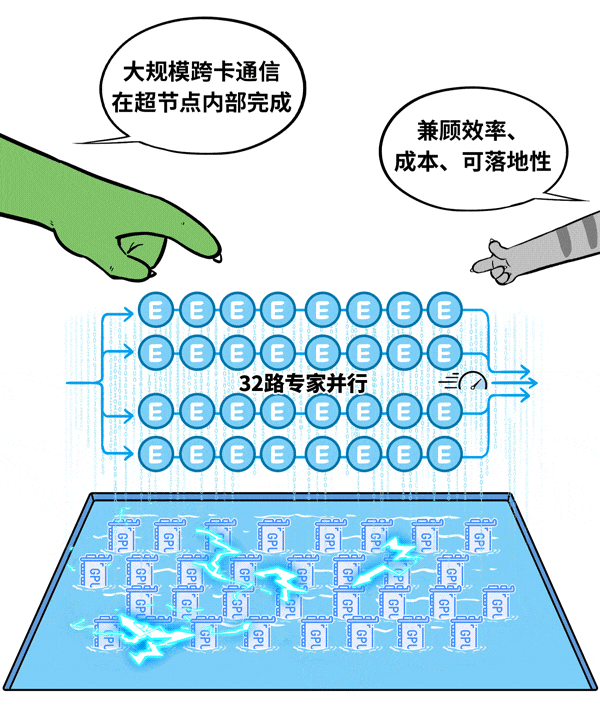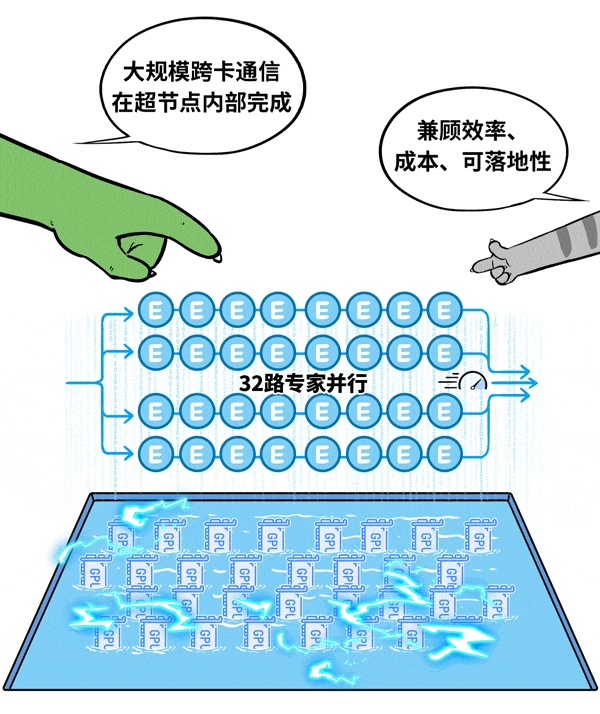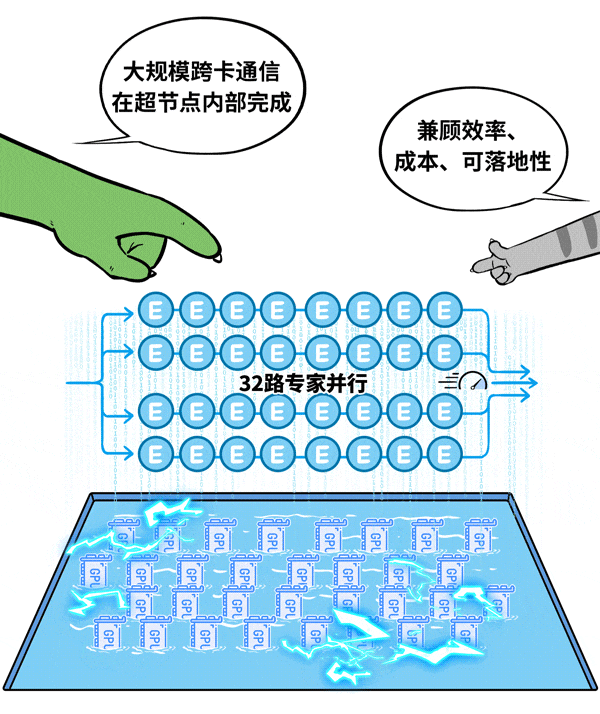
针对这一用例,新华三利用其超节点产品UniPod S80000进行了实际落地验证,取得了良好的效果。

确定了最优的Scale-Up域(单节点规模)后,可以根据实际的算力与并发需求,将多台超节点通过RoCE网络再次组建为Scale-Out集群。这种分层异构的集群架构不仅能实现最优的每Token成本,而且具备优异的可扩展性、易于运维部署,并能提供接近线性的性能增长。

当然,我们必须认识到,当前大模型技术与产品正以月甚至周为单位快速迭代。今天的最优架构明天可能就会过时。未来的主流模型是否仍是Transformer,MoE架构是否会持续适用,Scaling Law能否一直有效,都尚无定论。因此,8卡服务器与超节点之间、小节点与大节点之间的技术路线之争将长期存在,我们需要保持关注,与时俱进。

总结
- 能力覆盖:超节点能处理的大模型业务,普通8卡机构建的Scale-Out集群同样能够完成。
- 优势场景:只有在跨卡通信开销巨大的特定场景下,超节点才能体现出明显的性能与成本优势。
- 评估标准:超节点落地的核心评判标准是算力利用率和每Token成本,应避免被设备的“高端、大气”等情绪价值左右决策。
- 规模警示:超节点的Scale-Up域并非越大越好。“大”意味着更高的额外成本、更大的故障影响范围、更复杂的运维部署以及潜在的供应商锁定风险。
- 实践建议:结合当前国内企业级市场的主流模型生态,32卡至64卡规模的超节点是兼顾高算力利用率、可扩展性、可维护性、故障域控制及国产化因素的较优落地选择。
 发表于 2025-12-25 05:02:11
|
查看: 454|
回复: 0
发表于 2025-12-25 05:02:11
|
查看: 454|
回复: 0
