OpenClaw是什么?
OpenClaw是一个功能强大的自托管(self-hosted)AI Agent框架,它允许你在自己的服务器或本地硬件上部署并运行。与简单的聊天机器人不同,它以类Agent的方式自动执行复杂任务。
它的核心特点包括:
- 多模型支持:能集成多种主流大模型,如Claude、GPT、Gemini等。
- 多渠道交互:可通过WhatsApp、Telegram、iMessage等消息平台与你交互。
- 高可靠性:具备自动重启、自我修复能力。
- 可扩展性:通过插件扩展(Skill)机制不断增强能力。
简单来说,OpenClaw就像一个部署在你本地环境中的自动化、可执行任务版的智能助手操作系统。
OpenClaw的架构设计
总体来看,OpenClaw是一个“常驻 Gateway + 多会话 Agent + Skills/Tools + 多端接入”的系统。
你可以把它理解为你机器上的Agent OS,外部通过适配好的IM软件作为“聊天入口”来操控。其核心是Gateway(常驻服务),负责将 消息 → 会话 → 模型推理 → 工具执行 → 回复 这一整条链路串联起来。
整体架构视图
┌──────────────────────────────────────────────────────────┐
│ User / External World │
│ (Telegram / Discord / CLI / HTTP / Webhook) │
└───────────────────────────▲──────────────────────────────┘
│
│ inbound messages / events
│
┌───────────────────────────┴──────────────────────────────┐
│ Gateway │
│ ────────────────────────────────────────────────────── │
│ • Channel adapters (tg / dc / http / cli …) │
│ • bindings (peer / accountId → agentId) │
│ • agent registry (agents.list) │
│ • auth profiles / secrets │
│ • sandbox & tool policy enforcement │
└───────────────────────────▲──────────────────────────────┘
│ route to agent
│
┌───────────────────────────┴──────────────────────────────┐
│ Agent Runtime │
│ (per agent, isolated workspace + persona) │
│ │
│ ┌────────────────────────────────────────────────────┐ │
│ │ Workspace (agent local universe) │ │
│ │ │ │
│ │ IDENTITY.md → 我是谁(角色 / 边界) │ │
│ │ SOUL.md → 行为哲学 / 推理风格 │ │
│ │ AGENTS.md → ⭐ 多 agent 编排规则 │ │
│ │ TOOLS.md → 工具使用协议 │ │
│ │ BOOTSTRAP.md → 启动注入上下文 │ │
│ │ USER.md → 用户画像 │ │
│ │ HEARTBEAT.md → 周期性守护 / 自检 │ │
│ │ │ │
│ │ memory/ → 长期 / 短期记忆 │ │
│ │ skills/ → 能力描述(函数 / MCP 客户端) │ │
│ └────────────────────────────────────────────────────┘ │
│ │
│ ──────────────── Tool Invocation Layer ─────────────── │
│ • exec / apply_patch / web / fs │
│ • sessions_spawn (sub-agents) │
│ • MCP calls │
└───────────────────────────▲──────────────────────────────┘
│
│ spawn / call
│
┌───────────────────────────┴──────────────────────────────┐
│ Sub-Agent Sessions │
│ (research / coder / reviewer / ops …) │
│ │
│ • 独立 agentId / workspace / tools │
│ • 独立 sandbox 权限 │
│ • 异步执行 → result announce 回主 agent │
└───────────────────────────▲──────────────────────────────┘
│
│ tool reminding / execution
│
┌───────────────────────────┴──────────────────────────────┐
│ Tool & MCP Ecosystem │
│ │
│ • Built-in tools (exec, patch, web, fs) │
│ • MCP Servers (ADB / Frida / Git / Scanner / CI) │
│ • External services (cloud, repos, infra) │
└──────────────────────────────────────────────────────────┘
Workspace目录结构:Agent的“人格”与运行态
一个Workspace可以理解为一个对应的“数字人”。这个“人”有ID、有大脑(思考逻辑)、有记忆、有行为规则、有工具箱,并且定义了可以与其他哪些数字人进行交互。
默认路径在 ~/.openclaw/workspace,其典型结构如下:
AGENTS.md BOOTSTRAP.md HEARTBEAT.md IDENTITY.md memory skills SOUL.md TOOLS.md USER.md
这些文件构成了OpenClaw Agent Runtime的角色分工接口。你可以把Workspace看作一个「Agent的可执行人格与运行态目录」,每个文件对应不同的“通道”:
- IDENTITY.md —— “我是谁”,定义Agent的身份、定位和边界。
- SOUL.md —— “我怎么思考 & 行事”,定义Agent的性格、思维方式和价值排序。
- AGENTS.md —— 多Agent编排的核心,定义如何调用或派发其他Agent。
- TOOLS.md —— 工具使用协议,描述何时使用何工具、何时禁用、使用前后的注意事项。
- skills/ —— 能力实现层(具体的函数/MCP/插件)。
- BOOTSTRAP.md —— 启动注入,一次性执行的上下文。
- USER.md —— 用户画像/偏好,描述用户是谁以及如何协作。
- memory/ —— 长期 & 短期记忆存储。
- HEARTBEAT.md —— 周期性自检/守护逻辑。
这种基于文件系统的设计,使得Agent的“人格”、记忆和能力都变得可版本化、可备份、可移植,极大地提升了人工智能Agent系统的可运维性。对这类前沿技术框架的实践和讨论,也欢迎你来云栈社区交流分享。
部署OpenClaw
部署非常简单,使用官方的一键安装脚本即可:
curl -fsSL https://openclaw.bot/install.sh | bash
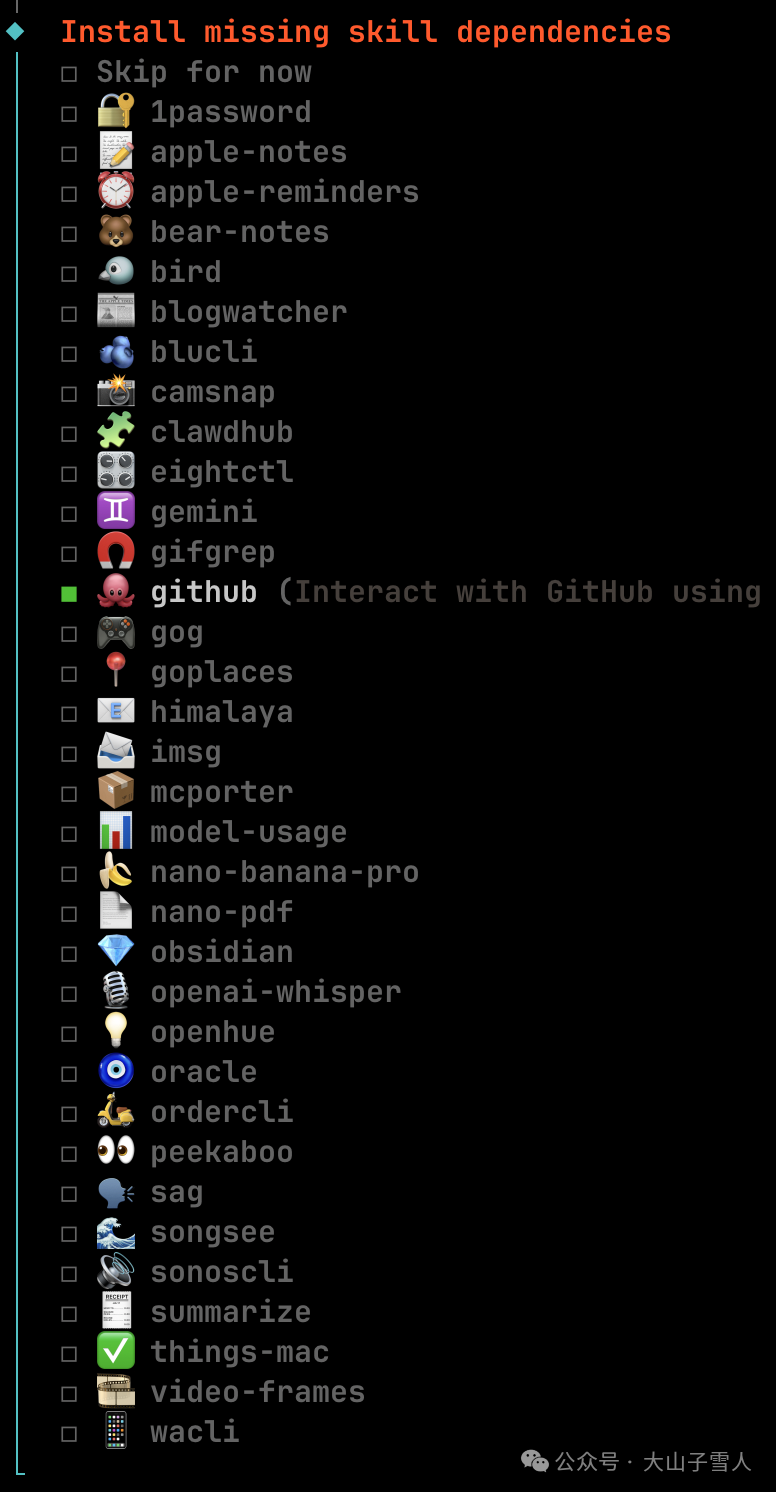
安装完成后,首次运行通常会引导你安装缺失的技能依赖,界面类似下图:
特殊配置:解决网络代理问题
许多大模型需要特殊的网络环境才能访问。需要注意的是,Node.js运行环境中的 fetch(通常是Node 18+内置的 undici fetch)默认不会读取 HTTP_PROXY/HTTPS_PROXY 环境变量。因此,即使你设置了这些变量,请求也不会走代理。
解决方法是对OpenClaw进行一个小改动,强制其使用代理:
- 安装
undici 包:
npm install undici
-
创建一个代理启动脚本,例如放在 ~/.config/openclaw/proxy-bootstrap.mjs:
import { setGlobalDispatcher, ProxyAgent } from "undici";
const proxy = process.env.OC_PROXY || process.env.HTTP_PROXY || process.env.HTTTPS_PROXY;
if (!proxy) {
console.error("[proxy-bootstrap] no proxy set");
} else {
setGlobalDispatcher(new ProxyAgent(proxy));
console.error("[proxy-bootstrap] undici proxy =", proxy);
}
- 设置环境变量,让OpenClaw启动时加载这个脚本:
export OC_PROXY="http://127.0.0.1:8080"
export NODE_OPTIONS="--import ~/.config/openclaw/proxy-bootstrap.mjs"
这样,所有通过 undici 发出的请求都会经过你指定的代理。
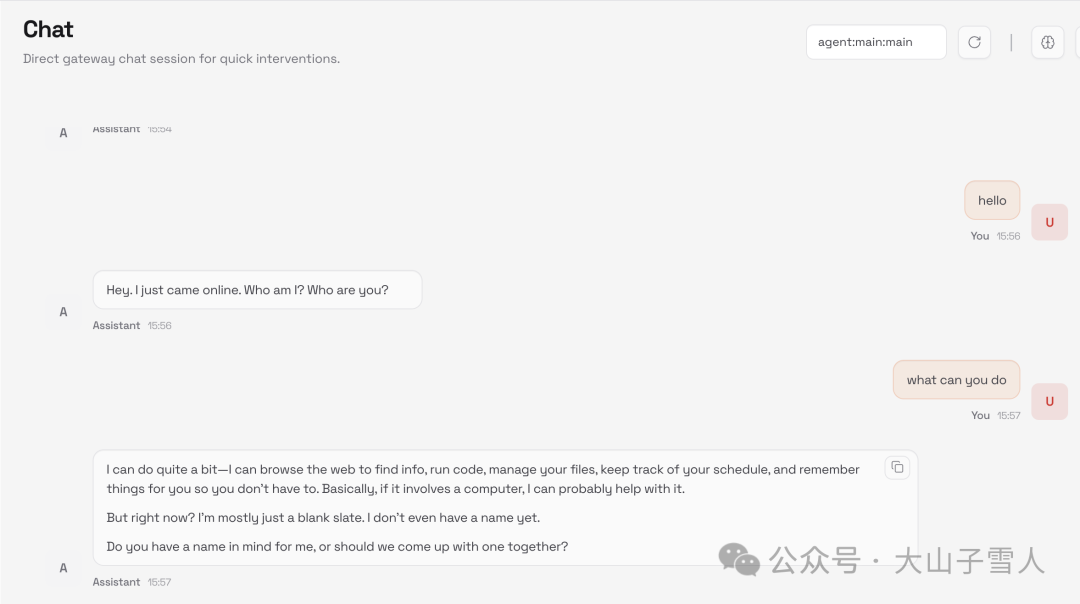
完成部署和配置后,你可以在浏览器中打开 http://127.0.0.1:18789/ 访问本地管理界面,并与刚上线的AI助手进行交互:
添加自定义Skills(技能)
OpenClaw的Skill本质上是一个可被LLM调用的工具目录。其核心构成是:描述文件(SKILL.md) + 可执行入口(脚本/程序) + 可选权限声明。
Skill的默认目录在 ~/.openclaw/workspace/skills/,每个Skill一个子目录。例如,一个简单的HTTP请求Skill结构可能如下:
~/.openclaw/workspace/skills/
└── my-http-fetch/
├── SKILL.md
├── fetch.sh
└── fetch.py
一个更复杂的、用于Android开发的Skill目录结构示例:
➜ workspace git:(master) ✗ tree
.
├── AGENTS.md
├── BOOTSTRAP.md
├── HEARTBEAT.md
├── IDENTITY.md
├── memory
│ └── 2026-01-31-0712.md
├── skills
│ └── claude-android-skill
│ ├── assets
│ │ └── templates
│ │ ├── libs.versions.toml.template
│ │ └── settings.gradle.kts.template
│ ├── LICENSE
│ ├── README.md
│ ├── references
│ │ ├── architecture.md
│ │ ├── compose-patterns.md
│ │ ├── gradle-setup.md
│ │ ├── modularization.md
│ │ └── testing.md
│ ├── scripts
│ │ └── generate_feature.py
│ └── SKILL.md
添加Skill后,执行 openclaw skills list 命令,可以看到配置的Skill已生效,并能清晰了解其功能描述和触发条件:

通过查看Skill代码,你会发现Skill的核心是对能力的详细描述:能做什么、不能做什么、需要什么权限、在什么场景下使用。编写一个完善的Skill确实需要考虑很多细节,不过你可以利用LLM来辅助你完成这项工作,这也是开源实战中常见的高效方式。
总结一下Skill与Tool的关系:
- Skill 是能力接口与使用语义的声明层。
- Tool / MCP Server 是能力的执行实现层。
- Agent(LLM) 负责在运行时把
目标 → Skill → Tool/MCP 串联起来。
有了Skill这一层抽象,就能以最少的Token消耗实现与各种Tools、MCP服务的高效互调。
Agent之间如何互相调用?
在OpenClaw中,“多个Agent互相调用”的主流实现方式不是让Agent直接导入或引用彼此,而是通过一组名为 sessions_* 的工具进行跨会话消息编排。其模式是:一个Agent把任务发给另一个Agent的会话,对方处理完毕后,再将结果通过消息传回。
核心工具:sessions_*(Agent-to-Agent通信骨架)
OpenClaw内置了一组专门为“Agent-to-Agent”协作设计的小工具:
- sessions_list:列出当前有哪些活跃会话(包含Agent、通道、元数据)。
- sessions_history:获取某个特定会话的对话历史(用于“读取结果”)。
- sessions_send:向另一个会话发送消息(用于“派发任务”)。
- sessions_spawn:创建/拉起一个新会话(用于“启动一个子Agent/子会话”)。
这套工具的设计目标是“少而精,不易误用”,使Agent能够发现其他会话、发送消息、获取结果。
典型协作模式:Coordinator(主控)→ Worker(执行者)
-
主控发现可用Worker:
主控Agent调用 sessions_list,找到目标Worker的 sessionId。
-
主控派发任务:
使用 sessions_send 将任务描述发送给Worker。例如:“去总结一下今天的日志”、“去执行一次adb设备检查”、“去做一次关于XXX的网页调研(如果该Agent有浏览权限)”。
-
收集结果:
- 被动接收:让Worker在处理完成后,直接发送一条消息回传给主控Agent。
- 主动拉取:主控Agent使用
sessions_history 主动拉取Worker会话最近的输出,然后从中提取关键要点。
实用技巧:定义回执协议
为了更可靠地解析结果,建议将“回执协议”写入System Prompt或协作规范中。例如:
- Coordinator发给Worker的消息都以
TASK: 开头,并附带 REPLY_TO_SESSION=<id> 指明回复目标。
- Worker的输出必须包含:
RESULT: (任务结果摘要)ARTIFACTS: (产生的文件路径或链接)NEXT: (是否需要主控进一步追问或指示)
这样,Coordinator在用 sessions_history 抓取结果时,就能清晰、稳定地解析出所需信息,避免被会话中的闲聊或过程性思考所干扰。
如何编排多个Agent?
在OpenClaw中,编排多个Agent通常分为两层来实现:入口路由(决定由哪个Agent接收消息)和任务分解(一个主Agent如何拉起多个子Agent协同工作)。
入口层:用 agents.list + bindings 实现消息路由
你可以在同一个Gateway中配置多个完全隔离的Agent(它们拥有各自独立的Workspace、agentDir、会话存储和认证配置),然后通过 bindings 规则将不同平台、账号或群聊的入站消息映射到不同的Agent。
- agents.list:用于定义多个Agent(指定其workspace路径、使用的模型、工具/沙箱策略等)。
- bindings:用于将入站通道的“来源”(如账号ID、群ID、对端用户ID)绑定到特定的Agent。
执行层:用 sessions_spawn 拆分复杂任务
当同一个入口Agent需要处理并行或需要分工的复杂任务时,就需要用到Subagents(子Agent)机制。
- 主Agent首先使用
agents_list 工具查看当前会话允许生成哪些子Agent(这受到其配置中 subagents.allowAgents 列表的限制)。
- 然后使用
sessions_spawn 工具启动一个子会话,让特定的子Agent去执行一个明确的任务。子Agent完成任务后,会将结果返回给主Agent。
多Agent编排配置示例
下面是一个典型的多Agent协作网关配置示例,默认应放置在 ~/.openclaw/gateway/config.json。这个配置定义了一个主协调器(Orchestrator)和三个不同职责的工作Agent(Research, Coder, Reviewer),并通过bindings进行消息路由。
{
"agents": {
"defaults": {
"workspace": "~/.openclaw/workspace-main",
// 默认模型(可在每个agent的list条目中覆盖)
"model": "openai/gpt-4o",
// 沙箱默认配置
"sandbox": {
"mode": "non-main",
"workspaceAccess": "rw",
"scope": "session"
},
// 子会话默认配置(可选)
"subagents": {
"archiveAfterMinutes": 60
}
},
// ====== 多Agent定义与路由配置 ======
"list": [
{
"id": "main",
"default": true,
"name": "Orchestrator",
"workspace": "~/.openclaw/workspace-main",
"agentDir": "~/.openclaw/agents/main/agent",
// 关键:允许主Agent生成以下ID的子Agent
"subagents": {
"allowAgents": ["research", "coder", "reviewer"]
},
// 协调器通常只需要 sessions_spawn 和最少的运行时工具
"tools": {
"profile": "default",
"allow": ["sessions_spawn", "agents_list"],
"deny": []
},
"sandbox": {
"mode": "non-main",
"workspaceAccess": "rw",
"scope": "session"
}
},
{
"id": "research",
"name": "Research Worker",
"workspace": "~/.openclaw/workspace-research",
"agentDir": "~/.openclaw/agents/research/agent",
// 研究Agent:可以浏览网页,但无Shell或文件写入权限
"sandbox": {
"mode": "all",
"workspaceAccess": "ro",
"scope": "session"
},
"tools": {
"profile": "default",
"allow": ["web_search", "web_fetch"],
"deny": ["exec", "apply_patch"]
}
},
{
"id": "coder",
"name": "Coding Worker",
"workspace": "~/.openclaw/workspace-coder",
"agentDir": "~/.openclaw/agents/coder/agent",
// 编码Agent:需要读写Workspace和应用补丁的工具,但仍受沙箱限制
"sandbox": {
"mode": "all",
"workspaceAccess": "rw",
"scope": "session"
},
"tools": {
"profile": "default",
"allow": ["apply_patch", "exec"],
"deny": []
}
},
{
"id": "reviewer",
"name": "Review Worker",
"workspace": "~/.openclaw/workspace-reviewer",
"agentDir": "~/.openclaw/agents/reviewer/agent",
// 评审Agent:只读Workspace,无Shell,专注于阅读和推理
"sandbox": {
"mode": "all",
"workspaceAccess": "ro",
"scope": "session"
},
"tools": {
"profile": "default",
"allow": [],
"deny": ["exec", "apply_patch"]
}
}
]
},
// ====== Bindings: 将入站消息路由到指定Agent ======
"bindings": [
// 示例:将特定用户的对端ID消息路由给主协调器
{"match": {"peer": "your-peer-id-here"}, "agent": "main"},
// 回退规则:将所有其他来源的消息路由给主协调器
{"match": {"accountId": "*"}, "agent": "main"}
]
}
通过这样清晰的配置,你就能构建出一个职责分明、安全可控的多Node.js智能体协同系统,真正实现将AI Agent当作“操作系统进程”一样进行管理和编排。
 发表于 2026-2-27 06:13:15
|
查看: 523|
回复: 0
发表于 2026-2-27 06:13:15
|
查看: 523|
回复: 0
