在AI大模型训练、海量数据存储需求爆发的今天,数据中心的存储架构正面临前所未有的压力。硬盘HDD作为存储核心硬件,其故障不仅会引发高昂的维护成本,更可能导致数据丢失风险与业务中断。2025 OCP全球峰会上提出的“硬盘再生(Drive Regeneration)”技术,将硬盘容错能力从传统的扇区级提升至磁头/盘面级,为数据中心提供了一套兼具经济性与可持续性的故障解决方案。

一、数据中心的存储痛点:被低估的硬盘故障成本
数据中心的存储稳定性直接决定业务连续性,但硬盘故障带来的损失远比想象中严重。首先看一组硬核数据:标准企业级硬盘的MTBF(平均无故障时间)为250万小时,对应0.35%的年故障率AFR,5年保修期内的累计故障率(CFR)达1.75%。这意味着一个拥有10万pcs硬盘的数据中心,每年可能面临350pcs硬盘故障,5年内故障总量将突破1750pcs。
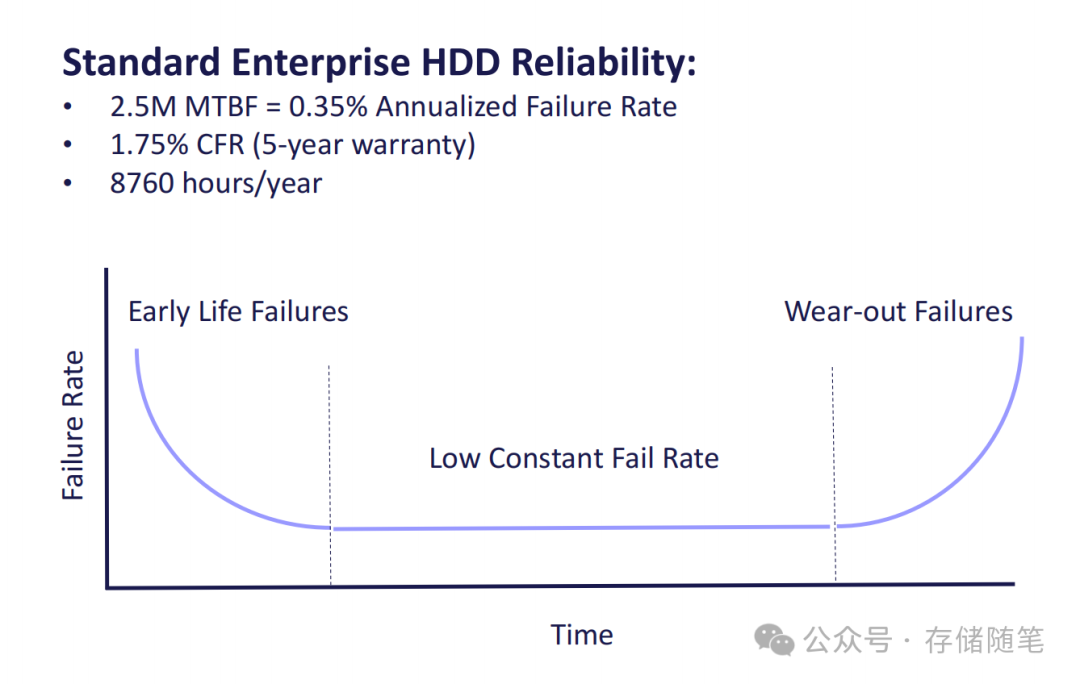
更棘手的是故障处理成本。更换或重建故障硬盘需要投入维修人员工时、硬件运输费用、数据重建的网络带宽消耗,更关键的是会造成存储节点停机——典型数据中心的存储可用性仅为95%,5%的不可用时间中,有相当比例来自硬盘故障后的空档期,部分节点甚至会闲置数周才完成硬盘更换。
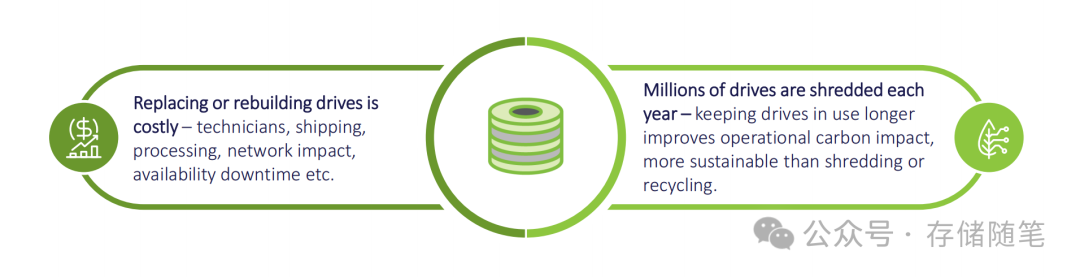
此外,可持续性压力日益凸显。全球数据中心每年会销毁数百万台硬盘,这些硬件的回收处理不仅增加环境负担,更浪费了其中仍具备可用价值的存储资源。研究表明,延长硬盘使用寿命比直接销毁或回收更具碳减排效益,这也成为硬盘再生技术的核心出发点之一。
值得注意的是,数据中心场景下的硬盘拒收率往往高于基线水平。高强度工作负载、高温运行环境会加速硬盘故障模式,系统级离线事件、性能波动等因素都可能导致硬盘被提前下线,而这些“被拒收”的硬盘中,多数并非完全报废。
二、可通过再生技术挽救40%+的故障
要理解硬盘再生技术的价值,首先需要明确数据中心硬盘故障的核心类型。数据中心硬盘拒收情况分为三类:
- GROUP 1:NTF(无故障):检测未发现明确故障。这类硬盘部分可能再次故障,后续会进入其他分类。
- GROUP 2:单磁头故障:这是最核心的突破口,占所有故障的40%以上。对于20磁头/10磁盘的硬盘,这类故障仅影响部分存储区域,95%以上的有效容量仍可保留。
- GROUP 3:退役:最少数的故障类型,通常需要彻底淘汰硬盘。
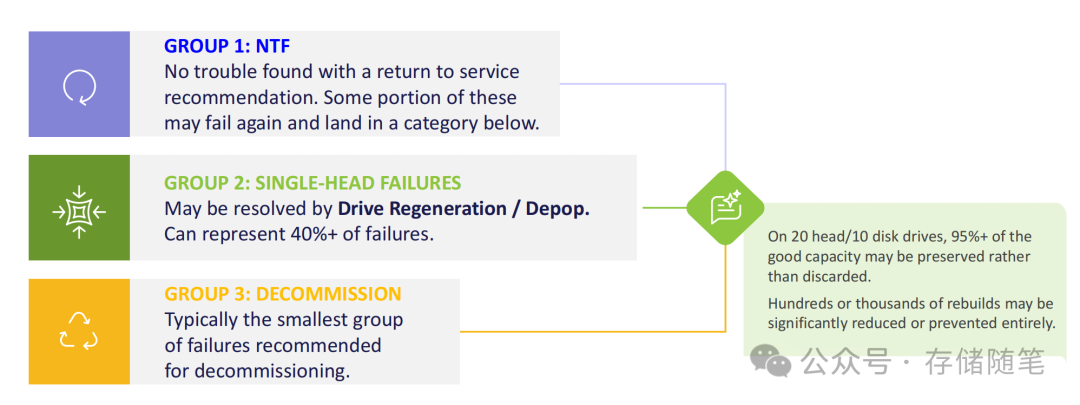
传统处理方式中,即使是单磁头故障的硬盘,也常被直接更换或销毁,造成95%可用容量的浪费。而硬盘再生技术的核心逻辑,就是针对单磁头故障这类“局部问题”,通过精准定位与隔离,实现硬盘的“二次服役”。
三、构建再生能力
硬盘再生技术并非单一功能,而是由故障检测、数据定位、存储调整三大核心模块构成的完整解决方案,每个环节都依赖硬盘硬件与软件生态的协同支持。
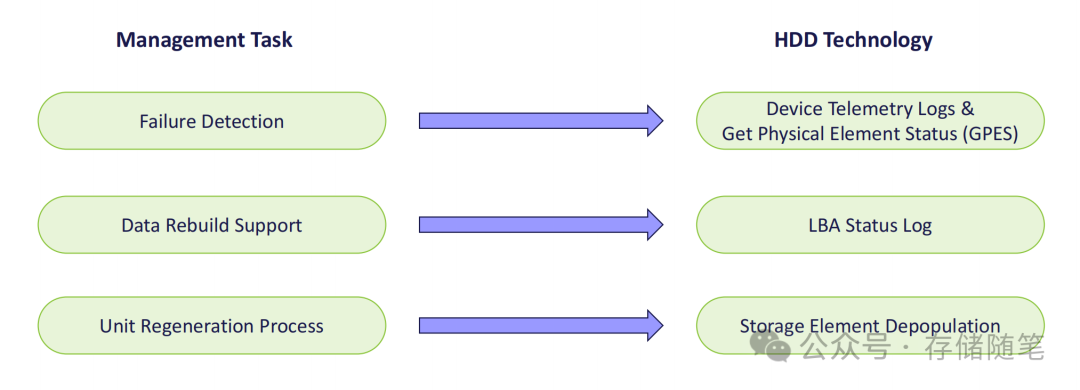
1. 故障检测:GPES+Telemetry日志数据,精准锁定磁头问题
传统硬盘故障检测多依赖扇区错误报告,难以定位磁头、盘面等物理组件的早期故障。硬盘再生技术引入了GPES(Get Physical Element Status) 机制,这一基于ACS标准的功能,能通过硬盘内置算法检测并报告哪个记录磁头出现性能退化或故障。
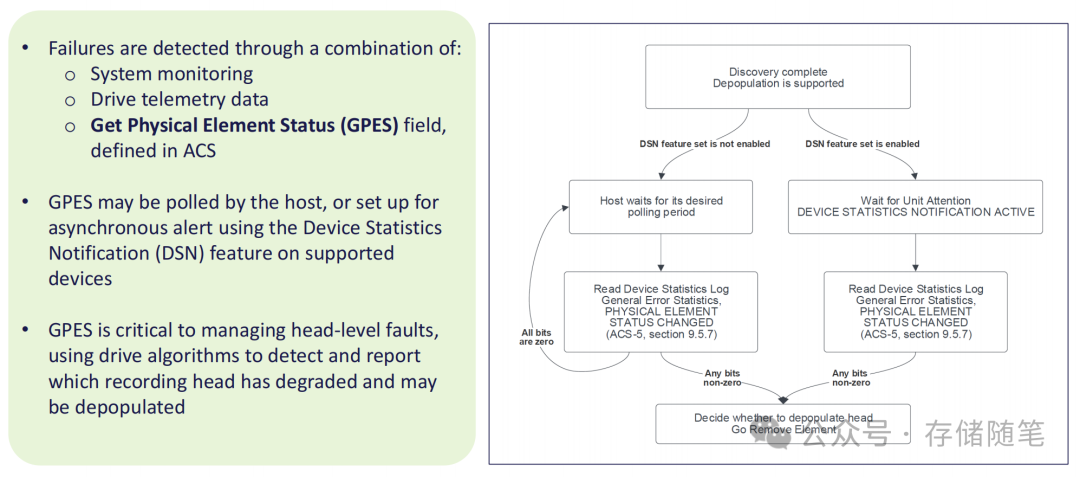
GPES的工作模式有两种:一是主机主动轮询,二是通过DSN(Device Statistics Notification,设备统计通知) 功能实现异步告警——当硬盘检测到磁头异常时,主动向主机发送通知,无需主机持续监控,大幅降低系统开销。这种精准到物理组件的检测能力,是实现“局部故障局部处理”的前提。
同时,设备Telemetry日志提供了磁头运行的全生命周期数据,包括读写错误率、温度变化、振动情况等,与GPES数据互补,能识别磁头的“潜在故障”,实现预防性再生处理,避免故障扩大导致数据丢失。
2. 数据定位:LBA状态日志,摸清有效数据分布
找到故障磁头后,需要明确哪些数据受影响、哪些仍可正常使用。LBA状态日志(Logical Block Address Status Log) 承担了这一角色,它是硬盘生成的逻辑块地址清单,包含每个LBA的 provisioning 状态与错误状态。
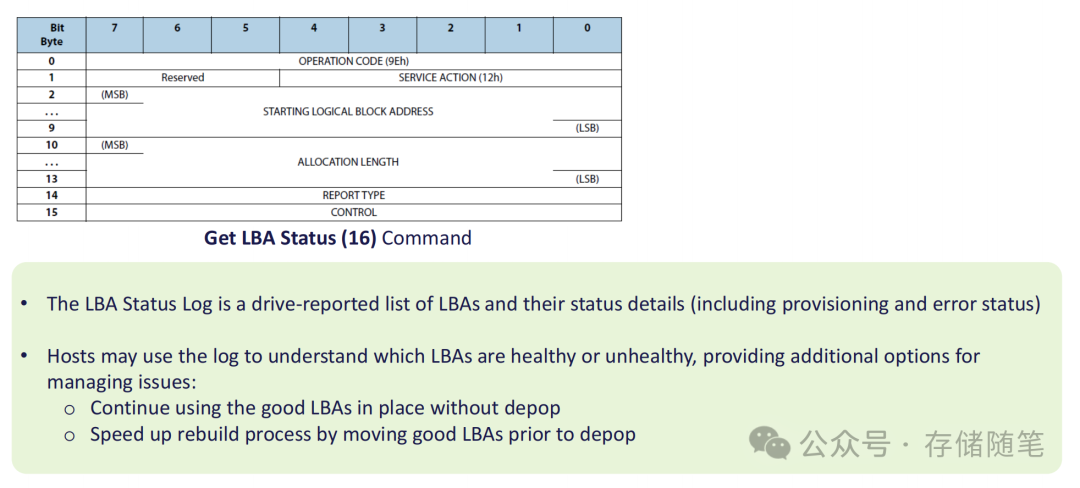
主机通过“Get LBA Status”命令读取该日志后,能清晰掌握:故障磁头对应的LBA范围、哪些LBA存储着有效数据、哪些已是空闲空间。基于这些信息,主机可以选择两种策略:要么直接使用剩余健康LBA,无需去激活操作;要么在去激活前迁移有效数据,加速后续重建过程。
目前LBA状态日志仍处于开发阶段,但它的落地将大幅提升数据迁移的精准度,减少不必要的容量损失。
3. 核心操作:存储单元离线(Depopulation)
这是实现硬盘再生的关键步骤——通过移除故障磁头对应的地址空间,让硬盘在保留健康存储区域的前提下重新上线。这对于数据中心的运维与测试流程来说,是一个减少复杂性的重要特性。
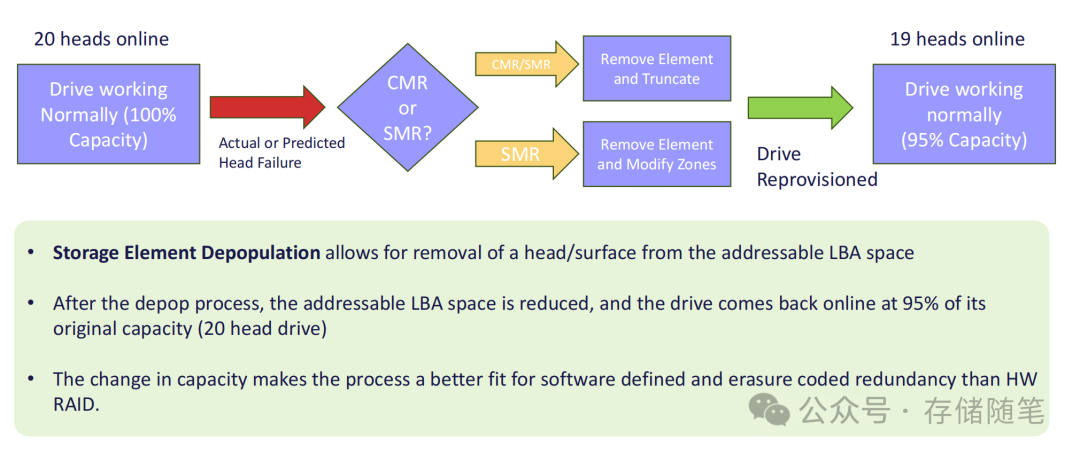
以20磁头的硬盘为例,当一个磁头故障时,将该磁头对应的LBA从可寻址空间中剔除,硬盘容量从100%降至95%,但其余19个磁头仍可正常工作。整个过程中,健康区域的存储数据不会丢失,无需对硬盘进行全盘格式化。
需要注意的是,这种容量调整更适合软件定义存储和纠删码冗余架构,而非传统硬件RAID——因为RAID对硬盘容量的一致性要求较高,而软件定义存储能更灵活地适配容量变化的硬盘。
四、进阶方案:从SMR到CMR,覆盖全场景再生
最初的硬盘再生技术仅支持SMR(Shingled Magnetic Recording,叠瓦式磁记录)硬盘,通过“移除元素+修改分区”的方式保留有效数据。为了覆盖更广泛的CMR(Conventional Magnetic Recording,传统垂直磁记录)硬盘场景,三种进阶方案,各有侧重与取舍。
方案1:CMR分区——适配RAID的折中选择
核心思路是为标准CMR硬盘启用分区结构,所有分区采用统一大小(参考SMR的256MB标准)。当磁头出现异常时,分区报告将明确标注受影响的分区,主机提前迁移这些分区的数据,再停止使用对应扇区。
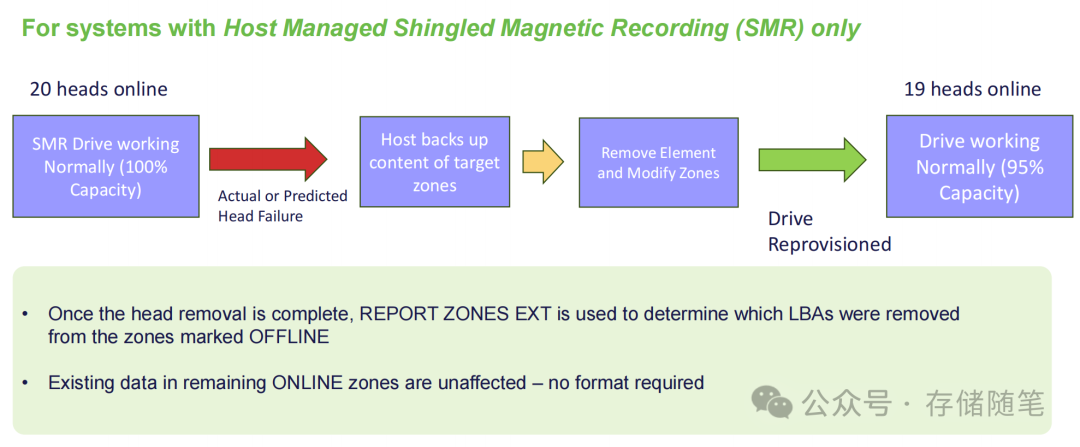

优势:能保留95%的容量,避免数据重建;分区大小若与RAID条带大小匹配,可完美适配RAID架构;更小的分区尺寸有助于硬盘负载均衡,提升性能稳定性。
挑战:分区粒度较大,部分跨磁头的分区会被“连带下线”,导致平均LBA损失约7%,高于理想的5%。
方案2:基于LBA日志的数据迁移——最小化容量损失
利用LBA状态日志的精准定位能力,当硬盘报告磁头异常时,主机通过日志找到受影响的LBA范围,仅迁移这些区域的有效数据。这种精细化的数据迁移策略,可以大幅减少重建开销。
数据迁移可使用两种命令:一是“WRITE GATHERED EXT”,无需占用数据中心网络资源,直接在硬盘内部完成数据复制;二是传统读写命令,依赖数据中心网络但兼容性更好。

优势:平均LBA损失仅为5%,几乎没有“连带损失”,容量利用率最高;主机完全掌控数据迁移过程,灵活性强。
挑战:当故障磁头对应的LBA范围较大时,日志可能生成数百万条记录,对主机的管理能力提出较高要求。
方案3:硬盘自主再生——免主机干预的终极形态
这一方案基于精简配置理念,被命名为“优化配置(Optimized Provisioning)”。核心逻辑是:硬盘检测到磁头故障后,自动将故障磁头对应的LBA访问请求重定向到健康磁头,主机仅收到“磁头异常”通知,无需执行任何数据迁移或配置调整操作。

实现这一功能需要两个前提:一是硬盘预留足够的空闲空间,二是主机通过TRIM命令告知硬盘哪些LBA是空闲的。当硬盘剩余空闲介质降至临界水平时,优化配置功能会主动上报,提醒主机释放空间。
优势:对主机完全透明,无需修改存储系统逻辑;同时适配RAID和纠删码架构;数据访问性能虽有波动,但仍处于硬盘平均访问时间范围内,不影响业务使用。
挑战:依赖主机TRIM命令支持;硬盘需要预留足够空闲空间,对存储规划提出更高要求。
五、实际价值:数据中心的三重收益
硬盘再生技术的价值不止于“拯救故障硬盘”,更在于从可用性、成本、可持续性三个维度为数据中心创造综合收益。
1. 可用性提升:填补5%的存储空档期
典型数据中心有5%的存储插槽处于不可用状态,部分原因是故障硬盘更换不及时。硬盘再生技术让故障硬盘在数小时内即可重新上线,无需等待新硬盘到货与部署,大幅缩短存储空档期。对于密封式数据中心这类难以进行现场维护的场景,这一优势尤为明显——无需拆开密封环境,即可通过远程操作实现硬盘再生,延长整个存储系统的使用寿命。
2. 成本优化:规避大规模数据重建
传统故障处理中,更换硬盘后需要进行全量数据重建,不仅占用大量网络带宽与CPU资源,还可能影响其他业务运行。硬盘再生技术保留了95%的有效数据,无需大规模重建,仅需迁移少量受影响数据(或无需迁移),显著降低系统开销。同时,减少硬盘采购与更换成本,据希捷测算,每台再生硬盘可节省包括硬件、人工、运输在内的综合成本达数百美元。
3. 可持续性:降低碳足迹
数据中心是碳排放的重要来源之一,硬盘生产与回收过程会产生大量碳足迹。硬盘再生技术延长了硬盘使用寿命,减少了新硬盘的采购需求与旧硬盘的销毁数量。按照每年数百万台硬盘的再生潜力计算,这一技术可为全球数据中心减少数万吨碳排放,符合“绿色数据中心”的发展趋势。
六、现状与展望:技术落地进度与生态支持
目前硬盘再生技术的生态支持已取得阶段性成果:
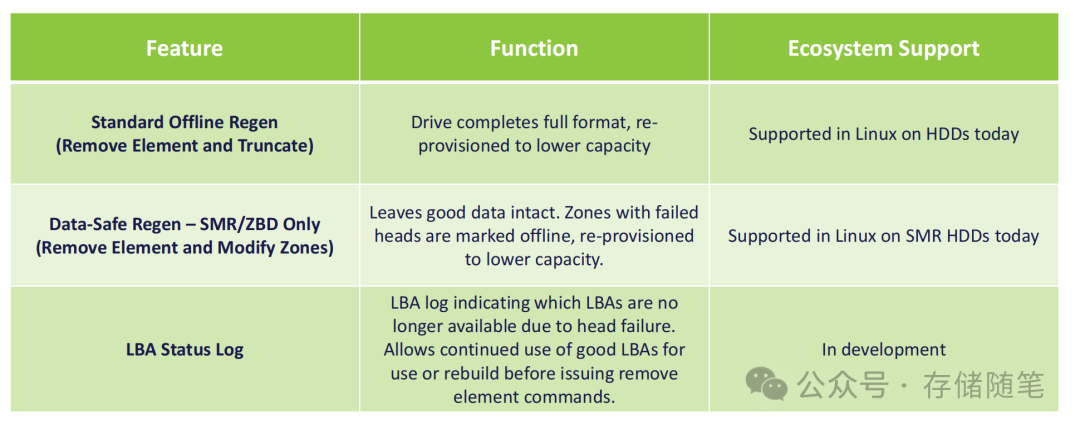
- 标准离线再生:已在Linux系统的HDD上实现支持;
- 数据安全再生:仅支持Linux系统的SMR硬盘,后续将扩展至CMR;
- LBA状态日志:处于开发阶段,未来将成为生态标配功能。
从发展趋势来看,“硬盘自主再生”(方案3)有望成为主流方向——它对存储系统的改动最小,适配性最强,能最大限度降低数据中心的部署成本。而随着LBA状态日志的成熟,方案2的管理复杂度将逐步降低,成为对容量利用率要求极高场景的优选。
结语:存储容错的“精细化”革命
过去十年,数据中心存储容错技术的发展集中在软件层面(如纠删码、多副本),而硬盘再生技术将优化视角回归硬件本身,通过“精准定位故障、保留有效资源”的精细化思路,实现了硬件容错能力的升级。
在AI时代,数据中心的存储规模将持续爆发,硬盘故障带来的成本与风险也将同步增长。硬盘再生技术不仅解决了当下的实际痛点,更构建了“硬件+软件”协同的容错新范式——它证明了:面对故障,不必“全盘抛弃”,精准干预同样能实现高效可靠的存储运行。
随着技术生态的完善与落地范围的扩大,我们有理由相信,未来数据中心的硬盘将不再是“一故障即报废”的消耗品,而是具备自我修复能力的“可持续资产”,为海量数据存储提供更稳定、经济、环保的底层支撑。对这类前沿存储技术感兴趣的开发者,欢迎到云栈社区的数据库与存储板块参与更深入的讨论。
参考文献:2025OCP-《Seagate Technology Drive Regeneration in Action: Enhancing Fault Tolerance in Datacenters》
 发表于 2026-1-31 08:30:46
|
查看: 153|
回复: 0
发表于 2026-1-31 08:30:46
|
查看: 153|
回复: 0
