大家好,我是小林。
之前跟大家盘点26届校招薪资的时候,发现有同学留言说想看海康威视的薪资情况。
看到留言后,我立马去收集整理了一波26届海康威视开发岗位的薪资数据。现在就来给大家分享一下,顺便聊聊它的面试难度。
26届海康威视开发岗薪资一览
先看数据。以下是基于我收集到的信息整理的薪资表格,年终奖一般是2-4个月,我这里取个中间值,统一按15薪来计算年总包,方便大家对比。
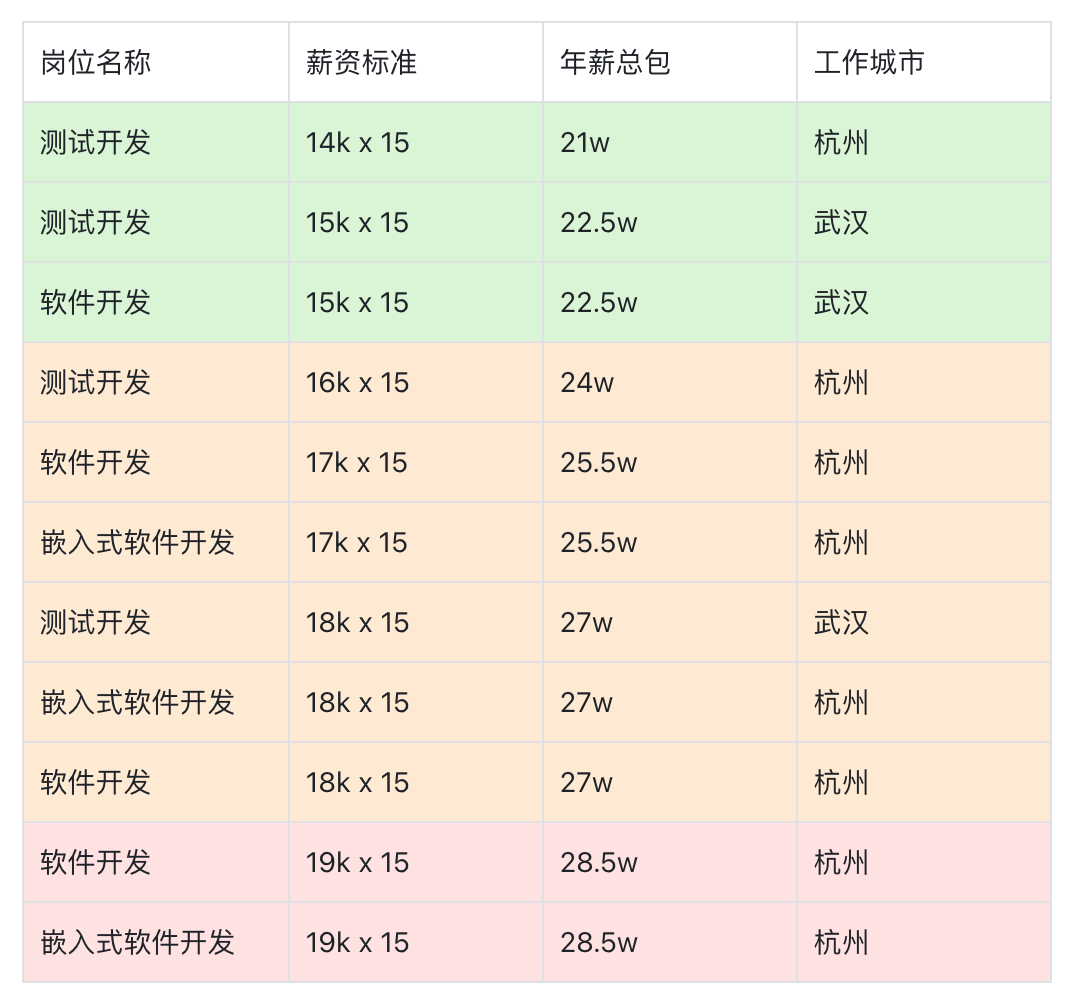
为了方便理解,我把不同offer档次的薪资范围划分了一下:
- 绿色部分可以看作是普通Offer,月薪在14k到15k左右。
- 橙色部分对应SP Offer,月薪在16k到18k。
- 红色部分则是SSP Offer,月薪达到了19k以上。
总体来看,这个薪资水平在行业中算是“体面”的。虽然谈不上顶尖,但也绝对不低,属于比较典型的中厂待遇范围,月薪集中在15k到20k这个区间。
我也对比了一下去年的数据,可以说基本没什么变化,薪资范围相当稳定。下面是去年25届的几个数据点,大家可以参考:

除了薪资,还有个福利点值得一提:海康威视是六险一金,并且公积金是顶格12%缴纳,这一点对员工来说还是很不错的。
聊完薪资,相信很多同学更关心的是:海康威视的面试到底难不难?都问些什么?
海康威视后端开发一面真题复盘
从我收集到的信息来看,这场面试的考察点主要集中在JavaSE、排序算法、Redis、MySQL、Java并发、操作系统、Spring这些核心知识上。
面试的风格属于广度大于深度,涉及的知识面很广,但每个知识点通常只问一到两个核心问题,不会在一个点上追问得特别深。所以,只要你基础扎实,对各个知识点都有所了解,应对起来应该不会太吃力。
下面我就把收集到的一道后端开发一面真题,结合我的理解和扩展,给大家详细解析一遍。

1. 你是如何理解Java的面向对象特性?
我认为Java的面向对象特性主要体现在封装、继承、多态这三个方面,这也是日常开发中使用最多的。
- 封装:核心是把数据和操作数据的方法绑定在一起,对外隐藏实现细节,只暴露必要的接口。例如,将类的属性设为
private,通过public的getter/setter访问,可以在setter中加入数据校验逻辑,保证有效性。封装也提高了代码的可维护性,内部实现变更只要接口不变,外部调用方就无需感知。
- 继承:允许子类复用父类的代码,避免重复。但需要谨慎使用,因为继承带来了较高的耦合度(父类改动可能影响所有子类)。在实际设计中,如果仅仅是为了代码复用,很多时候组合优于继承。
- 多态:这是面向对象的精髓。它允许同一接口有不同的实现,运行时根据实际对象类型决定调用哪个方法。最常见的应用就是定义接口或抽象类,然后有多个实现类。例如定义一个
Payment支付接口,有AliPay、WeChatPay等实现。业务代码只依赖接口,传入什么实现就调用什么方法,这使得系统对扩展开放,对修改封闭,非常灵活。
2. 说一下你对泛型的了解?
泛型是Java中用于提供编译时类型安全的机制。它允许在定义类、接口或方法时使用类型参数,在使用时再指定具体类型。
为什么需要泛型?
-
代码复用:避免为不同类型编写重复的逻辑。例如,一个加法方法,没有泛型时需要为int, float, double分别重载:
private static int add(int a, int b) {
System.out.println(a + "+" + b + "=" + (a + b));
return a + b;
}
// 还需要为float, double写同样的方法...
使用泛型后,可以复用为一个方法:
private static <T extends Number> double add(T a, T b) {
System.out.println(a + "+" + b + "=" + (a.doubleValue() + b.doubleValue()));
return a.doubleValue() + b.doubleValue();
}
-
类型安全:消除强制类型转换,避免ClassCastException。没有泛型时,集合可以放入任意对象,取出时需要强制转换,容易出错:
List list = new ArrayList();
list.add("xxString");
list.add(100d);
// 取出时需强制转换,可能发生类型转换异常
String str = (String) list.get(1); // 错误!
引入泛型后,编译器会在编译期进行检查:
List<String> list = new ArrayList<String>();
list.add("xxString"); // OK
// list.add(100d); // 编译错误!
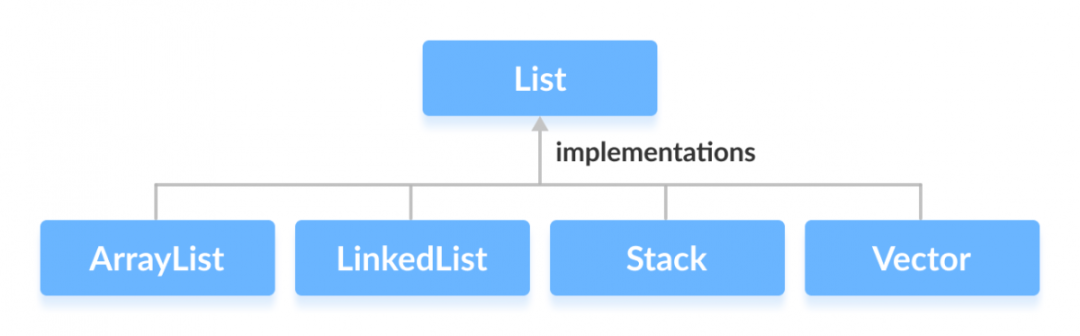
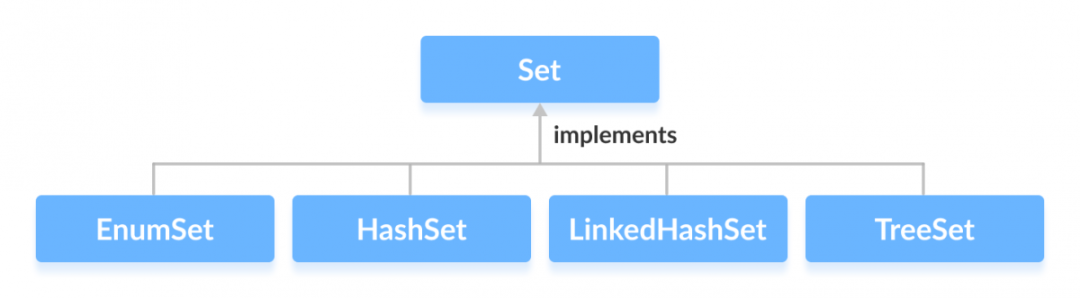
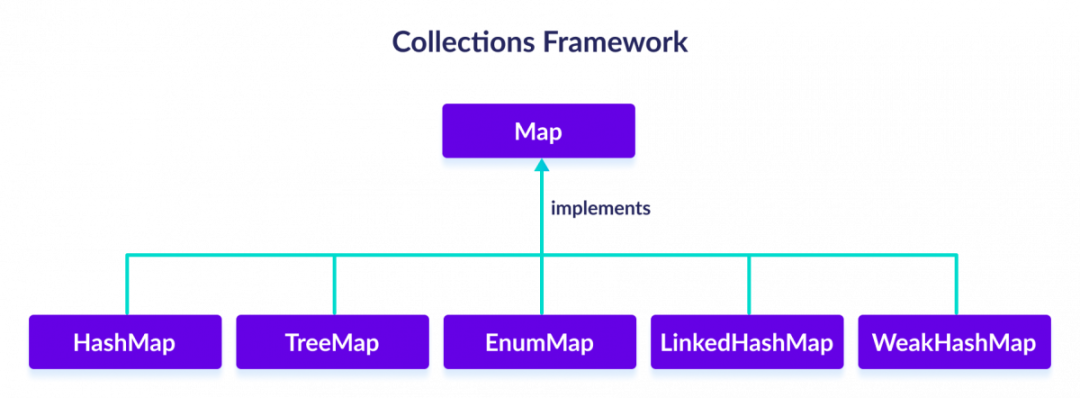
3. java 集合中 map,list,set的底层数据结构是怎样的?
4. 常用的排序算法有哪些,及其时间复杂度
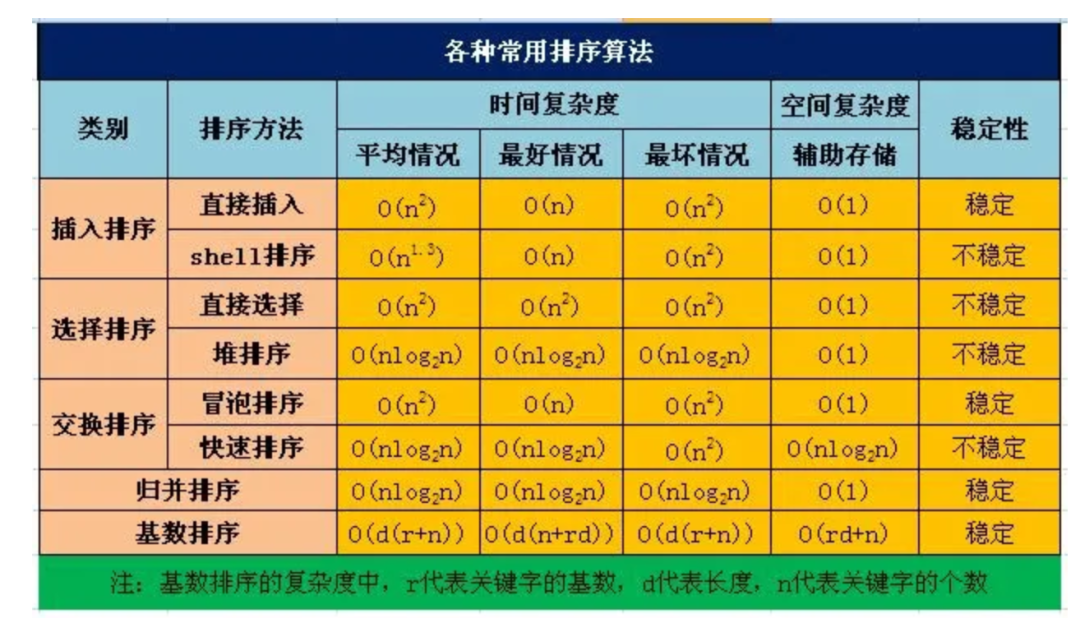
- 冒泡排序:相邻元素比较交换,逐步将最大/小值“冒泡”到一端。平均/最坏
O(n²),最好O(n),空间O(1),稳定。
- 插入排序:将元素逐个插入到前面已排序序列的合适位置。平均/最坏
O(n²),最好O(n),空间O(1),稳定。
- 选择排序:每次从剩余元素中选择最小/大值放到已排序序列末尾。始终为
O(n²),空间O(1),不稳定。
- 快速排序:选取基准,划分左右子数组递归排序。平均
O(n log n),最坏O(n²)(如已排序数组),空间O(log n),不稳定。
- 归并排序:分治法,递归划分子数组,然后合并有序子数组。始终
O(n log n),空间O(n),稳定。
- 堆排序:构建最大/小堆,交换堆顶与末尾元素并调整堆。始终
O(n log n),空间O(1),不稳定。
5. 谈一谈对redis的理解,高并发下会有什么问题?
Redis是一个基于内存的高性能键值数据库,常用作缓存、分布式锁、消息队列等。其单机QPS可达数万甚至十万级,支持String、List、Hash、Set、ZSet等多种数据结构。
在高并发场景下,使用Redis做缓存通常会遇到以下几个经典问题:
-
缓存穿透
查询一个数据库中根本不存在的数据,导致请求绕过缓存直接打到数据库。
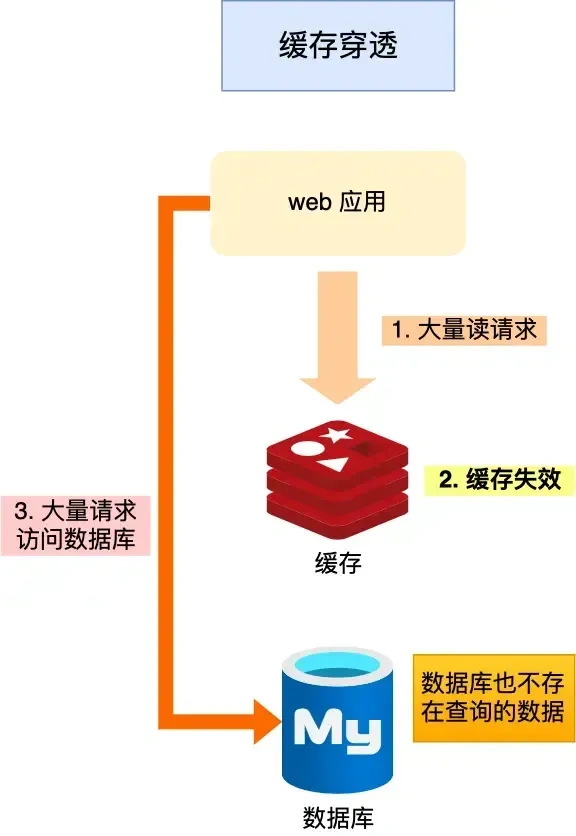
- 解决方案:
- 布隆过滤器:在查询缓存前,先用布隆过滤器判断Key是否存在,不存在则直接返回。
- 缓存空值:即使数据库查不到,也将这个Key在Redis中缓存为一个空值(如
null),并设置一个较短的过期时间。
-
缓存击穿(热点Key失效)
某个访问量巨大的热点Key突然过期,瞬间大量请求穿透缓存,直接访问数据库。
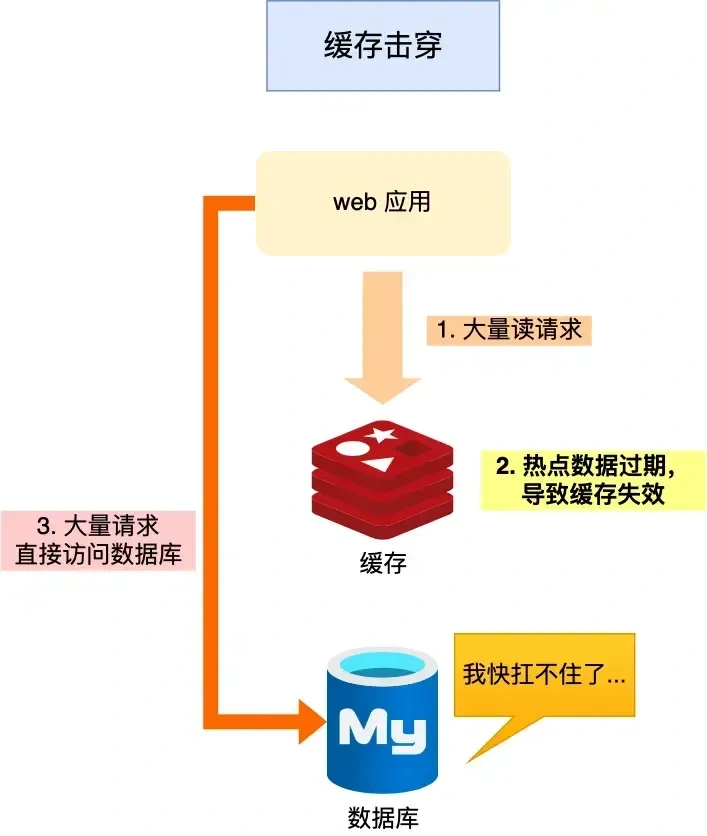
- 解决方案:
- 设置永不过期:对热点Key不设置过期时间,或通过后台任务异步更新。
- 互斥锁:当缓存失效时,只允许一个线程去查询数据库并重建缓存,其他线程等待或重试。
-
缓存雪崩
大量Key在同一时间段集中过期,或Redis服务宕机,导致所有请求涌向数据库。
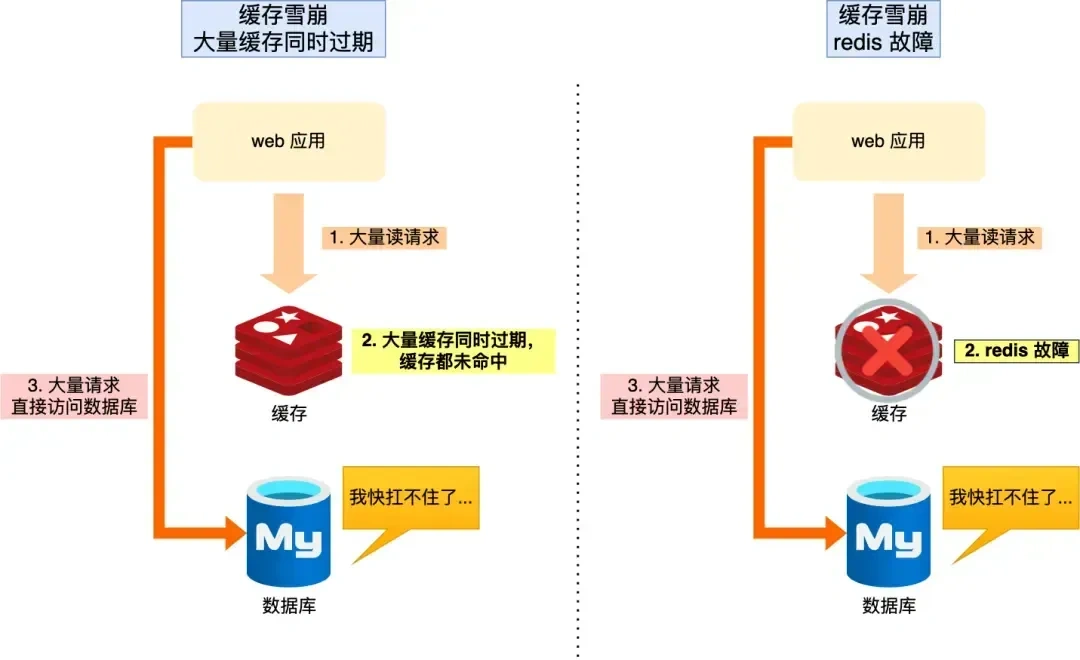
- 解决方案:
- 差异化过期时间:给缓存Key的过期时间加上一个随机值,避免同时失效。
- 高可用架构:采用Redis主从+哨兵或集群模式,避免单点故障。
- 服务降级与熔断:当发现数据库压力过大时,对非核心业务进行降级或熔断。
- 本地缓存兜底:可以使用Guava Cache等本地缓存作为二级缓存,在Redis失效时提供一定保护。
-
数据库与缓存一致性问题
这是最复杂的问题。常见的“先更新数据库,再删缓存”或“先删缓存,再更新数据库”都可能在高并发下产生短暂不一致。
- 解决方案:
- 延迟双删:先删缓存 -> 更新数据库 -> 休眠一段时间 -> 再删一次缓存。
- 设置合理的过期时间:对于一致性要求不高的场景,可以接受短暂不一致,通过设置较短的缓存过期时间来最终达成一致。
- 订阅数据库Binlog:通过Canal等工具监听数据库变更,异步更新或删除缓存(最终一致性)。
6. springboot和springmvc的差异是什么?设计理念的区别?
首先要明确,Spring Boot不是用来替代Spring MVC的,它们是不同层面的概念。
- Spring MVC是Spring框架中的一个Web MVC框架,专注于处理HTTP请求,实现控制器、模型、视图的分离。
- Spring Boot是一个快速应用开发脚手架,它整合了Spring技术栈(包括Spring MVC),并通过一系列默认配置和 starter 依赖,极大地简化了基于Spring的应用搭建、开发、部署。
核心差异:
- 配置方式:Spring MVC需要大量XML或Java Config配置(如
DispatcherServlet、视图解析器、数据源等)。Spring Boot推崇约定大于配置,提供大量自动配置,开发者只需极简配置(如一个application.yml)即可运行。
- 部署:传统的Spring MVC应用通常需要打包成WAR部署到外部Tomcat等Web容器。Spring Boot应用内嵌了Web服务器(如Tomcat),可以直接打包成可执行的JAR文件运行。
- 依赖管理:Spring Boot通过
spring-boot-starter-*系列依赖,自动管理版本和传递依赖,解决了传统Spring项目令人头疼的“Jar包地狱”问题。
- 生产就绪特性:Spring Boot内置了Actuator模块,提供了健康检查、指标监控、配置刷新等开箱即用的生产级特性,非常适合微服务架构。
设计理念:
- Spring MVC:提供灵活、可定制的Web框架,将控制权交给开发者,适合需要精细控制的项目。
- Spring Boot:旨在简化开发、快速上手,通过默认最佳实践和自动配置,让开发者能更专注于业务逻辑,提升开发效率。
简单说,Spring Boot是包含了Spring MVC的“一站式”解决方案平台。
7. springboot常用注解有哪些?
-
Bean声明与扫描:
@Component:通用组件注解。@Controller / @RestController:标识控制层组件,后者是@Controller+@ResponseBody。@Service:标识业务层组件。@Repository:标识数据访问层组件。@Bean:在配置类中声明方法,将返回值注册为Bean。@ComponentScan:指定扫描包路径。
-
依赖注入:
@Autowired:按类型自动注入。@Resource:默认按名称注入。@Qualifier:与@Autowired配合,指定注入的Bean名称。
-
读取配置:
@Value:注入单个属性值,如@Value(“${server.port}”)。@ConfigurationProperties:将一组配置属性绑定到一个Bean上。
-
Web请求映射:
@RequestMapping:通用请求映射。@GetMapping, @PostMapping, @PutMapping, @DeleteMapping:分别对应HTTP方法。
-
其他常用:
@Transactional:声明式事务管理。@Scheduled:声明定时任务。
8. MySQL常用的sql优化思路是什么?
- 使用EXPLAIN分析:这是第一步,通过
EXPLAIN命令查看SQL的执行计划,关注type(访问类型)、key(使用的索引)、rows(扫描行数)等字段。
- 合理创建与使用索引:
- 为
WHERE、ORDER BY、GROUP BY、JOIN ON条件中的字段创建索引。
- 使用联合索引并遵循最左前缀原则。
- 避免索引失效:如对索引字段进行函数计算、类型转换、使用
%开头的LIKE模糊查询、使用OR连接非索引字段等。
- 优化查询语句:
- 避免
SELECT *,只取需要的列。
- 尽量使用覆盖索引(索引包含所有查询字段)。
- 优化
JOIN查询,确保被驱动表的关联字段有索引,且小表驱动大表。
- 优化深分页
LIMIT M, N,可尝试用WHERE id > last_id LIMIT N或JOIN子查询等方式。
- 考虑读写分离:主库写,从库读,分摊压力。
- 表结构优化:
- 根据业务进行分库分表(水平/垂直拆分),应对单表数据量过大的问题。
- 进行适度的字段冗余,以减少关联查询。
- 引入缓存:使用Redis等缓存热点数据,减少数据库直接访问。
9. 进程和线程的区别是什么?
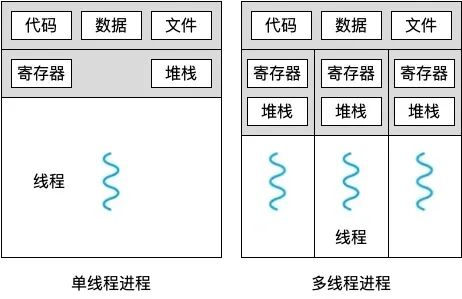
- 资源分配与调度:进程是操作系统资源分配(内存、文件句柄等)的基本单位;线程是CPU调度和执行的基本单位。
- 内存与开销:进程拥有独立的地址空间,一个进程崩溃通常不影响其他进程,但创建、切换开销大。线程共享进程的资源,创建、切换开销小,但一个线程崩溃可能导致整个进程崩溃。
- 通信方式:进程间通信(IPC)需要特殊的机制,如管道、消息队列、共享内存等。线程间通信可以直接读写共享的进程数据,但需要同步机制(如锁)来保证安全。
10. 线程间通信方式有哪些?
Java中线程间通信主要围绕共享变量的同步与协调。
-
等待/通知机制:
Object类的wait(), notify(), notifyAll()方法(需在synchronized同步块中使用)。Lock与Condition接口:Condition的await(), signal(), signalAll()方法,比Object的等待/通知更灵活,可以创建多个等待条件。
// Lock + Condition 示例
private final Lock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
public void consumer() throws InterruptedException {
lock.lock();
try {
while (!conditionMet) {
condition.await(); // 等待
}
// 消费数据
} finally {
lock.unlock();
}
}
public void producer() {
lock.lock();
try {
// 生产数据
condition.signal(); // 唤醒一个等待线程
} finally {
lock.unlock();
}
}
-
volatile共享变量:通过volatile关键字保证变量的可见性,一个线程修改后,其他线程能立即看到最新值。常用于简单的状态标志位。
-
并发工具类:
CountDownLatch:一个或多个线程等待其他线程完成操作。CyclicBarrier:一组线程相互等待,到达屏障点后一起继续执行。Semaphore:控制同时访问特定资源的线程数量(信号量)。
11. 多线程下, Java资源一致性如何保证?
保证多线程下资源一致性,核心是解决原子性、可见性、有序性问题。
-
synchronized关键字:JVM内置锁。能同时保证原子性、可见性和有序性。但它是互斥锁,性能有一定开销。
public synchronized void safeMethod() {
// 操作共享资源
}
-
Lock接口:如ReentrantLock。显式锁,比synchronized更灵活(可尝试获取、可中断、可设置公平性等),但必须手动lock()和unlock()。
-
volatile关键字:只能保证可见性和有序性(禁止指令重排序),不能保证复合操作的原子性(如i++)。
-
原子类:如AtomicInteger。底层使用CAS(Compare And Swap)操作保证单个变量的原子性更新,性能通常优于锁。适合计数器等场景。
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet(); // 原子操作
}
-
ThreadLocal:为每个线程创建变量的独立副本,从根本上避免共享,适用于上下文传递(如用户信息)。但需注意使用后及时remove(),防止内存泄漏。
选择哪种机制,取决于具体场景:简单状态用volatile;简单原子操作用原子类;复杂同步用synchronized或Lock;线程隔离用ThreadLocal。
12. 其他
- 介绍一下实习项目,讲一下全流程。
- 对岗位的未来规划。
总结
总的来说,海康威视为应届生提供的薪资待遇在行业中处于一个稳健、体面的水平,其面试则侧重于对Java及后端常用技术栈基础广度的考察。对于正在准备面试求职的同学来说,夯实本文中涉及的基础知识,是应对此类企业面试的关键。
希望这份薪资数据和面试解析能对大家有所帮助!
 发表于 2026-3-1 02:35:06
|
查看: 163|
回复: 0
发表于 2026-3-1 02:35:06
|
查看: 163|
回复: 0