向AI编程助手提出开发需求时,如果刻意不在提示词中提及任何具体工具,它会如何选择?最近,专注于量化AI主观决策的基准测试工作室 Amplifying.ai 针对 Claude Code 的工具选择倾向开展了一项系统性研究。
研究覆盖了3款模型、4种项目类型以及20个工具类别,累计分析了2430次工具选择行为。
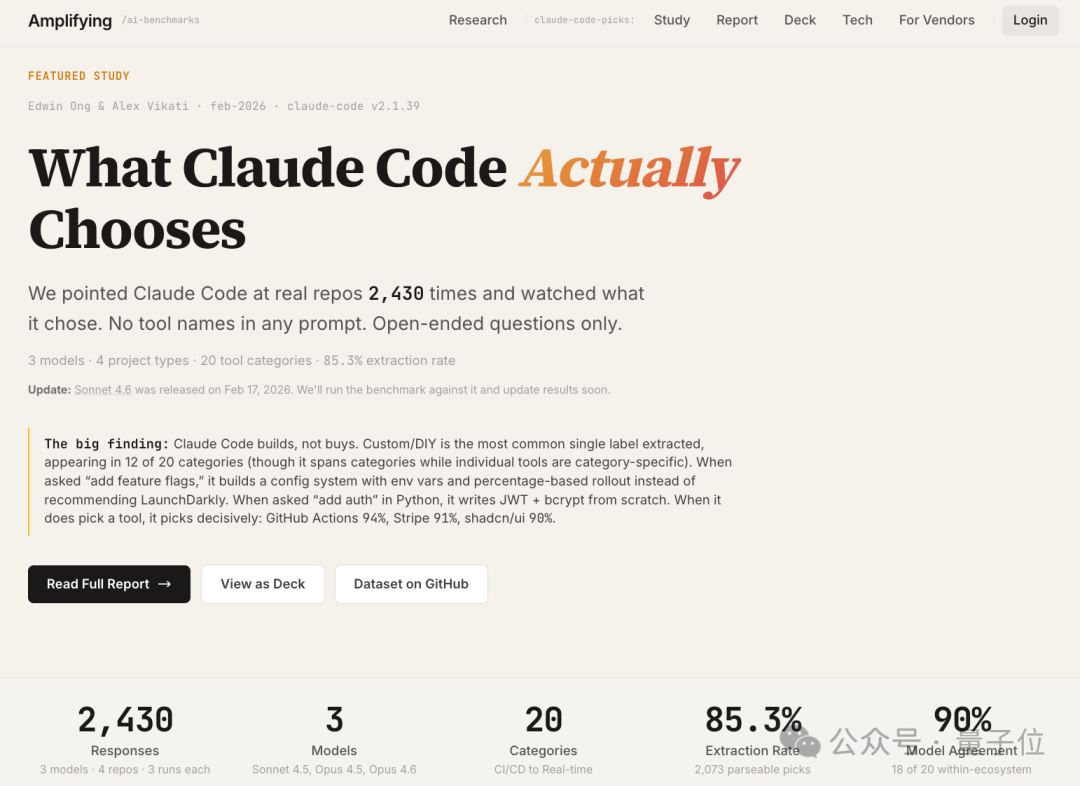
实验全程采用开放式提示词,例如“我应该用什么?”,完全不包含工具名称,旨在观察并记录 Claude Code 在实际操作中的自主选择。

通过这项大规模的测试,研究团队得出了以下几项核心结论:
- 倾向“自建”而非选用第三方工具:Claude Code 更倾向于自己编写自定义解决方案,而不是直接推荐现成的第三方工具。自定义/DIY实现占所有可提取主要选择的12%(2073次中的252次),成为最常见的选择。
- 默认技术栈已然形成:在推荐第三方工具时,Claude Code 的选择高度集中于一组默认工具,如 Vercel、PostgreSQL、Stripe、Tailwind CSS、shadcn/ui 等。此外,还会根据不同技术栈选择专属工具。
- 部分工具类别已“锁定”单一工具:例如,GitHub Actions 占据 CI/CD 类别94%的选择,shadcn/ui 占据 UI 组件类别90%的选择,Stripe 占据了支付类别91%的选择。
- 同一技术生态下,不同模型选择高度一致:在同一生态(如都是 JavaScript 或都是 Python)内比较时,三个模型在20个类别中的18个,都选择了相同的首选工具。
- 项目上下文比指令措辞更重要:同一工具类别在不同代码仓库中,Claude Code 的选择会随项目类型变化。但如果是同一个项目,即便使用不同的方式表述指令,其选择的稳定性平均也能达到76%。

实验设置
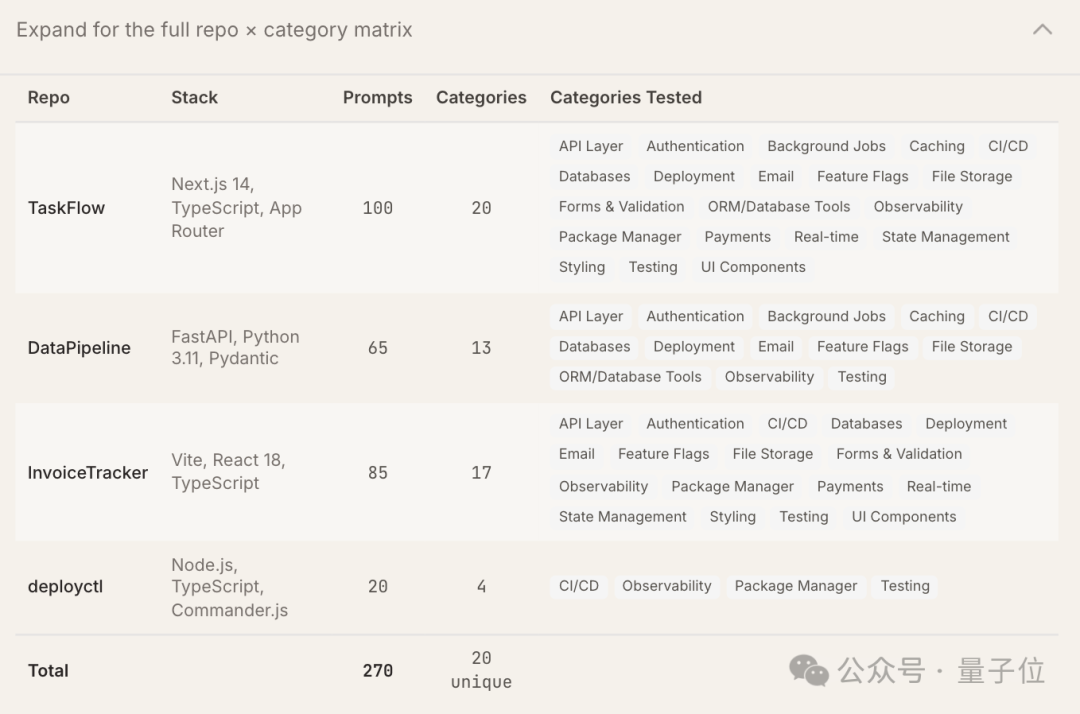
为了深入探究 Claude Code 的工具选择逻辑,研究团队搭建了4个全新的代码仓库开展测试,并针对20个工具类别设计了100条开放式指令。
测试覆盖了 Claude Sonnet 4.5、Opus 4.5、Opus 4.6 三款模型,每款模型在每个仓库上独立运行三次。为确保证每次实验的独立性,在每条指令执行前,均执行 git checkout . && git clean -fd 命令以重置代码环境。

所有提示词均未指定具体工具,例如:
- how do i deploy this?
- i need a database, what should i use
- add user authentication
- what testing framework works best with this stack

当 Claude Code 给出响应后,会由一个专门的子智能体(Subagent)来处理结果。该子智能体不负责执行任务,其唯一职责是读取全部响应内容,并从中提取出最核心的那个工具推荐。

研究团队还详细说明了实验采用的评估方法与各项指标的定义。
需要注意的是,并非所有20个工具类别都在全部4个仓库中进行了测试。部分类别因与特定仓库的项目类型不匹配而未被纳入。具体的测试覆盖矩阵如下:
团队特别强调,本研究聚焦于分析 AI 代码助手的显性偏好,其结果既不代表开发者的真实偏好,也不构成对工具质量的评估。
研究结果
喜欢自己从零搭建功能
测试中,Claude Code 频繁选择从零搭建功能,而非直接推荐第三方工具。
例如,当需求为“添加功能标记”时,它不会建议使用 LaunchDarkly 这类现成服务,而是基于环境变量与框架基础功能,完整实现一套包含百分比滚动的功能标记系统。
“自定义/DIY”方案在12个不同的工具类别中,累计被选为首选252次,其出现频率甚至超过了 GitHub Actions(152次)、Vitest(101次)等热门工具。
不过需要说明,该数据是跨12个类别的汇总结果,而其他工具仅在特定类别中被推荐,二者并非同一类别内的直接对比。在多工具可选的具体类别中,“自定义/DIY”在功能标记与身份认证领域的推荐率最高。
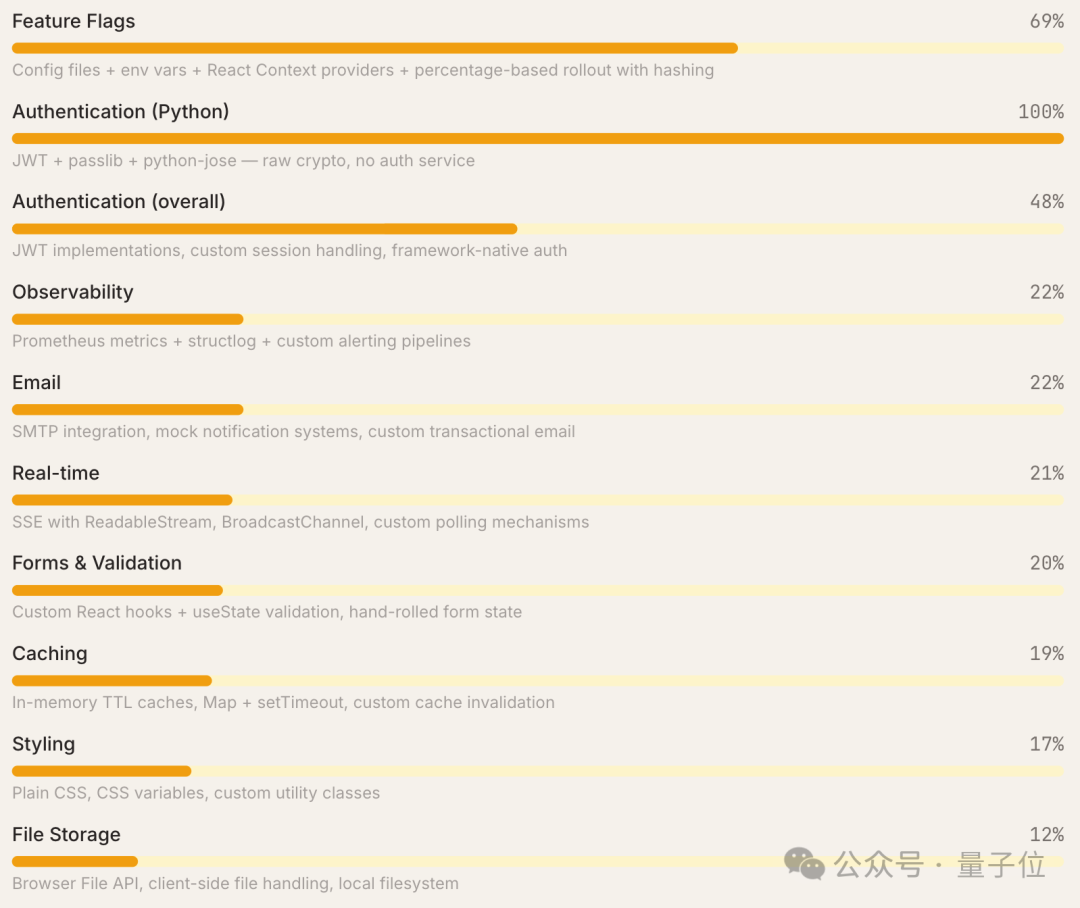
针对“是否存在子智能体将复杂回答误判为自定义方案”的疑问,研究团队人工抽查了50个被标记为“自定义/DIY”的案例。结果显示约80%为真实的从零搭建场景,剩余20%存在边界模糊的情况。这意味着真实的“自定义/DIY”比例可能略低于报告数据,但核心结论不变——Claude Code 明显更偏爱自主构建方案。
哪个工具被首选的概率最高?
在全部2073条可提取工具推荐的响应中(不含“自定义/DIY”方案),被选为首选工具次数最多的前20名如下:
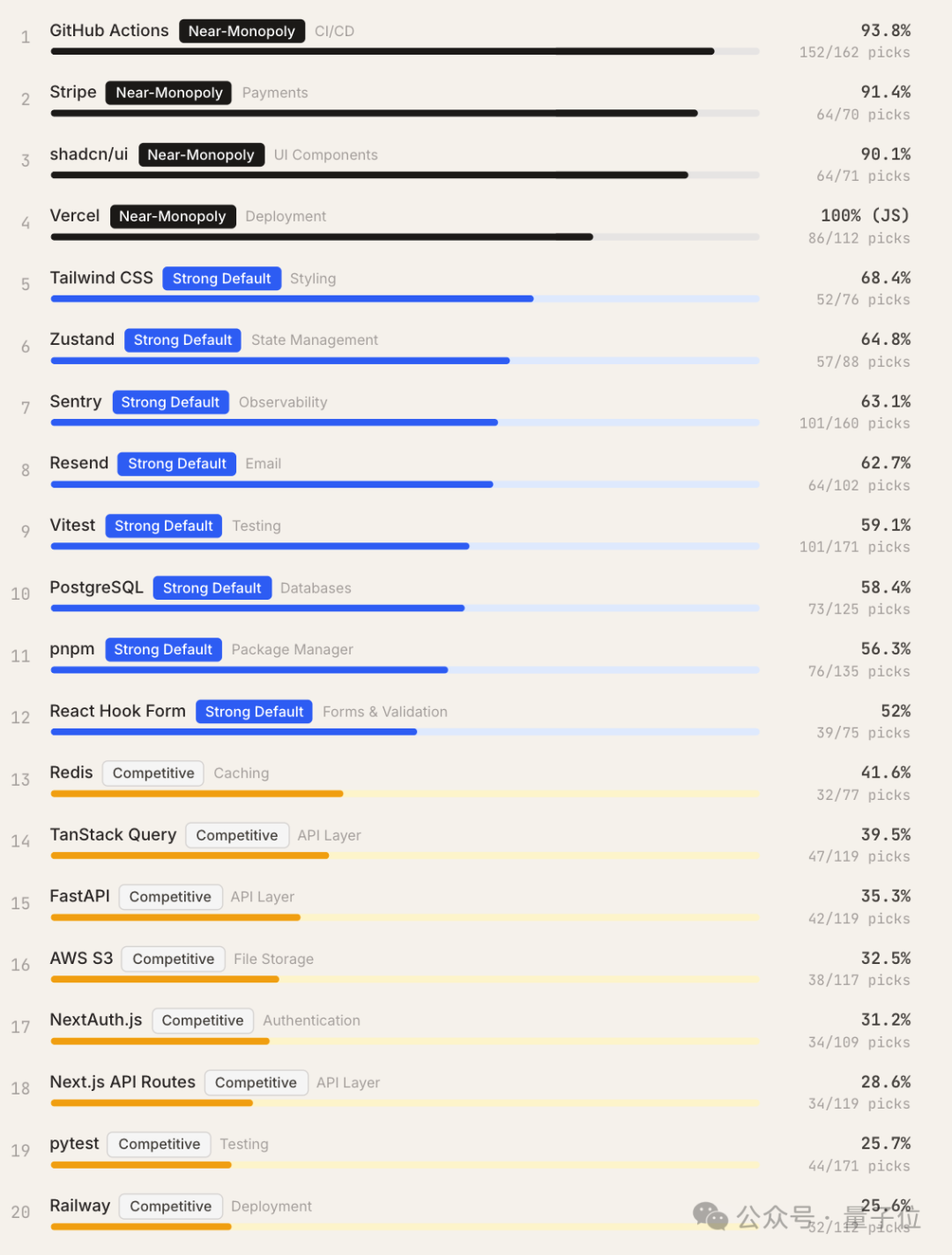
具体来看,实验中有4个工具类别呈现出单一工具主导率超75%的特征(近乎垄断):
- CI/CD:GitHub Actions 以93.8%的首选率占据绝对优势。
- 支付处理(Payments):Stripe 首选率高达91.4%。
- UI组件库(UI Components):shadcn/ui 以90.1%的占比成为默认选择。
- 部署(Deployment):在 JavaScript 生态下 Vercel 首选率达100%,Python 生态则由 Railway 主导(82%)。
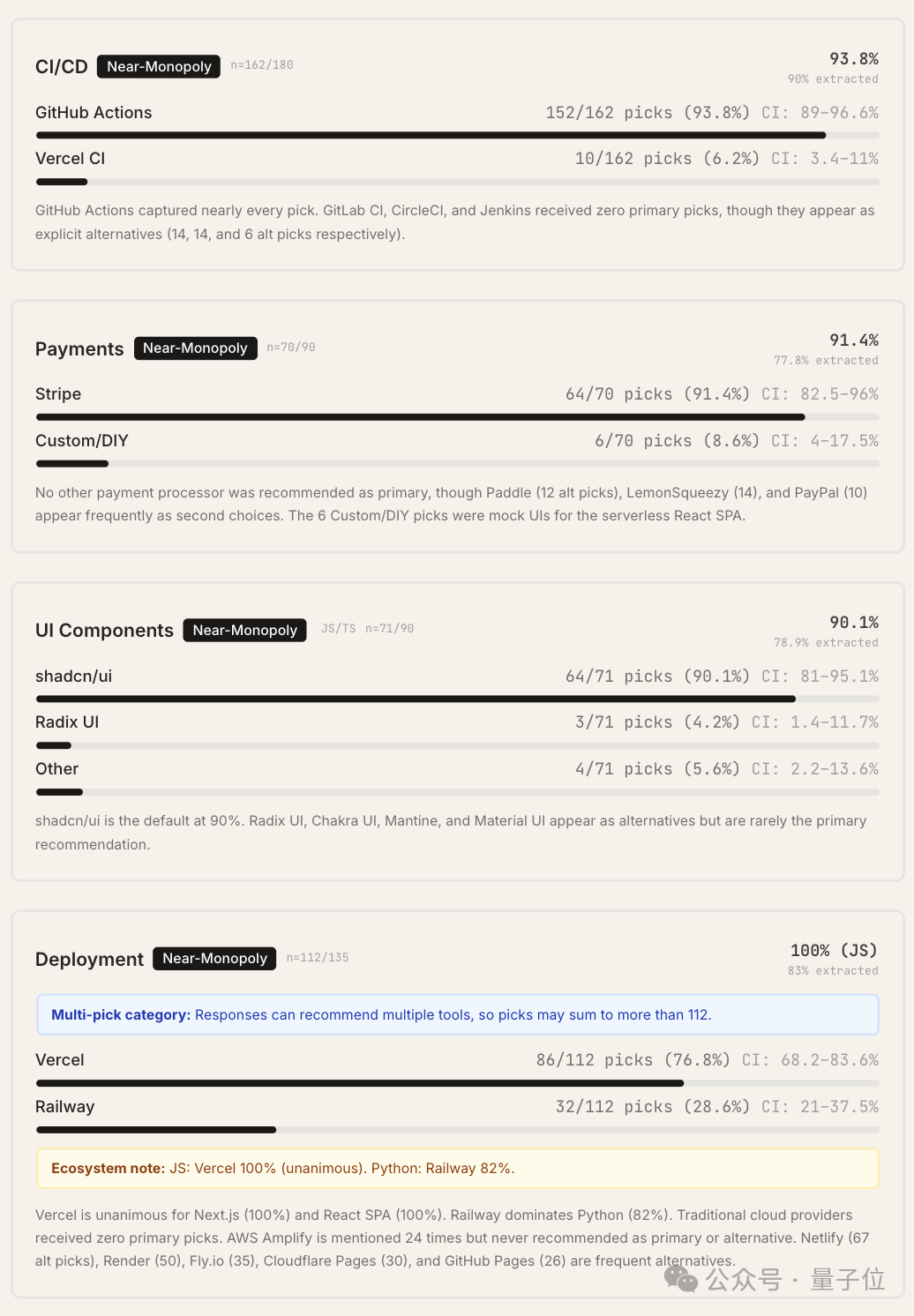
另有8个类别中,出现了首选率在50%–75%之间的“强力默认”工具,例如 Tailwind CSS(样式)、Zustand(状态管理)、Sentry(可观测性)、Resend(邮件)、Vitest(测试)、PostgreSQL(数据库)、pnpm(包管理器)和 React Hook Form(表单验证)。
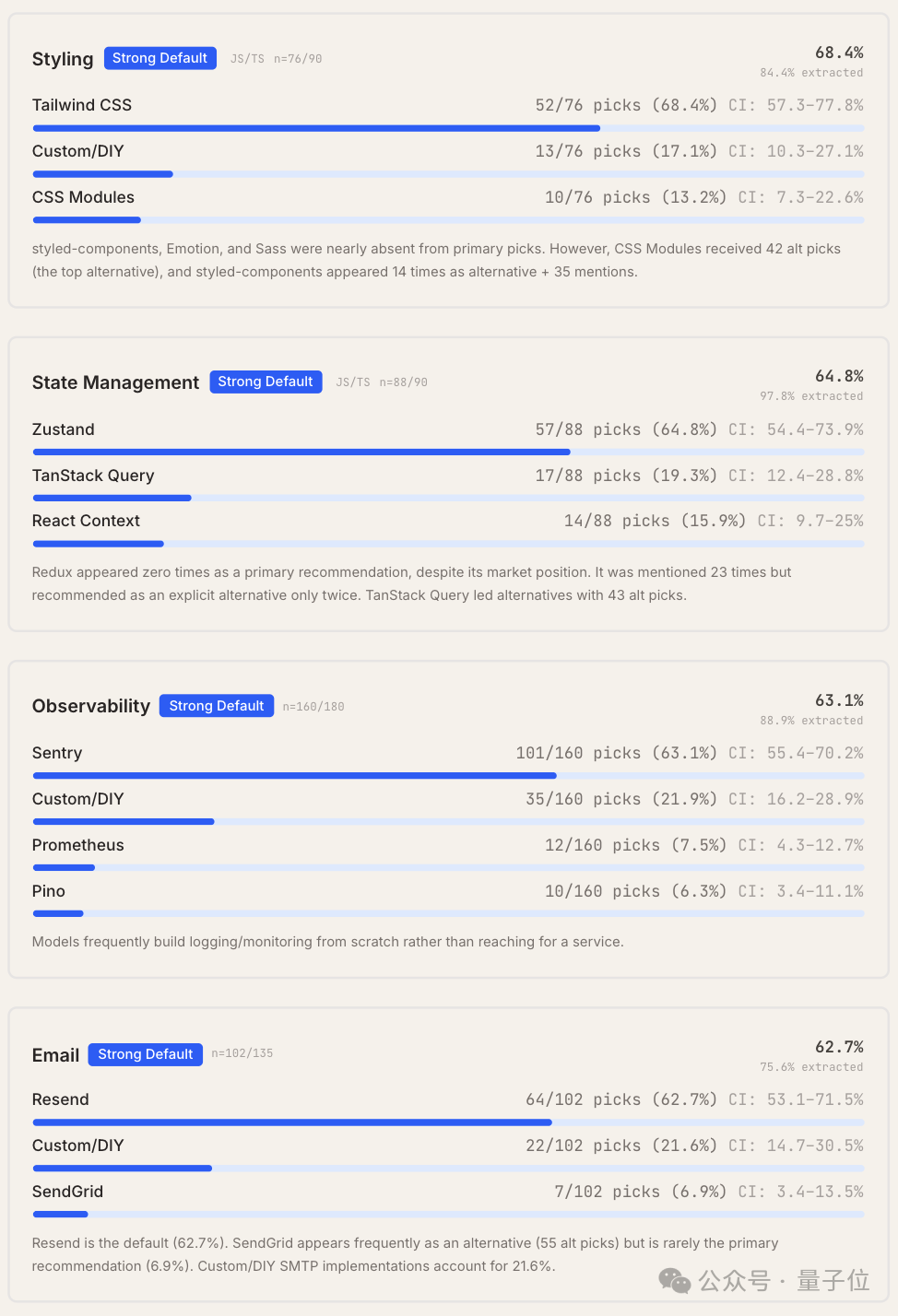
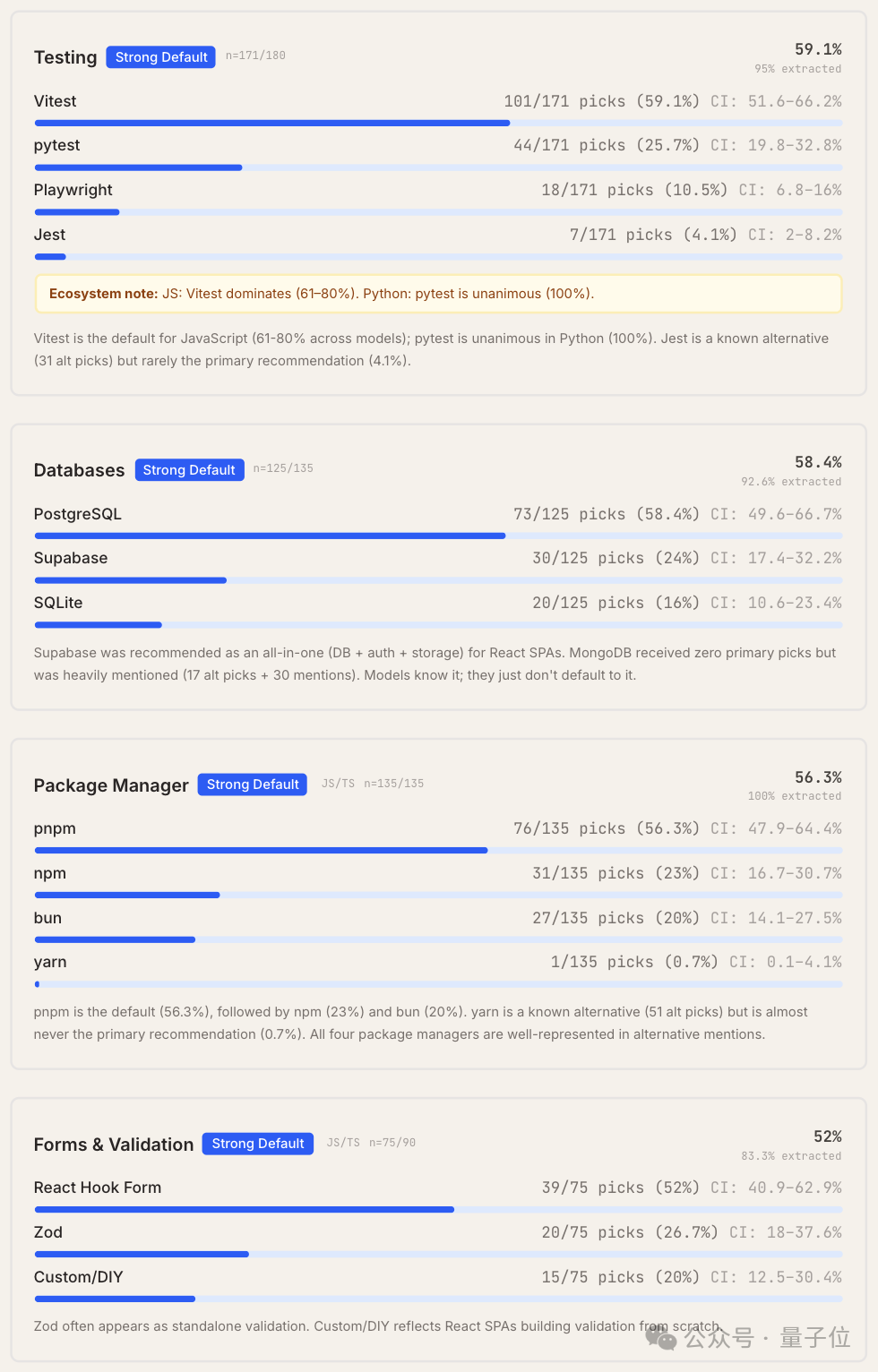
剩余8个类别未出现绝对主导工具,所有工具的首选率均低于50%,呈现出竞争性格局,例如认证、缓存、API层、文件存储、ORM/数据库工具、后台任务、功能标记和实时通信。
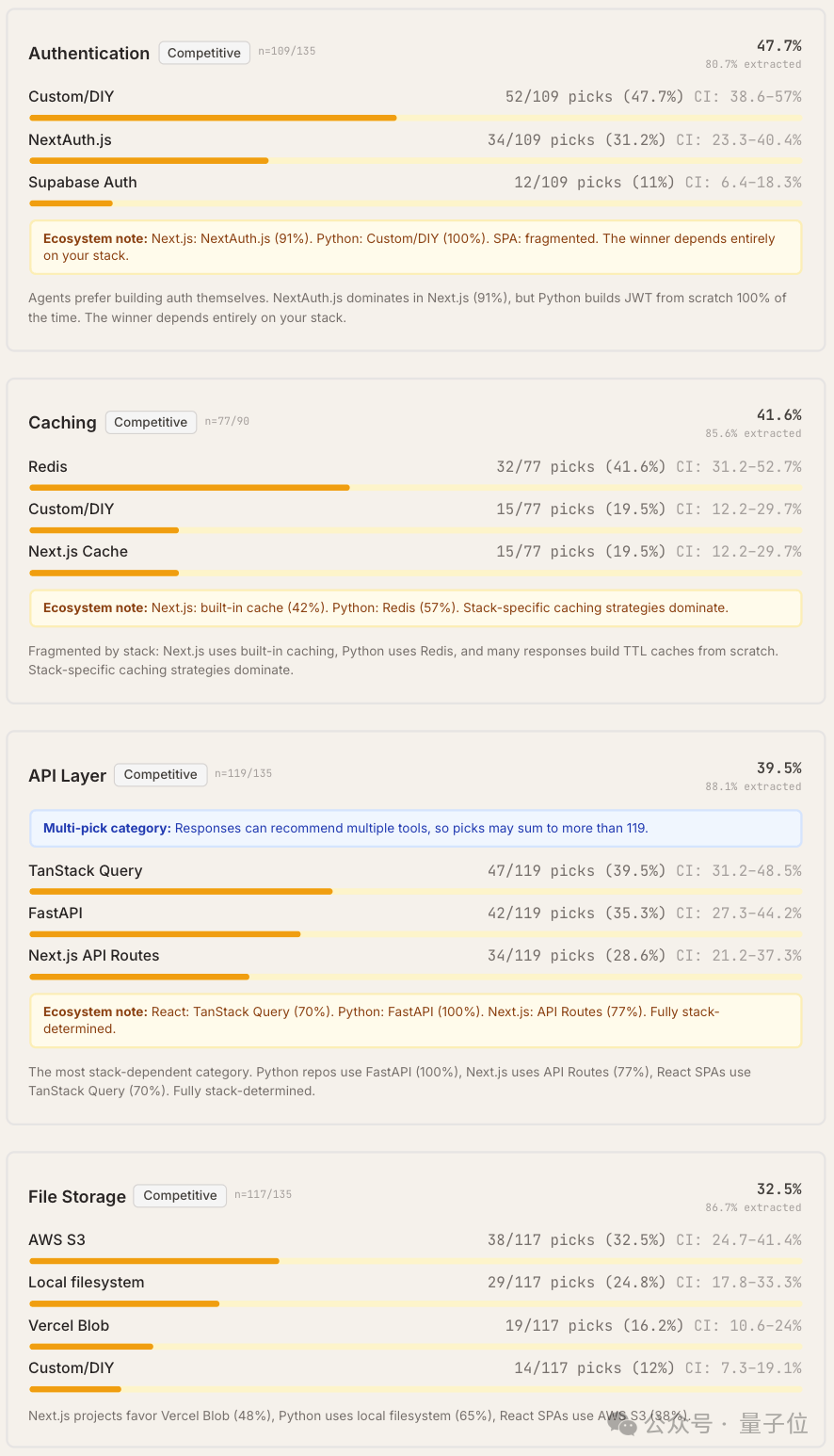
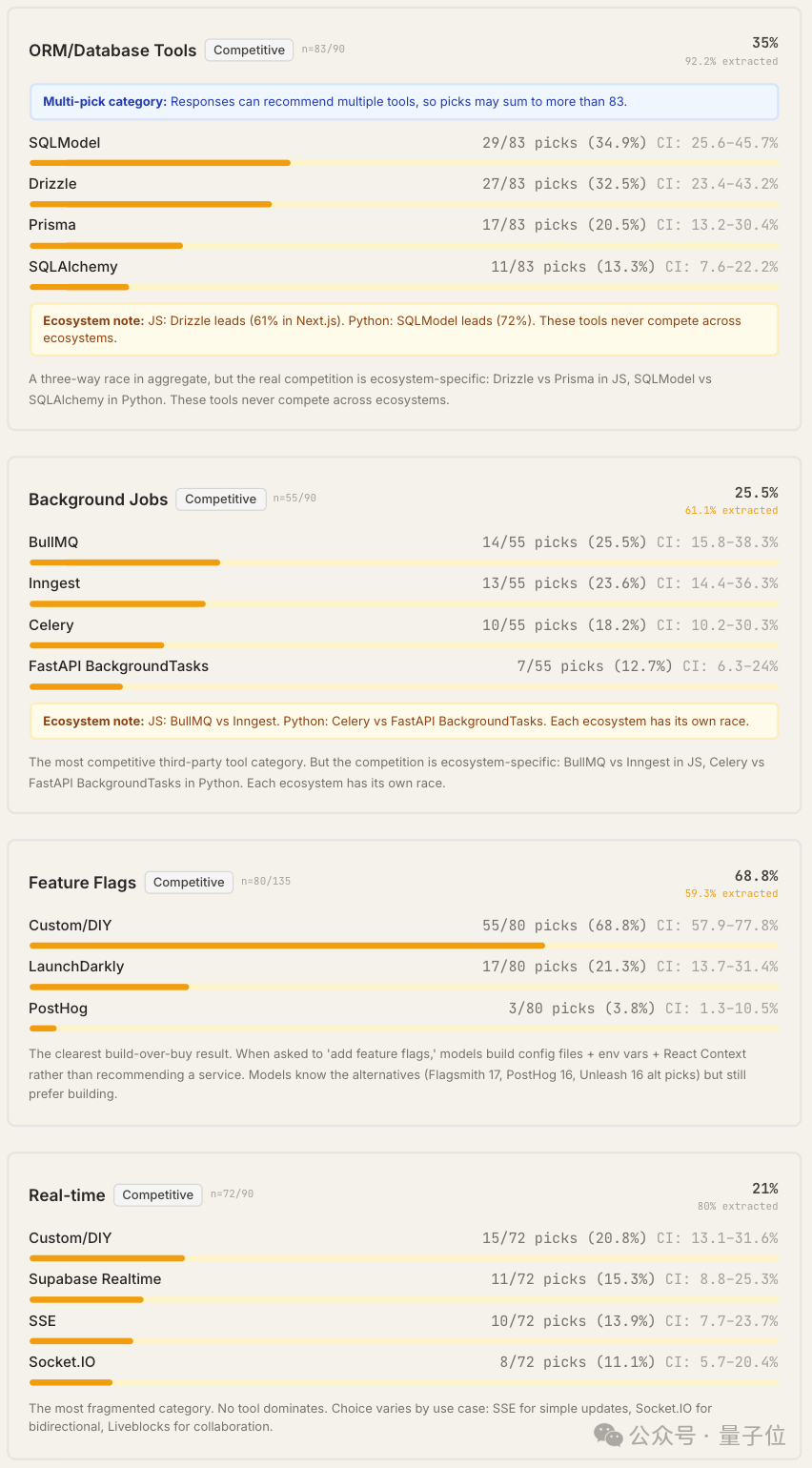
不同模型的选择有什么不同?
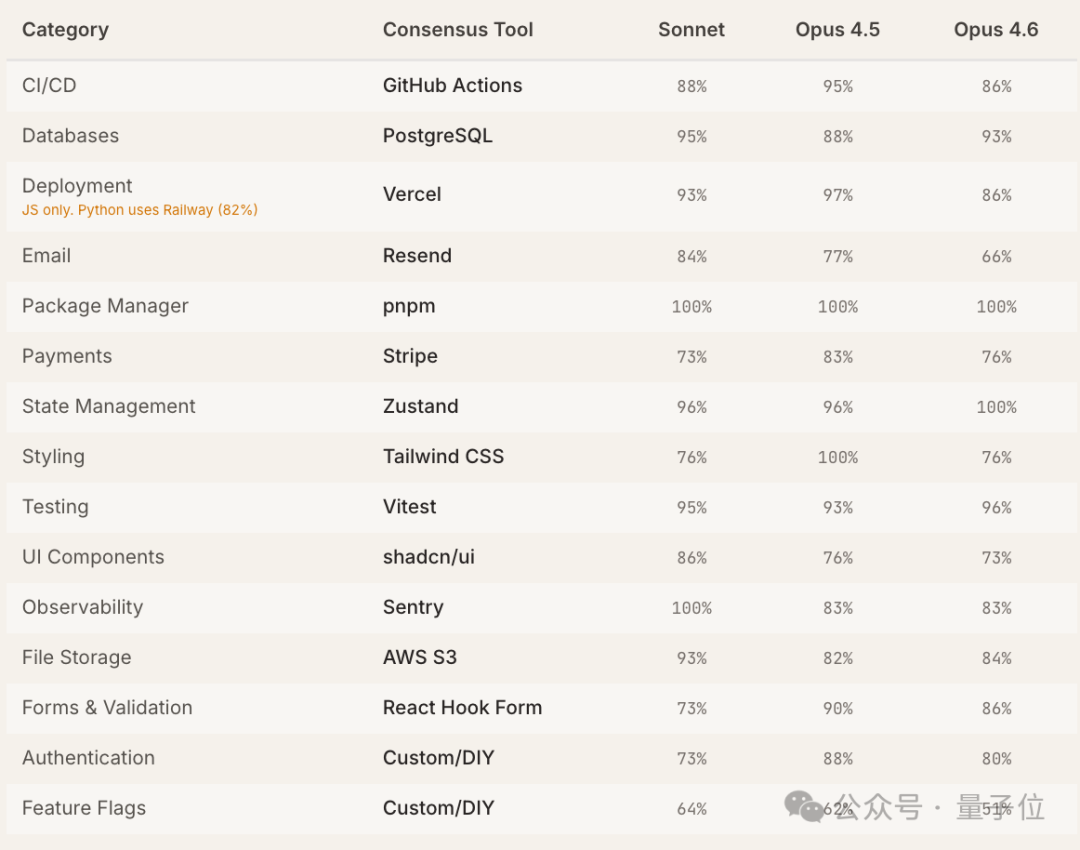
在20个工具类别中,三款模型对其中18个类别的首选工具判定完全一致,一致率达90%。这种高一致率符合预期,因为它们基于相似的基础训练数据。
真正具备研究价值的是模型间存在的分歧。这种差异很可能源于基于人类反馈的强化学习(RLHF)调优策略的不同,以及生成环节的专属微调差异。

从整体数据看,有5个类别的首选工具存在差异。但其中3个类别(如API层)的差异是因为混合了JavaScript和Python不同技术栈的结果,属于统计偏差。仅有缓存和实时通信两个类别,在不同模型之间存在真正的、跨技术生态的判断分歧。
有15个类别,三款模型的首选工具完全一致:
存在真实生态内偏好差异或跨编程语言判断分歧的5个类别如下:
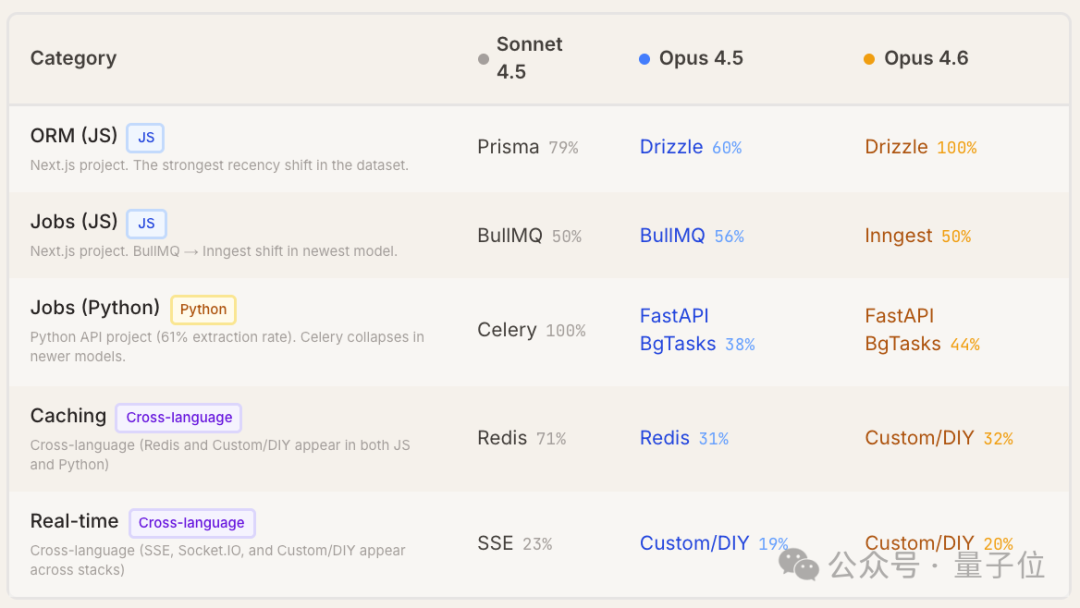
在同一技术生态下,仅缓存与实时功能2个类别,三款模型出现真实分歧:
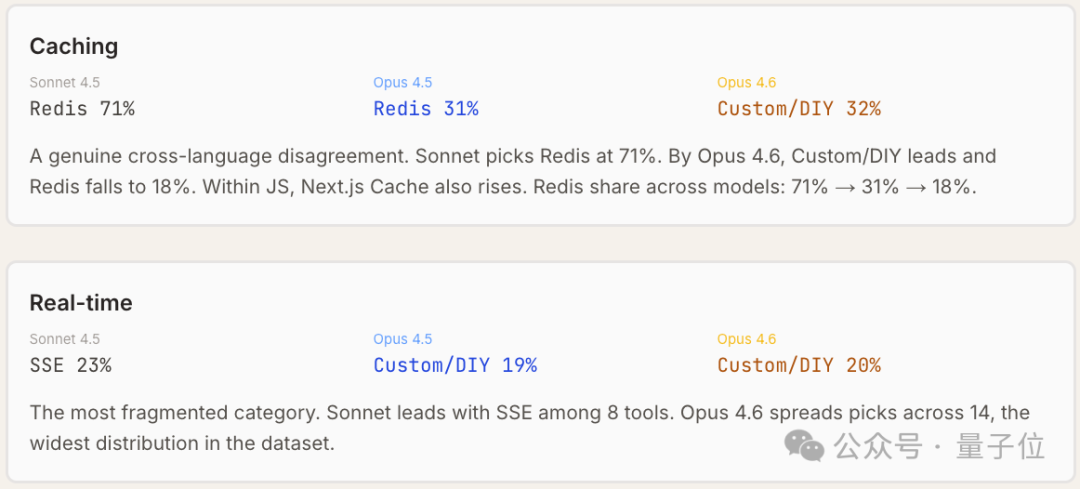
而API层的工具选择主要由开发框架本身决定(例如 Next.js 用 API Routes,Python 用 FastAPI),并非由模型驱动,因此在同一技术栈下三款模型的推荐结果是一致的。

值得注意的是,在同一技术生态内,更新版本的模型更倾向于选择更新的工具。例如在 JavaScript 项目中,ORM 的选择从 Sonnet 4.5 倾向的 Prisma,转向了 Opus 4.6 强烈推荐的 Drizzle。
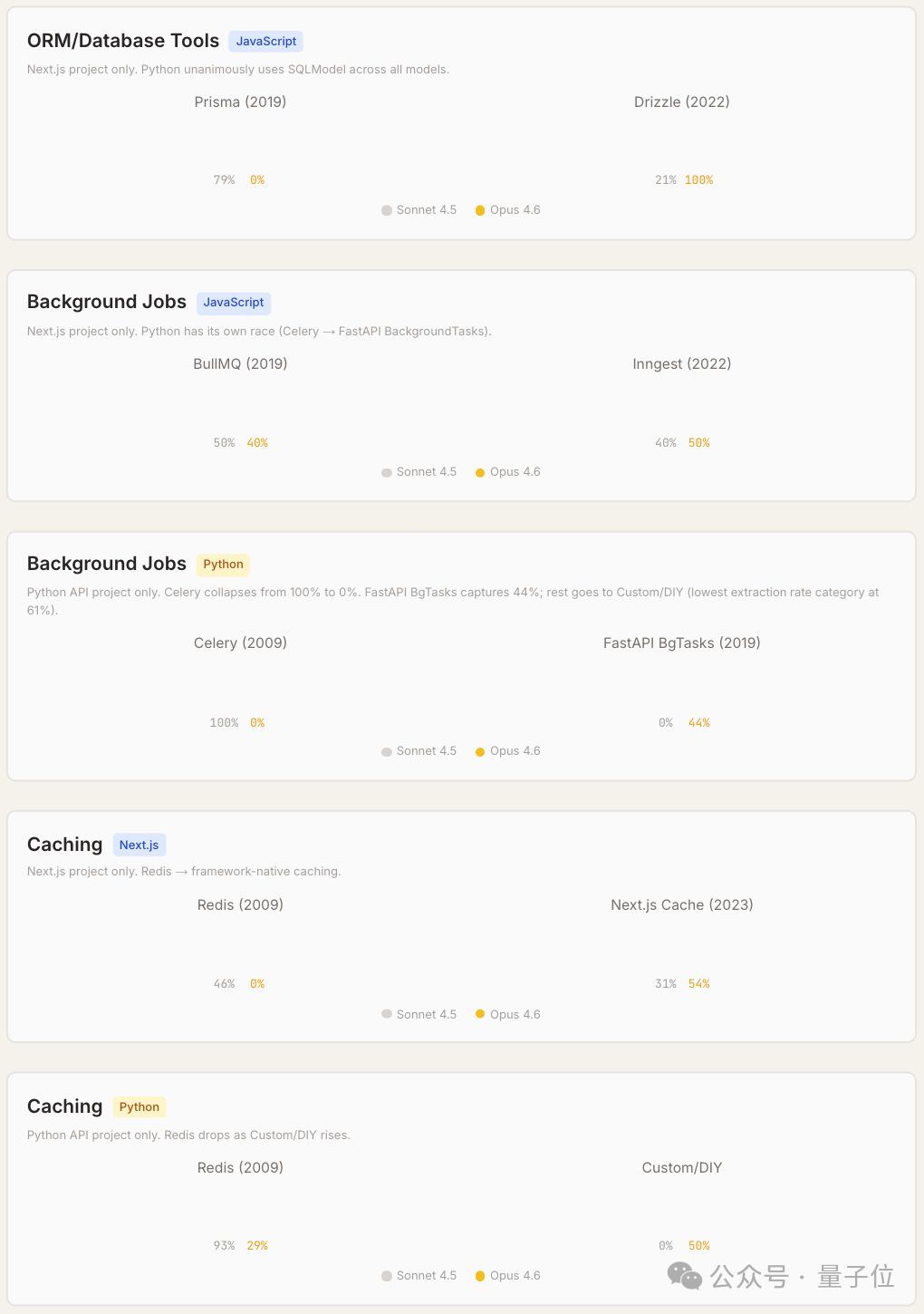
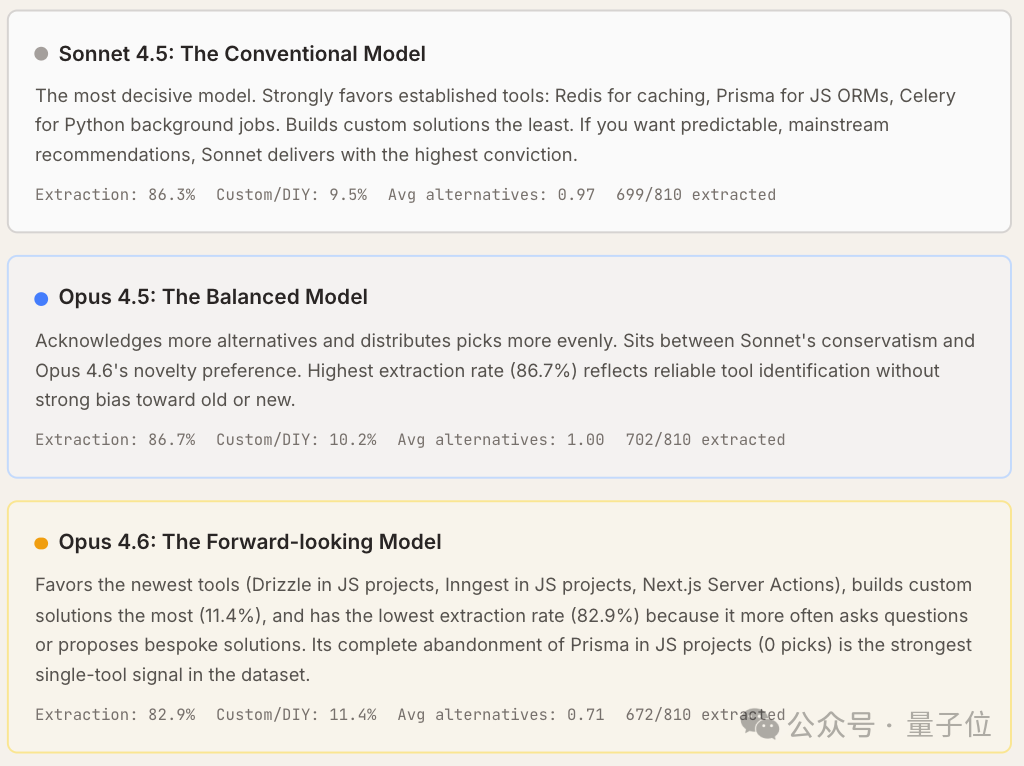
研究还总结了三款模型(Sonnet 4.5、Opus 4.5、Opus 4.6)的工具推荐“风格”画像:
- Sonnet 4.5:决策最果断,风格最保守,强烈偏好成熟、主流的工具。
- Opus 4.5:介于保守与求新之间,会考虑更多备选方案,推荐分布更均匀。
- Opus 4.6:最青睐最新、前沿的工具,同时最倾向于推荐自定义/DIY方案。
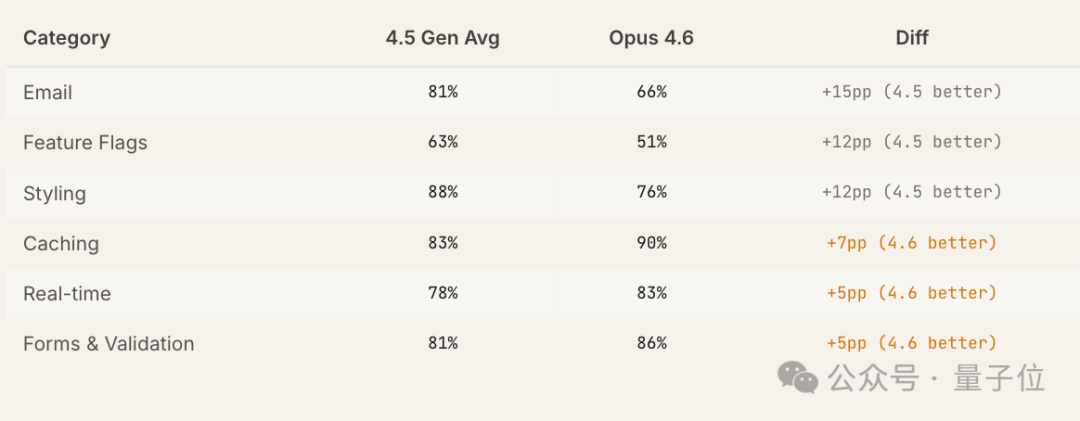
对比4.5代模型(Sonnet 4.5与Opus 4.5平均值)与Opus 4.6在工具推荐上的系统性差异,核心结论是:Opus 4.6 更倾向推荐新工具与自定义方案,而4.5代模型更偏好成熟稳定的工具。
更多结论:稳定性与场景依赖性显著
研究团队还测试了指令措辞变化对推荐结果的影响。针对每个工具类别,使用了5种不同措辞进行提问。结果显示,API Layer、身份认证、CI/CD、数据库、部署、支付等类别稳定性最高(100%),即使更换指令措辞,模型仍会推荐同一工具。
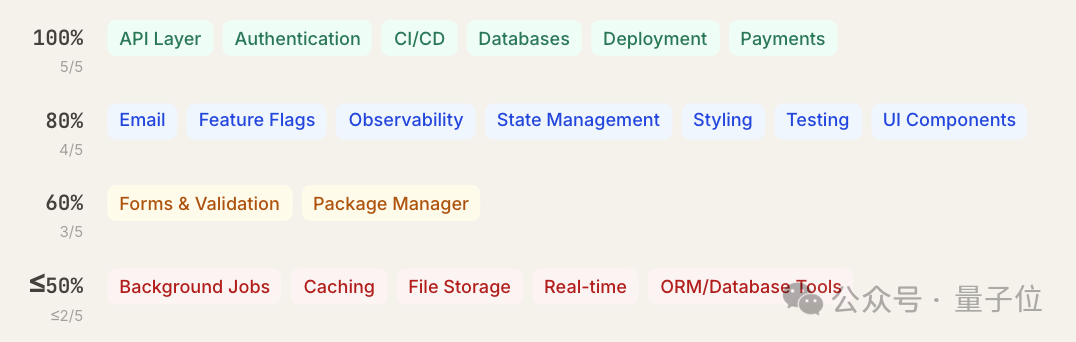
在严格控制变量(同一模型、同一提示词、同一代码仓库)的条件下,三款模型各自3次独立运行的推荐结果也表现出较高的一致性。例如在包管理器、CI/CD、状态管理、测试、支付等类别,3次推荐完全一致的比例高达87%–93%。
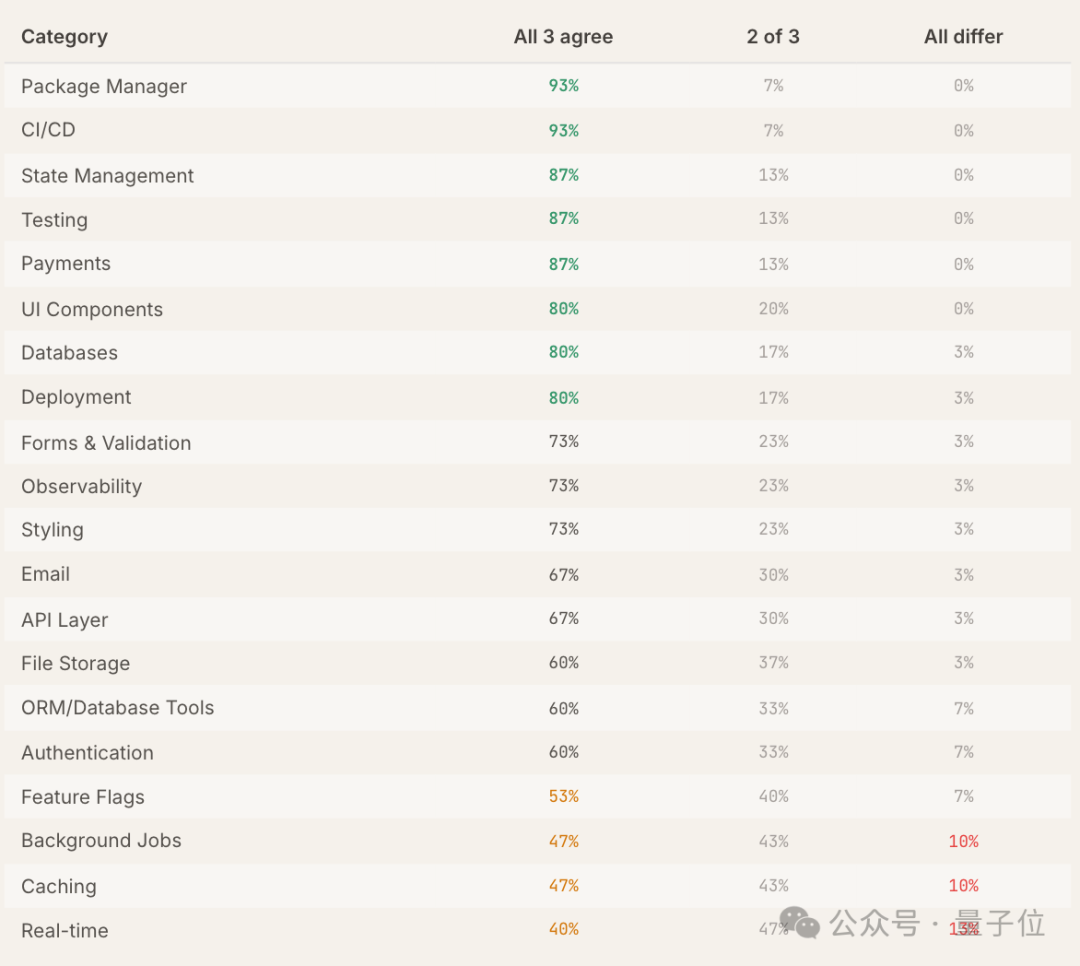
团队进一步分析了模型在不同代码仓库中的工具推荐一致性,发现工具推荐可分为两类:
- 通用型工具:如 GitHub Actions(CI/CD)、Sentry(可观测性),其推荐不受项目类型影响。
- 技术栈专属工具:如部署(Vercel vs Railway)、ORM(Drizzle vs SQLModel),其推荐结果高度依赖项目的技术栈。
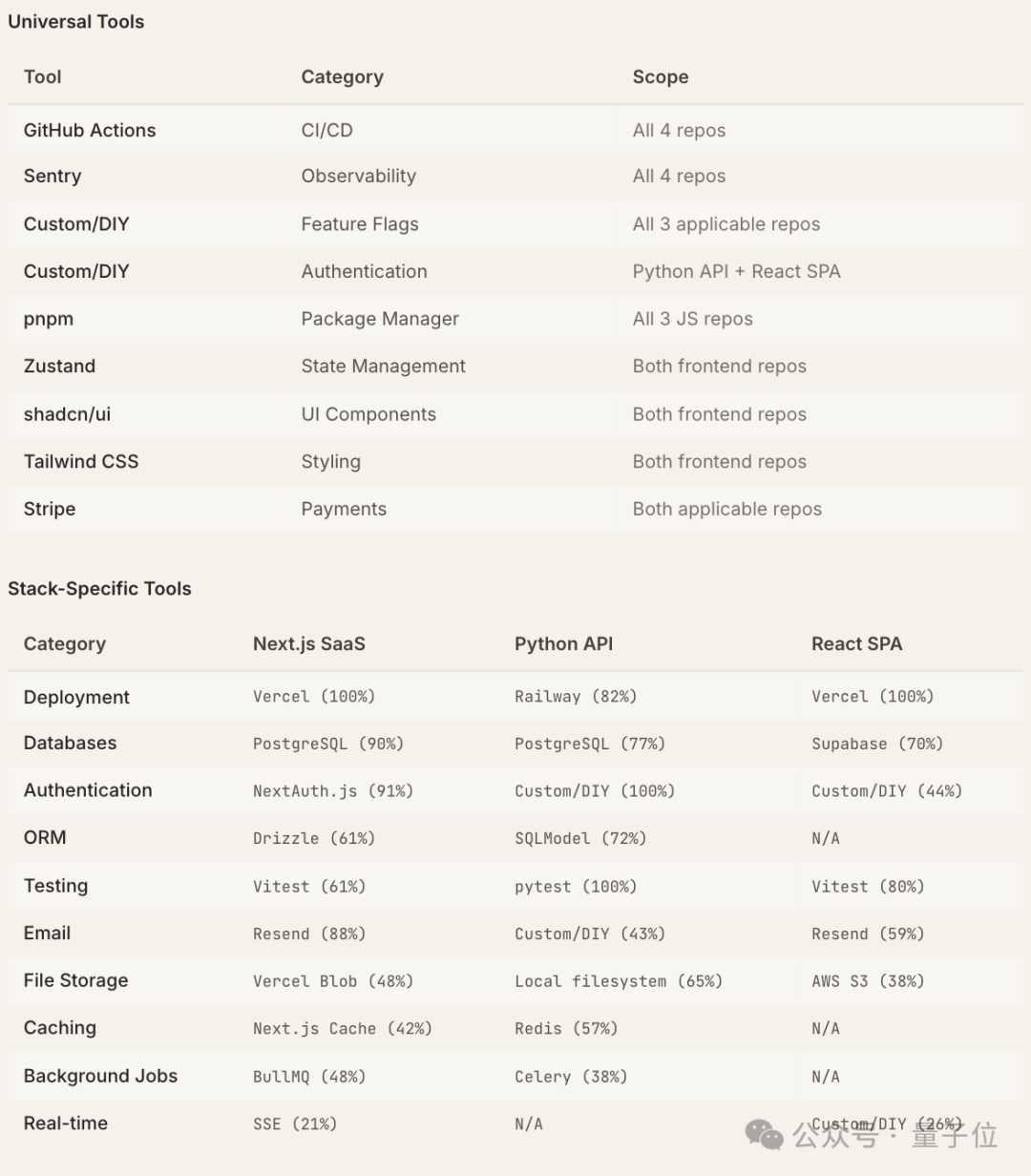
这最终指向一个核心发现:Claude Code 的工具推荐高度依赖具体的项目上下文。例如,同一个模型在 Next.js 项目中会推荐 Drizzle 作为 ORM 工具,而在 Python 项目中则会选择 SQLModel。
总结与启示
这项研究揭示了 AI 代码助手在技术选型上的鲜明倾向。对于开发者而言,了解这些偏好有助于更高效地利用 AI 助手,例如在构建 前端 或 后端 项目时,可以预期 Claude Code 可能会推荐哪些“默认”工具。同时,其“乐于自建”的特性也提醒我们,需要在自定义方案的灵活性与成熟第三方工具的稳定性之间做出权衡。
对于工具厂商和 AI 研发团队,这项研究则提供了量化模型行为、观察技术生态演变的独特视角。Claude Code 正在塑造一套由 人工智能 辅助开发模式下的新兴“默认技术栈”,这或许将深远影响未来开发工具的竞争格局。
官方研究报告:https://amplifying.ai/research/claude-code-picks/report
 发表于 2026-2-28 07:51:12
|
查看: 196|
回复: 0
发表于 2026-2-28 07:51:12
|
查看: 196|
回复: 0
