自动Alpha因子挖掘在量化投资中扮演着关键角色,但也伴随着巨大挑战。搜索空间广阔,需要注入领域知识以生成可解释的信号;更棘手的是,随着因子库的增长,发现与现有信号不冗余的新因子变得越来越困难。
为此,FactorMiner应运而生。它是一个轻量级、灵活的自进化AI Agent框架,通过结合模块化的技能架构与结构化的经验记忆,利用Ralph Loop范式迭代地使用记忆先验来引导探索,从而有效减少冗余发现。多数据集的实验表明,FactorMiner能够构建出高质量、低冗余的因子库,为在“相关性红海”约束下实现可解释的自动化Alpha因子发现提供了一种可扩展的实用方法。

简介
自动化因子发现主要面临三大挑战:极高的搜索复杂度、差劲的知识积累能力,以及必须满足可解释性约束。传统方法严重依赖专家手动构建因子;机器学习方法虽具强大预测力,但往往以牺牲可解释性为代价;遗传编程和强化学习等方法则存在知识遗忘问题。此外,现有方法通常孤立地处理每个因子,导致冗余发现和低效探索。
本研究将公式化的因子挖掘重构为一个自进化的AI智能体任务,其核心在于:智能体如何高效地探索程序空间,同时又能兼顾因子库的全局视角,并自主积累结构化知识。
FactorMiner的解决方案是组合两种协同机制:技能架构与经验记忆。技能架构将因子挖掘过程设计为可按需调用的技能,封装了领域知识;而经验记忆则存储了历史挖掘的结构化模式,使智能体能够从全局因子库的视角来决策挖掘方向。整个系统采用Ralph Loop范式,形成一个正反馈循环,持续提升未来探索的效率。该框架构建为一个轻量级的高性能系统,充分利用GPU加速、多进程并行和C编译操作符,实现了大规模的迭代评估。
本文的主要贡献包括:
- 引入了经验记忆用于因子挖掘;
- 设计了模块化的技能架构;
- 打造了高效的挖掘系统;
- 实现了从全局因子库视角进行决策;
- 提供了一个具有研究和实用价值的A股因子库。
相关工作
自动Alpha因子发现
传统的因子发现依赖于领域知识手动构建可解释信号,例如101 Alpha和Alpha191因子库,但这些通常局限于日线数据,且复杂结构的经济解释性不透明,高频市场也缺乏类似的因子库。
自动化方法主要包括:
- 进化程序搜索:如遗传编程,将因子公式表示为可进化程序,但探索效率低、收敛慢,且缺乏语义引导。
- 机器学习方法:预测性能强,但透明度低,在高风险场景中难以解释和审计。
- 强化学习:以评估指标作为奖励来探索离散空间,但存在额外的训练和重复评估开销。
- 神经/大语言模型驱动框架:可生成和优化因子,但仍难以跨挖掘会话复用结构化模式,当因子库增大时,探索容易重复。
具有技能和记忆的AI Agent
语言模型Agent正从单次文本生成转向闭环任务执行。受Toolformer、ReAct等工作的启发,FactorMiner将因子挖掘封装为可调用的技能。记忆和自我改进机制帮助Agent积累经验,本文为符号程序合成的场景实例化了这种记忆,保留了规则、模式及统计信息。从理论上讲,这与元学习和元强化学习中“学会学习”的思想相通,记忆引导的挖掘能够积累搜索的先验知识。
系统性的工作倡导模块化的Agent架构。相关研究关注如何将大模型输出转化为API调用及减少工具幻觉,强调规划与执行的分离以及工具技能的可检索更新。为解决长上下文问题,MemGPT提出了分层内存,Voyager则积累技能库。我们的工作表明,需要一个经验总结机制来避免重复和无效的探索。
方法
问题建模
任务定义:在 𝑀 个资产和时间范围 𝑇 内进行 Alpha 因子发现。市场输入为张量 D,符号化 Alpha 因子 𝛼 将市场状态映射为预测信号 𝑠ₜ。
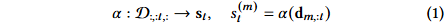
因子评估指标:使用信息系数(IC)来量化因子 𝛼 的有效性,信息比率(ICIR)衡量其时间一致性。使用时间平均的横截面 Spearman 相关性来衡量两个因子之间的冗余度。
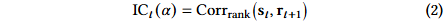
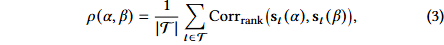
目标:迭代构建一个多样化的因子库 L,最大化其聚合的预测质量,同时满足全局冗余约束。
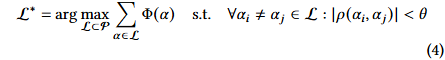
问题挑战:随着 L 的扩充,新的正交因子的可行区域迅速缩小,标准搜索方法极易陷入“相关性红海”。
解决方案:将发现过程重构为基于内部知识状态 𝑆ₜ 的顺序决策任务,通过记忆信号 𝑚ₜ 来引导采样。记忆 M 由蒸馏算子 Ψ 更新,从而使探索指向高效用、低冗余的区域。
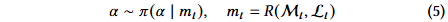
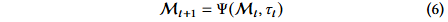
因子挖掘技能架构
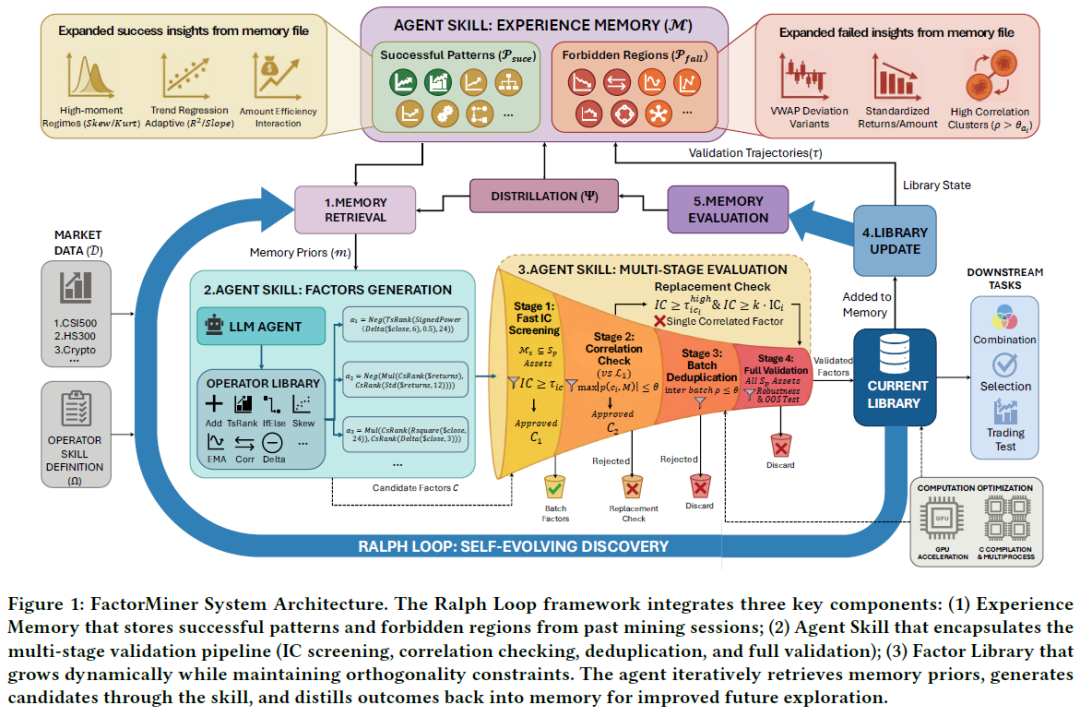
FactorMiner 采用模块化的技能架构,将因子挖掘过程封装为独立、可复用的 Agent 技能,其交互模式如图 1 所示。
技能采用组合式设计,是一个分层工具库:操作层包含 60 多个 GPU 加速的金融操作符;验证管道则包含严格的因子评估协议。
基于技能的方法具有三大优势:
- 防止计算幻觉:确保所有指标都经过严谨计算。
- 支持跨市场配置:技能可以根据不同市场的数据模式进行参数调整,实现跨域迁移。
- 执行与评估解耦:技能的执行和评估可以独立优化,提升系统吞吐量,且无需重新训练大语言模型。
经验记忆
FactorMiner 的关键组件是经验记忆 M,它通过三个概念上的算子实现动态管理:
- 记忆形成:在每批挖掘结束时,分析挖掘轨迹,使用形成算子 F 从原始数据中提取信息工件,主要分为成功模式 P_succ 和禁止区域 P_fail。
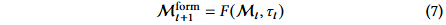
- 记忆进化:使用进化算子 E 将新形成的记忆候选者整合到现有知识库中,合并冗余条目,丢弃低效用信息。
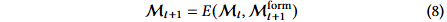
- 记忆检索:在因子生成阶段,通过检索算子 R 获取上下文相关的记忆信号 𝑚ₜ,以此来约束大语言模型策略的采样分布。
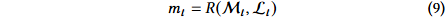
记忆内容包括:
- 挖掘状态:跟踪因子库的全局演变,如库大小、准入日志和饱和指标。
- 结构经验:是指导系统的核心,分为推荐方向 P_succ 和禁止方向 P_fail。
- 战略洞察:挖掘过程中总结的高级经验,例如非线性组合策略往往更优,或对特定操作符发出警告。
Ralph Loop:自我进化因子发现
FactorMiner 采用 Ralph Loop 范式进行因子挖掘,将经验记忆无缝融入搜索过程。该范式具有四个关键属性:
- 全局库视角:考虑候选因子与现有因子库的互补性,通过相关性约束和替换机制来保证多样性。
- 记忆引导探索:维护成功和失败的模式,避免重复和冗余的探索。
- 多阶段评估:分阶段进行筛选,以平衡效率与准确性。
- 自我进化:迭代更新记忆,持续改进搜索策略。
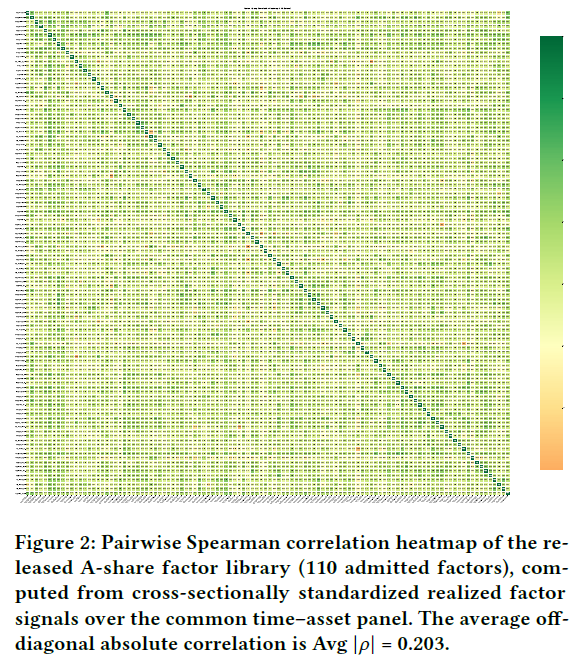
轨迹语义记录了候选因子的详细信息,支持经验的提炼。可视化A股因子库的相关性结构显示,大多数因子对之间的相关性为弱到中等。

实验
实验设置
数据集:在A股和加密货币市场评估 FactorMiner。A股使用三个指数成分股的10分钟日内高频数据(超过2500万个数据点),加密货币使用币安64种主要资产的10分钟数据。数据涵盖2024年第一季度至第四季度的训练期和2025年的测试期,预测目标为下一个10分钟开盘到收盘的价格变化率。
基线与指标:与五种方法对比:Alpha101 (Classic)、Alpha101 (Adapted)、Random Formula Exploration、GPLearn、AlphaAgent。所有方法应用相同的准入规则,评估同等规模的因子集,若数量不足则选择IC最佳者补充。还设置了 No Memory 变体作为内部基线。使用 Rank Information Coefficient (IC) 和 ICIR 量化性能,各基线共享操作符库、数据字段等,并使用统一的评估引擎进行评分。需要大语言模型生成提案的方法默认使用 Gemini 3.0 Flash。
结果
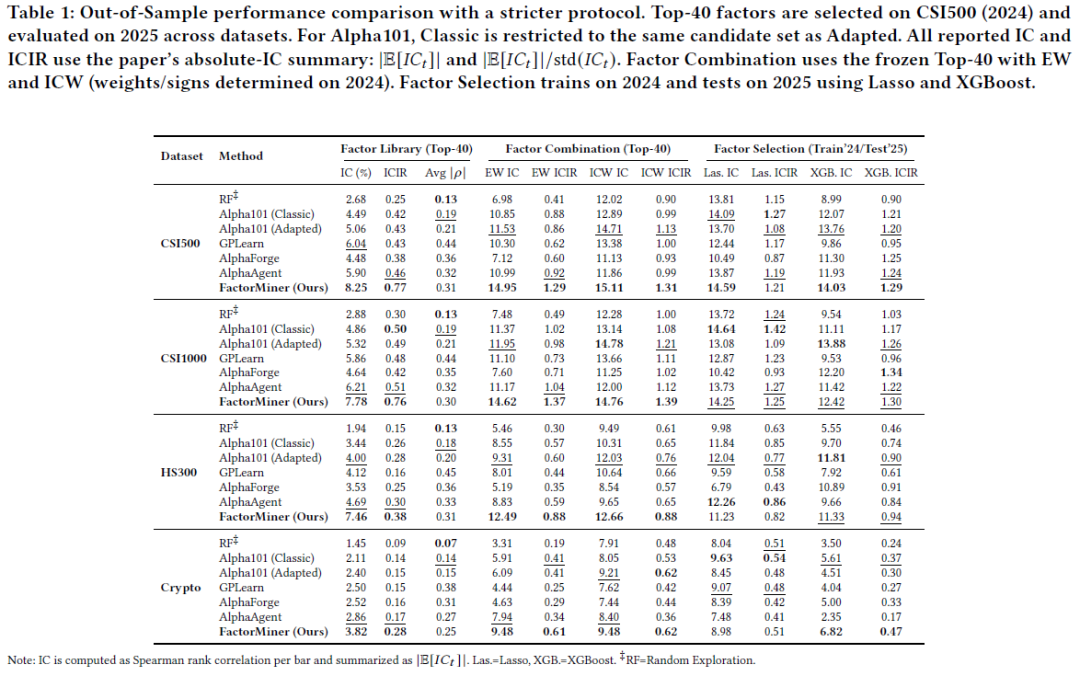
因子质量与多样性:2025年样本外结果显示,在严格协议下(从CSI500的2024年数据中选取前40个因子,并固定用于多数据集评估),FactorMiner 在因子库设置中于四个市场均表现最佳,在 CSI500 上实现了 8.25% 的 IC 和 0.77 的 ICIR,在其他市场也有类似的显著提升。FactorMiner 所选的因子呈现适度的两两依赖,A股平均两两绝对相关性为 0.30 - 0.31,加密货币为 0.25。相关性分布显示在特定阈值处存在约束,表明性能提升并非由少数近似信号驱动。
跨市场稳健性:跨市场评估显示 FactorMiner 发现的因子具有良好的泛化能力。尽管加密货币市场与A股结构不同,但 FactorMiner 在加密货币市场仍表现出色,这表明其捕捉到了跨资产类别不变的基本面量价动态。
集成与学习选择对比:通过简单的因子组合和学习选择模型评估挖掘出的因子库对下游投资组合构建的效用。在多数情况下,学习模型优于简单集成。但 FactorMiner 的简单集成信号已经捕捉了大部分可被利用的预测能力,学习选择带来的增益有限,甚至在部分数据集中为负。
经验记忆效应
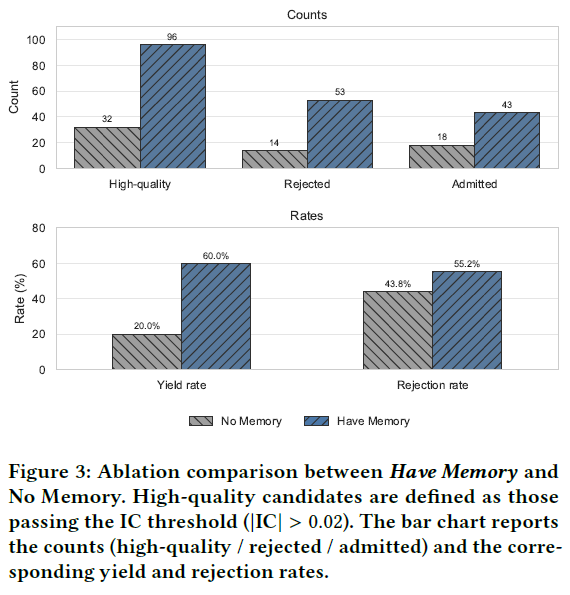
为分离经验记忆(M)的作用,进行了消融实验,对比 FactorMiner 与“无记忆”变体(禁用 𝐹、𝐸、𝑅 算子,变为标准的大语言模型进化),并采用较宽松的筛选阈值。
图 3 显示了记忆引导的效果:
- 精确导航(高产):“有记忆”变体生成了 96 个高质量候选因子(60% 产出率),而“无记忆”仅生成 32 个(20% 产出率),这说明检索算子有效地规划了搜索空间。
- 积极过滤(高多样性):“有记忆”变体产生的有效信号多了 3 倍,但因冗余而被拒绝的比例也更高(55.2% vs 43.8%),这表明进化算子(𝐸)重视独特信号的发现。
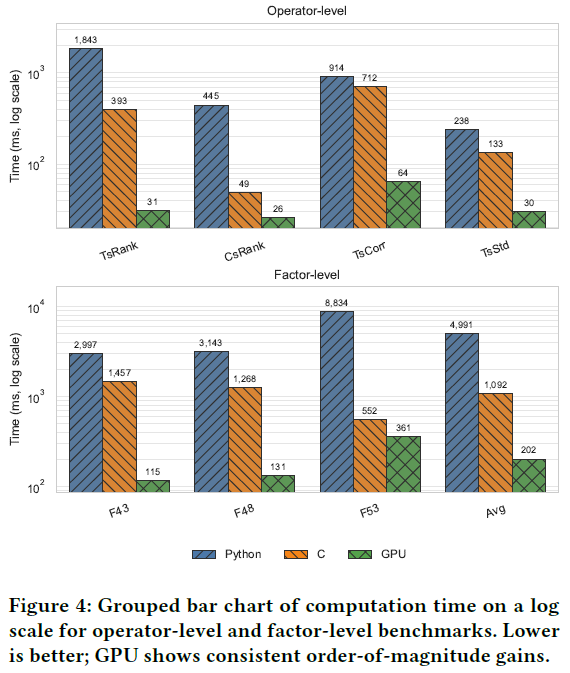
挖掘效率分析
为验证因子挖掘技能的实用性,对框架支持的三种执行后端(标准Python、C编译、GPU加速)进行了严格的基准测试。结果显示,在真实的 CSI500 数据集上:
- 算子层面:GPU 后端比 Pandas (Python) 快 8 - 59 倍,比优化的 C 后端快 2 - 13 倍,例如 TsRank 操作符的加速尤为显著。
- 端到端因子评估:排名密集型的因子获得了 23 - 27 倍的加速,C 实现平均比 GPU 后端慢 5.4 倍。
这种混合加速策略使得因子挖掘既灵活又高性能,让大规模迭代发现能够在普通硬件上实现。FactorMiner 评估 1000 个候选因子仅需约 6 分钟,远快于 Pandas 所需的约 70 分钟。
讨论
高频市场可以被视为一个数据丰富的复杂自适应系统。FactorMiner 提供了一个包含 110 个可解释高频 Alpha 因子的库及标准化的评估协议,支持可重复的假设检验等研究。
经验记忆是实现持续学习的关键。记忆引导的、基于技能的智能体可以高效地扩展神经符号程序合成,同时保留可解释性。经验记忆通过积累知识来实现元学习。从记忆中提取的关键见解包括:
- 成功模式:例如高阶矩机制、趋势回归的适应性等,能够产生高 IC 且低相关性的因子。
- 失败模式:例如 VWAP 偏差变体、高度标准化的收益/成交量等,这些模式与现有因子高度相关,应予以避免。
- “相关红海”现象:在没有记忆引导的情况下,随着因子库的增长,发现新的正交因子会变得越来越困难。
总结
FactorMiner 提供了一个轻量级的自进化 Agent 框架,结合了模块化的挖掘技能与经验记忆,用于高频可解释 Alpha 因子发现。该工作形成了包含 110 个公式化因子的库及标准化评估协议的可复现成果,可用于市场微观结构分析。未来工作将包括开展交易成本回测、拓展资产与频率范围、以及开发面向非平稳市场的在线记忆更新机制。
如果你对智能体架构、数据科学在金融领域的应用等话题感兴趣,欢迎在 云栈社区 交流探讨。此外,关于更多 数据挖掘 与计算性能优化的前沿实践,也可以在我们的技术板块找到深度讨论。随着 人工智能 技术的演进,这类结合经验记忆与领域技能的框架,为解决复杂的程序合成问题提供了新思路。
 发表于 2026-3-1 02:41:53
|
查看: 172|
回复: 0
发表于 2026-3-1 02:41:53
|
查看: 172|
回复: 0
