当 GPT-4 的 1.8 万亿参数让存储带宽需求呈指数级飙升,当 Meta 的万卡 A100 集群因 PCIe 瓶颈导致训练效率骤降 58%,AI 存储系统正站在从 “PCIe 主导” 到 “异构互连” 的历史性转折点。
ODCC最新发布的《AI 存储系统需求研究》,通过梳理 AI 全生命周期 8 大阶段的存储特征,量化分析 PCIe 带宽,并提出多技术路线协同方案,为后 PCIe 时代的 AI 基础设施建设提供了权威技术指南。
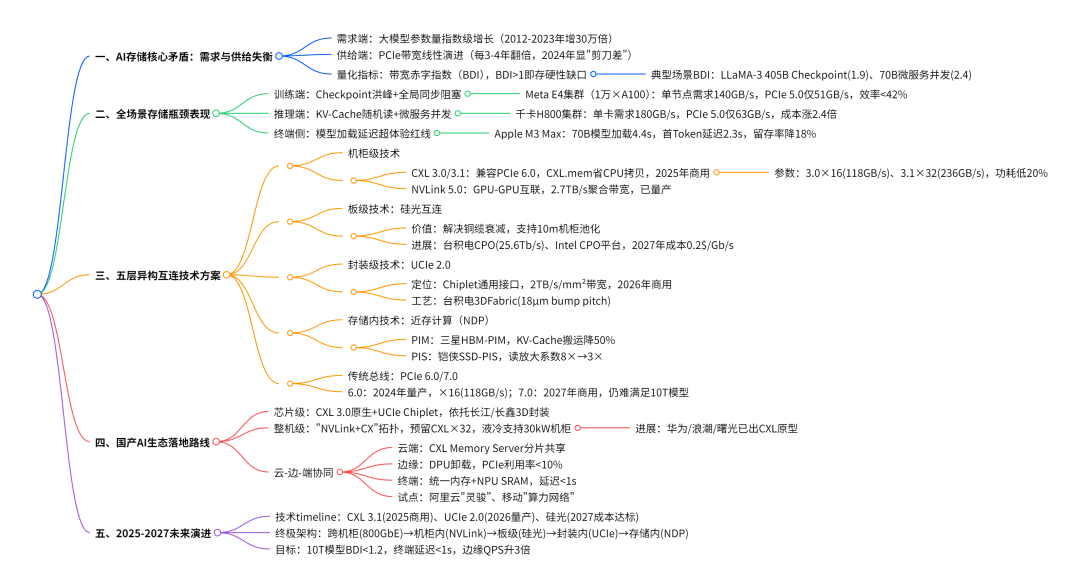
一、AI 存储瓶颈全面爆发:从训练集群到终端设备的 “带宽危机”
AI 存储的困境本质是 “指数级需求” 与 “线性级供给” 的矛盾。报告显示,2012-2023 年大模型参数量增长 30 万倍,而 PCIe 带宽仅提升 8 倍,这种失衡在 2024 年形成显性 “剪刀差”,且渗透到 AI 全流程的每个环节。
在训练端,Checkpoint 写入成为压垮 PCIe 的 “最后一根稻草”。Meta E4 集群训练 1.76 万亿参数的 GPT-MoE 模型时,每两小时需完成 7.4PB 的 Checkpoint 落盘,单节点瞬时带宽需求达 140GB/s,而 PCIe 5.0×16 的实际净荷带宽仅 51GB/s,链路利用率飙升至 364%,触发重传风暴后,All-Reduce 通信延迟从 15μs 暴增至 2.1ms,训练效率直接跌破 42%。这种 “同步等待” 困境在千卡级GPU集群中会呈线性放大,成为大模型训练的核心效率瓶颈。
推理场景则面临 “随机读放大” 的隐性消耗。某头部云厂商的千卡 H800 集群运行 700 亿参数 INT4 量化模型时,生成单个 Token 需随机读取 9GB KV-Cache,单卡带宽需求 180GB/s,而 PCIe 5.0×16 仅能提供 63GB/s,缺口近 3 倍。为弥补带宽不足,厂商被迫在内存中保留完整 KV-Cache,导致显存占用暴增,实例密度下降 60%,每 1000 Tokens 成本上涨 2.4 倍,直接侵蚀商业化收益。
终端设备的体验痛点同样尖锐。Apple M3 Max、高通 X Elite 等旗舰 SoC 仅支持 PCIe 4.0×4,理论带宽 8GB/s,加载 700 亿参数 INT4 模型需 4.4 秒,远超 “首屏 1 秒” 的用户体验红线。实测显示,即便采用 4-bit 量化与权重分页,首 Token 延迟仍达 2.3 秒,用户留存率下降 18%,成为端侧 AI 普及的关键障碍。
为量化这一困境,报告提出 “带宽赤字指数(BDI)”—— 当 BDI>1 时即出现不可通过缓存或压缩掩盖的硬性缺口。数据显示,LLaMA-3 405B 模型 Checkpoint 阶段 BDI 达 1.9,700 亿参数微服务并发场景 BDI 高达 2.4,而 PCIe 7.0 即便商用,面对 2027 年 10 万亿参数 MoE 模型,BDI 仍将突破 3.8,证明单一 PCIe 路线已无力支撑 AI大模型的持续发展。
二、技术破局:五层异构互连体系的协同进化
面对 PCIe 的系统性瓶颈,报告指出 AI 存储的未来在于 “机柜、封装、晶圆” 三层空间尺度的异构协同,通过五条技术路线的互补,构建全场景带宽解决方案。
CXL 3.0/3.1:当前最成熟的 “过渡桥梁”
作为 PCIe 的直接演进者,CXL 3.0 在物理层与 PCIe 6.0 兼容,却通过 CXL.mem 协议省去 CPU 拷贝环节,使 GPU-to - 内存池带宽提升 1.8 倍。Intel Xeon Max 平台搭配 CXL 3.0×16 构建的 2TB DDR5 扩展池,实测 GPU-to-pool 带宽达 110GB/s,延迟 190ns,可将 LLaMA-3 405B 模型的 BDI 压至 0.51,首次实现 “无赤字” 训练。更关键的是,CXL 3.1 支持 ×32 通道,提供 236GB/s 带宽,且功耗比 PCIe 6.0 低 20%,成本仅增加 0.4%,2025 年规模商用后将成为训练集群的主力总线。
NVLink 5.0:GPU 集群的 “高速内网”
NVIDIA Blackwell 平台搭载的 NVLink 5.0,通过 18 条 150GB/s 链路实现 72 GPU 全互联,构建 2.7TB/s 的机柜级胖树拓扑,专为训练阶段的张量同步优化。其优势在于延迟仅 20ns,且沿用 QSFP-DD 外壳,无需重构机柜布线,目前已进入现货阶段,成为超大规模训练集群的 “刚需配置”。报告测算,采用 NVLink 5.0 的 GPU 集群,梯度同步延迟可降低 60%,Checkpoint 间隔缩短 30%,直接提升训练效率。
UCIe 2.0:封装级的 “乐高接口”
如果说 CXL 解决机柜级问题,UCIe 2.0 则聚焦封装内部的异构集成。其 2TB/s/mm² 的带宽密度、2pJ/bit 的超低功耗,可实现 CPU、GPU、内存 Die 的自由拼接,台积电 3DFabric 工艺已支持 18μm bump pitch,为 Chiplet 架构提供标准化接口。Intel 测试片显示,UCIe 2.0 可将封装内延迟控制在 20ns 以内,虽需 2026 年才能商用,但已被视为 “后 CXL 时代” 的核心技术,将彻底改变芯片设计范式。
硅光互连:机柜内的 “无损耗通道”
当铜缆在 2m 以上距离面临信号衰减难题时,硅光互连凭借低损耗、高带宽密度的优势,成为机柜内扩展的关键补充。台积电 Co-Packaged Optics(CPO)测试片实现 32 通道 25.6Tb/s 板级带宽,Intel 第二代 CPO 平台将光引擎与 GPU 同基板集成,使 2m 链路无需 retimer,功耗降低 40%。LightCounting 预测,2027 年硅光引擎成本将降至 0.2$/Gb/s,与高端铜缆持平,届时将在 10m 机柜级内存池化场景中大规模替代铜缆。
近存计算(NDP):从 “搬运数据” 到 “驻留计算”
NDP 通过将计算单元嵌入存储介质,从根源减少数据移动。三星 Aquabolt-X HBM-PIM 在训练阶段将 KV-Cache 数据搬运次数减少 50%,铠侠 CD6-C SSD 集成 128×128 INT8 MAC 阵列,将推理场景的 PCIe 读放大系数从 8× 降至 3×。报告强调,NDP 的核心价值并非提升峰值带宽,而是构建 “PCIe/CXL-NDP” 互补缓冲带,在缓存行粒度完成局部计算,使系统在不升级总线的情况下缓解带宽压力。
三、国产 AI 生态的破局路径:从芯片到系统的三层协同
针对国产 AI 产业链的发展需求,报告提出 “芯片、整机、云边端” 协同的技术路线图,在兼顾可行性的同时规避 “卡脖子” 风险。
芯片层面,建议优先采用 “CXL 3.0/3.1 原生支持 + UCIe 2.0 Chiplet” 架构。国产 GPU、NPU 无需等待 PCIe 7.0 成熟,可基于现有 EDA 工具链开发 CXL 控制器,降低流片风险;同时通过长江存储、长鑫存储的 18μm 3D 封装能力,实现内存、加速器 Die 的异构集成,当前工艺已满足 UCIe 2.0 的物理层要求,可快速形成产品竞争力。
整机设计需重构机柜拓扑,构建 “NVLink 5.0 GPU 互联 + CXL 内存池化” 的三层架构。华为、浪潮、曙光已推出支持 CXL 3.0 的整机原型,建议在主板预留 CXL ×32 插槽,通过 retimer 实现 2m 铜缆或 10m 有源光缆的内存扩展,搭配液冷后门热交换器,满足 30kW 机柜的功耗需求,当前方案已具备量产条件。
云边端协同层面,需建立 “全局权重分片 + 区域热缓存” 机制。云端利用 CXL Memory Server 实现跨节点一致性共享,边缘通过 DPU 卸载将 PCIe 利用率压至 10% 以下,终端则依托统一内存架构与 NPU SRAM 屏蔽 PCIe 瓶颈。阿里云 “灵骏”、中国移动 “算力网络” 的试点数据显示,该模式可使端侧模型加载延迟缩短至 1 秒内,边缘推理 QPS 提升 40%,且无需新增硬件成本。
四、未来展望:2027 年实现带宽赤字最优解
报告预测,到 2027 年,AI 存储将形成 “800GbE/1.6TbE(跨机柜)-NVLink 5.0(机柜内)-UCIe 2.0(封装内)- 硅光(板级)-NDP(存储内)” 的五层异构体系,PCIe 则退居低速外设总线,仅用于键鼠、网卡等非核心设备。
技术成熟度方面,CXL 3.1 将于 2025 年规模商用,UCIe 2.0 在 2026 年进入量产,硅光与 NDP 则在 2027 年实现成本与性能的平衡。届时,10 万亿参数 MoE 模型的训练 BDI 将降至 1.2 以下,终端 700 亿参数模型加载延迟控制在 1 秒内,边缘推理并发 QPS 提升 3 倍,为通用人工智能(AGI)的发展奠定存储基础。
对于产业参与者,报告建议芯片厂商聚焦 CXL 控制器与 UCIe IP 的研发,整机厂商加速 CXL 内存池化原型落地,云服务商则需提前布局硅光与 NDP 的应用场景。政策层面应推动 CXL/PCIe 国产化标准制定,建立跨厂商 Chiplet 互操作联盟,避免生态碎片化。
这场存储革命的核心,已从 “追求更高带宽” 转向 “更优协同”。正如 ODCC 报告所强调,AI 存储的未来不在于某一项技术的单点突破,而在于多路线的分层协作 —— 通过 CXL 的过渡、UCIe 的重构、硅光的延伸与 NDP 的优化,共同构建一个能够支撑万亿级参数模型持续演进的基础设施体系,这既是技术必然,也是产业共识。

本文技术分析与核心观点援引自ODCC《AI存储系统需求研究》报告,并参考了业内关于超节点、数据中心网络架构等相关技术资料。
 发表于 2025-12-8 04:14:30
|
查看: 236|
回复: 0
发表于 2025-12-8 04:14:30
|
查看: 236|
回复: 0
