当地时间3月11日,Meta公司宣布,在成功商用前两代自研AI芯片MTIA(Meta Training and Inference Accelerators)系列后,目前正在开发四款全新的AI芯片。这些芯片旨在提升其生成式AI功能及内容排名系统的性能。
据介绍,这四款AI芯片分别为MTIA 300、MTIA 400、MTIA 450和MTIA 500,由Meta与博通公司合作开发,基于开源的RISC-V架构(采用Meta去年收购的Rivos公司的内核设计),并由台积电(TSMC)生产。目前,MTIA 300已经开始生产,而其他三款芯片预计将在2027年初至年底之间出货。
MTIA 100/200已部署数十万颗,两年再推4款芯片
此前,Meta已在业务中部署了数十万个MTIA 100和MTIA 200芯片,并用于许多内部生产模型及Llama等大型语言模型的测试。
如今,Meta正以更快的节奏连续开发四代新的MTIA系列芯片,计划在2026年或2027年部署。这些新芯片的工作负载覆盖范围将从排名和推荐推理,扩展到排名和推荐训练、通用生成式AI工作负载以及针对性优化的生成式AI推理。
Meta表示,人工智能模型的发展速度远快于传统的芯片开发周期。为了应对这一挑战,Meta采取了快速迭代的策略:每一代MTIA芯片都建立在上一代之上,采用模块化小芯片设计,结合最新的AI工作负载洞察和硬件技术,并以更短的节奏进行部署。这种紧密的循环使硬件能更好地与快速演进的模型保持一致。
具体来说,最新的四代MTIA系列芯片包括:
MTIA 300:经济高效的基础
MTIA 300主要针对排名和推荐模型进行了优化,为后续面向生成式AI模型优化的芯片奠定了坚实基础。
与前几代相比,MTIA 300 的显著特点还包括内置网卡芯片、用于卸载通信任务的专用消息引擎以及用于归约任务的近内存计算。这些低延迟、高带宽的通信组件为后续芯片高效的生成式AI推理和训练铺平了道路。
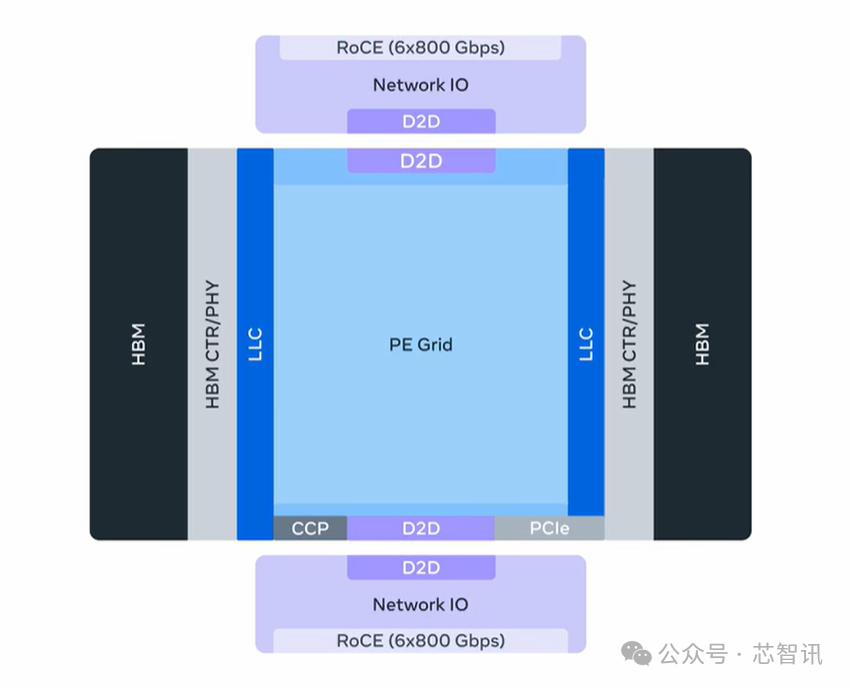
具体来说,MTIA 300 由一个计算芯片、两个网络芯片和多个HBM内存堆栈组成。每个计算芯片包含一个处理单元网格,每个处理单元包含:两个 RISC-V 向量核心、用于矩阵乘法的点积引擎、用于激活和元素级操作的特殊功能单元、用于累积和 PE 间通信的缩减引擎、以及用于本地暂存内存数据存取的DMA引擎。
在配置参数方面,MTIA 300配备了216GB HBM;带宽为6.1 TB/s;FP8/MX8 性能1.2 PFlops;BF16 性能 0.6 PFlops;加速器纵向扩展域规模为16个节点;纵向扩展网络 1 TB/s(单向带宽);横向扩展网络200 GB/s(单向带宽);TDP为800W。
目前这款芯片正在生产中,用于排名和推荐培训。
MTIA 400:极具竞争力的原始性能
MTIA 400主要是为了应对生成式AI需求的激增,以更好地支持生成式AI模型,同时保持支持排名和推荐工作负载的能力。相较于 MTIA 300,其 FP8 FLOPS 性能提升了 400%,HBM 带宽提升了 51%。MTIA 400具有72个加速器扩展域,可提供与领先商业产品竞争的高性能。
如果说MTIA 300是一款经济高效的产品,那么MTIA 400则是首款旨在不仅降低成本,而且提供媲美领先商用产品原始性能的MTIA芯片。
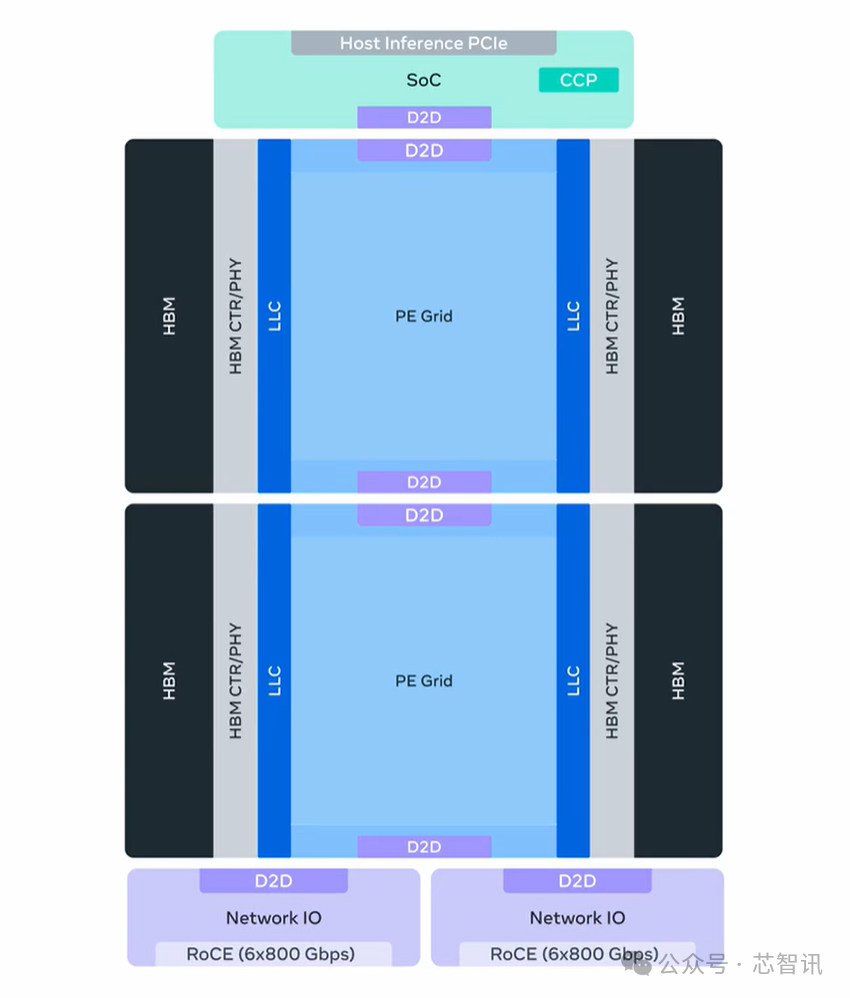
MTIA 400集成了两个计算芯片组,使计算密度翻倍,并且支持增强版的 MX8 和 MX4低精度格式。一个机架可以包含 72 个 MTIA 400,通过交换式背板连接,即可构成一个单一的扩展域。

具体参数方面,MTIA 400配备了288GB HBM;带宽为 9.2TB/s;MX4性能 12 PFlops;FP8/MX8 性能 6 PFlops;BF16 性能 3 PFlops;加速器纵向扩展域规模为72个节点;纵向扩展网络1.2 TB/s(单向带宽);横向扩展网络100 GB/s(单向带宽);TDP为1200W。
Meta已经在实验室完成了MTIA 400的测试,并正计划将其部署到Meta数据中心。
MTIA 450:生成式AI推理的飞跃
考虑到生成式AI推理需求的快速增长,Meta通过在四个方面改进,将MTIA 400升级到MTIA 450,使其更适合生成式AI推理:
- 将 HBM 带宽比上一版本提高一倍,以加快解码速度。
- 将 MX4 FLOPS 提高 75%,以加快混合专家模型前馈网络的计算速度。
- 引入硬件加速,使注意力机制和 FFN 计算更加高效。
- 支持低精度数据类型的创新。
MTIA 450 超越了 FP8/MX8,其 MX4 FLOPS 是 FP16/BF16 的 6 倍,体现了低精度 FLOPS 对推理的重要性。它还支持混合低精度计算,无需承担数据类型转换带来的软件开销。
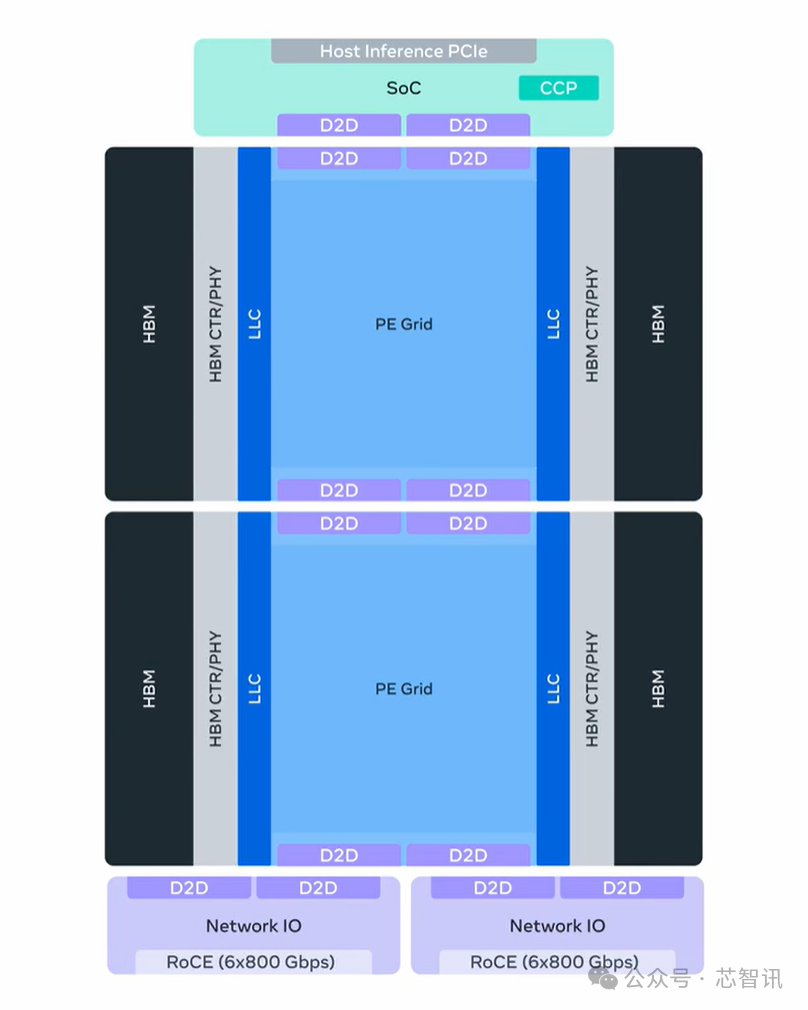
具体参数方面,MTIA 450配备了288GB HBM;带宽为18.4 TB/s;MX4性能21 PFlops;FP8/MX8 性能 7 PFlops;BF16 性能 3.5 PFlops;加速器纵向扩展域规模依然是72个节点;纵向扩展网络1.2 TB/s(单向带宽);横向扩展网络100 GB/s(单向带宽);TDP为1400W。
MTIA 450计划于2027年初大规模部署。
MTIA 500:以更少的资源实现更多生成式AI推理
随着生成式AI推理需求的持续增长,Meta进一步将 MTIA 450 升级为 MTIA 500,以更具成本效益的方式支持生成式AI推理。
MTIA 500 的 HBM 带宽提升了 50%,HBM 容量提升了高达 80%,MX4 FLOPS 提升了 43%。MTIA 500 进一步强化了模块化理念,采用 2x2 的小型计算芯片组配置。与 MTIA 450 一样,MTIA 500 也引入了额外的硬件加速和数据类型创新,以解决生成式AI推理中的瓶颈问题。
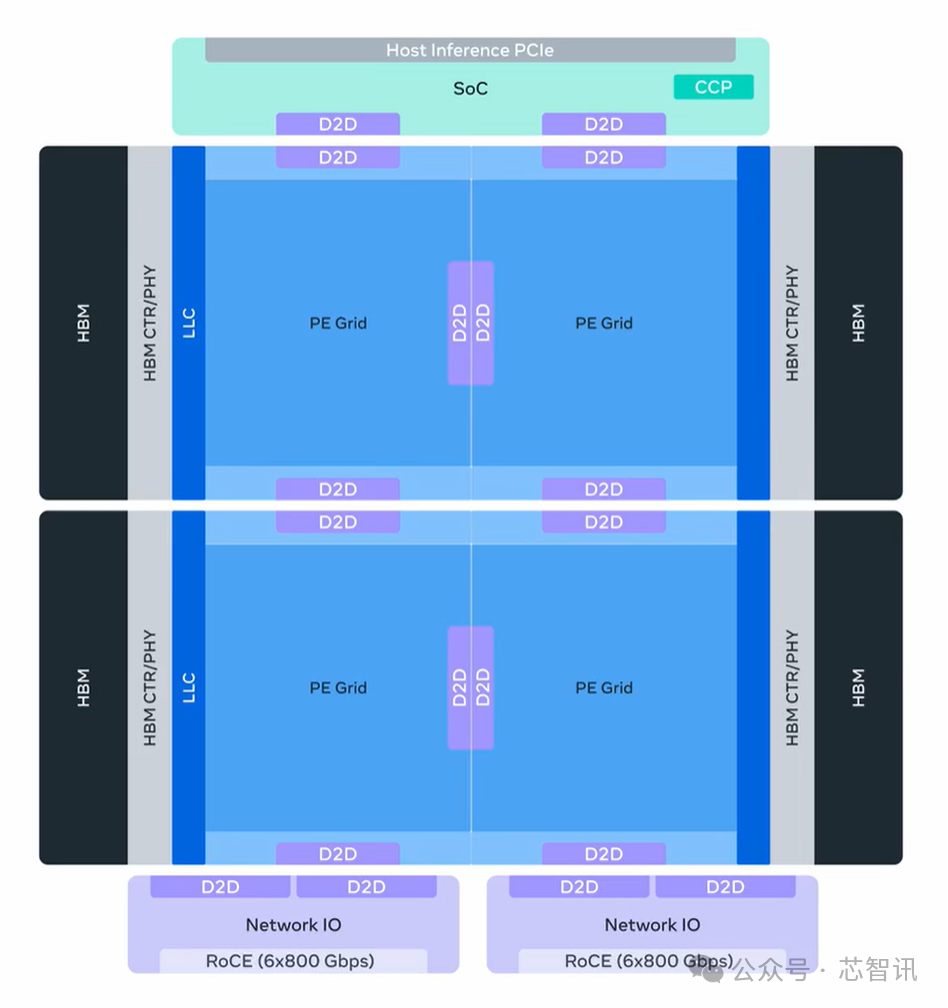
具体参数方面,MTIA 500配备了384-512 GB HBM,带宽为 27.6 TB/s;MX4性能 30 PFlops;FP8/MX8 性能 10 PFlops;BF16 性能 5 PFlops;加速器纵向扩展域规模为72个节点;纵向扩展网络1.2 TB/s(单向带宽);横向扩展网络100 GB/s(单向带宽);TDP为1700W。
MTIA 500计划于2027年大规模部署。
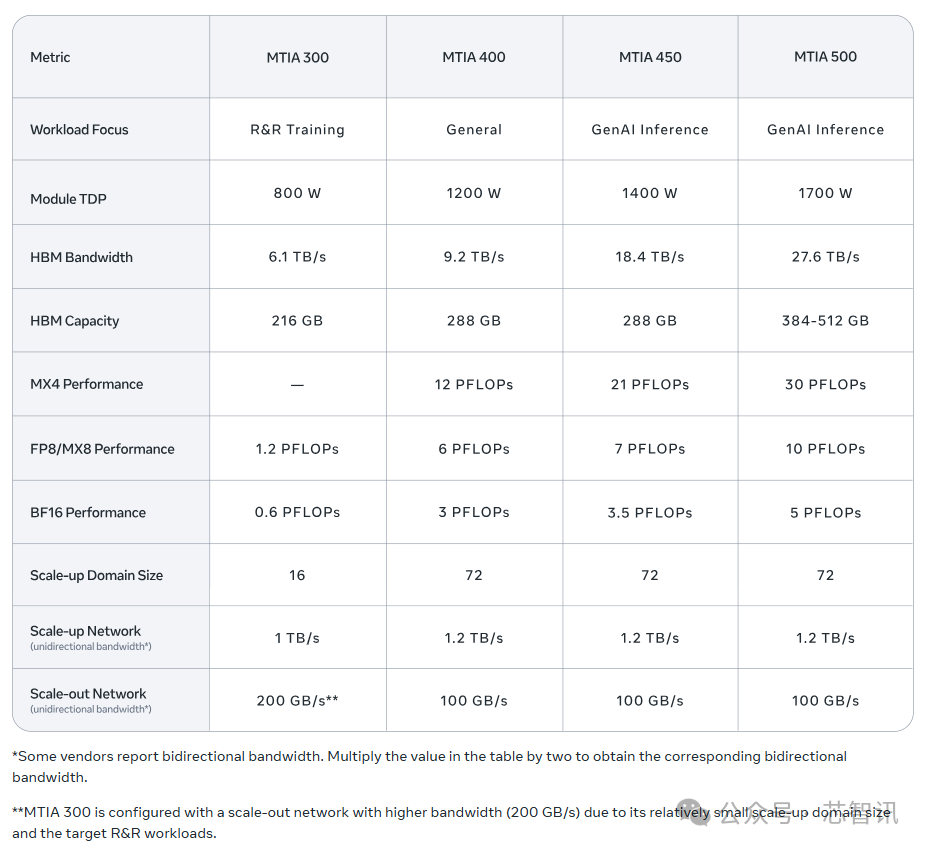
总结来看,从MTIA 300到MTIA 500,HBM带宽增加了4.5倍,计算性能增加了25倍,这一切都将在不到两年的时间内发生,凸显了Meta加速迭代战略的优势。
Meta的MTIA战略基于三大支柱:高速迭代芯片开发、以推理为先导、以及通过基于行业标准实现无缝采用。
高速迭代
鉴于人工智能创新日新月异,Meta已具备大约每6个月推出一款新芯片的能力。这种快速的研发速度带来了两个优势:
- 快速适应不断发展的 AI 技术:可以针对新的模型架构、低精度数据类型优化最新芯片,并为重要操作引入硬件加速。
- 快速采用最新硬件技术:例如最新的工艺节点、HBM 和封装技术。
Meta是如何做到如此快速迭代的呢?答案在于贯穿所有层面的可重用模块化设计:从芯片组、机箱、机架到网络基础设施。Meta将加速器设计为芯片组系统——独立的、可重用的计算、I/O 和网络构建模块。由于每个芯片组都可以单独升级,因此可以在数月内而非数年内完成改进。此外,不同的芯片组可以在不同的工艺节点上制造,从而在满足性能功耗要求的同时控制成本。
在系统层面,MTIA 400、450 和 500 均采用相同的机箱、机架和网络基础设施。因此,每一代新芯片都可以安装在相同的物理空间内,从而加快从设计到部署的过渡。
推理优先
主流GPU通常为最苛刻的大规模生成式AI预训练而设计,然后才被用于生成式AI推理等成本效益较低的工作负载。Meta采用了不同的方法:MTIA 450和500首先针对生成式AI推理进行优化,然后可根据需要用于支持其他工作负载。这使得MTIA能够很好地适应预期中生成式AI推理需求的增长。
无摩擦采用
MTIA 从一开始就基于行业标准的软硬件生态系统——PyTorch、vLLM、Triton 和开放计算项目——原生构建。由于PyTorch 起源于 Meta 且已成为应用最广泛的机器学习框架,MTIA 自然而然地采用了 PyTorch 原生架构。PyTorch、vLLM 和 Triton 共同为开发者提供了熟悉的软件栈。除了行业标准的软件之外,MTIA 的系统和机架解决方案也符合开放计算项目标准,从而能够无缝部署到数据中心。
MTIA 软件栈:一种基于 PyTorch 的原生方法
MTIA 软件栈在所有芯片代际中都能提供一致的编程体验,采用 PyTorch 原生架构。
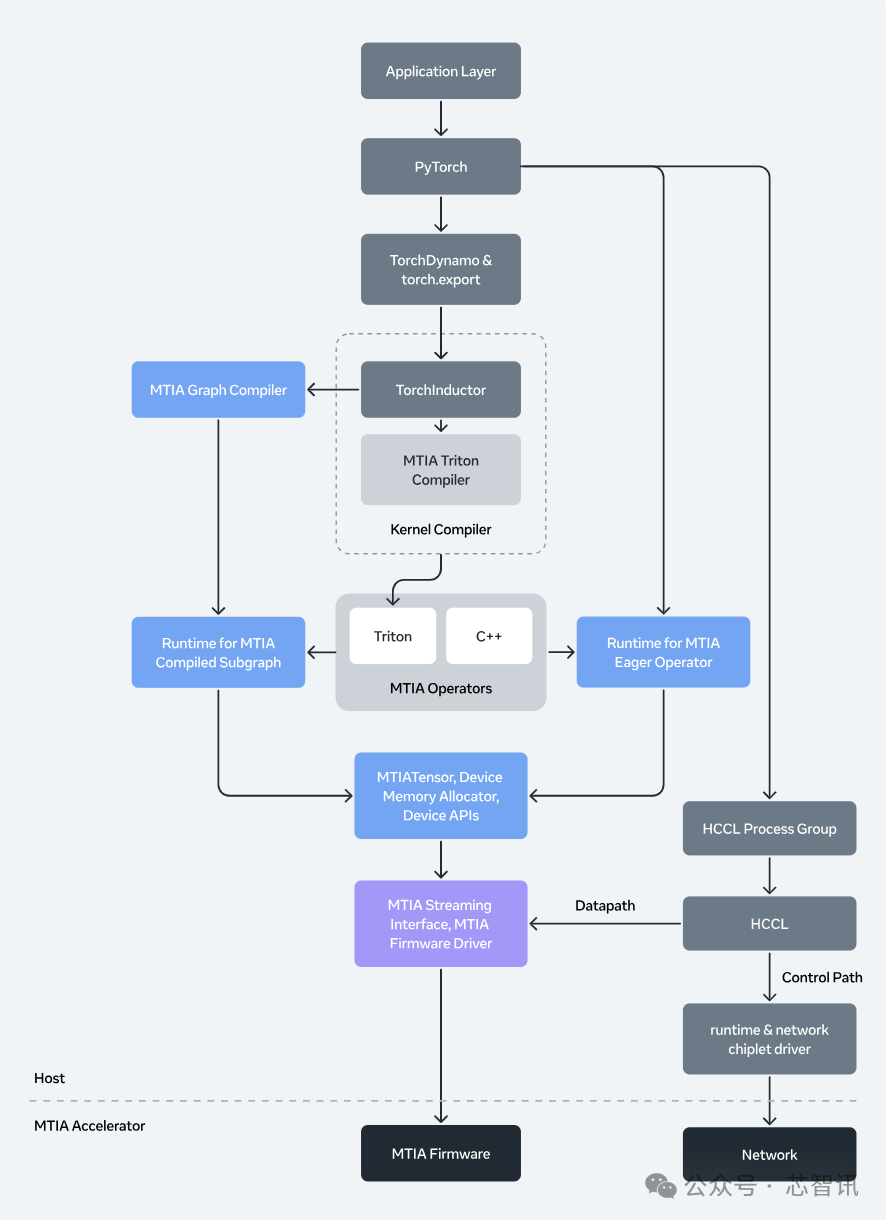
该软件栈的关键属性包括:
- 无缝模型部署: MTIA 同时支持即时模式和图形模式。在图形模式下,它直接与PyTorch 2.0 的编译流程集成。开发者可以使用熟悉的工具来捕获和优化模型图,无需对 MTIA 进行任何特定的重写即可启用模型。
- 编译器: 在 PyTorch 前端之下,MTIA 专用编译器将高级图表示转换为高度优化的设备代码。图编译器基于 Torch FX IR 和 TorchInductor 构建。内核编译器和底层后端基于 Triton、MLIR 和 LLVM,并针对 MTIA 进行了增强和优化。
- 内核编写: MTIA 支持编译器驱动的内核生成和融合,支持使用 Triton 和 C++ 进行自动生成和用户手动内核编写,并提供内核自动调优和优化功能。
- 通信与传输: MTIA 的通信库利用芯片内置的网络芯片实现高效通信,将集体操作卸载到专用消息引擎,并使用近内存计算来加速需要大量归约的集体操作。
- 运行时和固件: MTIA 运行时管理设备内存、内核调度以及跨多个设备的执行协调。运行时与基于 Rust 的用户空间驱动程序交互。固件采用裸机 Rust 编写,具有低延迟和高性能。
- vLLM 支持: vLLM 的插件架构使其能够轻松与 MTIA 集成。MTIA 插件使用 MTIA 专用内核替换了 FlashAttention 和融合 LayerNorm 等重要运算符。
- 生产工具: MTIA 提供生产级监控、性能分析和调试工具,支持跨主机和设备的全栈式、大规模可观测性。
总结
虽然Meta大规模部署的前两代 MTIA 芯片已展现出强大的排名与推荐推理能力,但最新的四代产品将进一步拓展生成式AI推理的边界,实现排名与推荐训练,并为未来的生成式AI训练奠定基础。
Meta表示,每一代 MTIA 芯片都汲取了前代产品的经验,与其软件栈协同设计。其模块化、多芯片设计和垂直整合的协同设计方法,能够在保持系统级兼容性的同时,实现快速且持续的性能提升。
内容来源:芯智讯
对AI芯片硬件生态与软件栈协同设计感兴趣的开发者,可以关注云栈社区的智能与数据板块,获取更多深度技术解析与行业动态。
 发表于 2026-3-14 08:43:37
|
查看: 208|
回复: 0
发表于 2026-3-14 08:43:37
|
查看: 208|
回复: 0
