引言: 编译器的魔法世界
想象一下,你是一位小说家,用英语写下精彩的故事,但你的读者遍布全球,需要不同语言版本。你需要翻译官、校对员和排版工协作完成这项工作。C语言编译器正是这样一个多步骤的“翻译工厂”,将人类可读的高级语言代码转化为机器能直接执行的二进制指令。
本文将以系统化、深入的方式,全面剖析C语言编译处理的每个环节。我们将穿越预处理、编译、汇编、链接四大阶段,揭示每个阶段的核心机制、数据结构和实现原理。
第一章: 编译流程全景图
1.1 四阶段编译模型
C语言的编译过程是一个经典的“四阶段流水线”模型:
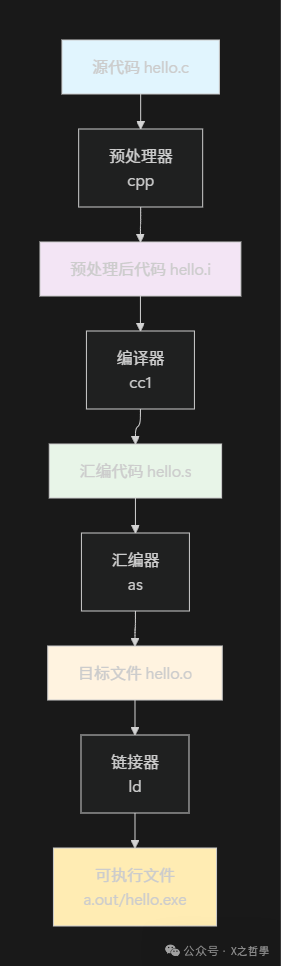 表1: 编译四阶段功能对比
表1: 编译四阶段功能对比
| 阶段 |
工具/组件 |
输入 |
输出 |
主要功能 |
生活比喻 |
| 预处理 |
预处理器 (cpp) |
.c源文件 |
.i扩展源文件 |
头文件包含、宏展开、条件编译 |
文稿的初步整理:插入参考书页、替换缩写词 |
| 编译 |
编译器 (cc1) |
.i扩展文件 |
.s汇编文件 |
词法分析、语法分析、语义分析、优化 |
从英文翻译为法文:理解句子结构、检查语法、优化表达 |
| 汇编 |
汇编器 (as) |
.s汇编文件 |
.o目标文件 |
汇编指令转机器码、生成重定位信息 |
将法文手稿转为印刷排版:字符到铅字模具 |
| 链接 |
链接器 (ld) |
.o目标文件+库文件 |
可执行文件 |
符号解析、地址重定位、合并节区 |
图书装订:合并各章节、解决交叉引用、生成目录 |
第二章: 预处理器: 源代码的“美容师”
2.1 预处理的核心任务
预处理器是编译流水线的第一站,它处理的是源代码中的预处理指令(以#开头的指令)。这些指令不是C语言的组成部分,而是给预处理器的命令。
// hello.c - 示例源代码
#include <stdio.h> // 头文件包含
#define PI 3.14159 // 宏定义
#define MAX(a,b) ((a)>(b)?(a):(b)) // 函数式宏
int main() {
#ifdef DEBUG // 条件编译
printf("Debug mode\n");
#endif
double radius = 5.0;
double area = PI * radius * radius; // 宏展开
int max_val = MAX(10, 20); // 宏展开
return 0;
}
2.2 预处理器的实现机制
预处理器的核心是一个文本替换引擎,它维护多种数据结构来处理不同的指令:
// 预处理器核心数据结构示例
typedef struct MacroDef {
char *name; // 宏名称
char **params; // 参数列表(函数式宏)
char *replacement; // 替换文本
int is_function_like; // 是否为函数式宏
struct MacroDef *next; // 链表下一个
} MacroDef;
typedef struct IncludePath {
char *path; // 头文件搜索路径
struct IncludePath *next; // 链表下一个
} IncludePath;
// 条件编译的栈结构
typedef struct ConditionalState {
int condition_met; // 当前条件是否满足
int skipping; // 是否跳过代码块
struct ConditionalState *parent; // 外层条件状态
} ConditionalState;
2.3 预处理过程详解
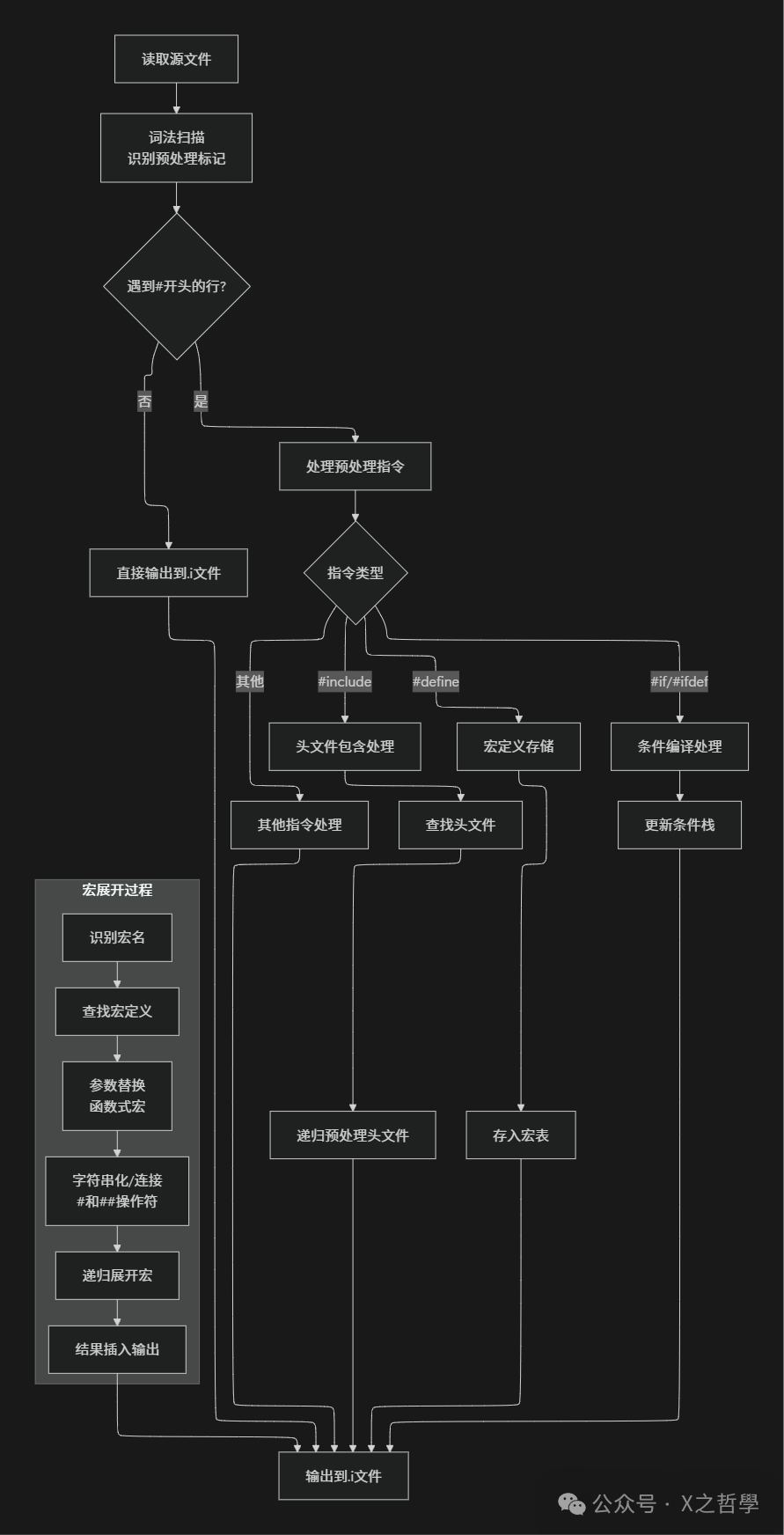 表2: 主要预处理指令及功能
表2: 主要预处理指令及功能
| 指令 |
功能 |
示例 |
处理结果 |
#include |
头文件包含 |
#include <stdio.h> |
将stdio.h的内容插入当前位置 |
#define |
宏定义 |
#define SIZE 100 |
程序中所有SIZE替换为100 |
#undef |
取消宏定义 |
#undef SIZE |
删除SIZE的宏定义 |
#if |
条件编译 |
#if DEBUG |
根据DEBUG值决定是否编译代码块 |
#ifdef |
如果已定义 |
#ifdef LINUX |
如果定义了LINUX则编译 |
#ifndef |
如果未定义 |
#ifndef WINDOWS |
如果没定义WINDOWS则编译 |
#else |
否则分支 |
#else |
条件不满足时的替代代码 |
#elif |
否则如果 |
#elif defined(MAC) |
前一个条件不满足时的测试 |
#endif |
结束条件块 |
#endif |
标记条件编译块结束 |
#pragma |
编译器指示 |
#pragma once |
编译器特定的功能控制 |
#error |
生成错误 |
#error "Not supported" |
强制产生编译错误 |
#line |
行号控制 |
#line 100 "newfile.c" |
修改行号和文件名信息 |
2.4 预处理器实例演示
让我们通过一个具体例子跟踪预处理过程:
# 使用GCC只进行预处理
gcc -E hello.c -o hello.i
预处理前的代码:
// hello.c
#include <stdio.h>
#define SQUARE(x) ((x)*(x))
#define DEBUG 1
int main() {
#if DEBUG
int x = 5;
printf("Square of %d is %d\n", x, SQUARE(x));
#endif
return 0;
}
预处理后的代码(hello.i):
# 1 "hello.c"
# 1 "<built-in>"
# 1 "<命令行>"
# 31 "<命令行>"
# 1 "/usr/include/stdio.h" 1 3 4
... (stdio.h的数百行内容) ...
# 4 "hello.c"
int main() {
int x = 5;
printf("Square of %d is %d\n", x, ((x)*(x)));
return 0;
}
可以看到:
#include <stdio.h>被替换为stdio.h的实际内容DEBUG宏被展开为1,所以#if DEBUG块被保留SQUARE(x)宏被展开为((x)*(x))- 添加了行号标记信息(
# linenum "filename"格式)
第三章: 编译器: 从源码到汇编的深度翻译
3.1 编译器前端: 理解源代码
编译器前端负责将预处理后的C代码转换为中间表示(IR)。这个过程分为三个主要阶段:
3.1.1 词法分析(Lexical Analysis)
词法分析器(Scanner/Lexer)将字符流转换为记号流(Token Stream)。就像英文阅读时,我们先识别出单词、标点,而不是一个个字母。
// 词法记号的数据结构
typedef enum TokenType {
TOKEN_IDENTIFIER, // 标识符
TOKEN_NUMBER, // 数字常量
TOKEN_STRING, // 字符串常量
TOKEN_CHAR, // 字符常量
TOKEN_KEYWORD, // 关键字
TOKEN_OPERATOR, // 运算符
TOKEN_PUNCTUATOR, // 标点符号
TOKEN_EOF // 文件结束
} TokenType;
typedef struct Token {
TokenType type; // 记号类型
char *lexeme; // 原始字符串
int value; // 数值(如果是数字)
int line; // 行号
int column; // 列号
struct Token *next; // 下一个记号
} Token;
// 示例: int result = x + 42;
// 词法分析结果:
// TOKEN_KEYWORD "int"
// TOKEN_IDENTIFIER "result"
// TOKEN_OPERATOR "="
// TOKEN_IDENTIFIER "x"
// TOKEN_OPERATOR "+"
// TOKEN_NUMBER "42"
// TOKEN_PUNCTUATOR ";"
3.1.2 语法分析(Syntax Analysis)
语法分析器(Parser)根据C语言的上下文无关文法,将记号流组织成抽象语法树(AST)。这就像分析句子的主谓宾结构。
// 抽象语法树节点类型
typedef enum ASTNodeType {
NODE_PROGRAM, // 程序
NODE_FUNCTION, // 函数
NODE_DECLARATION, // 声明
NODE_ASSIGNMENT, // 赋值
NODE_BINARY_OP, // 二元运算
NODE_UNARY_OP, // 一元运算
NODE_CONSTANT, // 常量
NODE_VARIABLE, // 变量
NODE_IF, // if语句
NODE_WHILE, // while语句
NODE_RETURN, // return语句
NODE_CALL // 函数调用
} ASTNodeType;
// AST节点基础结构
typedef struct ASTNode {
ASTNodeType type; // 节点类型
int data_type; // 数据类型
char *name; // 名称(标识符)
int value; // 值(常量)
struct ASTNode *left; // 左子节点
struct ASTNode *right; // 右子节点
struct ASTNode *child; // 子节点(用于代码块)
struct ASTNode *next; // 下一个节点(语句列表)
} ASTNode;
// 示例: y = x * 2 + 3 的AST表示
// =
// / \
// y +
// / \
// * 3
// / \
// x 2
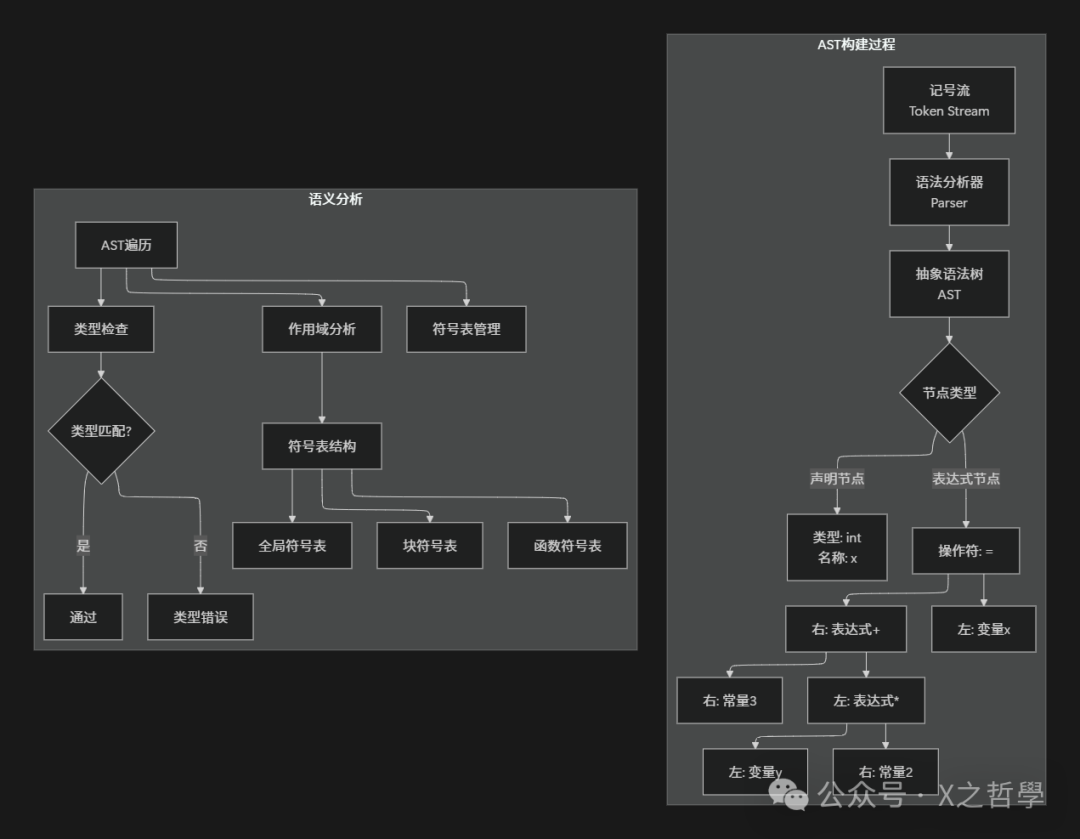
3.1.3 语义分析(Semantic Analysis)
语义分析器确保程序的意义是正确的,它进行类型检查、作用域分析,并构建符号表。
// 符号表数据结构
typedef struct Symbol {
char *name; // 符号名称
int type; // 数据类型
int scope; // 作用域层级
int is_initialized; // 是否已初始化
int is_function; // 是否为函数
int memory_offset; // 内存偏移量(用于代码生成)
struct Symbol *next; // 链表下一个
struct Symbol *params; // 参数列表(如果是函数)
} Symbol;
typedef struct SymbolTable {
Symbol *head; // 符号链表头
struct SymbolTable *parent; // 父作用域符号表
int level; // 作用域层级
} SymbolTable;
// 类型系统示例
typedef struct TypeInfo {
int base_type; // 基础类型: int, float, char等
int is_pointer; // 是否为指针
int pointer_level; // 指针层级
int array_size; // 数组大小(如果不是数组则为-1)
int size; // 类型大小(字节)
struct TypeInfo *subtype; // 子类型(用于结构体等)
} TypeInfo;
3.2 编译器优化: 中间代码的“精炼厂”
编译器优化器对中间表示进行各种转换,以提高程序性能。就像编辑优化文章,使其更简洁有力。
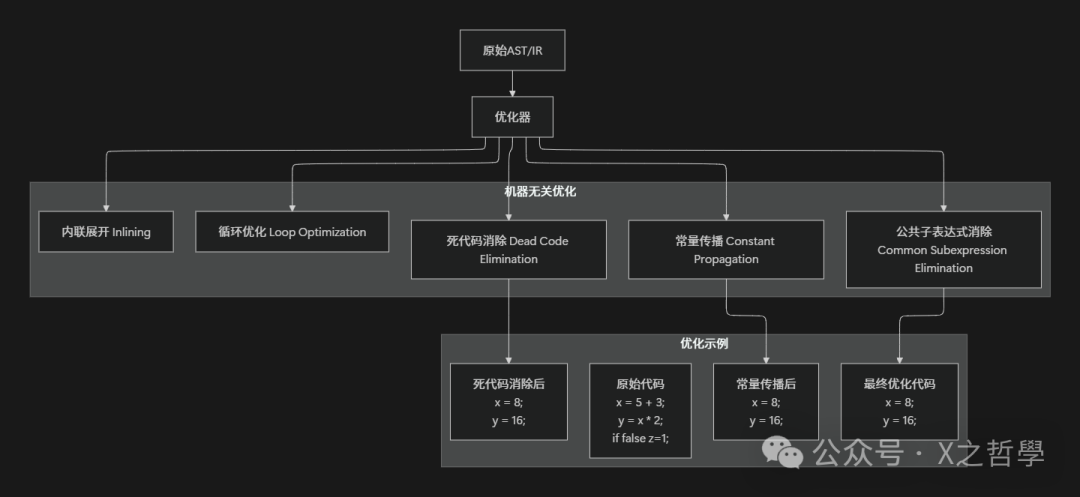 表3: 常见编译器优化技术
表3: 常见编译器优化技术
| 优化技术 |
描述 |
示例(优化前 → 优化后) |
效果 |
| 常量传播 |
将已知常量传播到使用处 |
x = 5; y = x + 3; → x = 5; y = 8; |
减少运行时的计算 |
| 常量折叠 |
编译时计算常量表达式 |
z = 2 * 3.14; → z = 6.28; |
消除编译时可计算表达式 |
| 死代码消除 |
删除永远执行不到的代码 |
if (false) { x = 1; } → `` |
减小代码体积 |
| 公共子表达式消除 |
重用相同表达式的计算结果 |
a = b * c + d; e = b * c + f; → tmp = b * c; a = tmp + d; e = tmp + f; |
减少重复计算 |
| 循环不变量外提 |
将循环内不变的计算移到循环外 |
for(i=0;i<n;i++) a[i]=x*y; → temp=x*y; for(i=0;i<n;i++) a[i]=temp; |
减少循环内的计算量 |
| 函数内联 |
将小函数调用替换为函数体 |
int sqr(int x){return x*x;} y=sqr(z); → y=z*z; |
减少函数调用开销 |
3.3 代码生成: 从中间表示到汇编
代码生成器将优化后的中间表示转换为目标平台的汇编代码。这是编译器的后端,需要深入了解目标机器的体系结构。
// 代码生成器的核心数据结构
typedef struct CodeGenContext {
FILE *output; // 输出文件
SymbolTable *symtab; // 符号表
int label_counter; // 标签计数器
int temp_var_counter; // 临时变量计数器
int stack_offset; // 栈偏移量
RegisterDescriptor *regs; // 寄存器描述符
} CodeGenContext;
// 寄存器分配示例(简化版)
typedef struct RegisterDescriptor {
char *name; // 寄存器名称: eax, ebx等
int is_free; // 是否空闲
Symbol *current_var; // 当前存储的变量
int last_used; // 最近使用时间(用于LRU)
} RegisterDescriptor;
// x86汇编代码生成示例
void generate_expression(CodeGenContext *ctx, ASTNode *node) {
switch(node->type) {
case NODE_CONSTANT:
// 生成加载常量到寄存器的代码
fprintf(ctx->output, " movl $%d, %%eax\n", node->value);
break;
case NODE_BINARY_OP:
// 生成二元运算代码
generate_expression(ctx, node->left);
push_register(ctx, "eax");
generate_expression(ctx, node->right);
pop_register(ctx, "ebx");
switch(node->value) { // value存储操作符
case '+':
fprintf(ctx->output, " addl %%ebx, %%eax\n");
break;
case '*':
fprintf(ctx->output, " imull %%ebx, %%eax\n");
break;
// ... 其他操作符
}
break;
case NODE_VARIABLE:
// 生成变量访问代码
Symbol *sym = lookup_symbol(ctx->symtab, node->name);
fprintf(ctx->output, " movl %d(%%ebp), %%eax\n",
sym->memory_offset);
break;
}
}
第四章: 汇编器: 从汇编到机器码的转换
4.1 汇编器的核心任务
汇编器接收编译器生成的汇编代码(文本格式),将其转换为可重定位的机器码。这个过程主要包括:
- 指令编码: 将助记符(如
mov, add)转换为操作码
- 符号解析: 记录未解析的符号供链接器处理
- 重定位信息生成: 标记需要链接时修正的地址
4.2 目标文件格式解析
目标文件(.o文件)通常采用ELF(Executable and Linkable Format)格式,包含多个节区(section):

4.3 汇编器实现核心
// 汇编器核心数据结构
typedef struct AssemblyLine {
char *label; // 标签(如果有)
char *mnemonic; // 助记符: mov, add等
char **operands; // 操作数数组
int num_operands; // 操作数数量
int address; // 指令地址
int machine_code; // 机器码
struct AssemblyLine *next; // 下一条指令
} AssemblyLine;
typedef struct SymbolRef {
char *name; // 符号名
int location; // 需要重定位的位置
int type; // 重定位类型
struct SymbolRef *next; // 下一个引用
} SymbolRef;
// 指令编码查找表
typedef struct InstructionInfo {
char *mnemonic; // 助记符
int opcode; // 操作码
int operand_types; // 操作数类型掩码
int size; // 指令大小(字节)
} InstructionInfo;
InstructionInfo instruction_table[] = {
{"mov", 0x88, REG_MEM, 2},
{"add", 0x00, REG_REG, 2},
{"sub", 0x28, REG_REG, 2},
{"call", 0xE8, REL32, 5},
{"ret", 0xC3, NONE, 1},
// ... 更多指令
};
第五章: 链接器: 模块的最终装配
5.1 链接器的核心功能
链接器是编译过程的最后阶段,负责将多个目标文件和库文件合并为单一的可执行文件。主要任务包括:
- 符号解析: 将符号引用与符号定义关联
- 重定位: 修正代码和数据中的地址引用
- 节区合并: 合并相同类型的节区
- 库解析: 解析并链接所需的库函数
5.2 链接过程详解
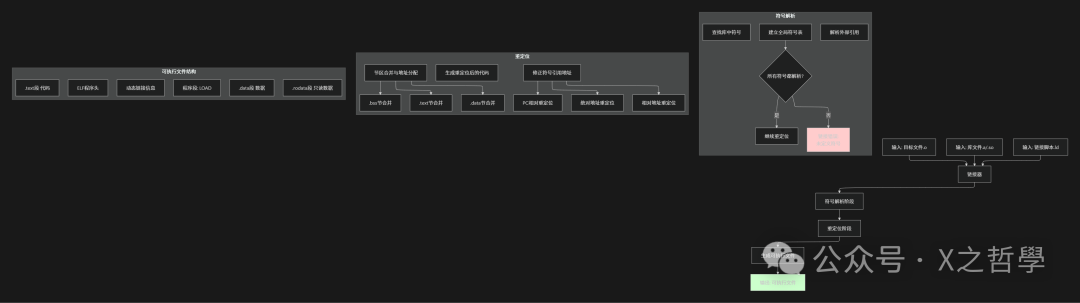
5.3 链接器核心算法
// 链接器核心数据结构
typedef struct GlobalSymbol {
char *name; // 符号名称
int defined; // 是否已定义
int value; // 符号值(地址)
int size; // 符号大小
char *filename; // 定义所在文件
int section; // 所在节区
struct GlobalSymbol *next; // 下一个符号
} GlobalSymbol;
typedef struct RelocationEntry {
int offset; // 需要重定位的位置
char *symbol; // 引用的符号
int type; // 重定位类型
int addend; // 加数
struct RelocationEntry *next;
} RelocationEntry;
// 简单的符号解析算法
GlobalSymbol *resolve_symbols(ObjectFile **files, int num_files) {
GlobalSymbol *global_table = NULL;
// 第一遍: 收集所有定义
for (int i = 0; i < num_files; i++) {
Symbol *sym = files[i]->symtab;
while (sym) {
if (sym->bind == STB_GLOBAL) {
GlobalSymbol *existing = find_symbol(global_table, sym->name);
if (existing) {
if (existing->defined) {
// 多重定义错误
fprintf(stderr, "多重定义符号: %s\n", sym->name);
return NULL;
}
} else {
add_symbol(&global_table, sym->name,
sym->value, sym->defined,
files[i]->name);
}
}
sym = sym->next;
}
}
// 第二遍: 解析外部引用
for (int i = 0; i < num_files; i++) {
RelocationEntry *reloc = files[i]->relocations;
while (reloc) {
GlobalSymbol *sym = find_symbol(global_table, reloc->symbol);
if (!sym || !sym->defined) {
// 未定义符号错误
fprintf(stderr, "未定义符号: %s\n", reloc->symbol);
return NULL;
}
reloc = reloc->next;
}
}
return global_table;
}
// 重定位算法
void apply_relocations(ObjectFile *file, GlobalSymbol *symtab) {
// 计算各节区的最终地址
int text_offset = 0x08048000; // .text段基址
int data_offset = text_offset + total_text_size;
// 应用重定位
RelocationEntry *reloc = file->relocations;
while (reloc) {
GlobalSymbol *sym = find_symbol(symtab, reloc->symbol);
if (sym) {
// 根据重定位类型计算新值
int new_value = calculate_relocation(reloc->type,
sym->value,
reloc->addend,
reloc->offset);
// 将新值写入指定位置
write_machine_code(file->data + reloc->offset,
new_value,
reloc->type);
}
reloc = reloc->next;
}
}
第六章: 完整编译实例演示
6.1 示例项目结构
让我们通过一个完整的多文件C项目来演示整个编译过程:
project/
├── main.c # 主程序
├── math_utils.c # 数学函数
├── math_utils.h # 数学函数头文件
└── helper.c # 辅助函数
math_utils.h:
#ifndef MATH_UTILS_H
#define MATH_UTILS_H
#define MAX(a,b) ((a)>(b)?(a):(b))
int add(int x, int y);
int multiply(int x, int y);
double circle_area(double radius);
#endif
math_utils.c:
#include "math_utils.h"
static const double PI = 3.1415926535;
int add(int x, int y) {
return x + y;
}
int multiply(int x, int y) {
return x * y;
}
double circle_area(double radius) {
return PI * radius * radius;
}
helper.c:
#include <stdio.h>
#include "math_utils.h"
void print_result(char* operation, int result) {
printf("%s 结果是: %d\n", operation, result);
}
main.c:
#include <stdio.h>
#include "math_utils.h"
int main() {
int a = 10, b = 20;
int sum = add(a, b);
print_result("加法", sum);
int product = multiply(a, b);
print_result("乘法", product);
double area = circle_area(5.0);
printf("半径为5的圆面积: %.2f\n", area);
int max_val = MAX(a, b);
printf("最大值: %d\n", max_val);
return 0;
}
6.2 分步编译过程
# 1. 预处理各个源文件
gcc -E main.c -o main.i
gcc -E math_utils.c -o math_utils.i
gcc -E helper.c -o helper.i
# 2. 编译为汇编代码
gcc -S main.i -o main.s
gcc -S math_utils.i -o math_utils.s
gcc -S helper.i -o helper.s
# 3. 汇编为目标文件
as main.s -o main.o
as math_utils.s -o math_utils.o
as helper.s -o helper.o
# 4. 链接为可执行文件
ld -dynamic-linker /lib64/ld-linux-x86-64.so.2 \
/usr/lib/crt1.o /usr/lib/crti.o \
main.o math_utils.o helper.o \
-lc /usr/lib/crtn.o \
-o myprogram
# 或者使用gcc一步完成(推荐)
gcc main.c math_utils.c helper.c -o myprogram
6.3 编译过程内部状态跟踪
让我们跟踪add函数从源代码到机器码的转换:

第七章: 编译工具链与调试技术
7.1 GNU编译工具链核心命令
表4: GCC编译选项详解
| 选项类别 |
选项 |
功能描述 |
示例用法 |
| 预处理 |
-E |
只进行预处理 |
gcc -E file.c -o file.i |
|
-DNAME[=VALUE] |
定义宏 |
gcc -DDEBUG -DVERSION=1 |
|
-Ipath |
添加头文件搜索路径 |
gcc -I./include |
| 编译 |
-S |
只编译到汇编 |
gcc -S file.c |
|
-c |
编译到目标文件 |
gcc -c file.c |
|
-std= |
指定C标准 |
gcc -std=c11 |
| 优化 |
-O0 |
不优化(默认) |
gcc -O0 file.c |
|
-O1 |
基本优化 |
gcc -O1 file.c |
|
-O2 |
更多优化 |
gcc -O2 file.c |
|
-O3 |
激进优化 |
gcc -O3 file.c |
|
-Os |
优化代码大小 |
gcc -Os file.c |
| 调试 |
-g |
生成调试信息 |
gcc -g file.c |
|
-ggdb |
生成GDB专用调试信息 |
gcc -ggdb file.c |
|
-pg |
生成性能分析代码 |
gcc -pg file.c |
| 警告 |
-Wall |
开启大部分警告 |
gcc -Wall file.c |
|
-Wextra |
更多警告 |
gcc -Wextra file.c |
|
-Werror |
视警告为错误 |
gcc -Werror file.c |
| 链接 |
-Lpath |
添加库搜索路径 |
gcc -L./lib |
|
-llib |
链接库文件 |
gcc -lm 链接数学库 |
|
-static |
静态链接 |
gcc -static file.c |
|
-shared |
生成共享库 |
gcc -shared -o lib.so |
熟练使用这些系统级工具是每个C/C++开发者必备的技能。
7.2 二进制分析工具
表5: 二进制分析与调试工具
| 工具 |
主要功能 |
常用命令 |
输出示例 |
| file |
识别文件类型 |
file program |
program: ELF 64-bit LSB executable, x86-64 |
| objdump |
反汇编目标文件 |
objdump -d program.o |
显示汇编代码 |
|
查看节区头 |
objdump -h program.o |
显示各节区信息 |
|
查看符号表 |
objdump -t program.o |
显示符号列表 |
| nm |
列出符号表 |
nm program.o |
显示符号地址和类型 |
| readelf |
显示ELF文件信息 |
readelf -a program |
完整的ELF信息 |
|
查看节区头 |
readelf -S program.o |
节区详细信息 |
|
查看程序头 |
readelf -l program |
段(segment)信息 |
| strings |
提取文件中的字符串 |
strings program |
显示所有可打印字符串 |
| size |
显示节区大小 |
size program.o |
.text .data .bss大小 |
| ldd |
显示动态依赖 |
ldd program |
显示所需的动态库 |
| strace |
跟踪系统调用 |
strace ./program |
显示所有系统调用 |
7.3 调试技术实战
7.3.1 使用GDB调试编译器生成的代码
# 编译带调试信息的程序
gcc -g -O0 -o debug_program main.c math_utils.c helper.c
# 启动GDB调试
gdb ./debug_program
# GDB常用命令
(gdb) break main # 在main函数设置断点
(gdb) run # 运行程序
(gdb) step # 单步进入函数
(gdb) next # 单步跳过函数
(gdb) print x # 打印变量x的值
(gdb) backtrace # 显示调用栈
(gdb) disassemble # 反汇编当前函数
(gdb) info registers # 查看寄存器值
(gdb) x/10i $pc # 查看当前指令附近代码
(gdb) quit # 退出GDB
7.3.2 使用objdump分析二进制文件
# 反汇编查看机器码
objdump -d -M intel debug_program | less
# 查看特定函数
objdump -d -M intel debug_program | grep -A 20 "<add>:"
# 输出示例:
# 0804841b <add>:
# 804841b: 55 push ebp
# 804841c: 89 e5 mov ebp,esp
# 804841e: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
# 8048421: 03 45 0c add eax,DWORD PTR [ebp+0xc]
# 8048424: 5d pop ebp
# 8048425: c3 ret
7.3.3 链接过程调试
# 查看链接过程中的符号解析
gcc -Wl,--verbose main.o math_utils.o helper.o -o program
# 查看链接器使用的库路径
gcc -print-search-dirs
# 生成链接器映射文件(查看内存布局)
gcc -Wl,-Map=program.map main.c math_utils.c helper.c -o program
第八章: 高级编译技术扩展
8.1 静态库与动态库
表6: 静态库 vs 动态库对比
| 特性 |
静态库 (.a) |
动态库 (.so/.dll) |
| 链接时机 |
编译时链接 |
运行时链接 |
| 文件包含 |
库代码复制到可执行文件 |
库代码独立于可执行文件 |
| 磁盘空间 |
占用较多(每个程序包含库代码) |
占用较少(多个程序共享) |
| 内存使用 |
每个程序有自己的库副本 |
多个程序共享内存中的库代码 |
| 更新维护 |
需重新编译程序 |
只需替换库文件(注意ABI兼容性) |
| 加载速度 |
启动快(已链接) |
启动稍慢(需要加载库) |
| 示例命令 |
ar rcs libmath.a *.o |
gcc -shared -o libmath.so *.o |
| 链接方式 |
gcc main.o -L. -lmath -o prog |
gcc main.o -L. -lmath -o prog |
8.2 交叉编译
交叉编译允许在一个平台上编译另一个平台的可执行代码。这在嵌入式开发和系统移植中至关重要。
# 安装交叉编译工具链
sudo apt-get install gcc-arm-linux-gnueabi
# 交叉编译ARM程序
arm-linux-gnueabi-gcc -o arm_program hello.c
# 查看交叉编译后的文件类型
file arm_program
# 输出: arm_program: ELF 32-bit LSB executable, ARM, EABI5 version 1 (SYSV), dynamically linked...
# 指定目标平台和架构
gcc -target x86_64-pc-linux-gnu -o linux_program hello.c
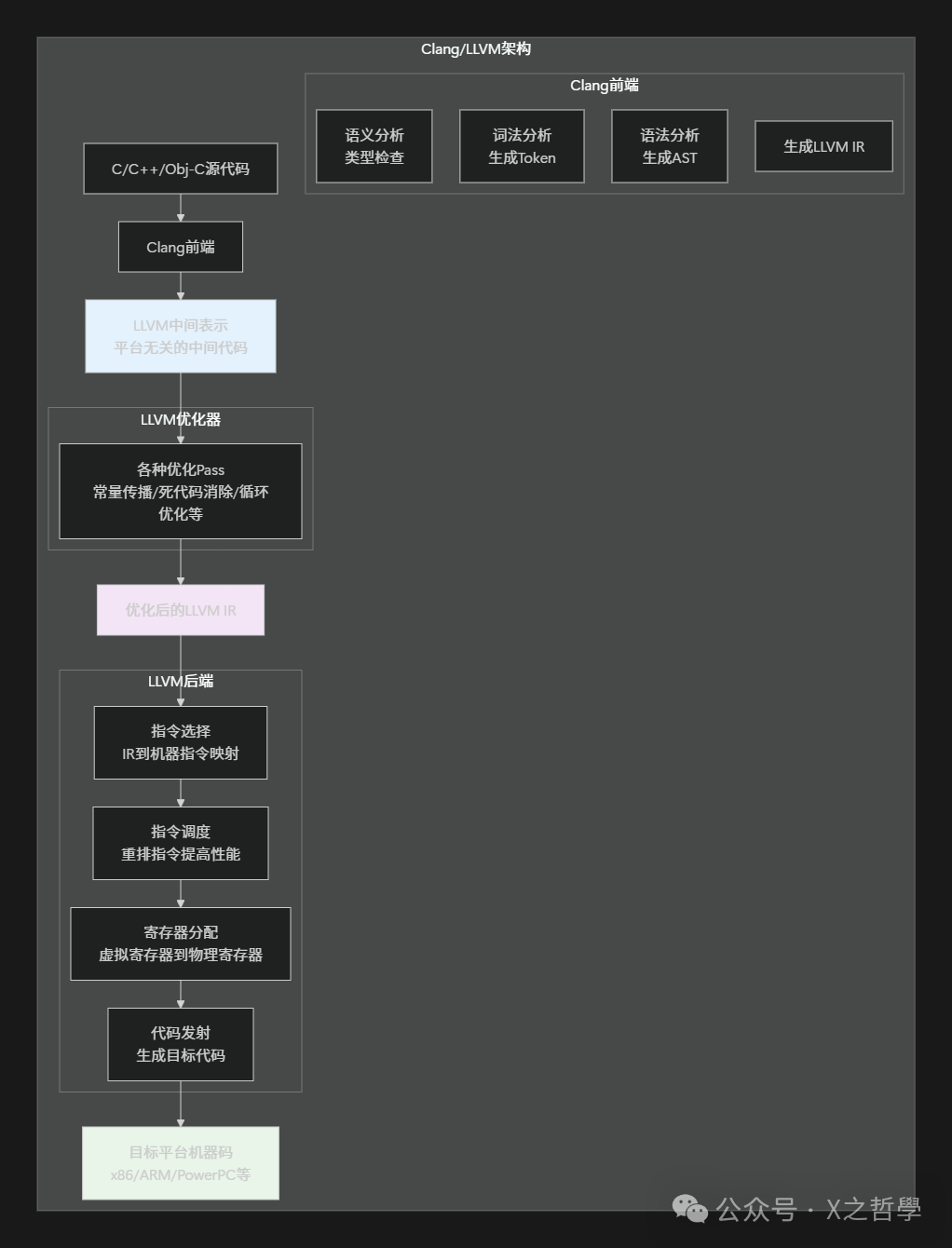
8.3 编译器前端技术: Clang/LLVM架构
现代编译器如Clang/LLVM采用了模块化设计,将前端、优化器和后端分离:
第九章: 编译原理在现代开发中的应用
9.1 即时编译(JIT)技术
JIT编译器在程序运行时动态编译字节码为本地机器码,结合了解释执行的灵活性和本地代码的高效性。
// 简化的JIT编译器概念示例
typedef struct JITCompiler {
void *code_buffer; // 代码缓冲区
size_t buffer_size; // 缓冲区大小
size_t code_pos; // 当前代码位置
// 编译方法
void (*emit_prologue)(struct JITCompiler*);
void (*emit_epilogue)(struct JITCompiler*);
void (*emit_add)(struct JITCompiler*, int reg1, int reg2);
void (*emit_call)(struct JITCompiler*, void *func);
} JITCompiler;
// 使用JIT编译执行动态代码
void execute_dynamic_code() {
JITCompiler jit;
init_jit_compiler(&jit, 4096);
// 动态生成函数: 返回两个参数的和
jit.emit_prologue(&jit);
jit.emit_add(&jit, 0, 1); // 将参数0和1相加
jit.emit_epilogue(&jit);
// 将生成的代码转为可执行函数
typedef int (*AddFunc)(int, int);
AddFunc add_func = (AddFunc)jit.code_buffer;
// 执行动态生成的代码
int result = add_func(10, 20);
printf("JIT计算结果: %d\n", result);
cleanup_jit_compiler(&jit);
}
9.2 编译技术在代码分析中的应用
现代IDE的智能提示、重构工具和静态分析工具都依赖于编译器技术:
- 语法高亮: 基于词法分析器识别不同词法单元
- 代码补全: 基于语法分析器的AST和符号表
- 静态分析: 基于数据流分析和控制流分析发现潜在错误
- 重构工具: 基于AST变换实现重命名、提取函数等操作
9.3 领域特定语言(DSL)编译器
许多现代框架使用内部DSL,这些DSL需要专门的编译器或解释器。
// 简化的SQL DSL编译器概念
typedef struct SQLStatement {
enum { SELECT, INSERT, UPDATE, DELETE } type;
char **columns;
char *table;
struct Condition *where_clause;
struct SQLStatement *next; // 用于UNION等
} SQLStatement;
// SQL DSL编译为实际SQL字符串
char *compile_sql(SQLStatement *stmt) {
StringBuilder *sb = create_string_builder();
switch(stmt->type) {
case SELECT:
string_builder_append(sb, "SELECT ");
for (int i = 0; stmt->columns[i]; i++) {
if (i > 0) string_builder_append(sb, ", ");
string_builder_append(sb, stmt->columns[i]);
}
string_builder_append(sb, " FROM ");
string_builder_append(sb, stmt->table);
if (stmt->where_clause) {
string_builder_append(sb, " WHERE ");
compile_condition(sb, stmt->where_clause);
}
break;
// ... 其他SQL类型
}
return string_builder_to_string(sb);
}
第十章: 总结与展望
10.1 C语言编译处理全景回顾
通过本文的深入剖析,我们全面了解了C语言编译处理的完整流程。让我们用一张综合图回顾整个过程:
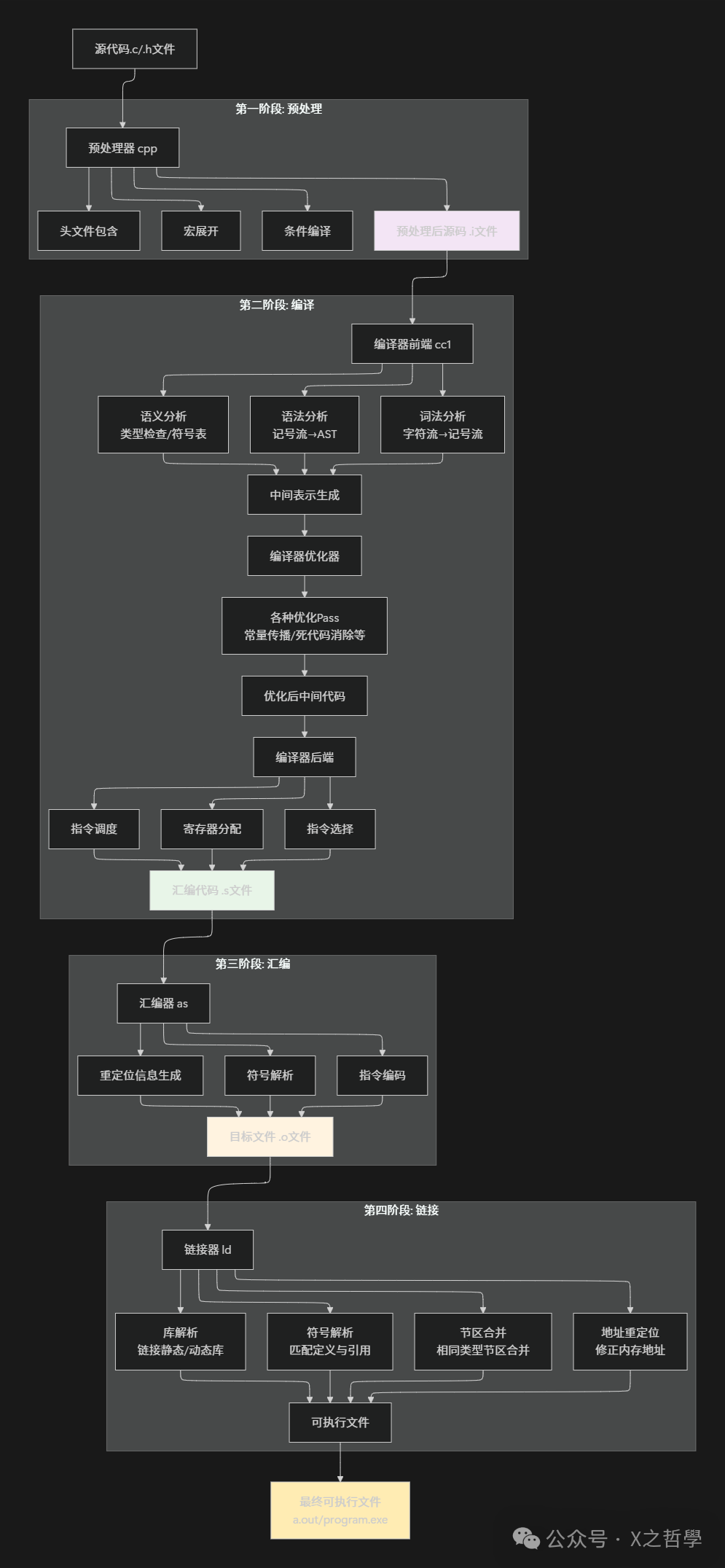
10.2 编译技术演进趋势
表7: 编译技术发展趋势
| 趋势 |
描述 |
代表技术/工具 |
优势 |
| 模块化编译 |
将编译器分解为独立组件 |
LLVM/Clang架构 |
可重用组件,易于维护和扩展 |
| 增量编译 |
只重新编译改变的部分 |
Visual Studio增量编译 |
大幅缩短大型项目编译时间 |
| 分布式编译 |
在多台机器上并行编译 |
distcc, icecream |
利用多机资源加速编译 |
| 预编译头文件 |
预处理常用头文件缓存 |
GCC的预编译头文件 |
减少重复预处理时间 |
| 链接时代码生成 |
链接时进行全局优化 |
LTO(Link Time Optimization) |
跨模块优化,提高性能 |
| 配置文件引导优化 |
基于运行数据优化 |
PGO(Profile Guided Optimization) |
针对实际使用模式优化 |
| 多阶段编译 |
分阶段优化编译 |
分级优化(-O1, -O2, -O3) |
平衡编译时间和代码质量 |
10.3 结语
C语言编译处理是一个复杂但精巧的系统工程,它像一座精心设计的工厂流水线,将人类可读的高级语言代码转化为机器能高效执行的指令。从预处理器的文本处理,到编译器的深度分析和优化,再到汇编器和链接器的精密装配,每个阶段都有其独特的数据结构、算法和设计哲学。
正如计算机科学家Niklaus Wirth所言: “程序 = 算法 + 数据结构”,而编译器正是将这一公式转化为可执行现实的关键桥梁。掌握编译原理,你将在系统软件开发的殿堂中拥有更深刻的洞察力和更强大的解决问题的能力。
 发表于 2025-12-7 00:49:21
|
查看: 168|
回复: 0
发表于 2025-12-7 00:49:21
|
查看: 168|
回复: 0
