本文内容转自:Substack


数据背后的“错位感”
2026年2月,一份来自OpenRouter的周报在中国AI圈激起千层浪:平台前十模型中,中国模型消耗了61%的Token,前三名(MiniMax M2.5、Kimi K2.5、智谱 GLM-5)全线来自中国。
在中国正深陷“芯片禁令”和“算力荒”焦虑的背景下,这份成绩单显得极度超现实。既然缺芯片,为什么中国的Token还能在海外“倾销”?甚至有人开始产生幻觉:这会不会导致美国的算力过剩?
但在欢呼之前,我们需要先拆解这61%究竟意味着什么。
OpenRouter:是“全景图”还是“实验室”?
要理解这组数据,必须先理解OpenRouter是一个什么样的存在。
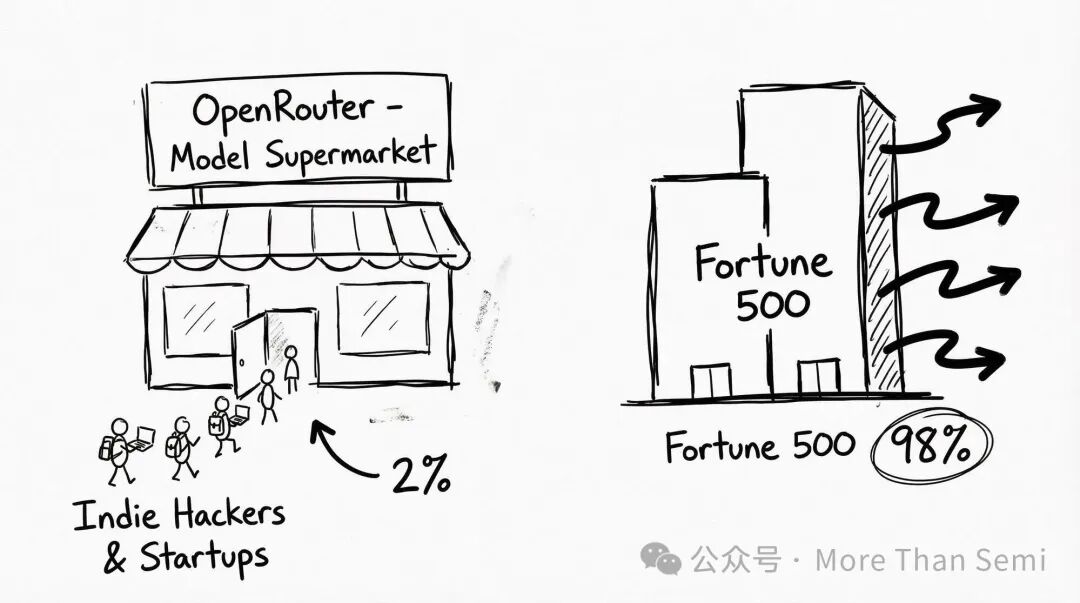
它是谁:OpenRouter是全球最大的AI API聚合平台,一个“模型超市”。它深受个人开发者、独立黑客和初创公司的喜爱。
谁在用:
首先是Agent工具的使用者。比如使用Cursor、Cline或OpenClaw的开发者,这些工具需要频繁调用不同模型进行代码编写和自动化任务,OpenRouter提供的一站式Key是刚需。
其次是成本敏感型项目,那些还在寻找PMF(产品市场契合点)的小型AI应用。
事实真相:OpenRouter虽然在开发者社区声量巨大,但在全球AI支出中的市场份额其实仅占2%左右。
真正的流量大头——那些消耗了全球90%以上Token的财富500强企业、大型SaaS厂商(如Salesforce、Microsoft),它们绝不会通过OpenRouter调用模型,而是直接对接OpenAI、Anthropic的官方原生API或通过Azure/AWS托管。
结论很清晰:中国模型的“霸榜”目前局限在全球AI应用的“创新实验室”里,尚未攻入企业级的“中央机房”。
中国Token的“出海优势”:价格、价格,还是价格
为什么在OpenRouter这种“用脚投票”的市场,中国模型能瞬间屠榜?
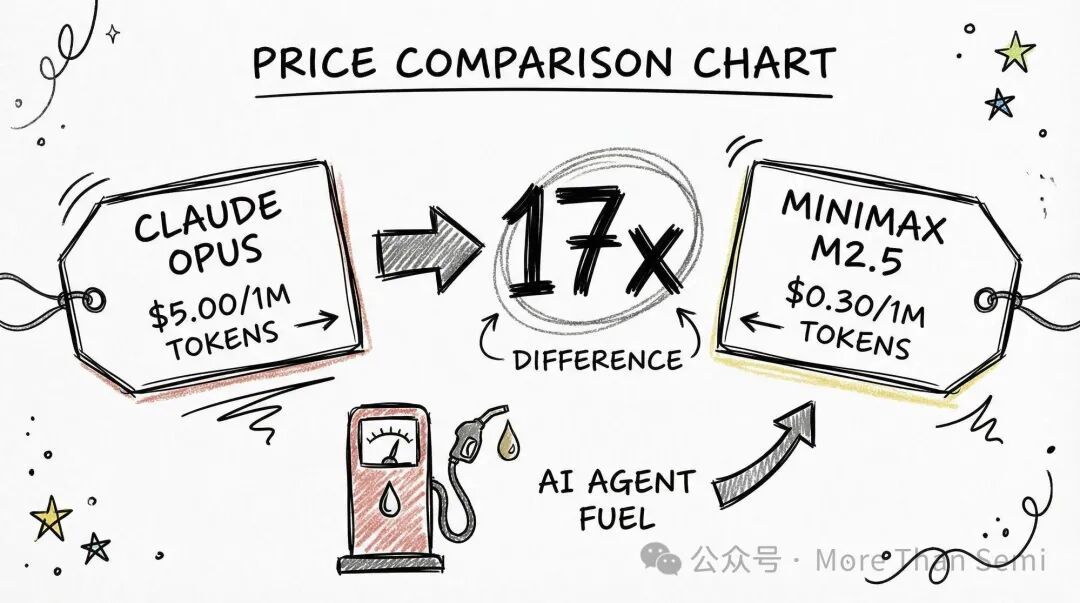
极致性价比:当Claude Opus 4.6的输入价格还在$5.00/1M tokens时,MiniMax M2.5已经做到了$0.30。这是近17倍的价差。
Agent时代的“燃料费”:2026年进入了AI Agent爆发年。运行一个像OpenClaw这样的智能体,一次任务可能要扫掉几百万个Token。如果用美国模型,一天的测试费可能就要几十美金;换成国产模型,只需几美金。
为什么中国Token能这么便宜?
模型架构的极致压榨:像DeepSeek、MiniMax等厂商在MoE(混合专家模型)和稀疏注意力机制上的优化,让推理成本大幅下降。
“以量换价”的出海策略:在算力受限的情况下,国产厂商必须提高单颗芯片的产出效率,将沉没成本摊薄到海量的海外Token订单中。
国内市场的内卷外溢:国内API市场的“价格战”已经常态化,这种在极低毛利下生存的韧性,在海外市场形成了“降维打击”。
被忽视的杀手锏:电力成本的跨境套利
但如果只看到价格战,你就只看到了故事的一半。中国Token的真正杀手锏,藏在一个更底层的逻辑里:电力价值的跨境交付。
这个概念听起来有点抽象,我们来拆解一下。
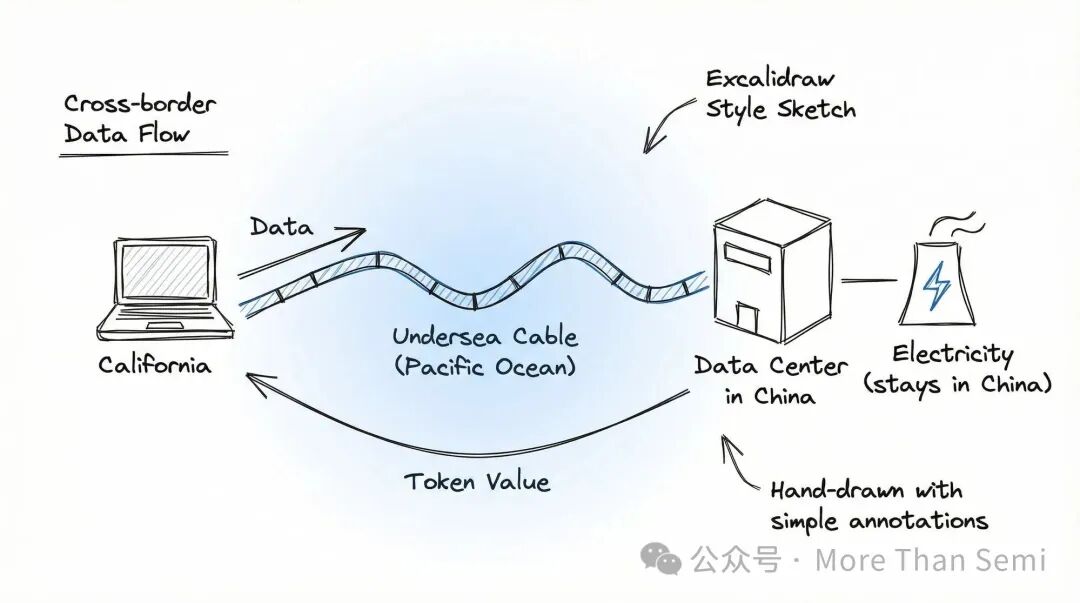
当一个美国开发者在旧金山调用MiniMax的API时,发生了什么?数据从加州出发,经过太平洋海底光缆,到达中国的数据中心。GPU在那里完成推理计算,结果再传回美国。
整个过程中,电力从未离开中国的电网,但电力的价值通过Token完成了跨境交付。
这不是比喻,这是真实的商业逻辑。
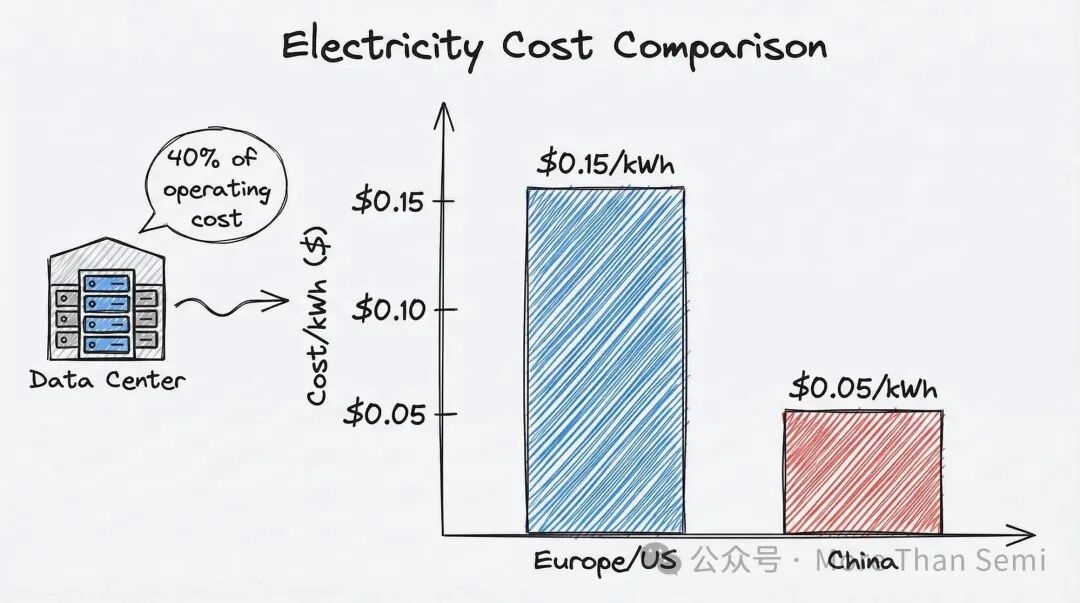
Token的成本拆开来看,最核心的两项是算力和电力。算力是GPU的折旧摊销,电力是数据中心的运营成本。而电费可以占到数据中心运营成本的40%。
这里就出现了一个巨大的成本剪刀差:
中国的工业电价,根据地区和政策不同,大约在0.4-0.6元/度(约$0.05-0.08/kWh)。 而欧美数据中心的平均电价在$0.15/kWh甚至更高,比中国高出50%以上。
更关键的是,中国的电力基础设施极其完善。数据中心想要接入电网?审批流程虽然复杂,但只要符合规范,电力供应是稳定且充足的。反观美国,现在很多地方的数据中心面临“获电难”的困境。
所以会出现一个有趣的现象:中国的AI公司虽然在芯片上受限,但在电力这个更底层的资源上,反而拥有结构性优势。
这就解释了为什么“算力荒”和“Token出海”可以同时存在——中国厂商是在用有限的算力,配合极致的电力成本优势,榨干每一颗GPU的产出效率。每一个Token的背后,都是中国电网在为全球开发者“供电”。
从这个角度看,Token出海不只是API调用量的增长,它本质上是中国电力价值的全球化输出。这是一种看不见的“新三样”。
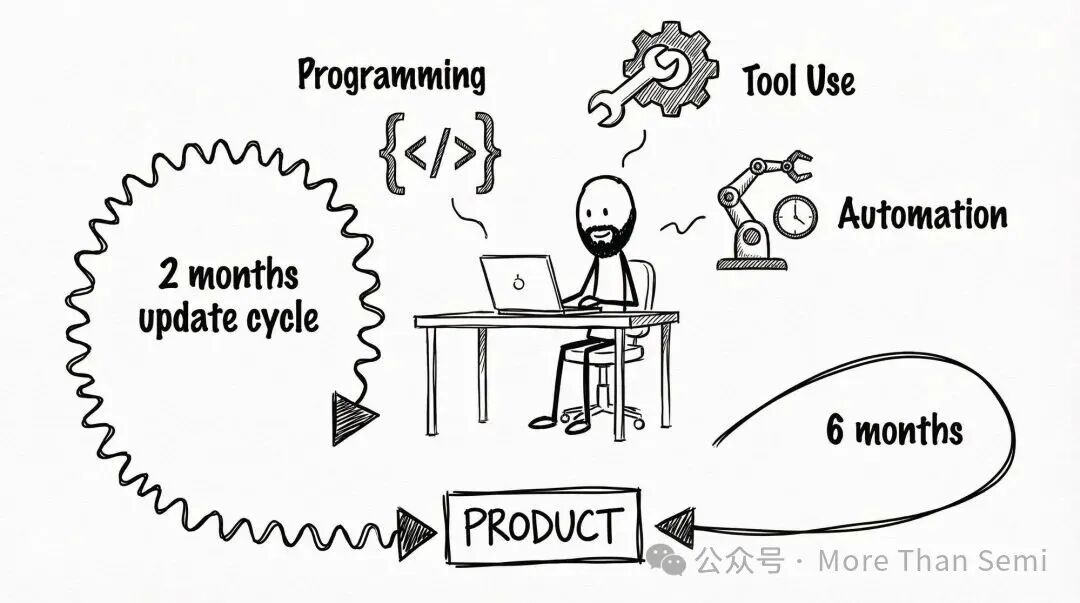
实力不容小觑:从“廉价平替”到“实战尖兵”
如果仅仅是便宜,开发者是不会买单的。中国Token的激增也释放了一个硬核信号:国产大模型已经能够处理真实、复杂的业务场景了。
不仅仅是闲聊:在OpenRouter的统计中,中国模型在Programming(编程)和Tool Use(工具调用)两个类目下的增长最快。这说明在处理真实代码、自动化脚本等生产力任务时,M2.5或GLM-5的表现已经达到了“可用且好用”的门槛。
快速迭代的红利:相比硅谷巨头长达半年的更新周期,国产模型几乎每两个月就有一个“大版本”迭代。这种对开发者反馈的快速响应,让中国模型在OpenRouter这种极度灵活的市场里如鱼得水。
一位做AI Agent的开发者分享了他的经历:“以前用GPT-4测试,一天烧掉几十美金,心疼得不行。现在换成Kimi,成本降到十分之一,迭代速度反而更快了。”
这就是中国模型在开发者生态里的真实位置:不是“能用就行”的备胎,而是“好用且便宜”的首选。
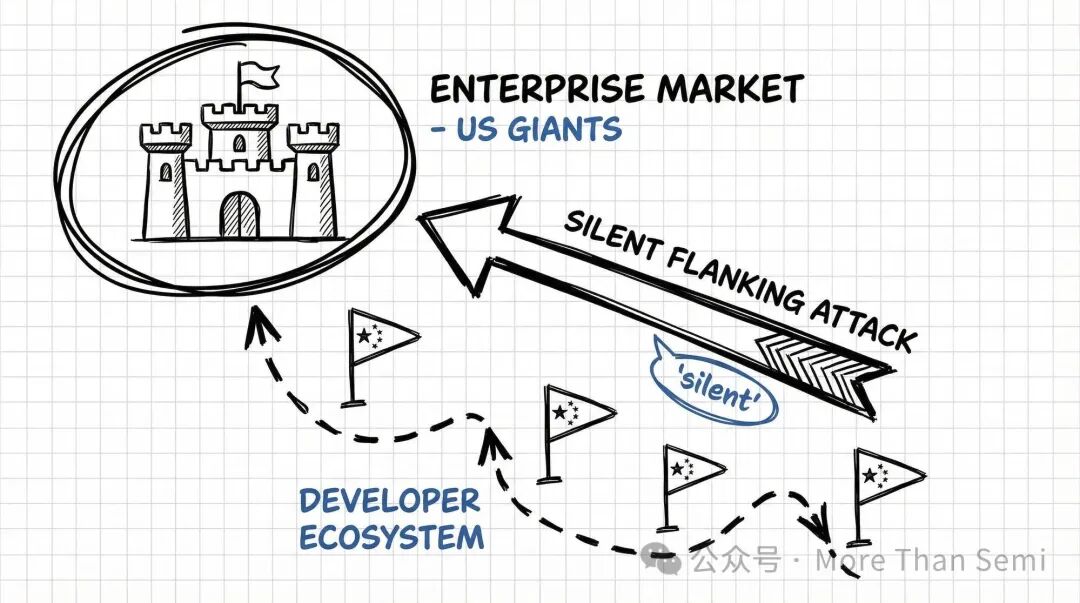
清醒的胜利
我们不应神话61%这个数字,因为它并没有改变全球AI算力格局;但我们也不应轻视它。
这份数据证明了:在全球AI应用的底座层,中国模型正在通过“性价比 + 电力成本优势 + 快速迭代”建立起一套属于自己的生态位。虽然大企业的主战场还在美国巨头手中,但在全球数百万开发者的指尖下,中国的Token正在成为AI时代最实惠、最充沛的“燃料”。
这不是“过剩”的补位,这是一场关于效率与生存空间的、沉默的侧翼突袭。
OpenRouter的2%市场份额今天看起来微不足道,但谁能保证,五年后这些用惯了MiniMax的独立开发者,不会成长为下一个独角兽的CTO?谁能保证,今天在“实验室”里跑通的商业模式,不会在明天攻入“中央机房”?
历史告诉我们,侧翼突袭往往比正面硬刚更有效。
中国AI的故事,或许才刚刚开始。对于这场围绕算力、电力和开发者生态的竞争,欢迎到云栈社区的开发者广场参与更多讨论。
 发表于 2026-2-28 05:47:36
|
查看: 206|
回复: 0
发表于 2026-2-28 05:47:36
|
查看: 206|
回复: 0
