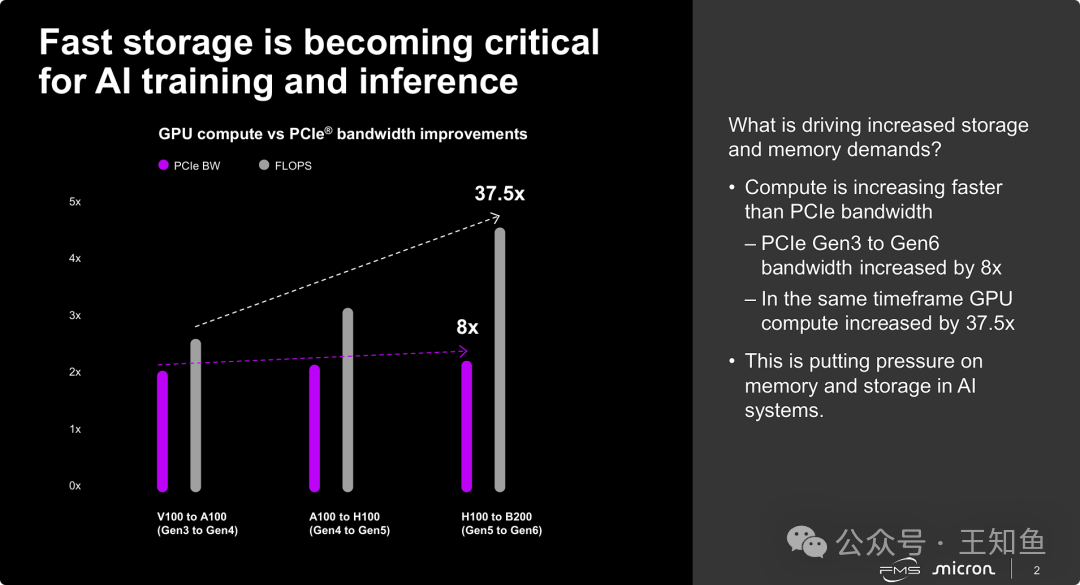
当前AI硬件架构正面临严峻的“I/O墙”(I/O Wall)或带宽瓶颈问题。计算能力(GPU FLOPS)呈指数级爆发,在数年间增长了37.5倍,但数据传输通道(PCIe带宽)仅实现了8倍的线性增长。这种严重失衡导致系统瓶颈从“计算”向“数据传输(I/O)”转移,强大的GPU因“喂不饱”数据而性能闲置。因此,AI系统迫切需要更高速的本地存储和内存技术来填补鸿沟,这也是存储厂商重点发力的技术背景。

为应对多样化需求,美光推出了清晰的SSD产品矩阵,尤其是在人工智能领域进行了针对性布局。其产品线围绕三个维度展开:针对AI/混合负载的“高性能”型、面向通用计算的“主流”型,以及追求存储密度的“大容量”型。其中,9000系列明确支持下一代PCIe Gen6标准,旨在通过极致带宽解决AI算力增长快于带宽的核心矛盾。这种细分策略有助于用户根据业务需求(追求极致IOPS还是优化每TB成本)进行精准选型。
数据中心超高性能型
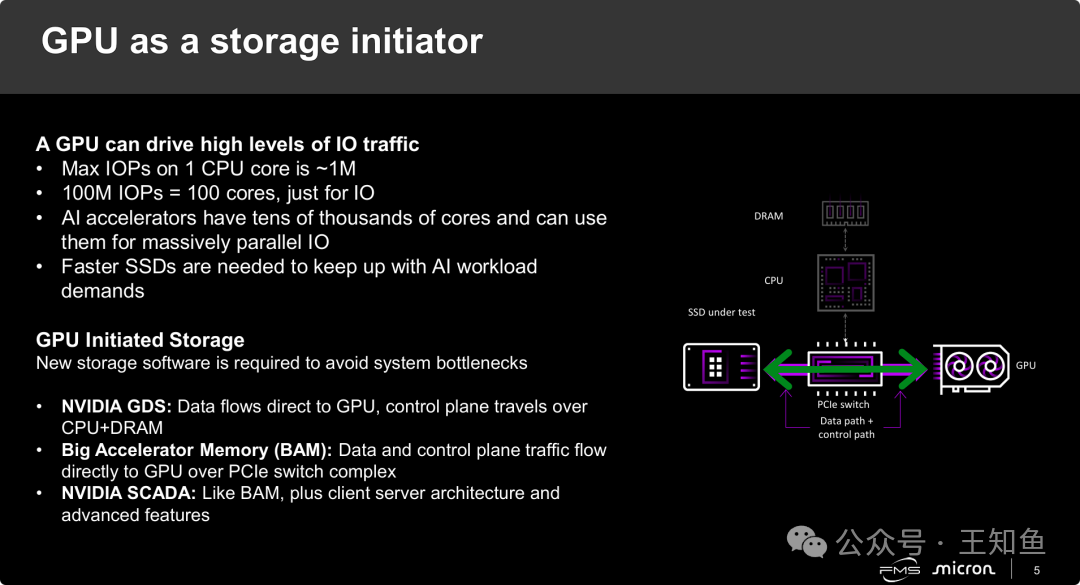
传统的由CPU处理所有存储I/O请求的方式,在应对PCIe Gen5/Gen6高速SSD时已成为瓶颈。为了充分利用SSD带宽,CPU算力几乎会被消耗殆尽。解决方案是将存储控制权移交给GPU:不仅让数据直通(如NVIDIA的GDS技术),更进一步实现由GPU发起存储访问(GPU Initiated Storage / BaM)。在这种架构下,GPU自己生成NVMe队列请求,直接读取SSD,实现了全路径直通。这也对SSD提出了更高要求:需要具备极高的随机读取性能(IOPS)和低延迟,以承受来自GPU数万个线程的并发访问。
可以预见,高性能存储的下一个竞争焦点将围绕加速卡的I/O调度展开,传统的分布式存储可能逐渐退居温数据层,而KVCache、向量数据库等需要高频召回的数据将依赖新的高性能存储层。

测试结果验证了PCIe Gen6 SSD + GPU直通架构的惊人性能。美光9650 SSD单盘即可提供27GB/s带宽与540万IOPS。更重要的是,在BaM架构下,由20块盘组成的系统实现了8600万IOPS的突破性性能。若采用传统CPU模式,CPU核心将首先达到饱和,无法发挥此等性能。这一结果不仅证实了9650的性能,更验证了GPU发起存储架构的可行性与必要性。此外,该性能的实现离不开与Broadcom(交换机)、Astera Labs(Retimer)、H3 Platform(服务器)及NVIDIA(GPU)的紧密生态协作,表明PCIe Gen6的硬件生态链已趋于成熟。
数据中心通用型
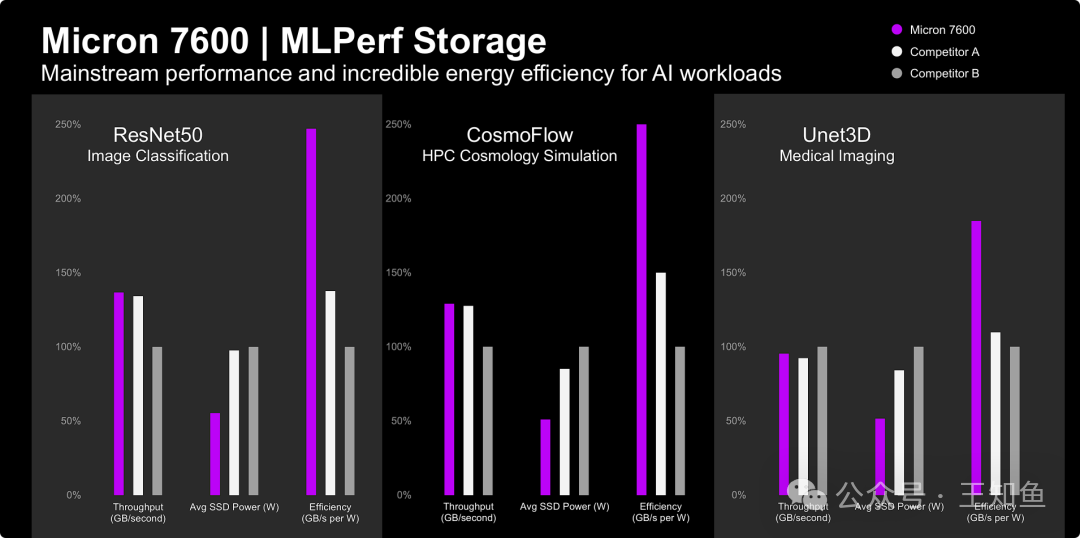
对于大规模部署的数据中心而言,除了极致速度,总拥有成本(TCO)愈发成为关键考量。美光7600系列定位为主流AI存储方案,其核心价值在于卓越的能效比。通过图像分类、科学计算和医学影像等多个领域的测试对比,7600的每瓦性能(GB/s per Watt)达到竞品的1.8倍至2.5倍。这意味着在相同的电力与散热预算下,客户可以部署更多存储资源,或显著降低运营成本。7600已获得MLPerf认证,证明了其在广泛AI应用场景中提供高能效稳定性能的能力,实现了从“唯速度论”到“TCO导向”的平衡。
数据中心容量型

美光6600系列通过采用E3.S外形规格和QLC技术,实现了单盘122TB的超大容量。这一设计的关键优势在于存储密度:在2U服务器中,其部署密度比采用传统U.2规格的竞品高出67%。最终,单一机柜可实现高达88.5 PB的存储能力。对于AI时代的海量数据湖、大模型检查点存储等场景,极高的机柜内密度能简化网络与系统拓扑并降低延迟。尽管SSD单盘成本高于HDD,但通过高达3.4倍的机柜整合率,美光试图论证在系统层级的TCO上,大容量SSD相比顶级容量HDD已具备竞争力,为推动全闪存数据中心提供了有力支撑。
延伸思考
- GPU发起存储(BaM)将如何重塑传统分布式存储在AI KVCache/向量数据库中的角色?
- 在电力成本飙升的时代,能效比是否会成为PCIe Gen6 SSD选型的首要指标,而非纯速度?
- E3.S 122TB SSD真能彻底淘汰HDD?系统级TCO计算中存在哪些隐形成本风险?
报告标题:Real-world AI workloads need fast, efficient storage[1]
Notice:Human‘s prompt, Datasets by Gemini-3-Pro
标签 #FMS25 #Gen6-eSSD
- https://files.futurememorystorage.com/proceedings/2025/20250807_AIML-302-1_Meredith-2025-08-04-19.11.56.pdf ↩
|  发表于 2025-12-15 12:10:58
|
查看: 227|
回复: 0
发表于 2025-12-15 12:10:58
|
查看: 227|
回复: 0
