我们以 “在线购物网站” 作为例子贯穿全文,帮助大家理解如何构建高性能、高可用的数据库集群。
1. MySQL 单节点部署模式的弊端
在“在线购物网站”早期发展阶段,我们通常采用单个MySQL数据库服务器来处理所有数据请求,这种单节点部署模式存在以下四个主要问题:
1.1 单点故障
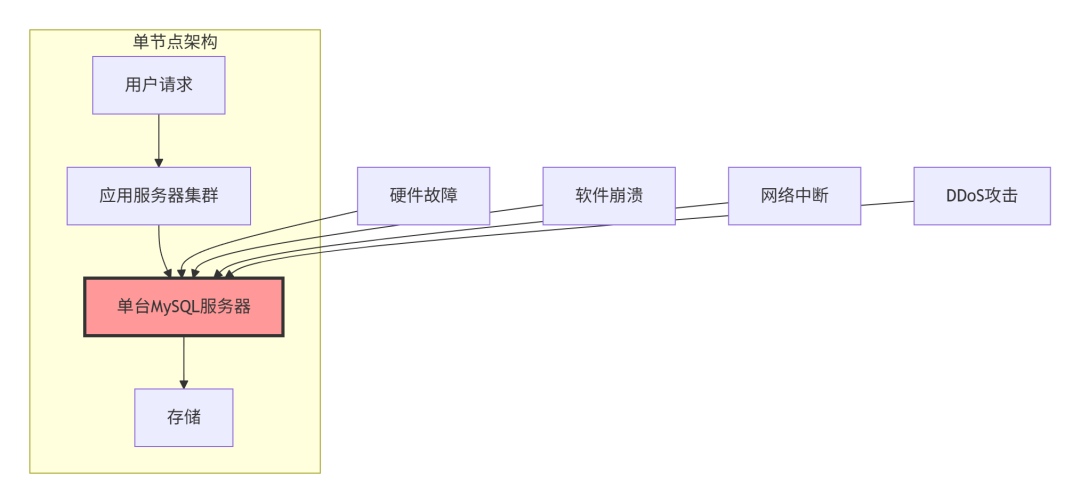
专业性描述:整个系统的数据库服务完全依赖于单一节点,一旦该节点因硬件故障、软件崩溃、网络中断等原因不可用,整个应用将完全无法访问数据库,导致服务中断。
“在线购物网站”示例:在网站只有一台MySQL服务器时,如果这台服务器的硬盘突然损坏,那么用户将无法:
- 浏览商品
- 下单购买
- 查看订单
- 进行支付
整个网站会直接瘫痪,直到服务器修复完成。在“双十一”大促期间,这种故障会导致每分钟数十万的订单损失。
1.2 性能瓶颈
专业性描述:所有读写请求都集中到单一数据库节点,随着业务增长,并发用户数增加,单节点的CPU、内存、磁盘I/O和网络带宽都会成为性能瓶颈。
“在线购物网站”示例:
- 高峰时段,每秒有上万个用户同时浏览商品(SELECT操作)
- 同时有数千个用户在下单(INSERT操作)
- 还有数百个用户在修改订单(UPDATE操作)
单台 MySQL 服务器的处理能力有限,当并发请求超过其处理上限时,响应时间会急剧增加,最终可能导致服务超时或服务器崩溃。
1.3 扩展困难
专业性描述:在单节点架构下,提升性能的唯一方式是通过升级硬件(垂直扩展),但硬件升级有物理上限,成本高昂,且需要停机维护。
“在线购物网站”示例:
- 初始阶段:使用4核CPU、16GB内存的服务器
- 发展阶段:升级到16核CPU、64GB内存
- 成熟阶段:即使升级到64核CPU、256GB内存,仍然无法满足数千万用户的需求
硬件升级不仅成本呈指数级增长,而且每次升级都需要停机,影响网站可用性。
1.4 数据丢失
专业性描述:单节点部署下,如果发生硬盘损坏、机房火灾、误操作删除数据等情况,且没有及时备份,将导致永久性数据丢失。
“在线购物网站”示例:
- 如果DBA误执行了
DELETE FROM orders WHERE 1=1,所有订单数据瞬间消失
- 如果硬盘损坏且没有备份,所有用户信息、商品数据、交易记录都会丢失
- 即使有备份,如果备份频率是每天一次,那么最多会丢失24小时的数据
下图展示了单节点架构的脆弱性:
2. 集群的优点
为了解决单节点的问题,“在线购物网站”引入了MySQL集群架构,带来了以下显著优势:
2.1 高可用
专业性描述:通过部署多个数据库节点,当主节点发生故障时,可以自动或手动快速切换到备用节点,最大程度减少服务中断时间。
“在线购物网站”示例:采用一主两从架构后,当主节点因硬件故障宕机时:
- 监控系统检测到故障
- 自动从两个从节点中选举新的主节点
- 应用切换到新的主节点
整个过程可在30秒内完成,用户可能只会感受到短暂的页面加载延迟,而不是完全无法访问。
2.2 负载均衡
专业性描述:可以将读请求分发到多个从节点,从而分摊负载,提高整体处理能力。
“在线购物网站”示例:统计发现网站流量中:
- 95%是读操作(商品浏览、订单查询、用户信息查看)
- 5%是写操作(下单、支付、修改信息)
通过负载均衡,可以将95%的读请求分发给多个从节点,主节点只需处理5%的写请求,整体处理能力提升数十倍。
2.3 水平扩展
专业性描述:可以通过增加从节点数量来线性扩展读性能,应对不断增长的业务压力。
“在线购物网站”示例:随着用户量从百万级增长到千万级:
- 初期:1主1从,处理每秒1万次查询
- 中期:1主3从,处理每秒3万次查询
- 后期:1主6从,处理每秒6万次查询
只需要增加从节点服务器,不需要修改应用代码,扩展成本相对较低。
2.4 提高数据安全性
专业性描述:数据在多个节点上有副本,即使单个节点数据损坏,其他节点仍保留完整数据。从节点还可用于备份,不影响主节点性能。
“在线购物网站”示例:
- 主节点实时同步数据到从节点
- 其中一个从节点专门用于备份,每天定时全量备份
- 另一个从节点用于数据分析,导出报表
即使主节点数据被误删除,也可以立即从从节点恢复。
3. MySQL 主从复制集群架构
3.1 架构组成
主节点:处理所有写操作(INSERT、UPDATE、DELETE),并将数据变更记录到二进制日志中。一个集群有且只有一个主节点。
从节点:复制主节点的数据变更,保持与主节点数据一致。从节点可以处理读操作(SELECT)。一个集群可以有多个从节点。
“在线购物网站”架构示例:
主节点(master1): 处理写操作
├── 从节点1(slave1): 处理读操作,实时同步
├── 从节点2(slave2): 处理读操作,实时同步
└── 从节点3(slave3): 专门用于备份,延迟同步
3.2 主从复制原理
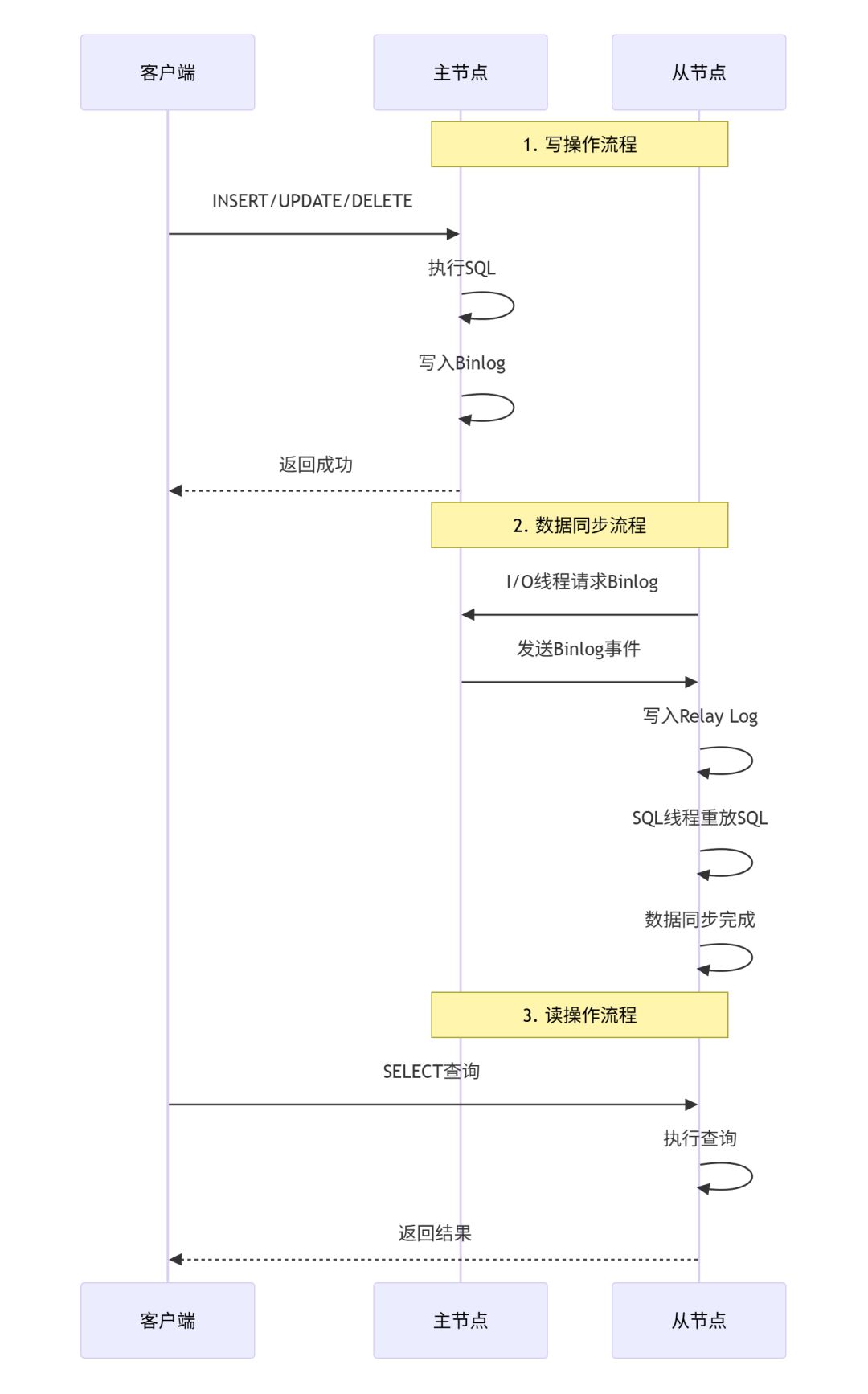
专业性描述:主从复制基于二进制日志实现,包含三个核心线程:
- 主节点Binlog Dump线程:当有从节点连接时创建,负责向从节点发送二进制日志事件
- 从节点I/O线程:连接主节点,读取二进制日志事件,写入本地的中继日志
- 从节点SQL线程:读取中继日志,执行其中的SQL语句,实现数据同步
大白话类比:就像总裁(主节点)的秘书记录他的所有工作安排(二进制日志)。其他部门的助理(从节点)会定期复印这份工作安排(I/O线程复制日志),然后按照安排执行工作(SQL线程重放日志)。
“在线购物网站”数据同步流程:
- 用户下单,主节点执行
INSERT INTO orders ...
- 主节点将这条SQL记录到二进制日志
- 从节点的I/O线程读取这条日志
- 写入从节点的中继日志
- 从节点的SQL线程执行这条SQL
- 从节点也有了这条订单记录
下图展示了主从复制的详细流程:
3.3 异步复制和半同步复制
异步复制:主节点执行完事务后立即返回给客户端,不等待从节点确认。这是默认的复制方式。
优点:性能好,主节点不会因为从节点延迟而变慢
缺点:可能存在数据丢失,主节点宕机时,未同步的数据会丢失
半同步复制:主节点在提交事务前,必须等待至少一个从节点接收并写入中继日志。如果超时(默认10秒),会退化为异步复制。
优点:保证至少一个从节点有数据,提高数据安全性
缺点:性能略有下降,响应时间增加
“在线购物网站”选择策略:
- 核心业务(支付、订单):使用半同步复制,确保数据不丢失
- 非核心业务(商品浏览、用户评论):使用异步复制,追求性能
- 从节点延迟较高时,自动降级为异步复制,避免影响主节点
4. 读写分离
4.1 核心思想
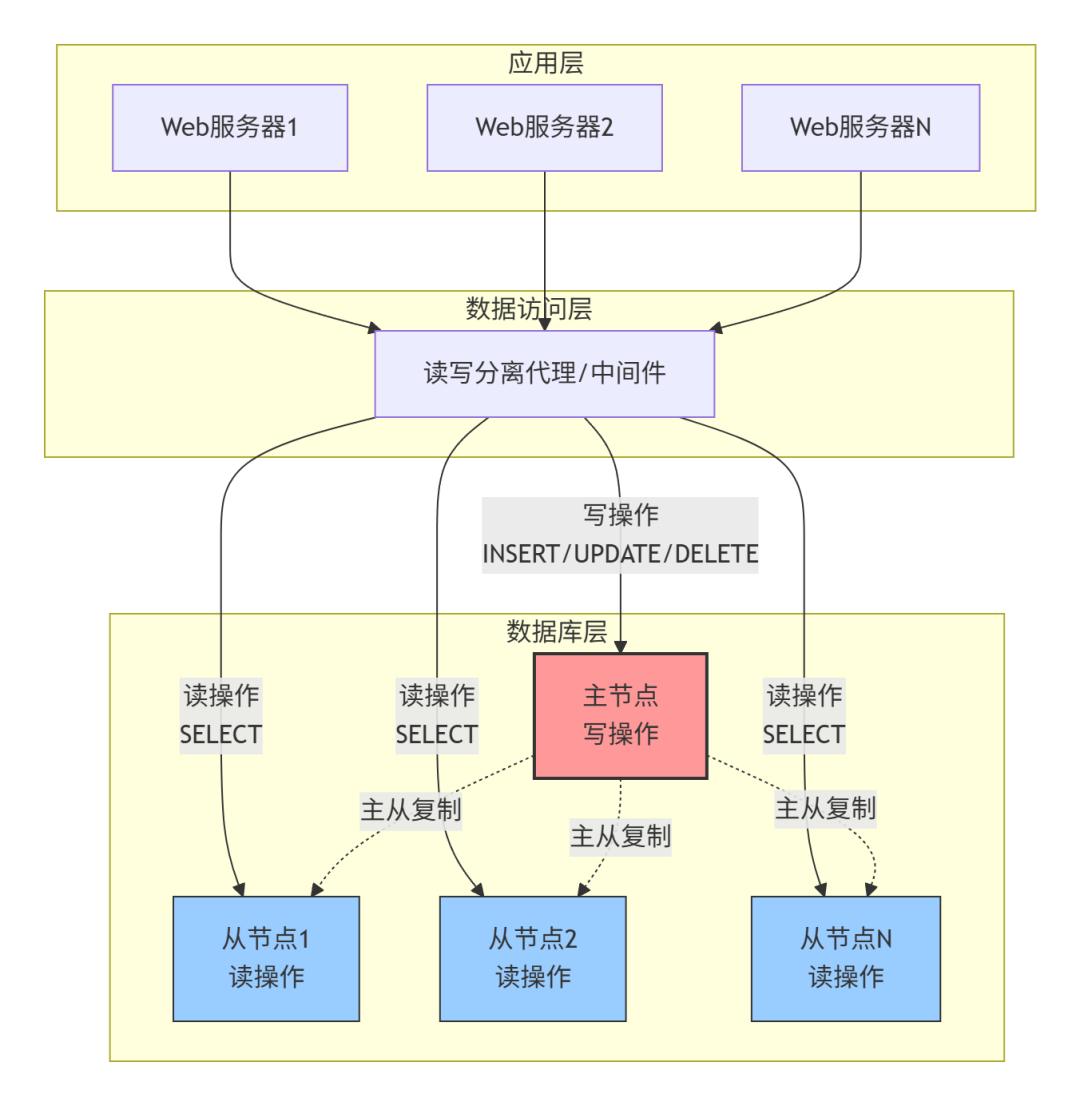
专业性描述:将写操作(增删改)定向到主节点,读操作(查询)定向到从节点,实现负载分摊。
“在线购物网站”示例:
- 写操作路由到主节点:用户注册、下单、支付、修改信息
- 读操作路由到从节点:商品浏览、订单查询、用户信息查看、搜索
4.2 读写分离的重要性
提高性能:将占95%的读请求分散到多个从节点,避免单点瓶颈。
提高扩展性:随着读压力增加,只需增加从节点即可,无需修改应用架构。
高可用:当某个从节点故障时,读请求可路由到其他从节点;主节点故障时可切换到从节点。
“在线购物网站”量化收益:
- 单节点时:QPS 5000,响应时间200ms
- 一主三从读写分离后:QPS 20000,响应时间50ms
- 性能提升4倍,成本增加不到2倍
4.3 实现方式
4.3.1 硬编码
在应用代码中直接指定数据库连接。
// 写操作使用主库
@WriteDataSource
public void createOrder(Order order) {
// 使用主库连接
String url = "jdbc:mysql://master:3306/shop";
// 执行INSERT
}
// 读操作使用从库
@ReadDataSource
public Order getOrder(String orderId) {
// 使用从库连接
String url = "jdbc:mysql://slave1:3306/shop";
// 执行SELECT
}
缺点:配置硬编码,难以维护;增删从节点需要修改代码重启应用。
4.3.2 嵌入式 SDK
使用数据库中间件的客户端SDK,在应用中配置数据源。
# application.yml
shardingsphere:
datasource:
names: master,slave1,slave2
master:
type: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://master:3306/shop
slave1:
type: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://slave1:3306/shop
slave2:
type: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://slave2:3306/shop
rules:
readwrite-splitting:
data-sources:
readwrite_ds:
type: Static
props:
write-data-source-name: master
read-data-source-names: slave1,slave2
优点:对应用透明,配置灵活,支持动态增减节点。
4.3.3 代理服务
在应用和数据库之间部署代理层,如MyCat、ProxySQL、MySQL Router。
应用服务器 -> 代理服务器 -> 数据库集群
↑ ↑
统一连接 自动路由
“在线购物网站”使用ProxySQL示例:
- 部署ProxySQL集群
- 应用连接ProxySQL的6033端口
- ProxySQL配置:
- 写组:指向主节点
- 读组:指向所有从节点
- 负载均衡策略:轮询
- ProxySQL自动检测节点健康状态,自动故障转移
优点:对应用完全透明,运维方便,支持高级路由策略。
下图展示了读写分离的完整架构:
5. 常见问题及解决方案
5.1 主从复制延迟
问题描述:从节点上的数据落后于主节点,在从节点上查询不到刚写入的数据。
“在线购物网站”典型场景:
用户支付成功后立即查看订单状态,由于查询走了从节点,而从节点还没同步到支付状态,用户看到“未支付”,导致重复支付或客诉。
5.1.1 产生原因
硬件差异:从节点使用低配服务器,同步速度跟不上。
-- 主节点:SSD硬盘,32核CPU
-- 从节点:机械硬盘,8核CPU
-- 结果:从节点处理Binlog速度只有主节点的1/4
网络延迟:主从节点跨机房部署,网络传输耗时长。
北京主节点 -> 上海从节点:网络延迟30ms
每次同步都要增加30ms延迟
资源竞争:从节点承担复杂查询,占用CPU和I/O资源。
-- 从节点上运行的报表查询
SELECT user_id, COUNT(*) as order_count,
SUM(amount) as total_amount
FROM orders
WHERE create_time >= '2024-01-01'
GROUP BY user_id
ORDER BY total_amount DESC
-- 这个查询运行5分钟,期间主从同步被阻塞
大事务:主节点执行大事务,从节点重放时间长。
-- 主节点执行的清理任务
DELETE FROM user_logs
WHERE create_time < '2023-01-01'
-- 删除1000万条记录,执行10分钟
-- 从节点也需要10分钟来重放
5.1.2 解决方案
关键业务强制走主库:
@Service
public class OrderService {
// 普通查询走从库
@ReadDataSource
public Order getOrderHistory(String orderId) {
// 历史订单查询,允许延迟
}
// 支付后查询强制走主库
@MasterDataSource
public Order getOrderAfterPayment(String orderId) {
// 支付后立即查询,必须实时
}
}
使用缓存:
// 支付成功后
public void paySuccess(String orderId) {
// 1. 更新数据库
orderDao.updateStatus(orderId, "PAID");
// 2. 同时写入Redis,设置5秒过期
redisTemplate.opsForValue().set(
"order:" + orderId,
"PAID",
5, TimeUnit.SECONDS
);
}
// 查询订单状态
public String getOrderStatus(String orderId) {
// 1. 先查缓存
String status = redisTemplate.opsForValue()
.get("order:" + orderId);
if (status != null) {
return status;
}
// 2. 缓存没有,查数据库(可能走从库)
return orderDao.getStatus(orderId);
}
硬件优化:
- 主从节点使用相同配置的服务器
- 全部使用SSD硬盘
- 保证足够的网络带宽
并行复制:
-- 在从节点上开启并行复制
STOP SLAVE;
SET GLOBAL slave_parallel_workers = 8;
SET GLOBAL slave_parallel_type = 'LOGICAL_CLOCK';
START SLAVE;
-- 从串行复制变为8个线程并行复制,提升同步速度
6. 记忆技巧与实战要点
核心口诀:
单节点四弊端,故障瓶颈扩展难。
集群架构好处多,高可用来负载均。
一主多从是标配,读写分离性能增。
异步复制性能好,半同步来保安全。
主从延迟要警惕,关键业务走主库。
7. 实战要点
- 容量规划:
- 每个从节点的读QPS不要超过主节点的70%
- 监控主从延迟,设置报警阈值(如>5秒)
- 监控体系:
-- 关键监控指标
SHOW SLAVE STATUS\G
-- 关注:Seconds_Behind_Master(延迟秒数)
-- 关注:Slave_IO_Running, Slave_SQL_Running
- 备份策略:
- 使用专用从节点进行备份
- 备份时间避开业务高峰
- 定期测试备份恢复流程
- 故障演练:
- 每季度进行主从切换演练
- 模拟从节点故障,测试路由切换
- 记录故障恢复时间,不断优化
- 连接管理:
// 使用连接池,合理配置
HikariConfig config = new HikariConfig();
config.setMaximumPoolSize(20); // 每个节点20连接
config.setConnectionTimeout(30000); // 30秒超时
config.setIdleTimeout(600000); // 10分钟空闲回收
通过构建 MySQL 主从复制集群并实施读写分离,在线购物网站可以有效解决单点故障、性能瓶颈等问题,从而支撑业务的快速增长。如果你对系统高可用架构或数据库优化有更多想法,欢迎在 云栈社区 与更多开发者交流讨论。
 发表于 2026-2-28 07:44:02
|
查看: 134|
回复: 0
发表于 2026-2-28 07:44:02
|
查看: 134|
回复: 0
