本文旨在梳理在分库分表架构实施过程中,会接触到的通用核心概念。理解这些术语,有助于我们理解市面上各类分库分表工具的实现思路。
我们以一个具体的业务场景为例:假设订单表 t_order 数据量已达亿级,查询性能严重下降。为此,我们进行分库分表优化,将原单库拆分为 DB_1 和 DB_2 两个库,并在每个库中继续拆分为 t_order_1 和 t_order_2 两张表。
数据分片
通常讨论分库分表时,主要指水平切分模式(水平分库、分表)。数据分片将一张数据量庞大的表(如 t_order)拆分成若干个表结构完全一致的小表(即拆分表),例如 t_order_0, t_order_1, ..., t_order_n,每张表只存储原表中的一部分数据。
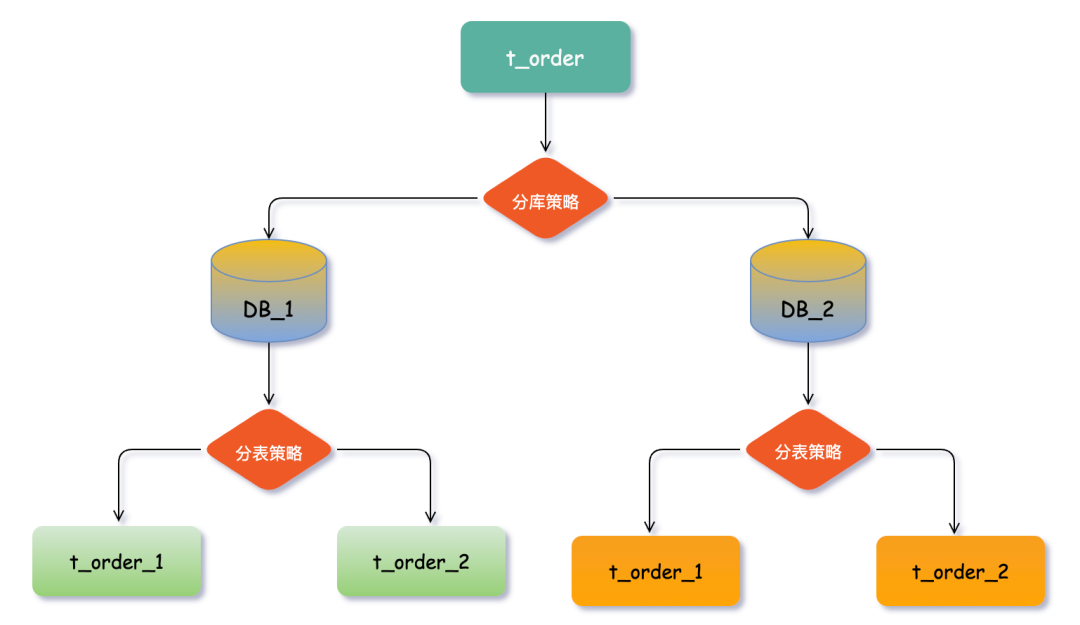
数据节点
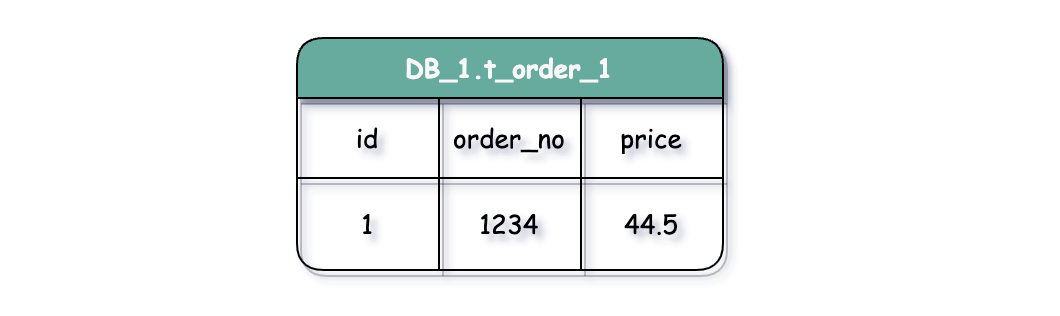
数据节点是分片后不可再分的最小数据单元(表),它由数据源名称和真实表名组成。例如,DB_1.t_order_1 和 DB_2.t_order_2 都各表示一个数据节点。
逻辑表
逻辑表是一组具有相同表结构的水平拆分表在逻辑上的总称。
例如,我们将订单表 t_order 拆分为 t_order_0 到 t_order_9 共10张表。此时物理数据库中已不存在 t_order 表。为了让业务代码无感知,我们在编写SQL时依然使用 t_order 这个表名,分片中间件会在执行前将其解析为真实的物理表。这里的 t_order 就是逻辑表。
业务逻辑SQL:
select * from t_order where order_no='A11111'
真实执行SQL:
select * from DB_1.t_order_n where order_no='A11111'
真实表
真实表即数据库中实际存在的物理表,例如 DB_1.t_order_n。
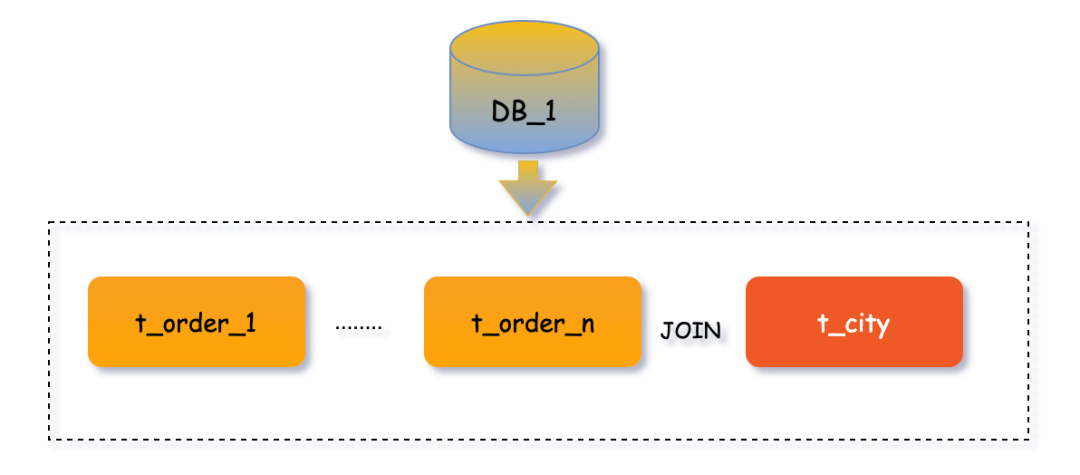
广播表
广播表是一类特殊的表,其表结构和数据在所有分片数据源中完全一致。它通常用于数据量小、更新频率低的字典表或配置表。由于数据全节点同步,可以极大避免跨库JOIN查询。
广播表的特点:
- 写操作同步:对广播表的插入、更新、删除会实时在所有分片数据源中执行,以保证一致性。
- 读操作任意:查询广播表时,只需在任意一个分片数据源中执行一次即可。
- JOIN无限制:可以与任何其他表进行JOIN操作,因为所有节点数据一致。
应用场景示例:
在订单管理系统中,常需按地区统计订单,这涉及省份地区表 t_city 与订单表 t_order_n 的JOIN查询。将 t_city 设计为广播表,可以彻底避免跨库JOIN。
注意:修改广播表(如UPDATE)会在所有分片数据源上执行。如果有1000个分片,就会产生1000次SQL。因此,应尽量避免在业务高峰期或高并发场景下修改广播表。
单表
单表指在所有的分片数据源中仅唯一存在的表(即未进行分片的表)。它适用于数据量不大、无需分片且没有与其他拆分表关联查询需求的表。单表通常存储在默认的数据源中。
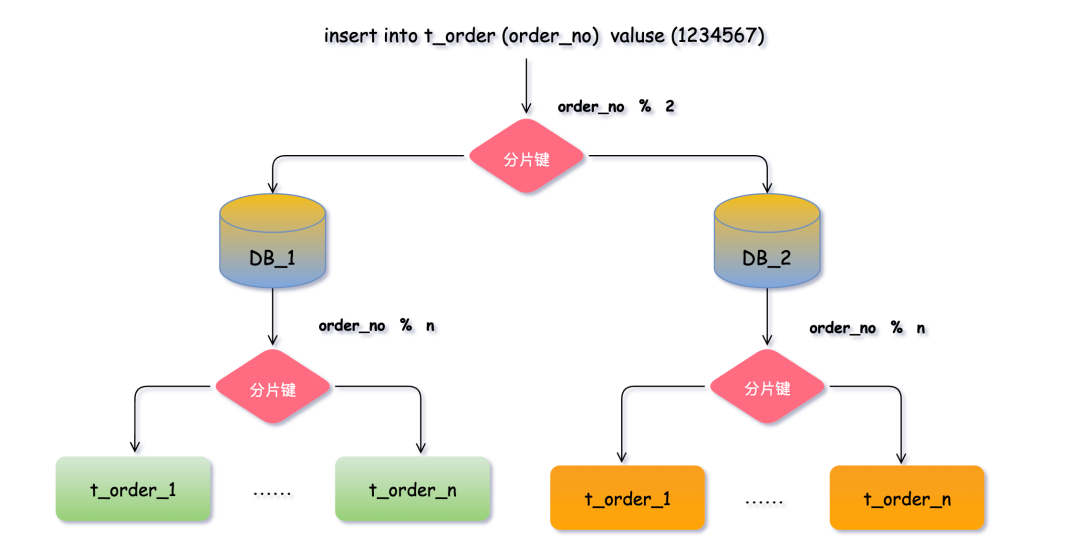
分片键
分片键是用于决定数据路由到哪个数据节点的关键字段。它的选择至关重要。
以 t_order 表为例,当我们执行一条插入订单的SQL时,中间件需要根据SQL中分片键的值进行计算。假设选择 order_no(订单号)作为分片键,通过取模运算(如 order_no % 2)来决定数据应该写入 DB_1 还是 DB_2。进一步,在库内分表时,再用另一套规则(如 order_no % n)决定写入哪张具体的表。
在这个过程中,order_no 就是分片键。选择合适的分片键是分库分表设计成功的关键。
分片策略
分片策略定义了使用哪种分片算法、基于哪个(些)字段以及如何将数据分配到不同的节点。它由分片算法和分片键组合而成,一个策略中可以组合多种算法,对多个分片键进行运算。
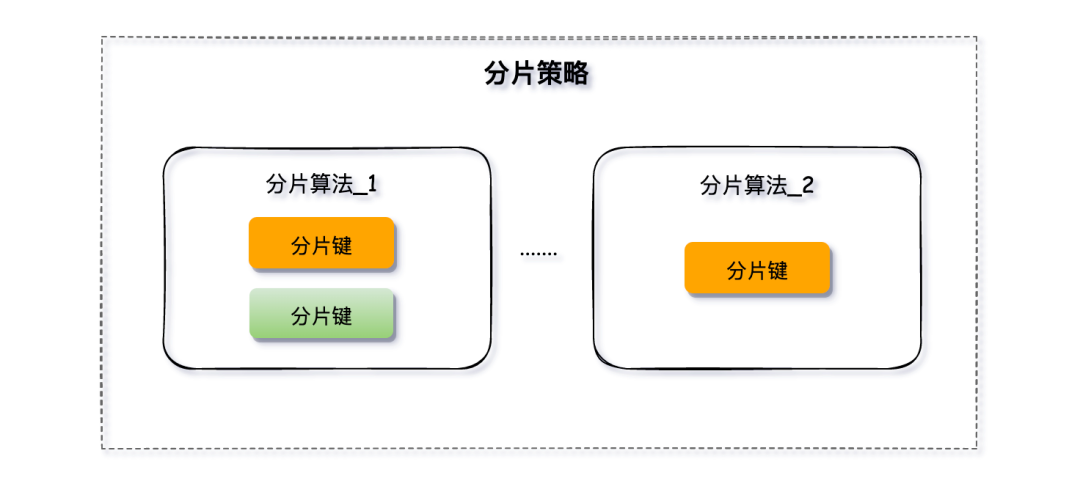
分库和分表的分片策略配置是独立的,可以分别使用不同的策略与算法。
分片算法
分片算法是用于对分片键的值进行运算,从而将数据映射到具体数据节点的规则。
常见的分片算法有:
- 哈希分片:根据分片键的哈希值分配数据。例如,按用户ID哈希,可将同一用户的数据分到同一节点。
- 范围分片:按分片键值的区间分配。例如,按订单创建时间或用户所属地区分片。
- 取模分片:对分片键值取模,根据余数分配。例如,
order_no % 2。
- ...其他定制化算法。
绑定表
绑定表是指分片规则完全相同的一组表。由于分片规则一致,相关联的数据必然会落入相同的数据库和表中,从而在JOIN查询时能有效避免跨库操作。
例如,t_order(订单表)和 t_order_item(订单明细表)都使用 order_no 字段作为分片键,且按相同规则分片,那么这两张表就是绑定表关系。
使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则仍会产生笛卡尔积查询或跨库查询,影响性能。
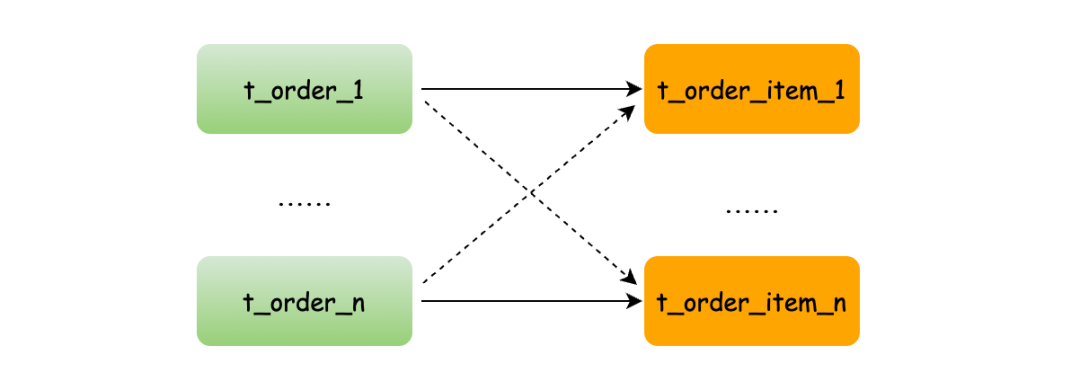
未配置绑定表时的查询:
逻辑SQL:
SELECT * FROM t_order o JOIN t_order_item i ON o.order_no=i.order_no
会产生4条真实SQL(笛卡尔积):
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_no=i.order_no
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_no=i.order_no
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_no=i.order_no
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_no=i.order_no
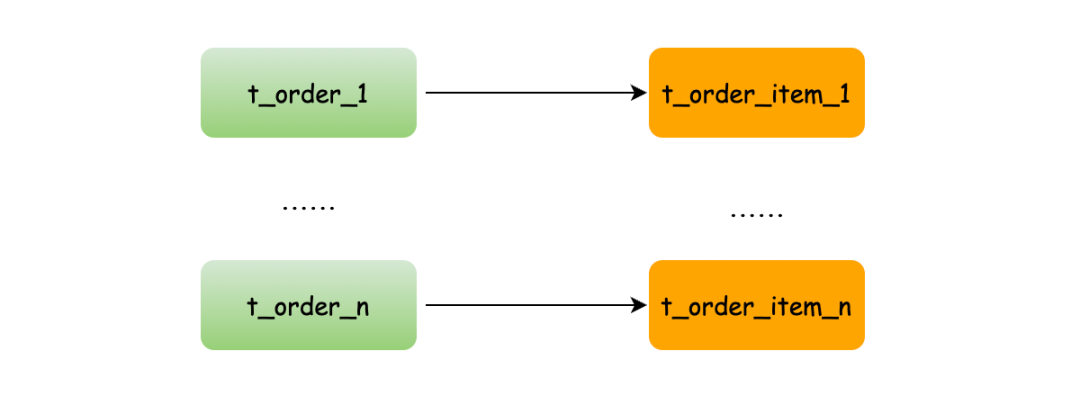
配置绑定表后的查询:
由于数据分片位置一致,只需在对应的分片内关联即可,只产生2条SQL:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_no=i.order_no
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_no=i.order_no
注意:在关联查询中,以t_order为主表。路由计算仅使用主表的策略,t_order_item表的分片计算也会使用t_order的条件。因此,绑定表之间的分片键必须完全相同。
SQL 解析
在分库分表架构下,应用执行一条SQL通常经过六个步骤:SQL 解析 -> 执⾏器优化 -> SQL 路由 -> SQL 改写 -> SQL 执⾏ -> 结果归并。
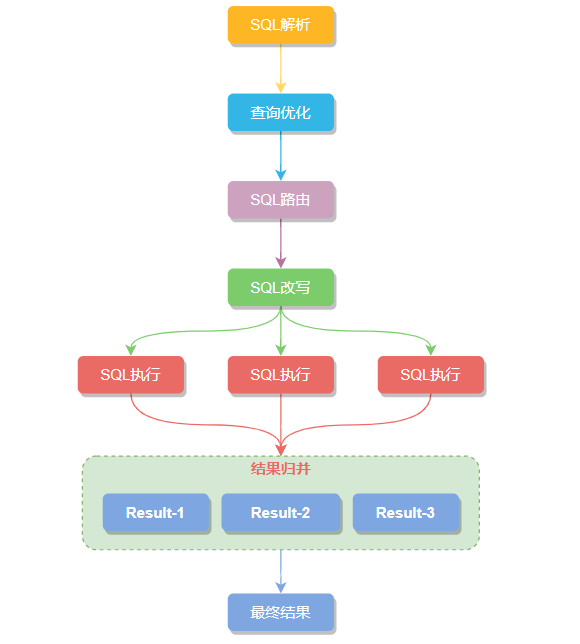
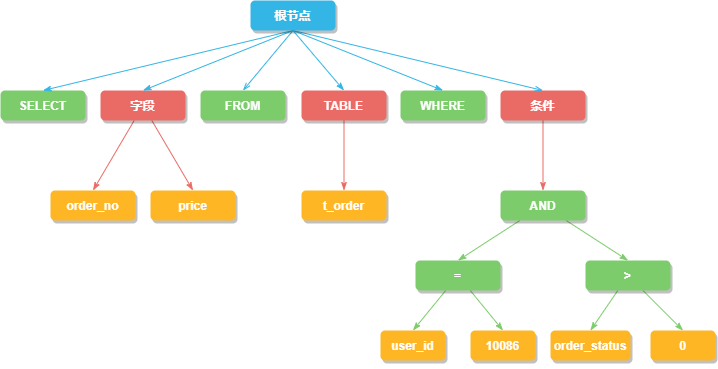
SQL解析分为词法解析和语法解析。以查询SQL为例:
SELECT order_no FROM t_order where order_status > 0 and user_id = 10086
词法解析将其拆分为不可再分的原子单元(如SELECT, order_no, FROM等)。语法解析则将这些单元转换为抽象语法树(AST),并从中提炼出分片所需的上下文信息,如查询字段、表、条件、排序、分组、分页等,同时标记出SQL中可能需要改写的位置。
执⾏器优化
执行器优化会依据查询特点和统计信息,选择最优的查询计划。例如,如果 user_id 字段有索引,优化器可能会调整查询条件的顺序,将等值条件前置,以提高查询效率。
优化后的SQL可能变为:
SELECT order_no FROM t_order where user_id = 10086 and order_status > 0
SQL 路由
基于SQL解析得到的分片上下文,并匹配用户配置的分片策略和算法,计算出SQL应该在哪一个(或哪几个)数据节点上执行。SQL路由根据是否包含分片键,分为 分片路由 和 广播路由。
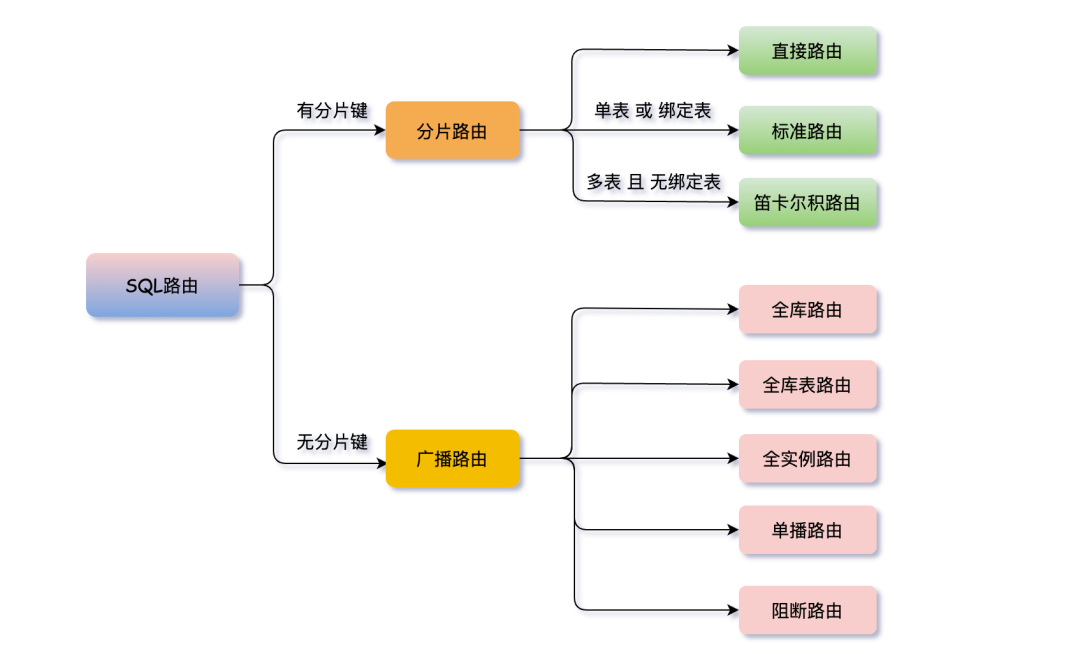
分片路由
指SQL中包含分片键的路由,又分为三种类型:
- 标准路由:最常用的方式,适用于不包含关联查询或仅包含绑定表关联的SQL。当分片键使用
= 运算符时,路由到单一节点;使用 BETWEEN 或 IN 时,可能路由到多个节点,一条逻辑SQL可能被拆分为多条真实SQL。
-- 逻辑SQL
SELECT * FROM t_order where t_order_id in (1,2)
-- 路由后可能变为
SELECT * FROM t_order_0 where t_order_id in (1,2)
SELECT * FROM t_order_1 where t_order_id in (1,2)
- 直接路由:直接指定SQL到某个具体的库、表执行。可用于分片键不在SQL中的场景,支持子查询、自定义函数等复杂SQL。
- 笛卡尔积路由:由非绑定表之间的关联查询产生。当关联表的分片键不同或规则不一致时,会产生笛卡尔积组合查询,性能低下,应尽量避免。
-- 假设t_order和t_user分片键不同,联表查询会产生多条SQL
SELECT * FROM t_order_0 t LEFT JOIN t_user_0 u ON u.user_id = t.user_id WHERE t.user_id = 1
SELECT * FROM t_order_0 t LEFT JOIN t_user_1 u ON u.user_id = t.user_id WHERE t.user_id = 1
-- ... 以此类推
广播路由
指SQL中不包含分片键的路由,分为五种类型:
- 全库表路由:针对所有分片中的表执行。例如,对逻辑表
t_order 的DQL/DML操作,会在所有真实表 t_order_0 ... t_order_n 上执行。
- 全库路由:针对数据库层面的操作,如
SET autocommit=0; 这类事务控制语句,会在所有真实库中执行。
- 全实例路由:针对数据库实例的DCL操作,如创建用户
CREATE USER order@127.0.0.1,会在所有实例上执行。
- 单播路由:获取某个真实表的信息,如
DESCRIBE t_order;。由于所有真实表结构相同,只需在任意一个表上执行一次。
- 阻断路由:屏蔽掉某些对数据库的操作,例如
USE order_db;。因为ShardingSphere采用逻辑Schema方式,无需切换物理数据库。
SQL 改写
将基于逻辑表编写的SQL,改写成能在真实数据库节点上正确执行的语句。主要是替换逻辑表名为真实表名。
例如:
逻辑SQL:
SELECT * FROM t_order
改写为真实SQL:
SELECT * FROM t_order_n
SQL 执⾏
将经过路由和改写的真实SQL安全、高效地发送到底层数据源执行。此过程会通过连接池等技术平衡资源控制与执行效率,而非简单地将SQL通过JDBC直接发送。
结果归并
将从各个数据节点返回的多个结果集,合并成一个完整的结果集返回给客户端。SQL中的排序、分组、分页和聚合等操作,都是在归并后的总结果集上进行的。
分布式主键
数据分片后,多个真实表(t_order_n)各自独立生成自增ID,必然会导致主键冲突,失去全局唯一性。
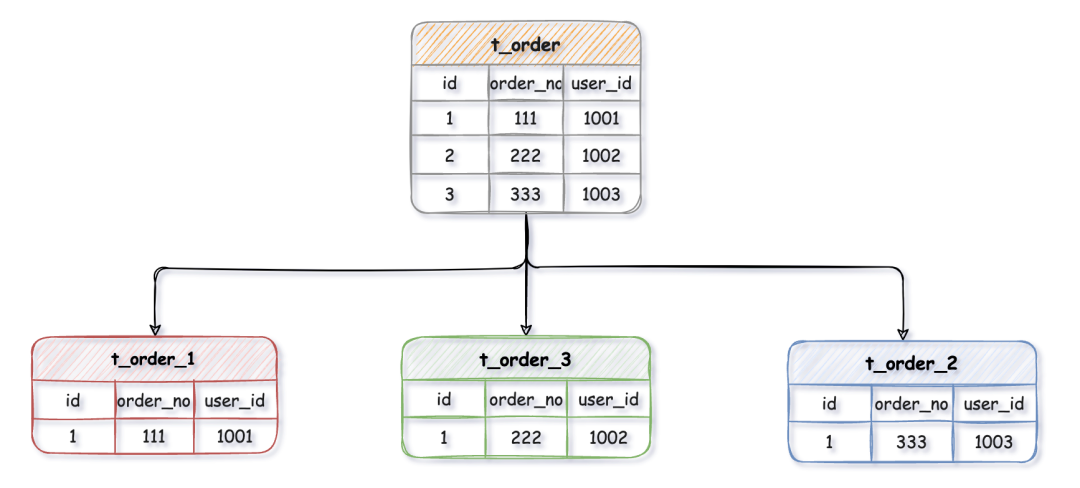
虽然可以通过设置不同表的自增初始值和步长来避免碰撞,但维护成本高,扩展性差。因此,需要一个全局唯一的ID生成器(发号器)来产生分布式ID。
数据脱敏
分库分表时,可以指定某些敏感字段(如手机号、身份证号)为脱敏列,并配置脱敏算法。在数据写入时,中间件会自动将字段值脱敏后再存储,以保护数据隐私。
分布式事务
分库分表使得事务的范畴从单个数据库扩展到了多个数据库,甚至多个服务,保证跨数据源操作的原子性成为巨大挑战。
以订单系统为例,创建订单可能涉及调用支付、库存、积分等多个服务,每个服务都有独立的数据库。
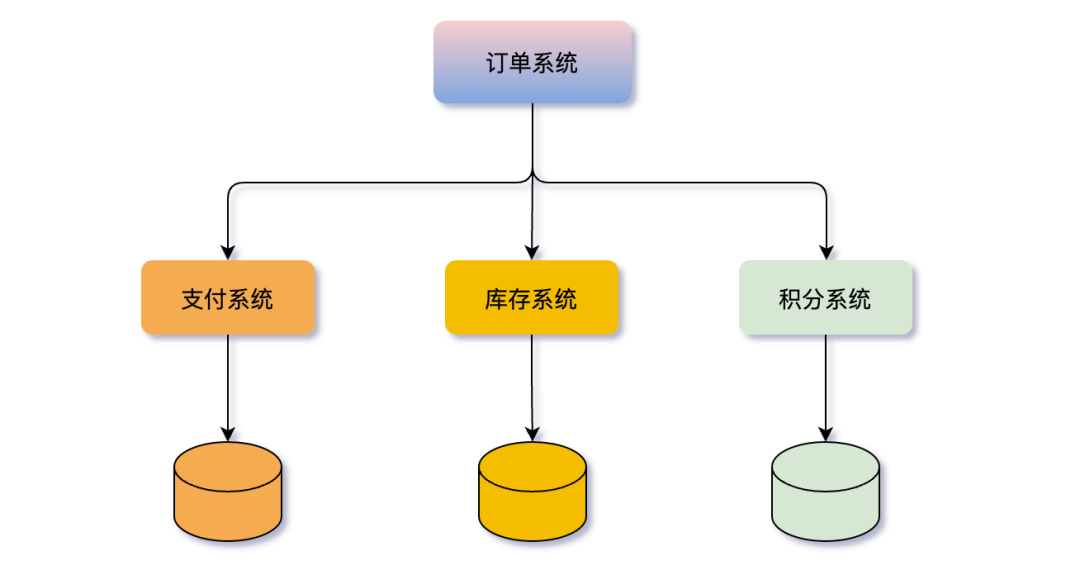
此时需要使用分布式事务解决方案,如强一致性的XA协议或柔性事务框架Seata。而分库分表后,订单服务自身也需要处理跨库事务,复杂度进一步增加。
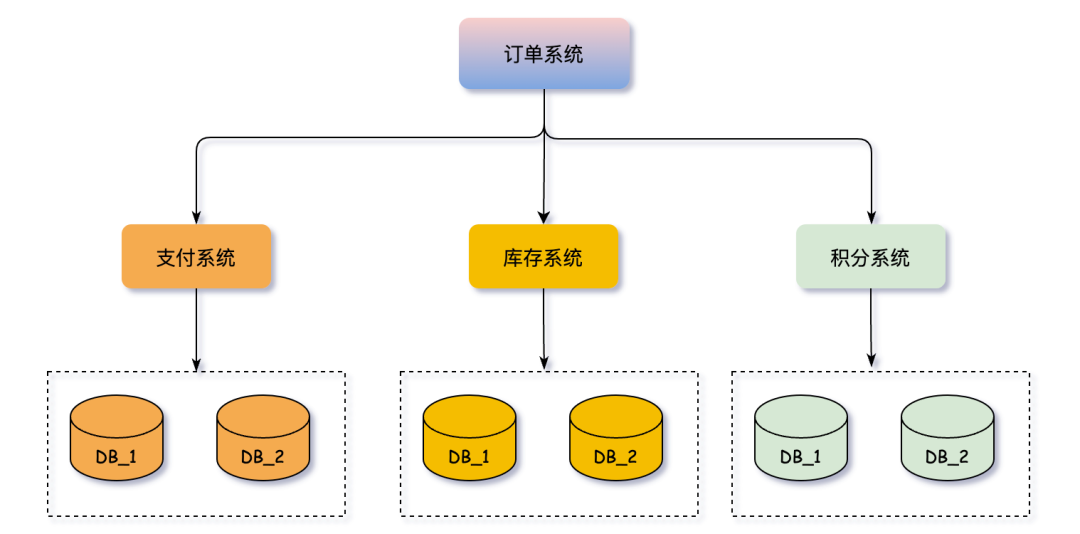
因此,不到万不得已,应尽量避免采用分库分表方案。
数据迁移
分库分表改造后,需要将历史数据从旧库迁移到新的分片集群中。这是一个复杂的过程,需考虑数据量、一致性、迁移速度和对业务的影响。
迁移主要针对两类数据:
- 存量数据:旧库中已有的历史数据,通常采用定时、分批迁移。
- 增量数据:迁移过程中及之后持续产生的新数据。可采用新、旧集群双写模式,待数据迁移完毕并验证一致后,再切换数据源。
影子库
影子库是一个与生产环境数据库结构完全相同的独立实例,用于在不影响线上业务的情况下,进行全链路压测、数据库变更验证等。
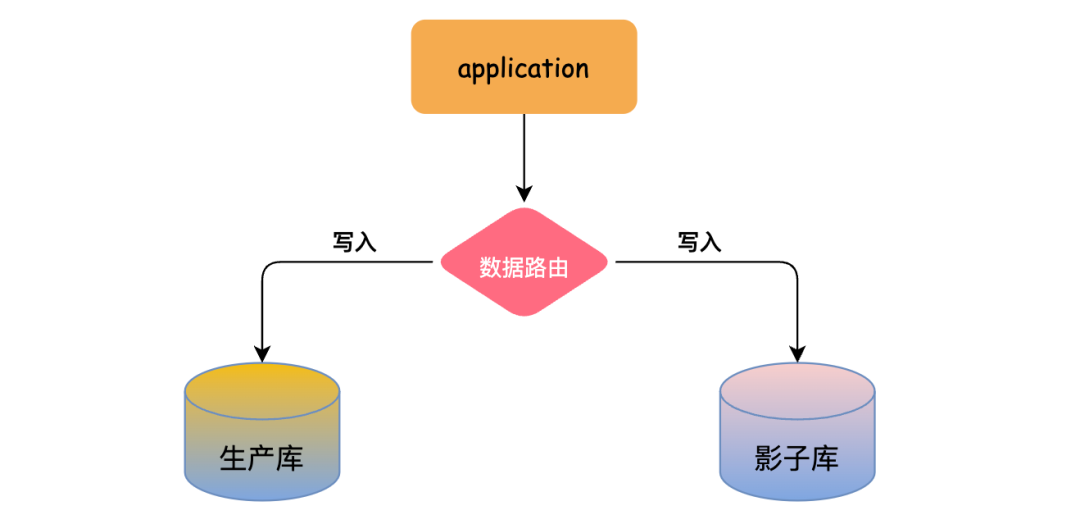
在生产环境进行压测或验证时,可以将部分流量(或测试流量)导入影子库,从而真实模拟生产环境的数据量和压力,因为测试环境的数据往往不可靠。
使用影子库需遵循以下原则:
- 结构与生产库完全一致。
- 数据与生产库保持同步(定期或实时)。
- 禁止在影子库执行影响生产的写操作(压测特定写场景除外)。
- 严格管控访问权限。
总结
本文系统性地介绍了分库分表架构中涉及的21个核心概念。掌握这些是进行后续深度实践的基础。在云栈社区的技术板块中,可以找到更多关于数据库架构的深度讨论。接下来,我们将进入更具体的实战环节,探讨读写分离、分布式事务等主题的具体实现。
 发表于 2026-3-1 02:30:07
|
查看: 163|
回复: 0
发表于 2026-3-1 02:30:07
|
查看: 163|
回复: 0
